






 本文详细探讨了HotSpot中字符串常量池的位置变化、静态方法特性、类的初始化顺序、反射机制的应用、异常处理机制、SPI机制的工作原理、WeakHashSet的实现方式、多线程的需求背景及并发问题根源等内容。
本文详细探讨了HotSpot中字符串常量池的位置变化、静态方法特性、类的初始化顺序、反射机制的应用、异常处理机制、SPI机制的工作原理、WeakHashSet的实现方式、多线程的需求背景及并发问题根源等内容。
1、HotSpot中字符串常量池保存哪里?永久代?方法区还是堆区?
- 运行时常量池(Runtime Constant Pool)是虚拟机规范中是方法区的一部分,在加载类和结构到虚拟机后,就会创建对应的运行时常量池;而字符串常量池是这个过程中常量字符串的存放位置。所以从这个角度,字符串常量池属于虚拟机规范中的方法区,它是一个逻辑上的概念;而堆区,永久代以及元空间是实际的存放位置。
- 不同的虚拟机对虚拟机的规范(比如方法区)是不一样的,只有 HotSpot 才有永久代的概念。
- HotSpot也是发展的,由于一些问题 (opens new window)的存在,HotSpot考虑逐渐去永久代,对于不同版本的JDK,实际的存储位置是有差异的,具体看如下表格:
| JDK版本 | 是否有永久代,字符串常量池放在哪里? | 方法区逻辑上规范,由哪些实际的部分实现的? |
|---|---|---|
| jdk1.6及之前 | 有永久代,运行时常量池(包括字符串常量池),静态变量存放在永久代上 | 这个时期方法区在HotSpot中是由永久代来实现的,以至于这个时期说方法区就是指永久代 |
| jdk1.7 | 有永久代,但已经逐步“去永久代”,字符串常量池、静态变量移除,保存在堆中; | 这个时期方法区在HotSpot中由永久代(类型信息、字段、方法、常量)和堆(字符串常量池、静态变量)共同实现 |
| jdk1.8及之后 | 取消永久代,类型信息、字段、方法、常量保存在本地内存的元空间,但字符串常量池、静态变量仍在堆中 | 这个时期方法区在HotSpot中由本地内存的元空间(类型信息、字段、方法、常量)和堆(字符串常量池、静态变量)共同实现 |
2、静态方法
静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法(abstract)。
3、初始化顺序
静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
4、反射
著作权归https://pdai.tech所有。 链接:Java 基础 - 知识点 | Java 全栈知识体系
每个类都有一个 Class 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。
类加载相当于 Class 对象的加载。类在第一次使用时才动态加载到 JVM 中,可以使用 Class.forName("com.mysql.jdbc.Driver") 这种方式来控制类的加载,该方法会返回一个 Class 对象。
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
- Field : 可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
- Method : 可以使用 invoke() 方法调用与 Method 对象关联的方法;
- Constructor : 可以用 Constructor 创建新的对象。
5、异常
Throwable 可以用来表示任何可以作为异常抛出的类,分为两种: Error 和 Exception。其中 Error 用来表示 JVM 无法处理的错误,Exception 分为两种:
- 受检异常 : 需要用 try...catch... 语句捕获并进行处理,并且可以从异常中恢复;
- 非受检异常 : 是程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序崩溃并且无法恢复。
6、反射机制
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。Java反射机制在框架设计中极为广泛,需要深入理解。
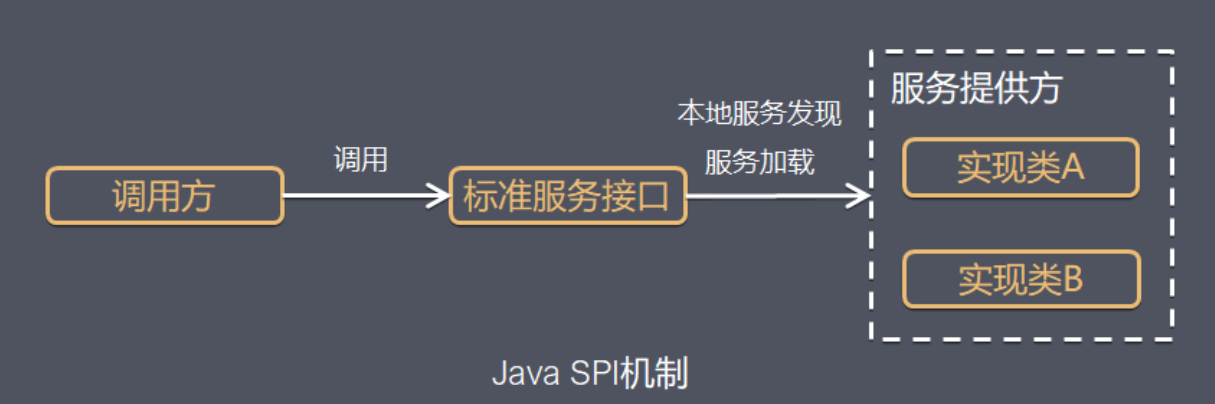
7、什么是SPI机制
SPI(Service Provider Interface),是JDK内置的一种 服务提供发现机制,可以用来启用框架扩展和替换组件,主要是被框架的开发人员使用,比如java.sql.Driver接口,其他不同厂商可以针对同一接口做出不同的实现,MySQL和PostgreSQL都有不同的实现提供给用户,而Java的SPI机制可以为某个接口寻找服务实现。Java中SPI机制主要思想是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要,其核心思想就是 解耦。
8、Weak HashSet?
如果你看过前几篇关于 Map 和 Set 的讲解,一定会问: 既然有 WeakHashMap,是否有 WeekHashSet 呢? 答案是没有:( 。不过Java Collections工具类给出了解决方案,Collections.newSetFromMap(Map<E,Boolean> map)方法可以将任何 Map包装成一个Set。通过如下方式可以快速得到一个 Weak HashSet:
9、为什么需要多线程?
众所周知,CPU、内存、I/O 设备的速度是有极大差异的,为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了贡献,主要体现为:
- CPU 增加了缓存,以均衡与内存的速度差异;// 导致
可见性问题 - 操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;// 导致
原子性问题 - 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。// 导致
有序性问题
10、并发出现问题的根源: 并发三要素
可见性: CPU缓存引起,
原子性: 分时复用引起
即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
这里需要注意的是:i += 1需要三条 CPU 指令
- 将变量 i 从内存读取到 CPU寄存器;
- 在CPU寄存器中执行 i + 1 操作;
- 将最后的结果i写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
由于CPU分时复用(线程切换)的存在,线程1执行了第一条指令后,就切换到线程2执行,假如线程2执行了这三条指令后,再切换会线程1执行后续两条指令,将造成最后写到内存中的i值是2而不是3。
有序性: 重排序引起
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读 / 写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从 java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









