







024:基于shardingjdbc实现分表分库
1 数据库分表分库规则
今日课程任务
- 订单表与会员表如何实现分表分库
- 分表分库实现算法有哪些
- sharding-jdbc与MyCat实现分表分库的区别
- sharding-jdbc实现分表分库的源码分析
- 分表分库后,如何实现联合查询
- 微服务电商项目如何整合Zipkin实现服务追踪
- 微服务服务追踪实现原理与存在缺陷
分表分库:最好是在千万级别数据开始分表分库。
分库概念:根据业务实现分库 订单数据库、会员数据库、支付数据库
会员数据库中分为多个不同的数据库
member_db1—member_table
member_db2—member_table
同样的表不建议在多个数据库中存放,最好在单个数据库中将一个大表拆分成多个子表
member_db.member_table1 member_db.member_table2
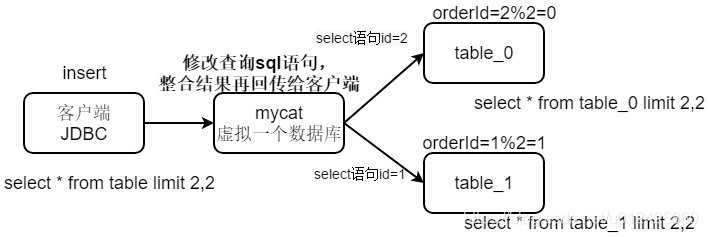
2 mycat实现分表分库原理
拆分子表能有效提高查询效率
举例:1000w数据量表查询效率10s,拆分成2个子表查询时间为5s左右
分片算法:
- 计算hash(常见) 根据唯一id取模 存在表扩容的问题
- 按照时间划分
- 按照范围划分
基于mycat实现分片,可以隐藏数据库db真实的联接地址,虚拟一个数据库类似nginx反向代理。分表分库后查询所有数据效率也不会很低,因为采用多线程查询数据。
3 shadingjdbc实现的原理
Sharding-jdbc实现原理:
本地采用aop拦截jdbc语句,在发送sql之前改写sql语句,效率比mycat要高。
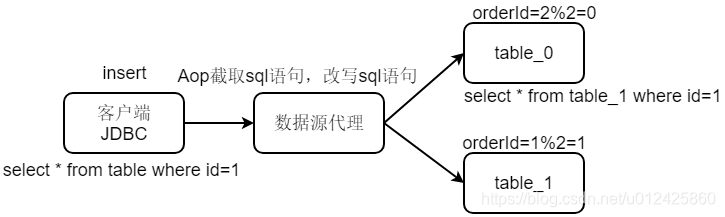
Sharding-jdbc与mycat区别:
- mycat是基于服务器虚拟数据库的方式实现分表分库;
- sharding-jdbc基于本地aop拦截改写sql语句
4 项目如何整合shadingjdbc
数据库表
CREATE TABLE `t_order_0` (
`order_id` bigint(20) NOT NULL,
`user_id` bigint(20) NOT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
CREATE TABLE `t_order_1` (
`order_id` bigint(20) NOT NULL,
`user_id` bigint(20) NOT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
Maven依赖
<dependencies>
<dependency>
<groupId>com.mayikt</groupId>
<artifactId>mt-shop-service-api-order</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.0.0.M3</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.9</version>
</dependency>
</dependencies>
bootstrap.yml
###服务启动端口号
server:
port: 3030
spring:
cloud:
nacos:
discovery:
##服务的注册
server-addr: 127.0.0.1:8848
config:
server-addr: 127.0.0.1:8848
application:
name: app-mayikt-order
sharding:
jdbc:
####ds1
datasource:
names: ds1
ds1:
password: root
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/meite_order?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8
username: root
#### 分片配置
config:
sharding:
tables:
####t_order
t_order:
table-strategy:
inline:
#### 根据order_id 进行分片
sharding-column: order_id
#### ds_1.t_order_0 ds_1.t_order_1
algorithm-expression: t_order_$->{order_id % 2}
###分表的总数 0到1 t_order_0 t_order_1
actual-data-nodes: ds1.t_order_$->{0..1}
props:
sql:
### 开启分片日志
show: true
核心代码
public interface OrderService {
/**
* 新增order
*
* @return
*/
@GetMapping("/addOrder")
BaseResponse<String> addOrder();
/**
* 根据订单号码查询
*
* @param orderId
* @return
*/
@GetMapping("/findByOrderId")
BaseResponse<OrderRspDto> findByOrderId(Long orderId);
/**
* 查询所有的订单
*
* @return
*/
@GetMapping("/listOrderId")
List<String> listOrderId();
}
@RestController
public class OrderServiceImpl extends BaseApiService implements OrderService {
@Autowired
private OrderMapper orderMapper;
@Override
public BaseResponse<String> addOrder() {
for (int i = 0; i < 100; i++) {
Long userId = 1L;
orderMapper.addOrder(i + "", userId);
}
return setResultSuccess();
}
@Override
public BaseResponse<OrderRspDto> findByOrderId(Long orderId) {
OrderEntity orderEntity = orderMapper.findByOrderId(orderId);
OrderRspDto orderRspDto = dtoToDo(orderEntity,OrderRspDto.class);
return setResultSuccess(orderRspDto);
}
@Override
public List<String> listOrderId() {
return orderMapper.findListOrders();
}
}
public interface OrderMapper {
@Insert("INSERT INTO `t_order` VALUES (${orderId},#{userId});")
int addOrder(String orderId, Long userId);
@Select("SELECT order_id as orderId FROM t_order limit 0,5; ")
List<String> findListOrders();
@Select("SELECT order_id as orderId,user_id as userId FROM t_order where order_id=#{orderId} ")
OrderEntity findByOrderId(@Param("orderId") Long orderId);
}
测试效果:
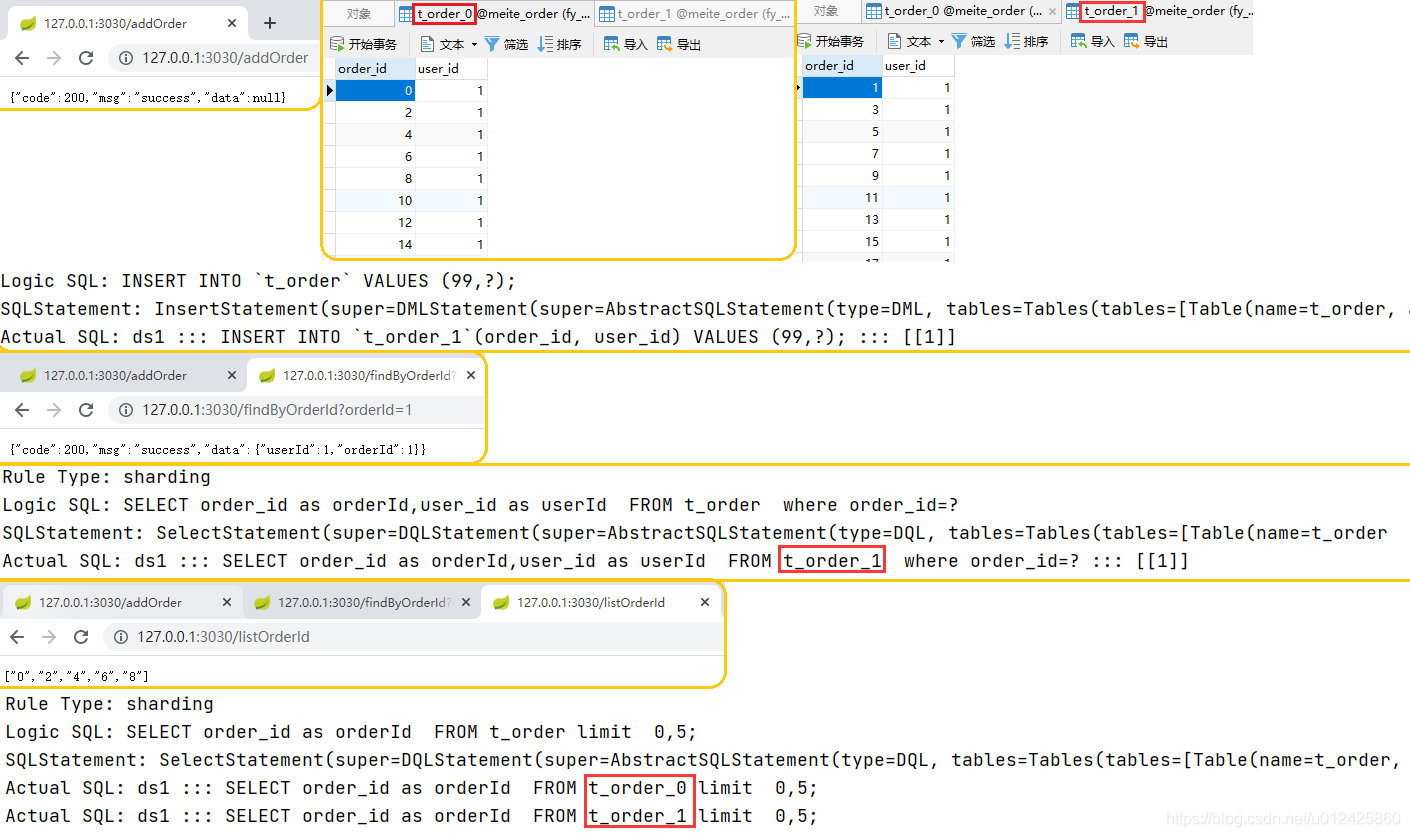
5 微服务如何实现服务追踪
生成环境中,遇到问题是怎么解决的
- 查询日志(服务器上直接看)
- Elk+kafka+aop异步采集日志
- 搭建微信公众号报警系统 微信公众号模板推送
- 构建服务追踪系统
以上234种方案选一种即可,没必要全部都搭建一遍。
微服务中依赖关系比较大,定位问题找到错误原因非常复杂,可以搭建服务追踪系统解决。
6 微服务服务追踪实现原理分析
ZipkinServer环境搭建
在 Spring Boot 2.0 版本之后,官方已不推荐自己搭建定制了,而是直接提供了编译好的 jar 包。详情可以查看官网:https://zipkin.io/pages/quickstart.html
注意:zipkin官网已经提供定制了,使用官方jar运行即可。
默认端口号启动zipkin服务
java –jar zipkin.jar 默认端口号; 9411
http://127.0.0.1:9411
指定端口号启动9411
java -jar zipkin.jar --server.port=8080
ZipkinClient集成
Maven依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
application.yml
spring:
application:
name: app-itmayiedu-member
zipkin:
base-url: http://127.0.0.1:9411/
###全部采集
sleuth:
sampler:
probability: 1.0
Sleuth简单的介绍
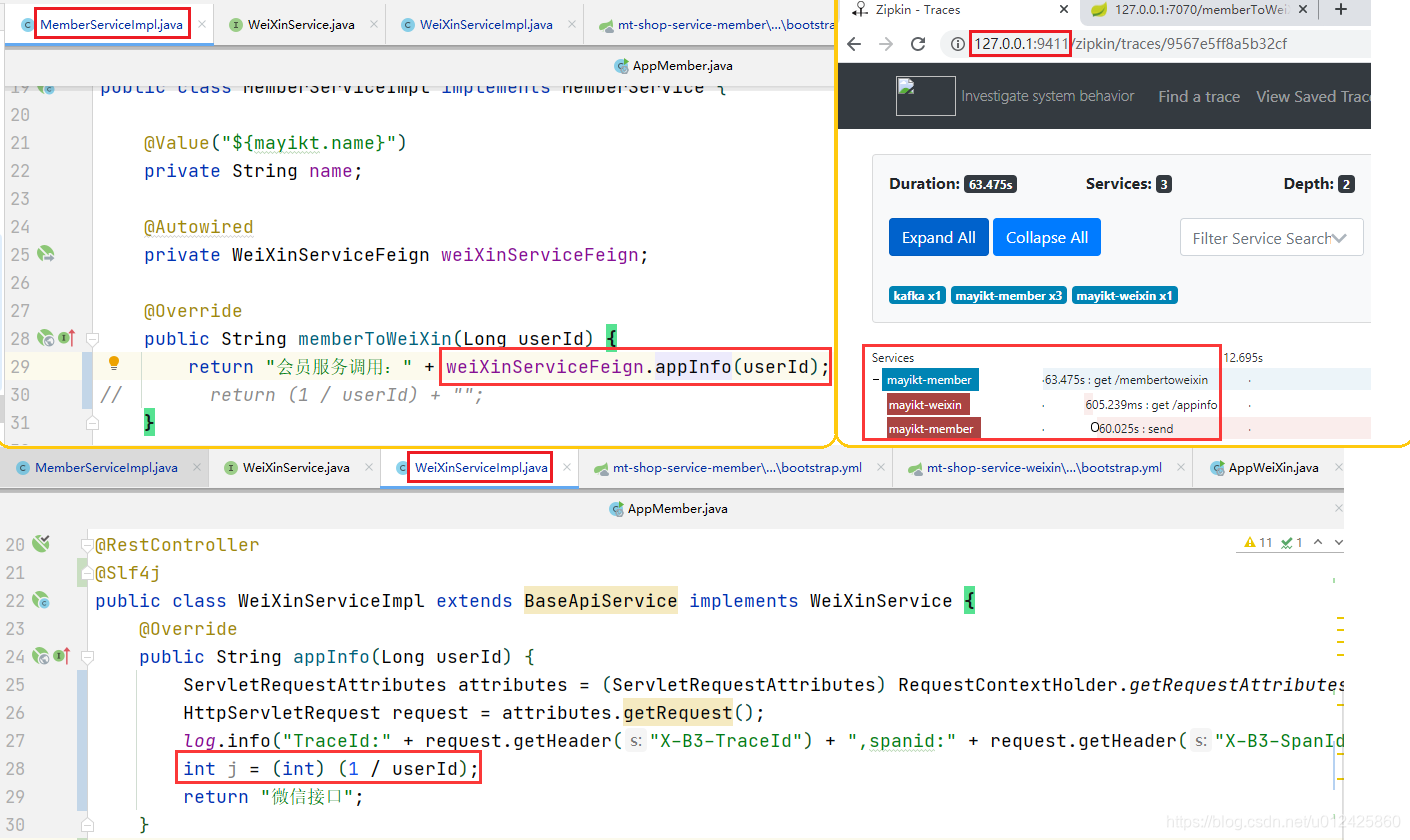
Sleuth 每一次RPC远程调用请求都会生成一个spanid记录每一次rpc请求的信息,还有一个traceid 全局唯一id;
实现原理:
- 开始方调用接口的时候会生成一个全局的id ,放入到请求中
- 每次调用rpc接口的时候会产生一个新的spanid,放入到请求中
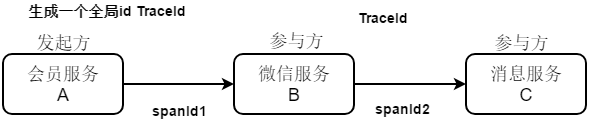
Sleuth可以结合Zipkin可以实现界面化的形式管理我们接口依赖信息。
效果测试:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









