








 LOGER是一个基于深度强化学习的查询优化器,旨在生成高效且鲁棒的查询执行计划。它利用GraphTransformer捕获表和谓词间的关系,通过限制算子搜索空间结合DBMS内置优化器选择物理算子,以及采用γ-beam搜索方法平衡探索与利用。LOGER还引入奖励加权和对数变换来稳定奖励值,提高训练性能的鲁棒性。实验表明,LOGER在多个基准测试上表现出色,相比传统和现有学习优化器有显著优势。
LOGER是一个基于深度强化学习的查询优化器,旨在生成高效且鲁棒的查询执行计划。它利用GraphTransformer捕获表和谓词间的关系,通过限制算子搜索空间结合DBMS内置优化器选择物理算子,以及采用γ-beam搜索方法平衡探索与利用。LOGER还引入奖励加权和对数变换来稳定奖励值,提高训练性能的鲁棒性。实验表明,LOGER在多个基准测试上表现出色,相比传统和现有学习优化器有显著优势。
标题:LOGER:一个用于生成高效和健壮的查询执行计划的学习优化器
***摘要***:基于深度强化学习(DRL)的查询优化是近年来的研究热点。尽管取得了可喜的进展,但由于连接顺序和算子选择的巨大搜索空间以及作为反馈信号的高度变化的执行延迟,DRL优化器仍然面临鲁棒地生成高效计划的巨大挑战。在本文中,我们提出了LOGER,一个用于生成高效鲁棒计划的学习优化器,旨在生成高效的连接顺序和算子。LOGER首先利用Graph Transformer捕获表和谓词之间的关系。然后,对搜索空间进行重组,其中LOGER学习限制特定的算子,而不是为每个连接直接选择一个算子,同时利用DBMS内置的优化器在限制下选择物理算子。该策略利用专家知识提高了计划生成的鲁棒性,同时提供了足够的计划搜索灵活性。此外,LOGER引入了𝜖-beam搜索,它在执行引导探索的同时保留了多个搜索路径,以保留有前景的计划。最后,LOGER引入了一个带有奖励权重的损失函数,通过减少糟糕算子带来的波动进一步增强性能的鲁棒性,并通过对数变换压缩奖励的范围。我们在Join Order Benchmark (JOB)、TPC-DS和Stack Overflow上进行了实验,并证明LOGER可以实现比现有学习查询优化器更好的性能,与PostgreSQL相比,LOGER在JOB上的加速速度提高了2.07倍。
介绍
查询优化一直是数据库领域的关键问题,因为查询优化的难度和查询执行性能的重要性。为了给每个查询找到一个有效的执行计划,查询优化器必须在一个非常大的搜索空间中进行搜索,我们知道,在这个搜索空间中,寻找最优的连接顺序是一个NP-hard问题[7]。此外,物理算子的选择也会影响性能,使问题更加复杂。因此,目前几乎所有的关系数据库管理系统都采用启发式方法和各种策略来平衡查询优化的复杂性和执行延迟。这些传统的查询优化方法经过不懈的努力,在不同的环境下都实现了稳定的性能。
然而,传统的优化器仍然面临挑战,因为数据分布和查询在实际应用程序中可能非常复杂,并且不可能评估所有可能的计划。因此,这些优化器依赖于简单的策略和假设来做出决策,并经常产生良好但次优的计划。此外,这些优化器通常需要数年或数十年的开发时间。当考虑到诸如在新硬件上运行之类的更改时,传统的优化器很难适应不同的环境。
为了克服传统查询优化器的局限性,近年来出现了基于DRL的优化器[12,16,17,28,29]。使用DRL,通过将每个连接视为一个动作,计划生成自然地转换为计划搜索空间中的序列决策问题。DBMS作为DRL的环境,在生成完整的计划时回应奖励反馈,即执行延迟。然后,这些DRL查询优化器从奖励中学习,在当前数据分布上生成有效的计划。这些学习优化器的成功证明了DRL查询优化的可行性,表明经过充分的训练,在特定的工作负载和环境下,学习优化器可以在开源DBMS(如PostgreSQL)和商业DBMS上显著优于传统方法。
尽管学习优化器实现了有前景的竞争性能,但这些方法仍处于早期阶段。DRL优化器面临着与传统方法相同的巨大搜索空间。为了达到高鲁棒的性能,需要适当的策略来获得有前景的计划。此外,DRL优化器是根据执行延迟进行训练的,而执行延迟在很大程度上随连接顺序和算子的不同而变化,这使得鲁棒查询优化的稳定训练变得更加困难。因此,方法设计应考虑影响计划生成鲁棒性的因素。我们总结了一个成功的学习优化器的要求如下。
-
首先,expressive query representation是学习优化器的先决条件。以前的各种方法[16,17,28]将每个查询表示为join graph,其中每个节点代表一个表,每个边是一个连接谓词。为了利用图结构,模型应该在node representations中利用足够的信息,并沿着edges交换它们以提取表和谓词之间的关系。然而,这些先前的方法利用join graph,将adjacency matrix简单地处理为一个flattened vector,并使用像MLP这样的网络,这对于通过图结构提取信息是低效的。为了获得更好的性能,需要一个更具表现力的查询表示模型。
-
其次,从一个非常大的搜索空间中鲁棒地搜索有效的计划是至关重要的。许多现有的学习查询优化器[17,29]通过只处理连接顺序的搜索来降低找到有效计划的难度,将物理算子的选择留给DBMS的内置优化器,这提供了更少的机会来实现更高的性能。其他[16,28]尝试同时使用连接顺序和物理运算符来生成计划,以达到更好的性能,但随着搜索空间的进一步扩大,搜索难度明显更高。为了从包含连接顺序和算子的空间中鲁棒地获得有效的计划,不仅需要一种生成有前景的计划的搜索方法,而且还值得讨论如何利用传统优化器来降低搜索难度。
-
第三,需要一种策略来处理分散和高度波动的奖励(scattered and highly fluctuating rewards),这对学习优化器的鲁棒性有严重影响。一个低效的计划可能比一个更好的计划的成本高几十倍甚至几千倍,导致延迟在一个非常大的范围内变得很稀疏。同时,连接顺序和物理算子之间的相互影响使得延迟变化很大。具有相同连接顺序但不同连接算子的计划可能具有不同的性能,导致强化学习中奖励反馈的差异很大,进一步增加了鲁棒计划生成的难度。为了解决这个问题,提出了一种简单的超时机制(simple timeout mechanism),将不良计划的反馈限制在预定义的值[28]。然而,更灵活的方法对于鲁棒的性能是必要的。
为了克服上述问题提出了一种实用思路,我们提出了LOGER,一个旨在生成高效鲁棒计划的学习优化器,旨在生成高效的连接顺序和算子。
为了提高representation expressiveness,我们应用Graph Transformer(GT)[5],一种图神经网络(GNN)模型,从连接图中的表和谓词中捕获信息。使用GT,LOGER不仅可以在相邻的表节点之间充分交换信息,还可以将图的结构信息集成到每个节点中,从而在table representations反映表和谓词之间的关系。
为了利用专家知识(expert knowledge)来提高计划生成的鲁棒性,我们提出了约束算子搜索空间(Restricted Operator Search Space,ROSS),它结合了学习优化器和传统优化器的优点来选择算子和连接顺序选择。ROSS使用限制算子来禁止使用特定的物理算子,而不是直接为每个连接选择算子,并调用DBMS内置的优化器来完成算子的选择。ROSS的关键思想是利用DBMS优化器来降低学习优化器的计划搜索难度,同时提供足够的灵活性以避免低效的算子选择。为了进一步提高搜索效率,我们提出了一种新的搜索方法𝜖-beam search,该方法在多个路径上同时采取行动,并以广阔的视野选择预测的最佳候选路径。该方法采用𝜖-greedy[26]算法的思想引入探索机制,并进一步以价值预测为指导,寻找最具潜力的计划,自适应平衡探索与利用。
最后,LOGER利用不同的策略来降低训练过程中波动奖励对鲁棒性的影响。我们提出了奖励加权(reward weighting)来稳定奖励值,并使LOGER专注于学习有效的连接顺序。以算子相关时延(operator-relevant latency)和算子无关时延(operator-irrelevant latency)的加权值(weighted value)作为奖励,缓解了之前选择的不良算子所带来的波动。此外,我们使用对数变换(log transformation)对灾难性计划的分散奖励值进行压缩,且使LOGER更加关注较好的计划通过使其奖励值与不良的计划更容易区分。
我们用PostgreSQL测试了LOGER在Join Order Benchmark (JOB)[13]、TPC-DS[19]和Stack Overflow[15]上的性能。实验表明,在JOB测试负载下,经过约2小时的训练,我们的方法可以超越传统的优化器,最终达到2.07倍的提速。我们在一个商业DBMS上进一步测试了我们的方法,得到了类似的结果。与先前的最先进的学习查询优化器相比,LOGER性能最好,并且推理时间短。
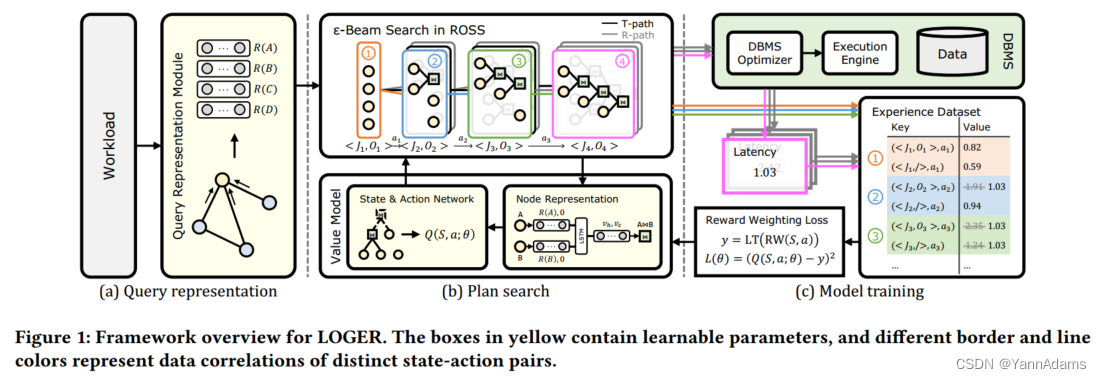
方法框架
LOGER的框架如图1所示。与现有方法[12,16,28,29]类似,LOGER侧重于没有子查询的select-project-join (SPJ)语句,并使用基于值的DRL框架,其中,在搜索过程中评估中间计划(子计划)的质量以指导计划生成。然后,每个生成计划的延迟作为来自环境的反馈,用作训练LOGER的奖励。在本节中,我们简要介绍了LOGER中基于值的DRL方法,并列出了三个主要过程,同时讨论了现有方法与LOGER之间的共同点和差异部分。
-
Value-based DRL for query optimization
在强化学习中,agent从初始state出发,根据policy采取actions,在state-action空间中进行搜索,并从environment中获得reward值,然后通过training来提高性能。在value-based DRL方法中,policy由learned value network V(S)或Q(S, a)确定,该网络评估state或state-action pair的最大累积未来reward。agent估计所有候选actions,并在选择预期reward最大的action和探索其他action之间做出决定,直到达到最终state。
基于DRL的查询优化采用了DRL的思想,将查询优化问题转化为每个查询的join sequence的决择。一个不完整的序列,即subplan,被视为一种state,而选择下一个连接的行为是一种action。与Neo[16]和RTOS[29]等先前的方法类似,我们将序列视为连接树的森林,每个树代表一个表或连接多个表的结果。树需要组合以产生新的树,直到森林中只剩下一棵树,这表明所有表都连接在一起。从查询中没有表连接的state开始,LOGER通过估计所有候选action的最低可达延迟来选择actions。我们将每个子计划S标记为一对(J, O),其中J是一组连接树表示连接顺序,O是包含所选连接算子信息一个集合。
使用一个查询包含四个表𝐴,B,𝐶,𝐷作为一个例子,初始状态 =({𝐴,𝐵,𝐶,𝐷},∅),和到达状态
=({𝐴⋈𝐵,𝐶,𝐷},{𝐴
𝐵}),在采取𝐴和𝐵使用
的action后,其中
是一个限制算子,将在后面详细解释。当得到一个完整的连接树((𝐴⋈𝐵)⋈𝐶)⋈𝐷时,这个过程就结束了,因为所有的表都连接在一起了。在此过程之后,从DBMS引擎获得延迟并用于模型训练。
-
Query representation
为了在查询中捕获信息用于评估子计划,LOGER将其转换为vectorized representations,用作值模型的输入,如图1(a)所示。在这一步中,通过query representation module获得每个表的representation。以前的方法使用简单的网络如MLP,在利用图结构方面效率低下,但LOGER通过使用GT来有效地提取信息并捕获表和谓词之间的关系。
-
Plan search
在query representation之后,LOGER通过DRL搜索过程建立初始子计划并逐步生成计划,如图1(b)所示。LOGER使用一个值模型,通过table representations来预测每个步骤中state-action pair的延迟值,并根据预测选择动作。为了公平地评估慢查询和快查询的计划,值模型预测相对执行延迟。给定一个查询,其相对延迟 𝑙 由以下公式计算,其中是由LOGER生成的计划S的执行延迟,
是由DBMS优化器生成的计划
的执行延迟。𝑙 = {
} / {
} (公式如下)。
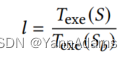
与现有工作不同的是,LOGER利用限制算子对搜索空间进行重组,利用传统优化器的专家知识,并应用𝜖-beam搜索,在平衡探索和利用的情况下获得更好的训练计划。在图1中,通过𝜖-beam搜索选择探索或利用,依次生成子计划①-④以及它们后面展示的其他子计划。每个子计划中的分支节点表示限制算子的选择。
-
Model training
生成计划后,执行生成的计划,获取延迟值,并记录在experience dataset中。经验数据集包含一个hash lookup table 𝑇,该表记录了每个state-action pair ((𝐽,𝑂) , 𝑎) 达到的最低延迟。由于不完整的子计划(如图1中的①-③)不能单独评估,它们的table values 𝑇((𝐽,𝑂) , 𝑎)用相应的最终计划(如④)的延迟进行更新。然后利用损失函数更新value model和query representation module的参数。与以往不同的是,我们提出了reward weighting,通过log transformation来减少以往不良算子的影响,使LOGER减少对灾难性计划的关注。为了执行reward weighting,还记录了另一个table values 𝑇((𝐽, /), 𝑎),稍后将对此进行解释。
在下面的部分中,我们将详细描述每个过程。我们在表1中列出了常用的符号。

查询表示
在本节中,我们首先介绍连接图join graph的构造,然后演示LOGER如何通过query representation module提取信息并获得table representations。
3.1 Join Graph Construction
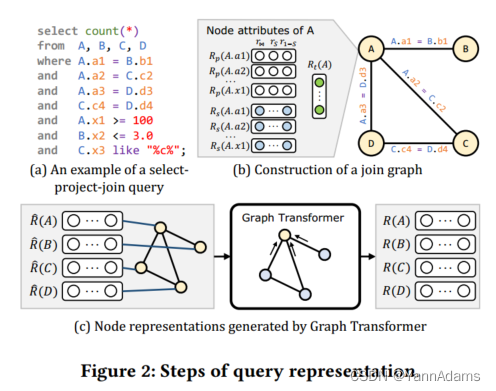
如图2(a)和2(b)所示,select-project-join查询可以自然地转换为连接图,其中每个节点表示一个表,每个边是一个连接谓词。LOGER将其他信息集成到节点属性中,包括查询中涉及的相应表、列和谓词的知识,这些信息由DBMS收集的统计信息提供。查询表示模块进一步利用节点属性生成节点表示。
-
LOGER对每个表使用table-level learned embedding vector
,将表的知识集成到node representation中。例如,表A的learned embedding vector表示为
。对
-
LOGER为每一列使用大小为13的column-level statistic vector
来利用列的统计信息,其中包含:(1) 列的值类型,描述为3-bit one-hot vector,分别表示整数、浮点数和非数字;(2) 唯一值的比例,用3 bits表示区间[0,0.001)、[0.001,0.999]和(0.999,1];(3) 根据收集到的统计数据预测唯一值计数是否会增加,描述为2 bits表示true或false;(4) 空值的比例,用3 bits表示区间[0,0.001)、[0.001,0.999]和(0.999,1];(5) 列是否有索引,用2 bits表示。
-
LOGER对查询中涉及的每个列使用column-level predicate vector
来表示谓词信息。每个
,
,
]。我们取列A.a1的表示
= [
,
,
] (公式如下),其中
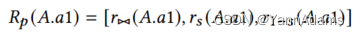
表示该列上的单表谓词的选择性。如果不存在这样的谓词,则将
设置为0。否则,
被设置为选择性的负对数,目的是区分差异。例如,两个谓词的选择性分别为
和
,它们的值很接近,但是两个谓词应用于表的结果却有10倍的差异。通过采用对数,这些小数值可以被模型清楚地识别出来。假设谓词的选择性A.𝑥1 >= 100为0.1,则
的取值如下:
= − ln Sel[𝐴.𝑥1 >= 100] = − ln 0.1 ≈ 2.30 (公式如下)。
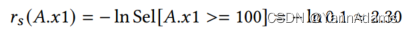
表示列上逆谓词的选择性,其目的是在处理大值时降低负对数的敏感性问题。在上面的例子中,通过A.𝑥1 < 100的选择性来计算出
的值:
= −ln Sel[𝐴.𝑥1 < 100] = −ln 0.9 ≈ 0.11(公式如下)。
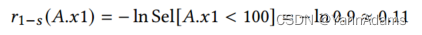
LOGER利用DBMS基数估计器的近似值来估计每个谓词的选择性,因为精确的选择性是不实际的。当一个列上有多个单表谓词时,LOGER只使用选择性最小的谓词,并丢弃其他谓词,以避免由于分布假设而导致的低估。对于上述对数的计算,所有输入值都被限制在的下界。
3.2 Query Representation Module
查询表示模块为连接图中的节点生成向量化表示,这些向量化表示被用于计划生成。
-
Initial representation
在得到表级嵌入向量、列级谓词向量
和统计向量
后,查询表示模块将它们组合得到初始节点表示
。对每个表不同的矩阵
被学习来结合
和
= [
,
,
] 变成列表示
,遵循下面的方程,其中
,
和 𝑏 是学习矩阵和向量。
是将中间结果分割成大小相同的三个向量
、
、
。
= [
||
||
] (公式如下),
= [
||
||
] (公式如下)。
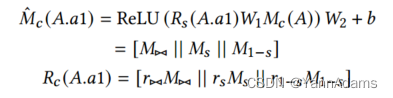
查询表示模块通过对列表示应用池化来形成每个表的列级表示。我们使用最大池化是因为选择性较小的谓词(具有较高的)应该比较大的谓词更受关注。考虑图2(a)中的示例,列级表示
是由
,
,
和
聚合在一起。然后计算初始节点表示
,其中
为学习矩阵,
= MaxPooling{
,
,
,
} (公式如下),
= ([
||
])
(公式如下)。
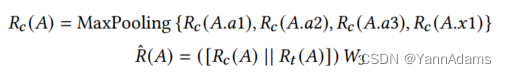
- Final representation
为了沿着图结构交换table node representations中的信息,查询表示模块将Graph Transformer[5]应用于连接图,如图2(c)所示。利用Transformer[25]的注意机制和Laplacian positional encodings,GT不仅有效地捕获了包含表信息和谓词信息的table representations之间的关系,而且将连接图的全局结构信息集成到table representations中。
将连接图连同初始节点表示作为输入,由GT层计算查询中所有表的最终表示
,然后由值模型用于计划搜索期间的延迟预测。
计划搜索
在本节中,我们介绍了ROSS的思想,解释了使用值模型评估state-action pair候选计划的方法,并描述了LOGER如何通过𝜖-beam search自适应探索和利用来执行高效搜索。
4.1 Restricted Operator Search Space
LOGER利用DBMS优化器的知识来提高计划生成的鲁棒性。正如以前的各种工作[12,16,28]所采用的那样,计划搜索空间既包含连接顺序也包含物理算子。在这样的空间中,物理算子完全依赖于学习优化器进行选择,这有可能获得有效的计划,但也有很大的风险产生不良的计划。
因此,我们对其进行了重组,提出了限制算子搜索空间(Restricted Operator Search Space,ROSS),其中学习优化器在每一步中选择连接顺序和限制算子,物理算子由限制算子和DBMS优化器的选择共同确定,以降低不良计划的风险。在LOGER中,ROSS允许四种类型的限制算子来禁止特定的物理算子选择:
-
no restriction(
)
-
no nested loop join(
)
-
no merge join(
)
-
no hash join(
)
相应地,直接选择物理算子的搜索空间称为直接算子搜索空间(Direct Operator search space, DOSS)。
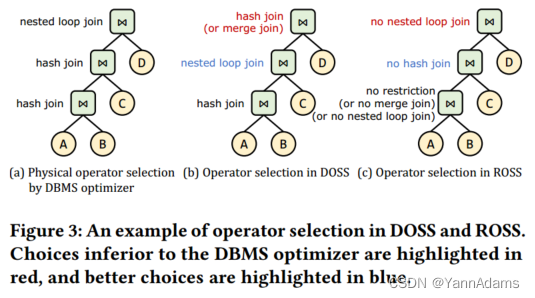
图3显示了两个搜索空间中算子选择的示例,从中我们可以发现,当DBMS优化器选择最优物理算子时,限制算子降低了高效计划搜索的难度。图3(b)中的示例显示,在DOSS中,必须精确指定物理算子,才能获得与DBMS优化器相同或更高的性能。在三个选项中选择最佳算子的难度可能会导致失败,从而导致糟糕的性能。相比之下,当DBMS优化器的选择正确时,LOGER只需要在ROSS中的4个选项中选择3个。此外,通过禁用特定的物理算子,ROSS保留了选择比DBMS优化器更好的算子的可能性。图3(c)显示,在第一步从三个选项中进行选择的效率是一样的,这显然更容易学习。在第二步中,可以选择一个禁止DBMS优化器使用哈希连接的算子来实现更好的计划。
4.2 Value Model for State-Action Evaluation
值模型通过预测可到达的最低延迟,即从(𝑆, 𝑎)到达所有计划中的最低延迟,来评估子计划𝑆的state-action pair候选(𝑆, 𝑎),下面表示为C(𝑆, 𝑎)。子计划的信息包括连接顺序和算子,它们共同决定性能。因此,LOGER分别获得连接顺序和算子的表示,为值模型提供输入。
-
Candidate generation
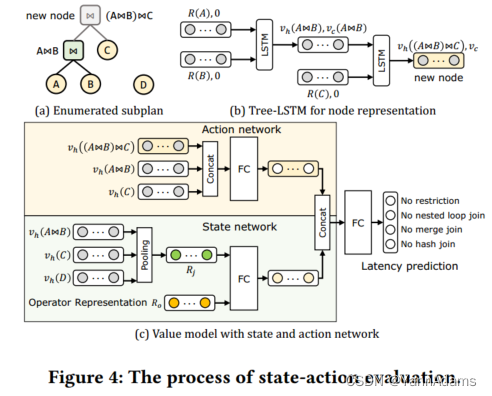
每个状态S=(𝐽, 𝑂)的state-action pair候选(𝑆, 𝑎)是通过枚举所有可能的连接生成的。在此过程中,我们采用System R[22]的策略,当 𝐽 中存在两棵可以执行条件连接的连接树时,可以避免笛卡尔积(Cartesian products)。图4(a)显示了一个候选的例子,其中列举了两棵树A⋈B和C的连接。然后通过以下程序对这些候选进行评估。
-
Join order representation
LOGER受到RTOS[29]的启发,利用Tree-LSTM[24]对每个计划𝑆=(𝐽, 𝑂)进行向量化连接顺序 𝐽。作为LSTM[6]的变体,Tree-LSTM适用于树状结构的数据,以捕获自下而上的顺序信息。对于 𝐽 中的每个连接树,我们使用查询表示模块产生的最终表示作为叶节点的hidden向量
,并将叶节点的cell向量
设置为0。我们应用N-ary Tree-LSTM计算树中分支节点的hidden向量和cell向量。在图4(b)所示的示例中,节点(A⋈B)⋈C的hidden向量和cell向量的计算如下:[
((A⋈B)⋈C),
((A⋈B)⋈C)] = TreeLSTM( [
(A⋈B),
(A⋈B)], [𝑅(𝐶), 0]) (公式如下)。
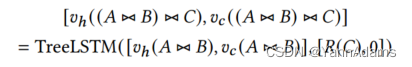
-
Operator representation
operator representation 是查询中涉及的所有表上的operator representations的组合。每个表都有一个列表的四个学习嵌入向量
=[
,
,
,
],representing operator分别是
,
,
和
。当连接表时,根据使用的限制算子从
中选择其operator representation。
例如,当表A通过算子与表B连接时,将
作为表A的operator representation
。对于未确定限制算子的表,将其
设置为0。子计划𝑆=(𝐽, 𝑂)的operator representation
是查询中所有表(表示为集合T)的平均值
。
= 1 /|T| ∑︂
(𝜏) (公式如下)。
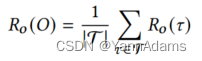
-
State-action pair evaluation
值模型通过其所有枚举连接预测每个状态𝑆的延迟值。如图4(c)所示,该值模型包括两个子网络:动作网络和状态网络。状态网络处理关于子计划𝑆的信息,动作网络将枚举连接的信息作为输入。将两个子网络的输出结合起来,为共享相同连接但具有不同限制算子的所有四个动作𝑎产生预测C(𝑆, 𝑎)。
状态网络的输入包括连接树集合 𝐽 中所有根节点的hidden向量,以及operator representation 。通过均值池化,将根节点表示聚合为连接表示向量
。对于上面的例子,
由下式得到,
= 1/ |J| ∑︂ (
(𝜏)) = 1/3 (
(𝐴⋈𝐵) +
(𝐶) +
(𝐷)) (公式如下)。
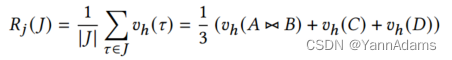
对于动作网络的输入,LOGER计算由枚举连接指定的生成的新节点的hidden向量。
以图4(c)所示的案例为例,当𝐴⋈𝐵和C被连接在一起时,(𝐴⋈𝐵)⋈C的hidden向量被计算。然后将新的hidden向量与两个连接节点的一起输入到动作网络中。值模型通过一个全连接(FC)层将状态网络和动作网络的输出结合起来,生成一个大小为4的向量,每个元素表示为(𝑆, 𝑎) 对一个具有特定限制算子的动作𝑎。
4.3 𝜖-Beam Search with Adaptive Exploration
从没有表连接的初始子计划开始,LOGER在ROSS中逐步生成计划,并对值模型进行预测。为了在广阔的搜索空间中选择有前景的子计划,我们提出了𝜖-beam搜索,一种具有自适应探索的波束搜索变体。经典算法包括𝜖-greedy[26]、UCB[2]、Boltzmann探索[9]和Thompson抽样[20],它们都执行线性搜索,只保留一条搜索路径,表示为顺序选择的状态-动作对的列表[(,
), (
,
), …]。
相比之下,波束搜索同时在多条路径上进行搜索,以寻求全局更好的结果。此外,为了引入探索,𝜖-beam搜索遵循𝜖-greedy算法的思想进行随机选择,并在值模型的指导下选择潜在的动作。此外,我们还采用了一种自适应方法来平衡探索和利用。
-
Combination of beam search and 𝝐-greedy
𝜖-beam search保留每一步上的𝐾条搜索路径,其中𝐾是一个常量。搜索路径分为探索路径(R-paths)和利用路径(T-paths)。R-paths是指通过随机选择至少获得一种状态的搜索路径,T-paths是指根据值模型的预测,始终通过选择最佳状态来获得搜索路径中的状态。在每一步之前,通过𝜖-beam搜索确定下一步保留的R-paths和T-paths的数量。至少保留一条R-path和一条T-path,其余𝐾−2条路径分别成为具有探索概率𝜖的R-path或者其它情况为T-path。也就是说,取R-paths数为,T-paths数为
,
遵循二项式分布 B(𝐾−2, 𝜖)。
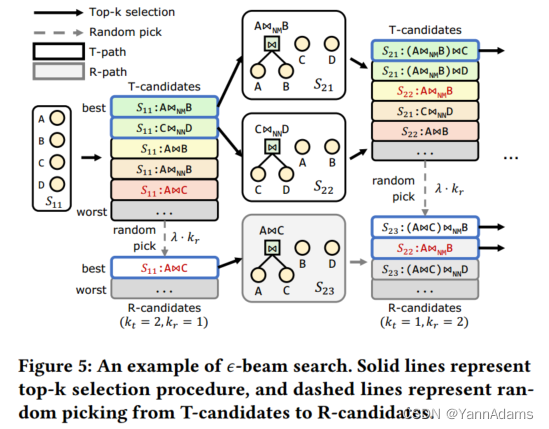
图5给出了一个𝜖-beam搜索的示例。确定和
后,𝜖-beam search将当前路径中所有枚举的state-action pair候选分类为R-candidates和T-candidates。T-candidates是来自当前T-paths的pairs,top
pairs被选为下一个T-paths。在这个例子中,
通过选择最好的2个candidates来生成下一个T-paths。R-candidates来自两个sources,包括从剩余的T-candidates中随机选择的
和来自当前R-paths的所有candidates,其中λ是常数因子。
和
在第二步生成T-candidates,在通过top-1选择确定一条T-path后,4个T-candidates与
生成的pairs随机放入R-candidates中。随后的R-paths由R-candidates的top-
选择决定。
这个例子展示了𝜖-beam搜索相对于𝜖-greedy和原始的光束搜索的优势。第二步的Top-选择对不同子计划
和
的candidates进行比较,提供了更广阔的搜索空间。相比之下,𝜖-greedy只对一个状态的candidates进行本地比较。此外,𝜖-beam search通过选择预测的最佳R-candidates来选择探索路径,而不是𝜖-greedy中的随机决策,这保证了LOGER在极大的空间中探索有前景的计划。当R-paths个数
= 0时,原光束搜索等价于𝜖-beam搜索,收敛后总是选择相同的路径。
-
Adaptive exploration with probability adjustment
为了在探索和利用之间取得平衡,且为了充分探索搜索空间,一开始的探索概率应该很大,在训练过程中逐渐减小。此外,不同的查询需要不同的探索概率。当查询优化得很差且相对延迟很大时,需要进行更多的探索,直到达到良好的性能。增加对执行时间较长的查询的探索也有助于提高工作负载的吞吐量。LOGER对𝜖使用衰减周期。
从一个初始值开始,在对
个查询生成计划后,𝜖和一个恒定的终值
之间的距离减小了一半。同时,在工作负载Q中的每个查询
的值
根据一个随性能变化的值
增大。公式如下,其中𝑛是训练期间迭代查询的次数。
= (公式如下),
= (公式如下),
= (公式如下) 。
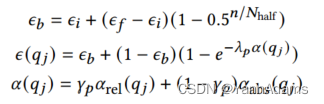
参数𝛼的值由和
两部分组成。
表示与DBMS优化器相比,LOGER生成的计划是否相对较差,得到过程如下,其中
为
的相对延迟,
为
的几何平均值。
= 公式,
= max{
−
, 0} 公式。
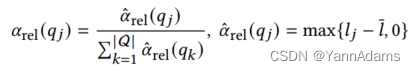
通过LOGER生成的计划显示
是否是执行时间最长的查询之一。如果
是某个比率
内最慢的查询之一,则设置为1/⌈
⌉ ,否则设置为0。
我们设置𝐾=4,𝜆= 2,=0.8,
=0.2,
=200,
=0.5,
=0.125和
=0.6 在我们的实验中。在测试期间,通过设置
=0禁用探索以稳定性能。
模型训练
在本节中,我们首先介绍了经验数据集(experience dataset),即存储执行的奖励的数据结构,然后描述了LOGER的损失函数,该函数通过奖励加权(reward weighting)和对数变换(log transformation)来分别减少由于糟糕的算子造成的变化和处理灾难性计划的奖励。
5.1 Experience Dataset
LOGER训练值模型来预测每个state-action pair (𝑆, 𝑎)的可达最低延迟值C(𝑆, 𝑎)。由于获取真实的C(𝑆, 𝑎)是一个昂贵的过程,需要耗尽搜索空间,因此LOGER将达到的最低延迟𝑇(𝑆, 𝑎)作为C(𝑆, 𝑎)的近似值存储到经验数据集中。当从DBMS引擎获得延迟值𝑙时,更新相应搜索路径中所有state-action pairs的𝑇(𝑆, 𝑎),并在每次迭代后使用存储的值来训练agent。将𝑆表示为(𝐽, 𝑂),当旧值𝑇((𝐽, 𝑂), 𝑎)不存在时,将该值初始化为𝑙。否则,只有当𝑙小于原值时,才会更新𝑇((𝐽, 𝑂), 𝑎),如公式(1)所示。𝑇((𝐽, 𝑂), 𝑎) := min{𝑇((𝐽, 𝑂), 𝑎), 𝑙 } 公式1。
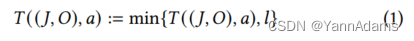
为了在损失函数中执行奖励加权,还通过公式(1)更新另一个表值𝑇((𝐽, /), 𝑎),其中将算子信息𝑂替换为占位符。𝑇((𝐽, /), 𝑎)代表所有记录对((𝐽, 𝑂’), 𝑎)的最小延迟,记录对具有相同的连接顺序𝑆=(𝐽, 𝑂),命名为operator-irrelevant latency。表项((𝐽, 𝑂), 𝑎)的值相应地称为operator-relevant latency。
经验数据集中的数据不直接采样用于训练。根据Deep Q-learning[18]的设置,LOGER保留了一个重放内存,这是一个容量有限的队列,用于存储搜索过程中发现的state-action pairs (𝑆, 𝑎)。在训练过程中,从队列中采样小批量的state-action pairs,其ground truth values从𝑇获得。我们在训练时将容量设置为4000。当超过容量时,头部项被丢弃,为新项腾出空间。
DRL方法通常面临冷启动问题,这是由于最初对选择高质量动作的知识不足,需要通过有效的策略来缓解[4]。LOGER将DBMS优化器作为专家模型引入初始知识,为训练工作负载中的每个查询生成计划,并在训练开始时将相应的state-action pairs存储到经验数据集中。然后从队列中抽取这些经验,用专家知识训练LOGER。
5.2 Reward Weighting Loss with Log Transformation
由于执行延迟很大程度上受到连接顺序和算子的影响,因此直接学习预测达到的最低延迟𝑇(𝑆,𝑎)可能非常困难,从而导致鲁棒计划生成方面的问题。我们在下面详细列出两个主要困难。
-
首先,低效的计划会导致灾难性的延迟值,这对模型训练造成很大的干扰。间隔(0, 1)内的相对延迟值表明该计划优于DBMS优化器的计划。然而,不适当的计划可能会在[1, +∞)范围内产生较大的相对延迟。这种计划导致延迟值在很大范围内分散,显著增加了值预测的难度。
-
其次,连接顺序和物理算子之间的相互影响使得延迟变化很大。因此,先前在子计划中选择的不良操作会影响后续动作选择的学习。考虑一个例子,其中两个表的A和B被连接在一起,在子计划
中有一个有效的算子,在
中有一个较差的算子。虽然类似的子计划
为了解决上述值预测的困难,我们提出了一个带有奖励加权和对数变换的损失函数,通过该函数将相对延迟时间转换为一个方差小得多的值。设𝜃代表LOGER所有可学习的参数。对于值模型的输出𝑄(𝑆, 𝑎; 𝜃),LOGER使用以下损失函数𝐿(𝜃),下面将解释。
-
𝑦 = LT(RW(𝑆, 𝑎))
-
RW((𝐽, 𝑂), 𝑎) = 𝑤𝑇((𝐽, 𝑂), 𝑎) + (1 − 𝑤)𝑇( (𝐽, /), 𝑎) 公式2
-
LT(𝑥) = ln(2 + ln𝑥),当𝑥 ≥ 1;ln(1 + 𝑥) ,当0 ≤ 𝑥 < 1 公式3
-
𝐿(𝜃) = (𝑄(𝑆, 𝑎; 𝜃) − 𝑦) ^ {2}
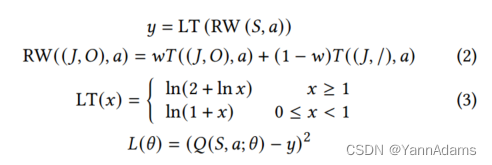
-
Reward weighting
为了减少不良算子在状态𝑆=(𝐽, 𝑂)评估后续动作𝑎的影响,我们通过权重因子𝑤结合operator-relevant 延迟 𝑇((𝐽, 𝑂), 𝑎)和operator-irrelevant 延迟𝑇((𝐽, /), 𝑎),如公式(2)所示。weighted value作为ground truth value,而不是直接使用𝑇((𝐽, 𝑂), 𝑎)。奖励权重通过减少先前算子的影响来稳定评估并防止对动作𝑎的低估,其稳定值𝑇((𝐽, /), 𝑎)与算子信息𝑂无关。通过加权,即使𝑆中的不良算子因为一个较高的𝑇((𝐽, 𝑂), 𝑎)导致不好的性能,一个正确的动作𝑎的评估不会很大程度上受到影响,因为影响的减少是通过将𝑇((𝐽, /), 𝑎)添加到考虑中。
奖励加权也鼓励LOGER优先于算子寻找更好的连接顺序,但缺点是会选择次优计划。我们设置𝑤= 0.1来平衡这个权衡。我们将通过实验进一步证明其有效性。
-
Log transformation
为了减少灾难性计划的影响,将公式(3)中的对数变换函数LT(·)应用于加权奖励值。LT(·)的关键点是压缩分散的差奖励值,以降低模型对它们的敏感性,使LOGER更专注于区分更好的计划。对于优于基线的计划,LT(·)将值映射到区间(0, 0.69)。同时,它显著压缩了较差计划的值范围。例如,分散在很长范围内(1, 100)的差计划的值被映射到一个更小的区间(0.69,1.89)。
实验
在本节中,我们详细描述了我们的实验设置,展示了LOGER和其他竞争对手的结果,并通过消融研究展示了组件的有效性。
6.1 Experiment Setup
-
Datasets and workloads
三种不同的数据集:IMDB上的Join Order Benchmark[13]、TPC-DS[19]和Stack Overflow[15]。
-
Database and environment settings
PostgreSQL 13.5配置64GB共享缓冲区,我们禁用GEQO,并应用pg_hint_plan插件为PostgreSQL的查询优化器实现ROSS启用提示。
我们使用Python 3.8和Pytorch 1.8.0实现LOGER,并在Ubuntu 20.04服务器上运行实验,该服务器具有两个Intel(R) Xeon(R) Gold 2.30GHz CPU, 256GB内存和NVIDIA RTX 3090 GPU。
-
Training configuration
在每个实验中,我们对LOGER进行了200次训练工作负载的训练。
在训练过程中,我们使用Adam优化器,初始学习率为3 × ,在第50和第100 epoch之间逐渐降低到3 ×
,直到第200 epoch为3 ×
。
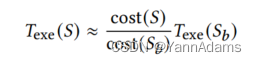
-
Metrics
我们使用两个主要指标来评估性能。
-
Workload relative latency (WRL)
-
Geometric mean relative latency (GMRL) [29]
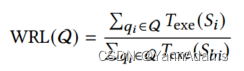
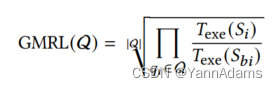
-
Comparison
我们将LOGER与以下最先进的学习查询优化器进行比较,并使用下面表示为PG-NoMerge的简单基线。
-
PG-NoMerge
-
RTOS [29]
-
Bao [15]
-
Balsa [28]
-
Experimental design
我们演示了LOGER在PostgreSQL和CommDB上的性能,分析了它的单查询加速和尾部性能,并在WRL、GMRL、训练时间和平均推理时间方面与以前的方法进行了比较。实验还分析了增量训练对更新后schema的泛化效果。
此外,我们通过消融研究验证了组件和设计选择的影响,包括(1) 𝜖-beam搜索算法,(2) ROSS,(3) 查询表示模块中的GT层和池化方法,(4) 奖励加权和对数变换,(5) 经验数据集中的专家知识,(6) 左深约束。通过这一过程,我们分析了对冷启动能力、训练稳定性和最终性能的影响。
6.2 Overall Performance and Comparison
-
Performance overview
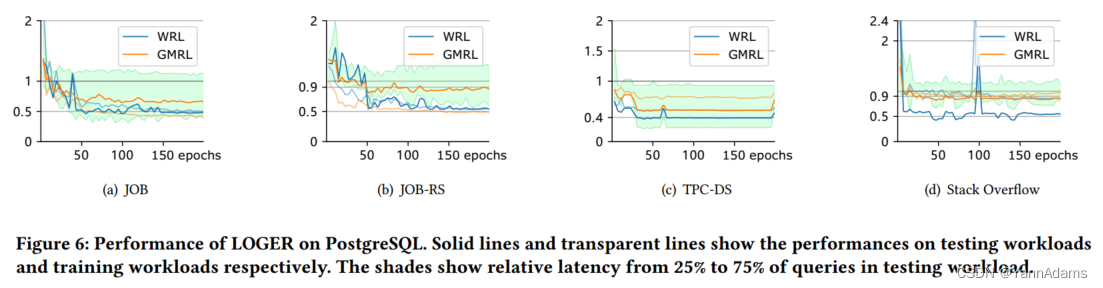
图6显示了PostgreSQL在不同工作负载下的性能,从图中我们可以看到,LOGER的性能很快超过了PostgreSQL的优化器,最终在JOB、TPC-DS和Stack上都达到了很高的性能。
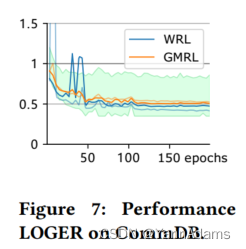
为了验证LOGER是否可以泛化到不同的数据库系统,我们在CommDB上的JOB工作负载上进行了测试,如图7所示,从中我们可以发现,LOGER也很快达到了比CommDB的优化器更好的性能。
-
Workload latency analysis
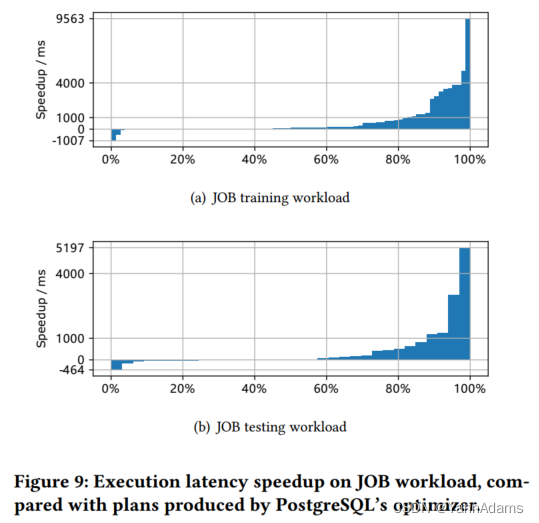
一个健壮的学习查询优化器不仅应该为大多数查询生成有效的计划,还应该确保良好的尾部性能,即为优化最差的查询提供良好的性能。LOGER在JOB训练工作负载上的总执行延迟加速为52.96秒,在测试工作负载上的总执行延迟加速为13.25秒。图9显示了JOB上的执行延迟分布。
-
Performance on a changed schema
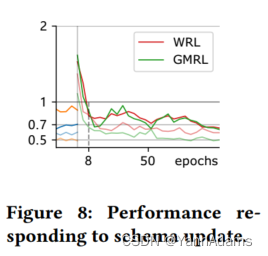
LOGER被设计为能够通过增量训练来响应模式更改。图8中的红色和绿色曲线显示了LOGER在响应模式更新时对char_name的所有查询的性能。
最初,LOGER没有关于新表的信息,必须利用其他表的信息来为新查询选择计划。经过8个epoch的增量训练,LOGER在新查询上的表现优于PostgreSQL,最终在训练和测试工作复负载上达到收敛。
-
Comparison with other methods
我们将LOGER与PG-NoMerge、RTOS[29]、Bao[15]和Balsa[28]在每个工作负载上进行比较。
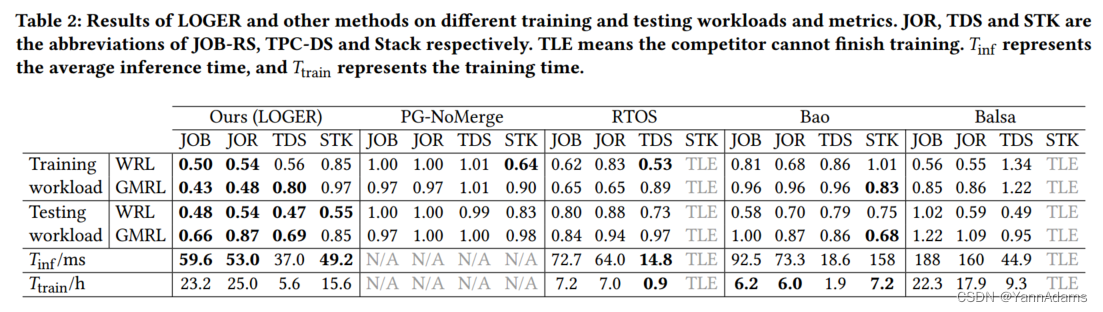
表2给出了各方法的WRL、GMRL、平均推理时间和训练时间
,从中可以看出,在训练和推理时间合理的情况下,LOGER在所有工作负载上都具有很强的竞争力。
6.3 Ablation Study
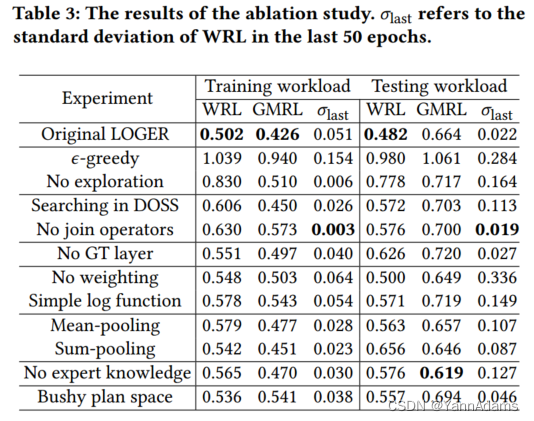
通过下面的实验,我们分析了LOGER的设计选择,如表3所示。我们单独使用替代方案来替换每个组件,并在JOB工作负载上测试LOGER。
-
Effect of 𝜖-beam search
由于𝜖-beam搜索采用了𝜖-greedy算法的思想,我们分析了引入𝜖-greedy思想的优势以及相对于𝜖-greedy的优势。结果表明,𝜖-beam搜索在性能和训练稳定性上都明显优于𝜖-greedy和没有探索的原始波束搜索。
-
Effect of ROSS
ROSS平衡了完全依赖DBMS优化器和学习选择物理算子之间的关系。在依赖DBMS优化器选择算子的情况下,我们做了在DOSS中搜索和只选择连接顺序的实验。使用ROSS的LOGER在测试工作负载上达到了最好的性能,其它两者都不如ROSS。
-
Effect of GT layer for query representation
GT的功能是捕获表和谓词之间的关系,以及连接图到table representations中的结构信息。
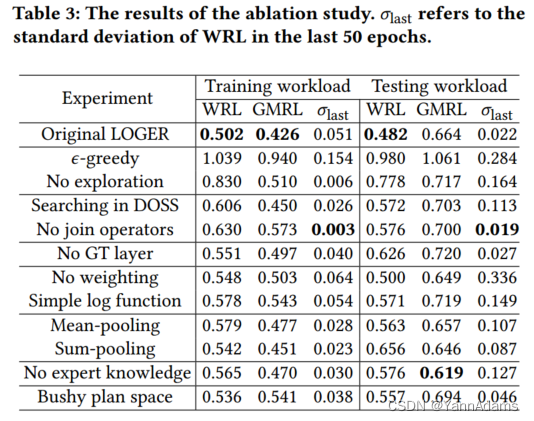
在实验中,我们抛弃了GT,直接使用表的初始表示作为最终表示𝑅。从表3可以看出,如果没有GT,查询表示模块将无法捕获足够的信息,从而导致测试工作负载的泛化效果变差。
-
Effect of reward weighting and log transformation
对于奖励加权实验,我们将权重因子𝑤设置为1,表示只使用与算子相关的延迟。这样的修改导致WRL变差,但GMRL略好。
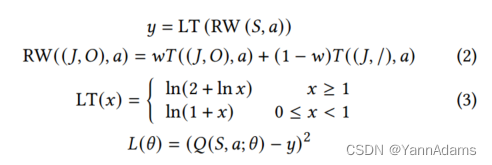
我们还通过将公式(3)中的对数变换函数LT替换为简单的log(x+1)函数来检验其效果。对数变换有助于稳定性能,而简单的对数函数无法处理灾难性的奖励值,导致性能较低且不稳定。
-
Effect of other alternatives on model performance.
查询表示模块通过最大池化聚合列级信息。我们分别用均值池化和和求和池化来测试其合理性。在测试工作负载上可以看到,与替代方案相比,最大池化实现了更好的WRL和最稳定的性能,但GMRL略差。
为了测试引入专家知识的有效性,我们禁用了具有专家计划的经验数据集的初始化。原始LOGER具有更高的GMRL,但WRL和比备选方案要好得多。尽管专家知识可能会导致某些查询的次优计划,但它使LOGER能够在最初避免不良计划,从而显着提高训练稳定性。
我们还对没有左深限制的JOB进行了实验,发现测试工作负载下的性能有所下降。在密集的计划空间中搜索,找到更好的计划的可能性更高,但也会显著扩大空间,使得寻找有效计划的难度加大,最终导致JOB性能下降。
-
An overall analysis of cold-start ability and training stability
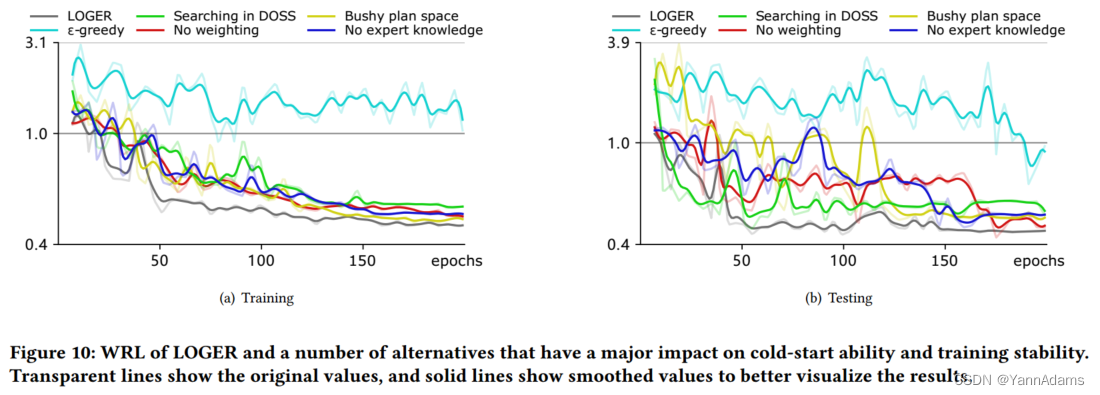
图10显示了使用了许多不同的替代方案时WRL随时间的变化,这些替代方案对冷启动能力和训练稳定性有重大影响。
相关工作
-
Learned query optimizers
近年来,人们提出了各种各样的学习查询优化器。
-
ReJOIN[17]提供了一种使用强化学习选择连接顺序的思路。ReJOIN不考虑物理算子的选择,而是依赖于DBMS优化器的算子选择算法
-
DQ[12]进一步提出了一种通过值模型预测每个子计划的估计成本,并通过使用实际执行延迟对模型进行微调的想法。
-
为了解决ReJOIN和DQ中使用的平面向量子计划表示造成的歧义问题,RTOS[29]使用了树结构表示,并通过Tree-LSTM[24]进行了向量化。与ReJOIN类似,RTOS只关注连接顺序的选择,这对性能造成了限制。
-
Neo[16]展示了用学习优化器代替传统优化器用于SPJ查询的可能性。Neo通过训练由专家优化器生成的计划来初始化模型,并对其进行微调,以获得选择连接顺序和物理算子的查询优化器。
-
Balsa[28]使用一个简单的模拟器来代替Neo中的专家优化器,并采用各种其他策略来完全避免对传统优化器的依赖。
-
Bao[15]建立在传统优化器的基础上,通过全局启用或禁用特定的物理算子来优化计划。虽然Bao实现了稳定的性能,但较小的搜索空间限制了它的性能,因为它依赖于传统的优化器来生成计划
我们的方法提出了一种想法,通过限制算子搜索空间来利用传统非学习优化器的知识,这与Bao[15]有类似的见解。我们的方法指定了连接顺序以及对每个连接的物理算子限制,因此搜索空间更大,更有可能包含有效的计划。
-
Deep learning for database
随着深度学习的巨大成功,数据库研究人员寻求将深度学习的进步应用到DBMS的不同组件中,并取得了有希望的结果。
之前的研究包括但不限于基于递归模型的学习索引[11]、基于GNN的实体解析[3]、基于多任务学习的基数估计[23]、基于强化学习的数据库调优[14]、基于强化学习的查询调优程序[21]等。这些方法的成功表明了将深度学习方法应用于数据库领域的巨大潜力。
-
Graph neural networks
图神经网络(GNN)是一种通过在图结构数据中嵌入特征来学习节点表示的网络,支持各种下游任务[27]。以Graph Convolutional Network[10]为先进方法,近年来出现了包括Graph Transformer[5]在内的许多变体。GT采用Transformer[25]对GNN的视角来捕捉相邻节点之间的关系,并通过位置编码将结构信息整合到每个节点表示中,从而在各种数据集上获得具有竞争力的性能[1,8]。在LOGER中,我们使用连接图来表示每个查询,并在其上应用GT来生成table representations。
总结
我们提出了LOGER,一个学习查询优化器,用于生成高效和鲁棒的计划。我们通过将GT应用于每个查询的连接图来提高representation expressiveness。我们引入ROSS来利用DBMS优化器的知识来减少搜索有效计划的困难,并提出𝜖-beam搜索来寻找潜在的更好的计划,同时自适应地平衡探索和利用。通过奖励加权和对数变换的损失函数进一步提高了鲁棒性。
实验表明,我们的方法在PostgreSQL和商业DBMS上都实现了极具竞争力的性能,且优于以前最先进的学习优化器,并且所有提出的组件对性能都有积极的影响。
我们计划在以下几个方面对LOGER进行扩展。我们将进一步研究资源感知或硬件感知的计划生成,以使LOGER适应不同的环境。还需要改进该方法以支持更复杂的谓词(如子查询)。此外,我们正在寻找一种使用更复杂的DRL技术来进一步提高鲁棒性和性能的方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









