







 GBase8a数据库采用流水线工作模式和client-server模型进行数据同步,确保并发处理和数据准确性。通过数据分片并行化、线程处理的pipeline模式以及work-group模式,有效提升同步效率。同时,提到了潜在的优化方案,如per-thread模式、无锁队列和RCU队列处理,以及可能引入协程进行优化。
GBase8a数据库采用流水线工作模式和client-server模型进行数据同步,确保并发处理和数据准确性。通过数据分片并行化、线程处理的pipeline模式以及work-group模式,有效提升同步效率。同时,提到了潜在的优化方案,如per-thread模式、无锁队列和RCU队列处理,以及可能引入协程进行优化。
数据同步在分布式数据库中是必不可少的角色。南大通用的gbse8a数据库产品,作为一款成熟的市场产品,其数据同步功能也是十分的完善,不管从功能还是性能上来说,都具有无可挑剔性。
下面就来简单说明一下gbase8a产品的数据同步原理。
大家知道,数据同步一个是功能上的一个是性能上的。即要做到又快又准确。
如果同步后的数据出现错误或者丢失那无意是失败的,同样如果数据同步是准确了,但是每次都得折腾很久,这也是不能忍受的。
言归正传,gbase8a产品的数据同步采用流水线的工作模式,结合client-server模型进行工作,既保证并发处理,有保证在同步过程中数据的校验准确。
但分片数据并行化
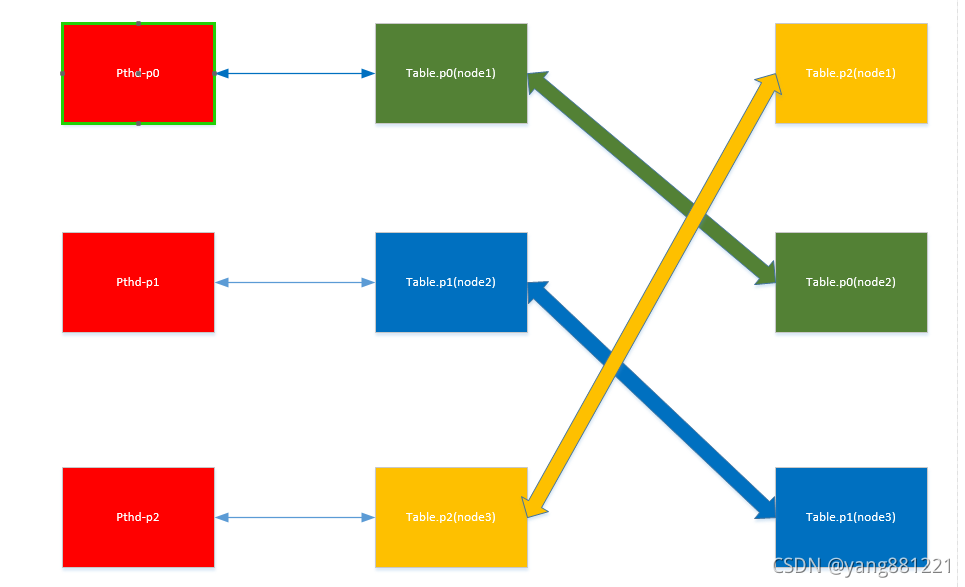
上图为同一个表的数据,不同数据分片的并行化。如果说一个表的数据有1g,分为3个分片到3各节点,那么并行化后,时间可以变为原来的1/3
多分片数据并行化
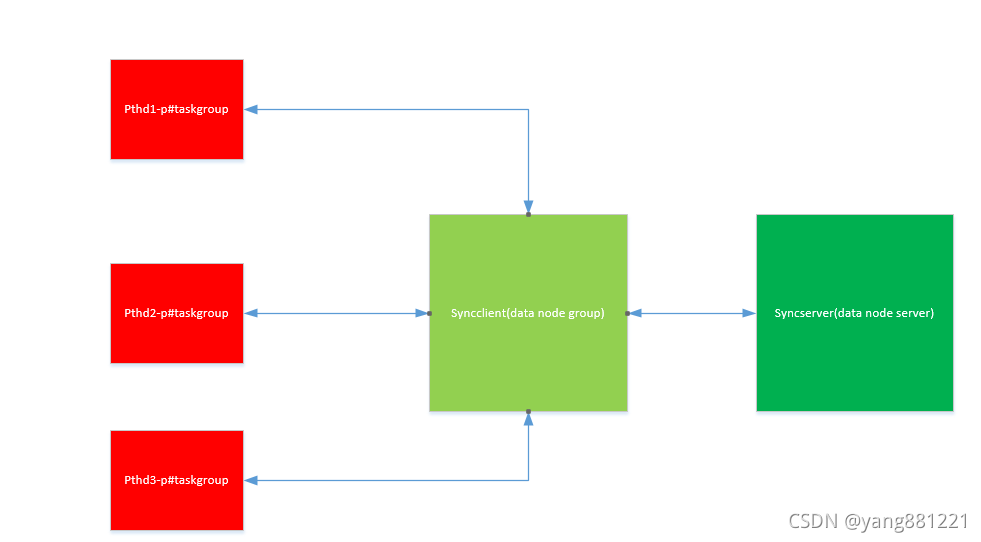
线程处理的piple line 模式
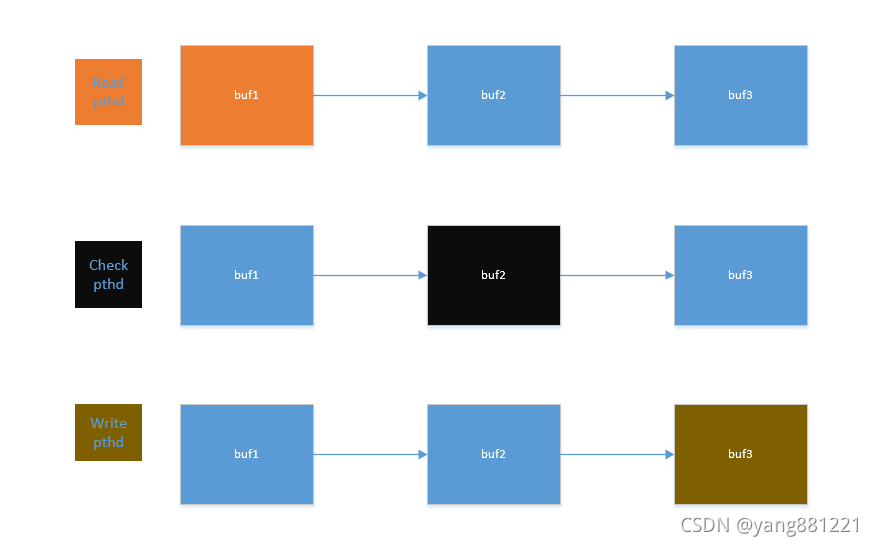
piple line模式可以充分利用多线程的处理能力,比如有的线程读取数据,有的线程校验读取的数据,有的线程写入正确的数据或者发送正确的数据。
由于各个线程和需要计算处理的量级可能会有差异,比如check较快,read较慢,这样就会造成有的线程一直忙有的线程一直闲
那么可以根据业务量使用不同的线程数量
piple+multi pthd模式
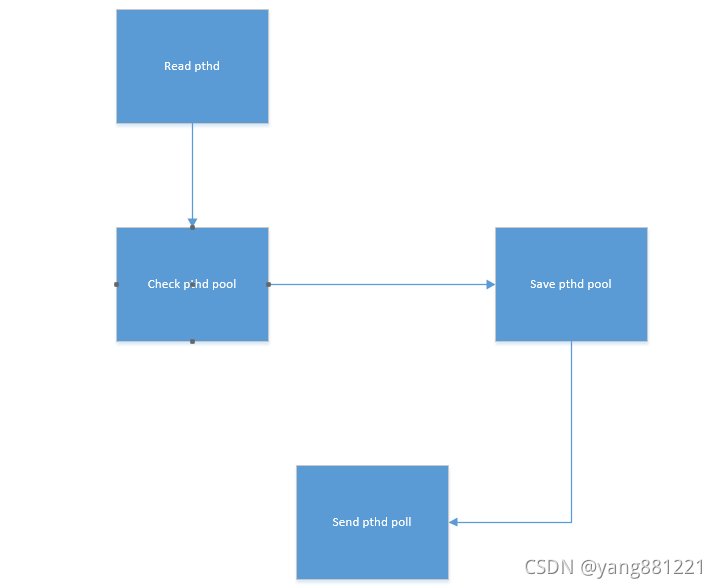
work -group模式:该模式下需要进行状态机的管理,但是这样可以以最少的线程数做最多的事情,但是缺点就是线程上下文会频繁切换
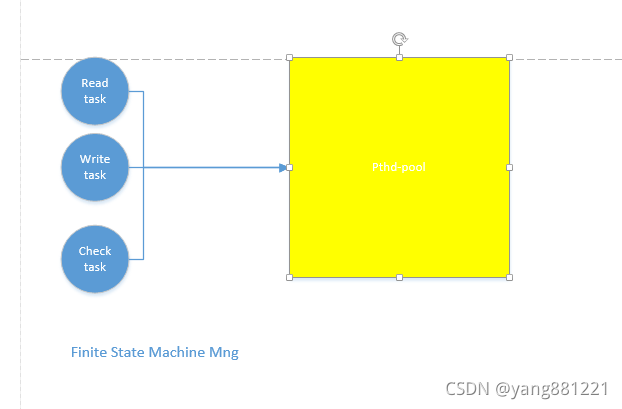
以上是目前gbase同步的具体原理。充分利用了并发和多核的思想进行处理。
当然后续还可以进行优化处理,比如perthd模式,无锁队列模式,RCU队列处理。或者引入协程进行处理。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









