[root@hadoop000 bin]# ./spark-submit --master local[2] --jars /root/app/spark-2.3.0-bin-2.6.0-cdh5.7.0/jars/elasticsearch-spark-20_2.11-6.3.0.jar /root/app/spark-2.3.0-bin-2.6.0-cdh5.7.0/python/spark008.py
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import udf
def get_grade(value):
if value <= 50 and value >= 0:
return "健康"
elif value <= 100:
return "中等"
elif value <= 150:
return "对敏感人群不健康"
elif value <= 200:
return "不健康"
elif value <= 300:
return "非常不健康"
elif value <= 500:
return "危险"
elif value > 500:
return "爆表"
else:
return None
if __name__ == '__main__':
spark = SparkSession.builder.appName("project").getOrCreate()
#能够自动推导
# df = spark.read.format("csv").option("header","true").option("inferSchema","true").option("delimiter",",").load("file:/
data2016 = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/data/Beijing_2016_HourlyPM25_created20170201.csv")
# data2016 = spark.read.format("csv").option("header","true").option("inferSchema","true").load("file:/
# data2015 = spark.read.format("csv").option("header","true").option("inferSchema","true").load("file:/
# data2017.show()
# data2016.show()
# data2015.show()
grade_function_udf = udf(get_grade,StringType())
# 进来一个Value,出去一个Grade
# group2017 = data2017.withColumn("Grade",grade_function_udf(data2017['Value'])).groupBy("Grade").count()
group2016 = data2016.withColumn("Grade",grade_function_udf(data2016['Value'])).groupBy("Grade").count()
# group2015 = data2015.withColumn("Grade",grade_function_udf(data2015['Value'])).groupBy("Grade").count()
# group2015.select("Grade", "count", group2015['count'] / data2015.count()).show()
#group2016.select("Grade", "count", group2016['count'] / data2016.count()).show()
# group2017.select("Grade", "count", group2017['count'] / data2017.count()).show()
#withColumn 列的值
result2016 = group2016.select("Grade", "count").withColumn("precent",group2016['count'] / data2016.count()*100)
# group2017.show()
#group2016.show()
# group2015.show()
#df.show()
# df.printSchema()
#列的名字改成小写的
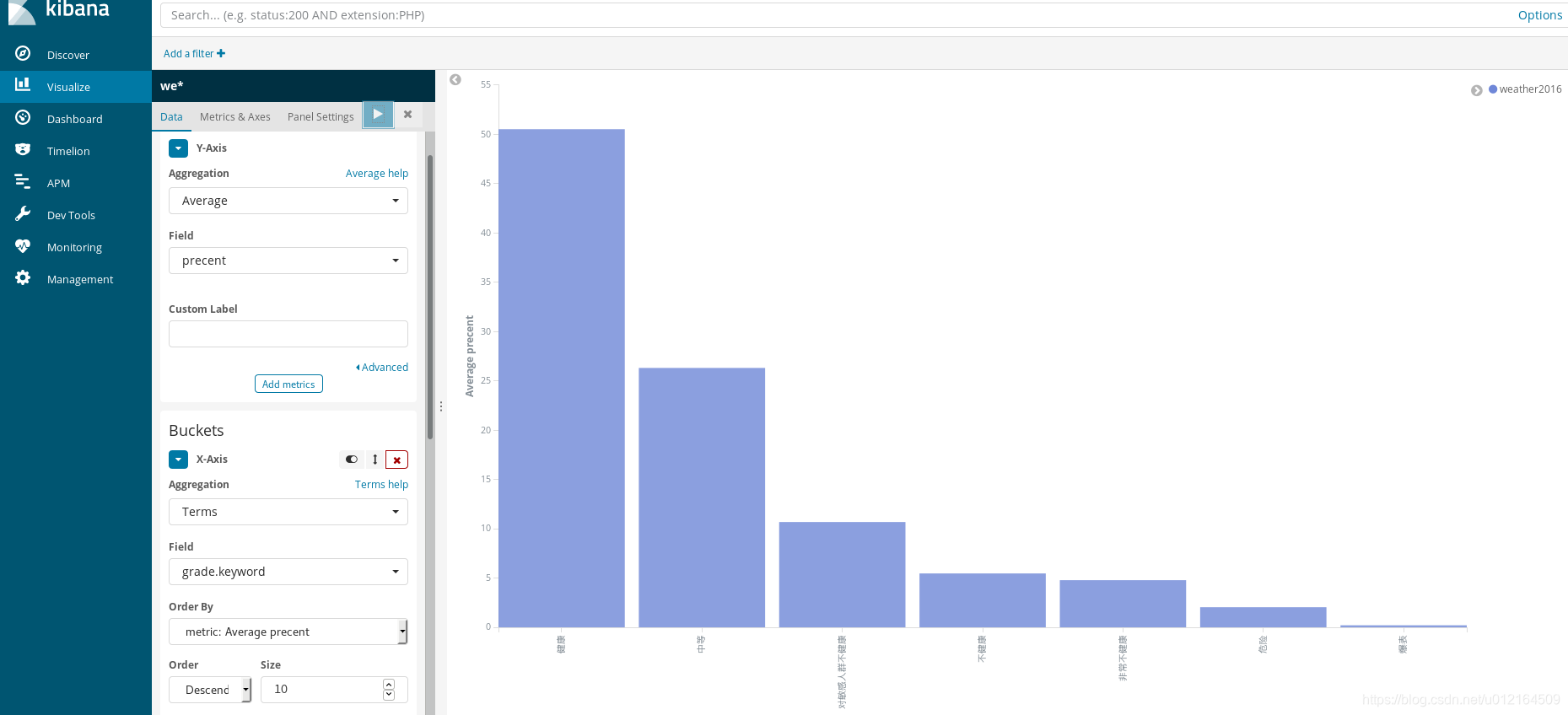
result2016.selectExpr("Grade as grade", "count", "precent").write.format("org.elasticsearch.spark.sql").option("es.nodes","192.168.194.151:9200").mode("overwrite").save("weather2016/pm")
spark.stop()



























 2862
2862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











