







013:整合canal解决mysql与Redis数据一致性的问题
1 MySQL如何与Redis解决数据同步问题
今日课程任务
- 微服务电商项目如何解决Redis与Mysql数据一致性问题
- AlibabaCanal解决Redis、Mysql数据一致性原理
- 搭建AlibabaCanalServer端环境
- 使用事件监听的方式解决Mysql与Redis一致性问题
- 构建Kafka+Zookeeper环境
- AlibabaCanal如何整合CanalServer端环境
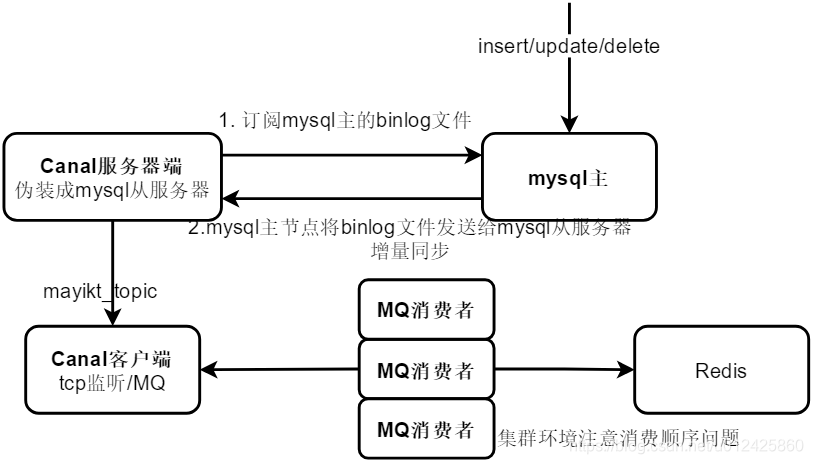
2 canal解决数据同步的底层实现原理
Canal的实现原理
- canalServer端会伪装成一个mysql从节点,读取主节点的binlog文件,实现增量同步;
- canalServer端将binlog文件数据转换成json格式发到MQ中,mq消费者订阅该topic,通过mq消费者异步同步到redis中。
3 启动canalServer端
构建canal服务端之前需要准备的条件
配置Mysql服务器
1 配置MySQL的 my.ini 开启允许基于binlog文件主从同步
log-bin=mysql-bin #添加这一行就ok
binlog-format=ROW #选择row模式
server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复
配置该文件后,重启mysql服务器即可
show variables like ‘log_bin’;
没有开启log_bin的值是OFF,开启之后是ON
2 添加cannl的账号 或者直接使用root账号
drop user 'canal'@'%';
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
grant all privileges on *.* to 'canal'@'%' identified by 'canal';
flush privileges;
一定要检查mysql user 权限为Y
构建CanalService
修改 \conf\example下的instance.properties 配置文件内容
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
需要同步的数据库表(库.表;以下表示全库全表)
canal.instance.filter.regex=.\…
启动startup.bat 查看 \logs\example example.log日志文件(start success…)
canal是否存在数据同步的网络延迟
Canal实现mysql与redis数据的同步问题,会不会存在延迟?
延迟是不可避免的,同步的速度非常快人为无法感知。短暂的延迟可以接受,最终数据一定要保持一致。
4 快速构建zookeeper的运行的环境
安装zookeeper
下载文件包zookeeper-3.4.14.tar.gz
conf\zoo_sample.cfg 修改为 zoo.cfg
修改 zoo.cfg 中的 dataDir=E:\zkkafka\zookeeper-3.4.14\data(zookeeper目录)
新增环境变量:
ZOOKEEPER_HOME: E:\zkkafka\zookeeper-3.4.14 (zookeeper目录)
Path: 在现有的值后面添加 “;%ZOOKEEPER_HOME%\bin;”
运行zk bin/zkServer.cmd
5 快速构建kafka的运行的环境
解压 kafka_2.13-2.4.0 改名为 kafka
修改config\server.properties中的配置
log.dirs=E:\zkkafka\kafka\logs
cmd 进入到该目录:cd E:\zkkafka\kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties
Kafka启动成功
6 canal整合kafka的配置说明
Canal配置更改
- 修改 example/instance.properties
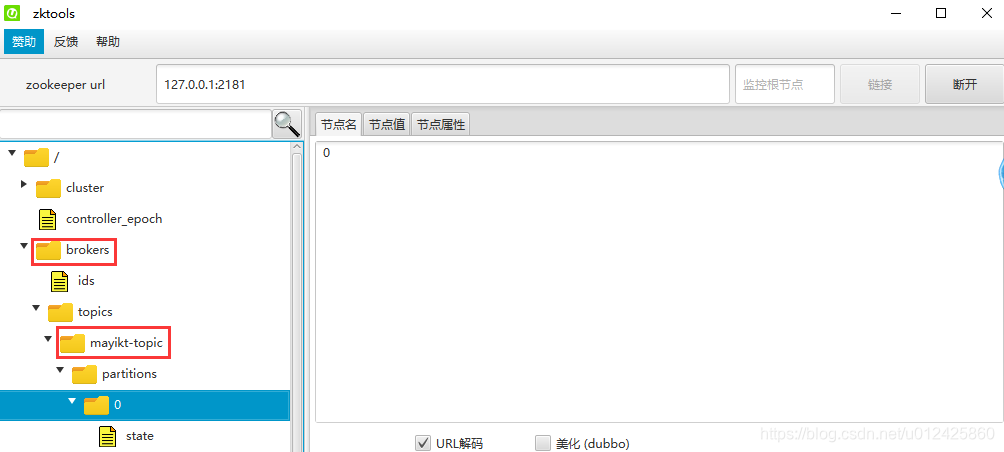
canal.mq.topic=mayikt-topic - 修改 canal.properties
canal.serverMode = kafka
canal.mq.servers = 127.0.0.1:9092
重启canal,zk节点上brokers里有topic节点说明配置成功。
7 微服务电商项目整合canal环境
建立子模块mt-shop-service-cana/mt-shop-service-member-canalclient
引入依赖Maven依赖
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
</dependencies>
配置文件 bootstrap.yml
# kafka
spring:
kafka:
# kafka服务器地址(可以多个)
bootstrap-servers: 127.0.0.1:9092
consumer:
# 指定一个默认的组名
group-id: kafka2
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
redis:
host: 127.0.0.1
# password:
port: 6379
database: 0
Kafka消费者
@Component
public class MemberKafkaConsumer {
@Autowired
private RedisUtil redisUtil;
@KafkaListener(topics = "mayikt-topic")
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset() + "," + consumer.value());
String json = (String) consumer.value();
JSONObject jsonObject = JSONObject.parseObject(json);
String type = jsonObject.getString("type");
String pkNames = jsonObject.getJSONArray("pkNames").getString(0);
JSONArray data = jsonObject.getJSONArray("data");
for (int i = 0; i < data.size(); i++) {
JSONObject dataObject = data.getJSONObject(i);
String key = dataObject.getString(pkNames);
switch (type) {
case "UPDATE":
case "INSERT":
redisUtil.setString(key, dataObject.toJSONString());
break;
case "DELETE":
redisUtil.delKey(key);
break;
}
}
}
}
测试效果:
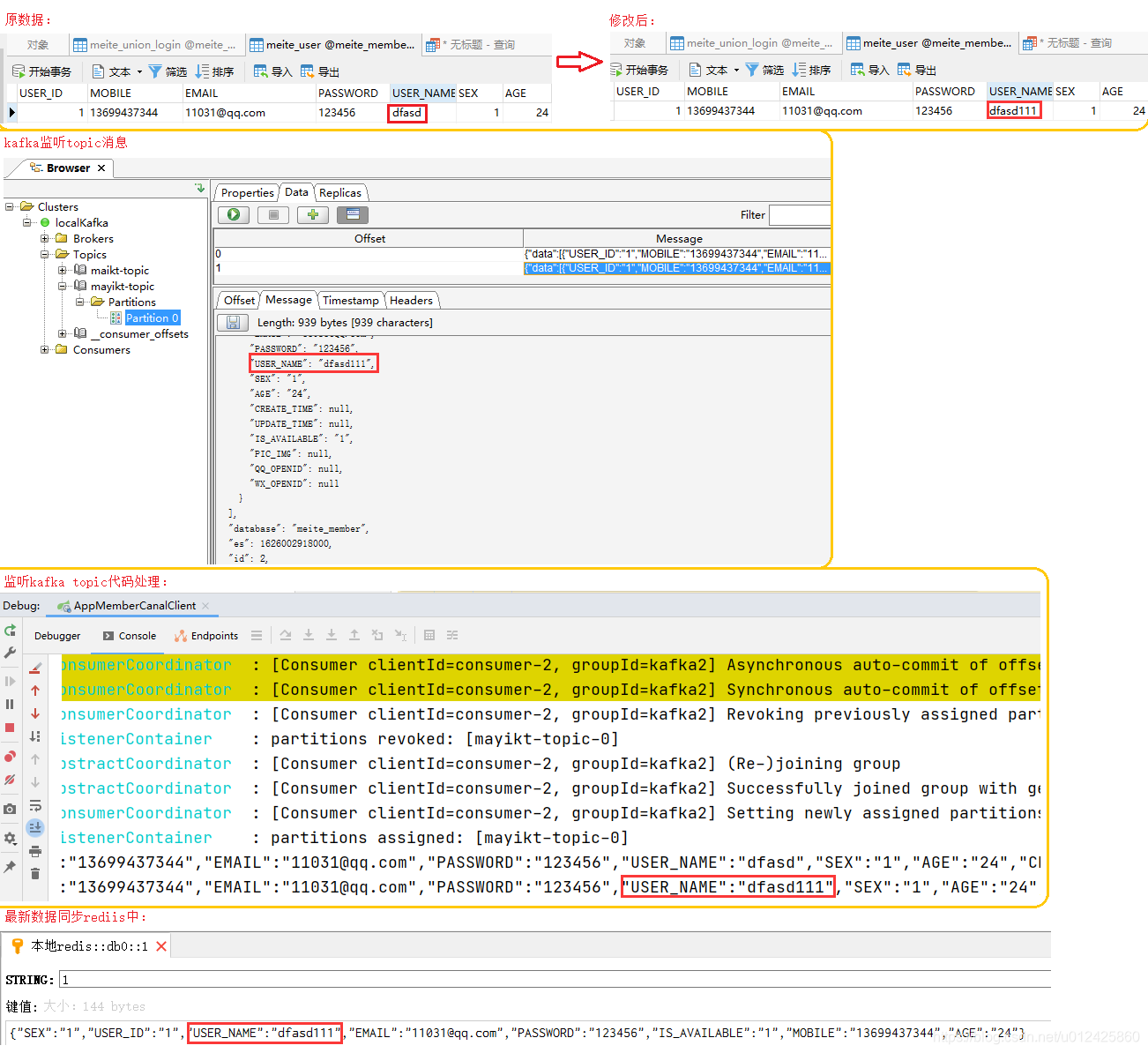
如何解决多表数据同步的问题
Redis的key设为数据库名+表名+主键id值


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









