







Spark Core 进阶
- Spark 核心概念
- Spark运行架构及注意事项
- Spark和Hadoop重要概念区分
- Spark Cache详解
- Spark Lineage 详解
- Spark Dependency详解
192.168.00.00:4043/storage/rdd/?id=1
一、 核心概念
http://spark.apache.org/docs/latest/cluster-overview.html
Spark核心概述
Application: 基于Spark的应用程序 = 1driver + 多个executors
User program built on Spark
Consists of a driver program and executors on the cluster -----由群集上的驱动程序和执行程序组成。
这两个都是应用程序
-
spark0402.py
-
pyspark/spark-shell
Driver program —驱动程式
the process running the main() function of the application
creating the SparkContext —该进程运行应用程序的main()函数并创建SparkContextCluster manager
An external service for acquiring resources on the cluster --获取资源从集群上 比如说从(e.g standalone manager, Mesos, YARN)
spark-submit --master local[2]/spark://hadoop000:7077/yarn 这些就是集群的管理
Deploy mode
Distinguishes where the driver process runs
In “cluster” mode, the framework launches the driver inside of the cluster --在集群上
In “client” mode, the submitter launches the driver outside of the cluster --在本地上
部署方式 区分驱动程序进程的运行位置。在“集群”模式下,框架在集群内部启动驱动程序。在“客户端”模式下,提交者在群集外部启动驱动程序。
工作节点(work node): 这些节点运行你的应用程序在进群里面
standalone: slave节点 slaves配置文件
yarn: nodemanager
执行者: 进程,启动应用程序在work节点之上的,该进程运行任务并将数据存储在内存或磁盘存储中。每个应用程序都有自己的执行程序 executors运行的是tasks
任务: 一种工作单元,将发送给一个执行者
工作 : 甲并行计算由多个任务(例如save,collect); 您会在驱动程序的日志中看到该术语。
一个action对应一个job
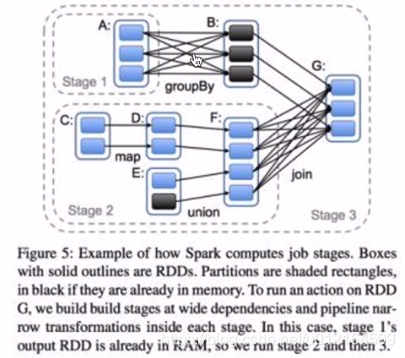
阶段: 每个作业都被分为一些较小的任务集,这些任务集称为相互依赖的阶段(类似于MapReduce中的map和reduce阶段);您会在驱动程序的日志中看到该术语。
一个stage的边界往往是从某一个地方取数据开始,到shuffle的结束
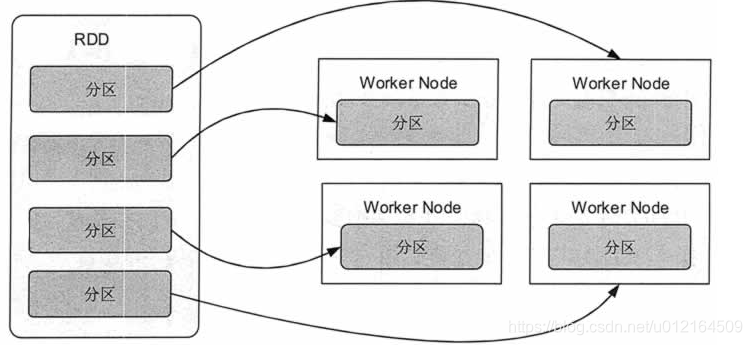
二、 RDD
RDD 的基本概念
RDD 是 Spark 它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。
可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
RDD 具有容错机制,并且只读不能修改,可以执行确定的转换操作创建新的 RDD。具体来讲,RDD 具有以下几个属性。
只读:不能修改,只能通过转换操作生成新的 RDD。
分布式:可以分布在多台机器上进行并行处理。
弹性:计算过程中内存不够时它会和磁盘进行数据交换。
基于内存:可以全部或部分缓存在内存中,在多次计算间重用。
RDD是什么,这有一篇文章
https://blog.youkuaiyun.com/dsdaasaaa/article/details/94181269
三、Spark 运行架构及注意事项
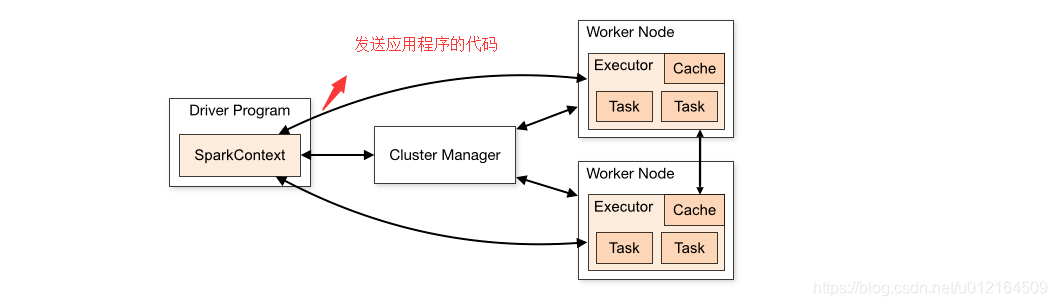
the SparkContext can connect to several types of cluster managers
cluster managers: 应用程序之间分配的资源
通过 cluster managers 去工作节点上申请到的
executors 运行在 Worker Node 之上的 ,它能运行task 能够存储缓存数据 ,发送应用程序的代码
Task 是多线程跑的
关于此体系结构,有几点有用的注意事项:
- 每个应用程序都有其自己独立的的执行程序进程,这些进程在整个应用生命周期一直存在,并在多个线程中运行任务。这样的好处是可以在调度方面(每个驱动程序调度自己独立的任务)和执行者方面(来自不同应用程序的任务在不同的JVM中运行)因为task有映射的,彼此隔离应用程序。但是,这也意味着,你的数据不能够共享跨不同应用程序,如果不将数据写入外部存储系统,则无法在不同的Spark应用程序(SparkContext实例)之间共享数据。
- Spark与基础群集管理器无关。只要它可以获取执行程序进程,并且它们彼此通信,即使在还支持其他应用程序
- 驱动(driver)程序,整个生命周期中必须侦听并接受其执行程序的传入连接(意思就是driver要和Executor通信) (例如,请参见网络配置部分中的spark.driver.port)。如果挂掉了,可以在另一个节点上在起一个executor运行的我们作业
- 由于驱动程序在群集上调度任务,因此应在工作节点附近运行(尽可能近点),最好在同一局域网上运行。如果您想将请求远程发送到集群,最好是将RPC打开到驱动程序,并让它在附近提交操作,而不是在远离工作节点的地方运行驱动程序。
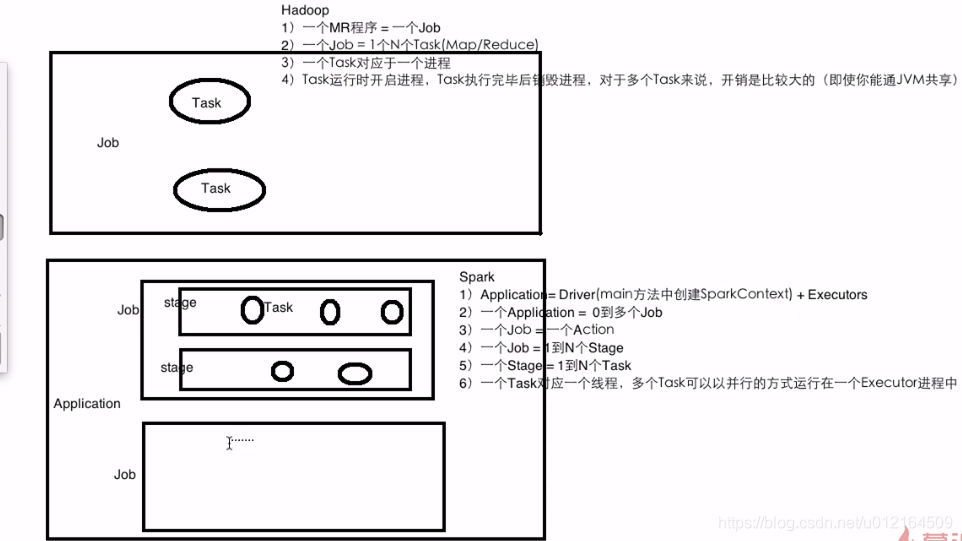
四、Spark 和Hadoop重要概念区分
Hadoop
- 一个MR程序 = 一个job
- 一个job = 1个N个Task(Map/Reduce) 进行
- 一个Task对应于一个进程
- Task运行时开启进程,Task执行完毕后销毁进程,对于多个Task来说,开销是比较大的(即使你能通JVM共享)
Spark
- Application = Driver(main)方法中创建SparkContext + Executors
- 一个Application = 0到多个job
- 一个Job = 一个Action
- 一个Job = 1到N个Stage
- 一个Stage = 1到N个Task Task是多线程
- 一个Task对应一个线程,多个Task可以以并行的方式运行在一个Executor进程中
五 Spark Cache 详解
http://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-persistence
启动


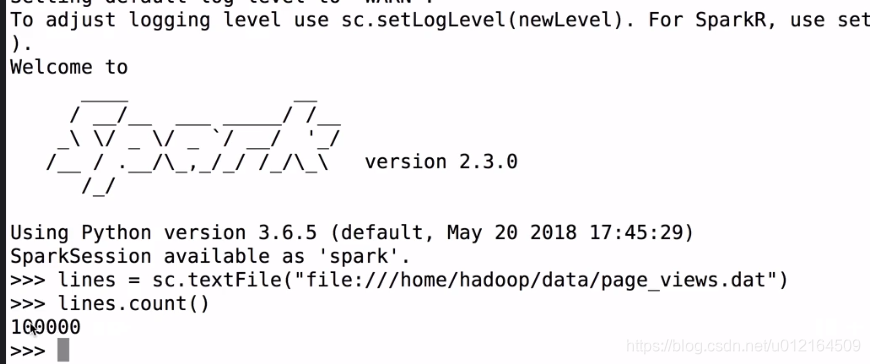
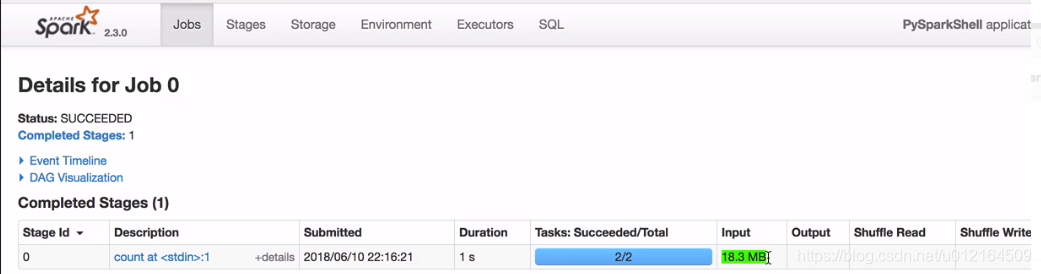
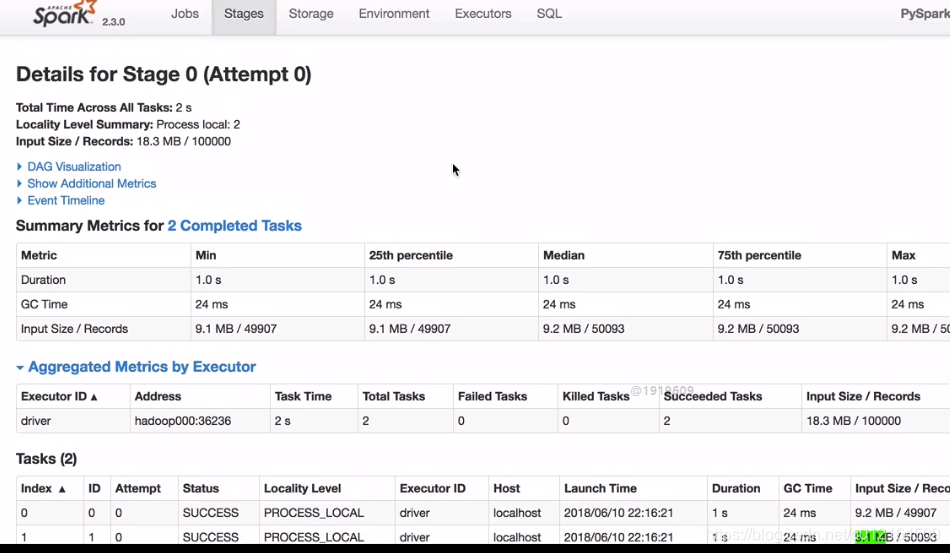


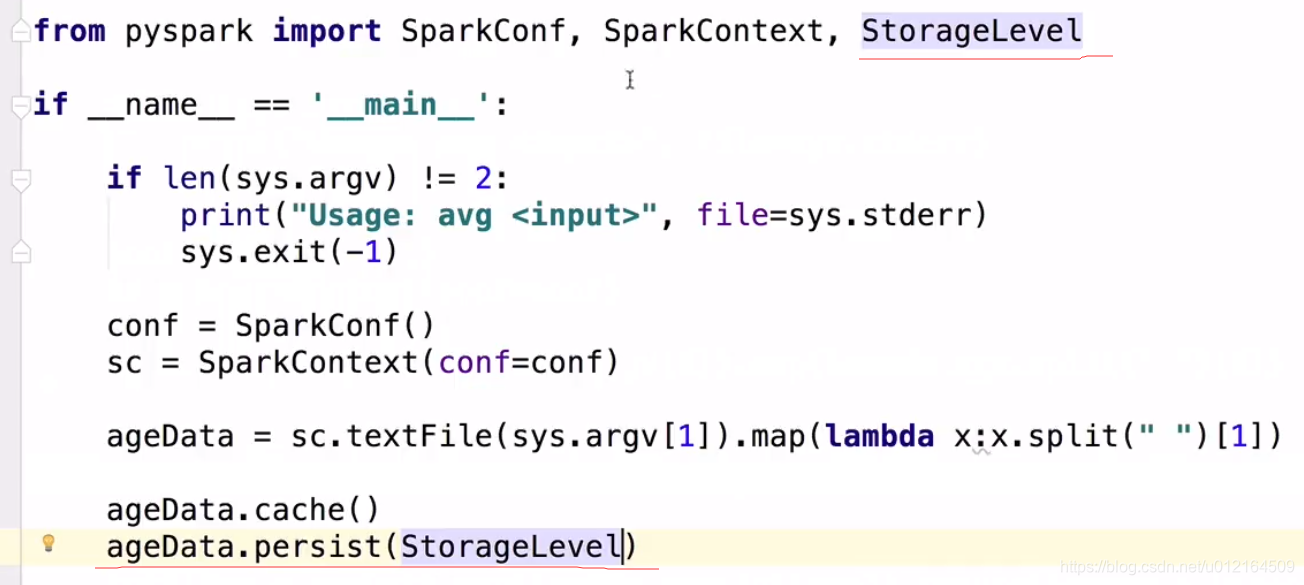
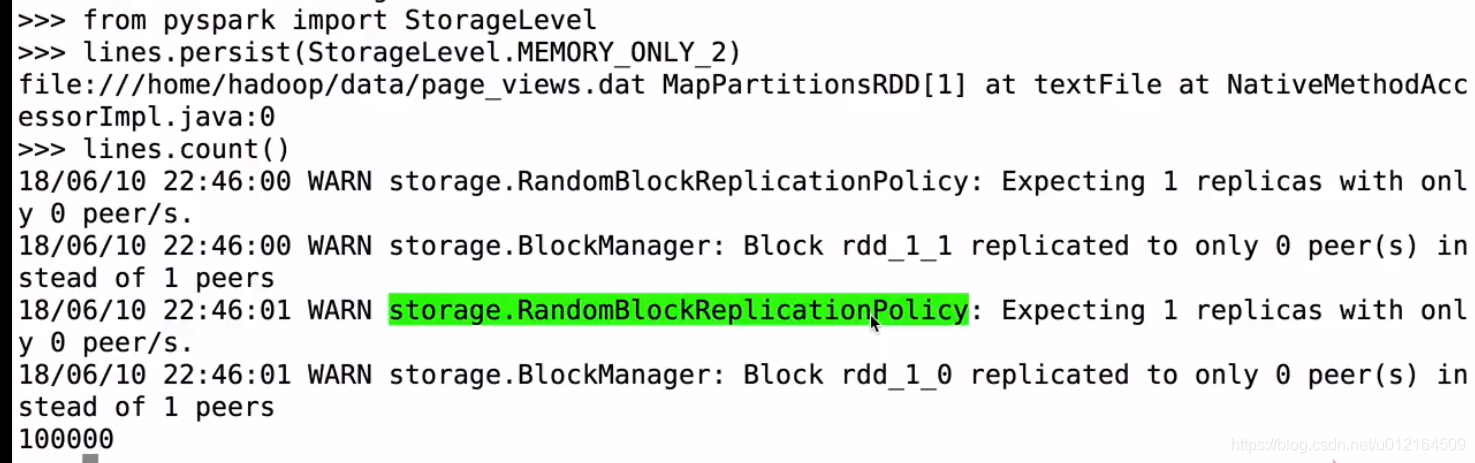
因为cache 是lazy 遇到action 才提交到spark 所以在lines.count()
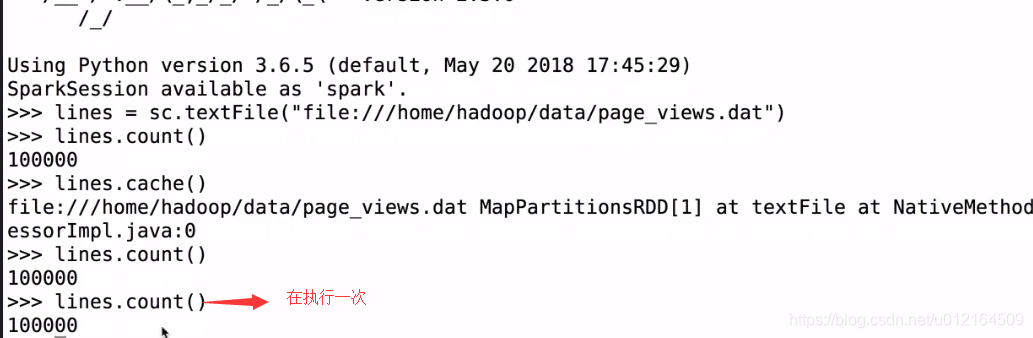
在看下页面
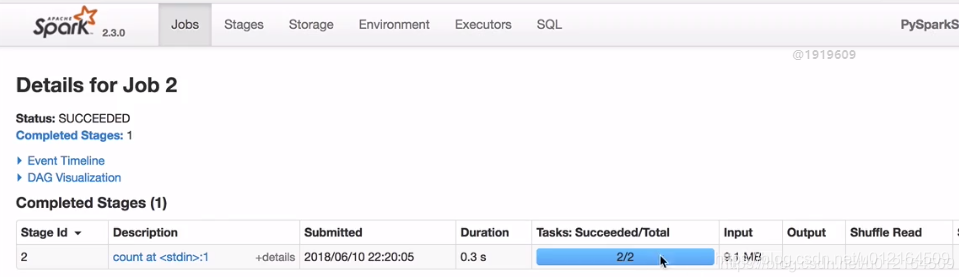
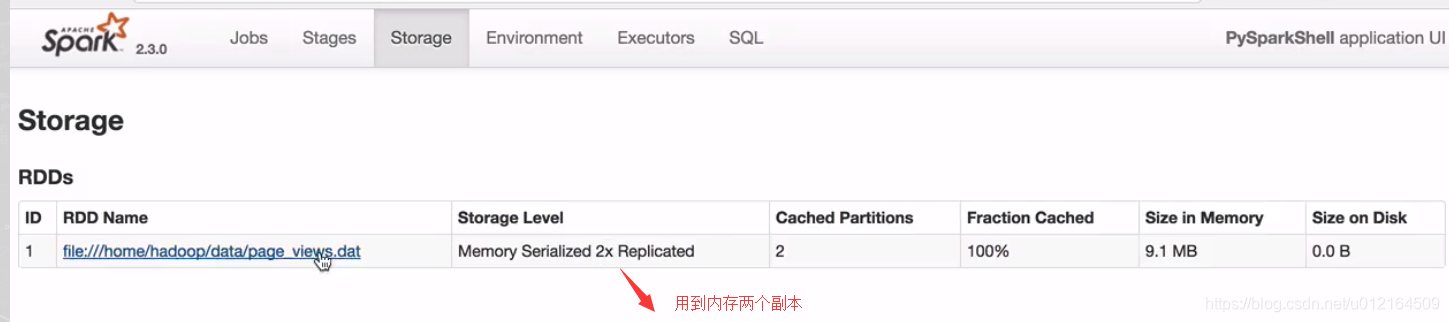
还有两个分区 100% size on Disk 磁盘没有 这就放到内存里面去了
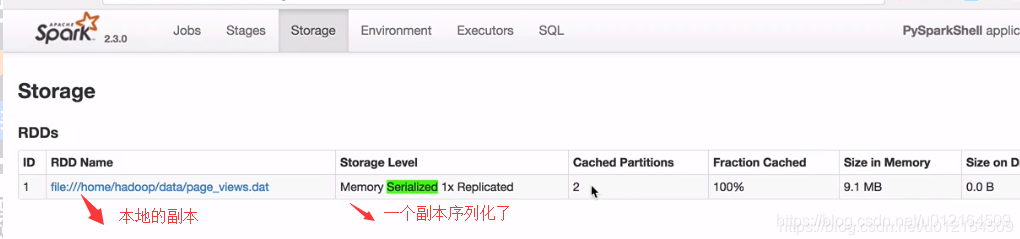
rdd.cache(): StorageLevel 存储级别
cache 它和tranformation: lazy 没有遇到action是不会提交作业到spark上运行的
如果一个RDD在后续的计算中可能会被使用到,那么建议cache
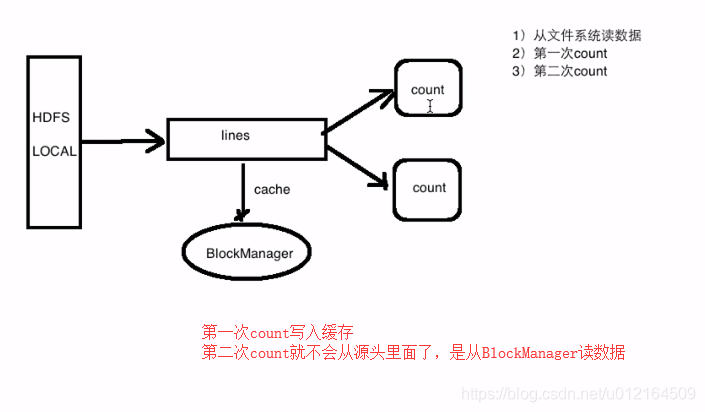
有缓存减少,磁盘io
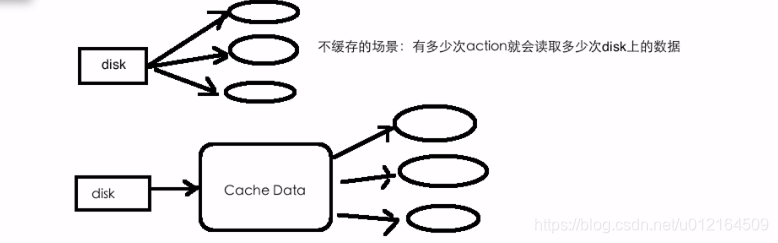
cache底层调用的是persist方法,传入的参数是 StorageLevel.MEMORY_ONLY
cache=persist
unpersist: 立即执行
第一次触发的收,会把数据保存到节点上去以内存的方式,spark缓存也是容错的,如果RDD丢了,会自动重新计算,从原始创建起来
它将使用最初创建它的转换自动重新计算
每一个持久化RDD能够被存储,不同的存储策略,例如,可以持久化你的数据到磁盘上面,持久化你的数据在内存里面,序列化节省你的空间,不仅仅是磁盘,内存,序列化,而且还可以多副本
这些levels,可以通过参数StorageLevel必须要通过persist()
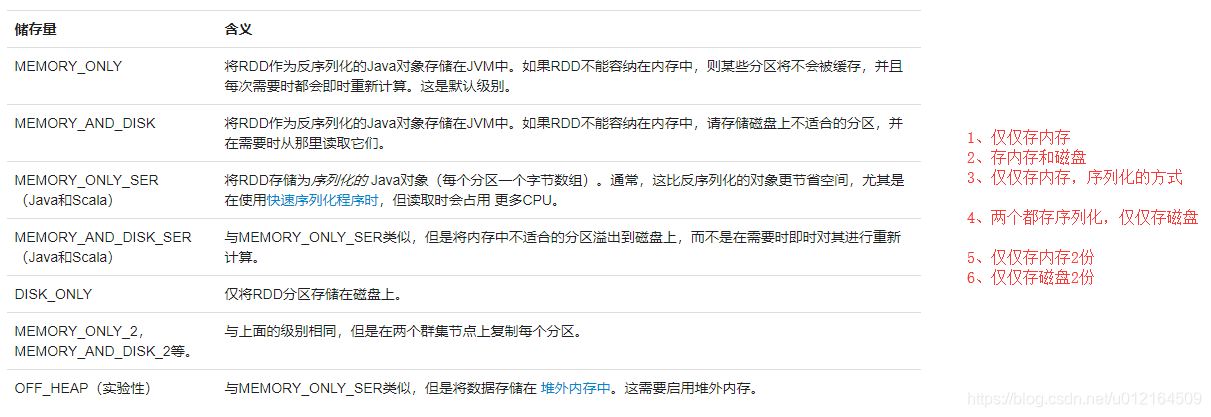
- 仅仅存内存
- 存内存和磁盘
- 仅仅存内存,序列化的方式
- 两个都存序列化,仅仅存磁盘
- 仅仅存内存2份
- 仅仅存磁盘2份
python的话
只有内存,只有内存2份,内存跟磁盘,内存跟磁盘2份,仅仅磁盘,仅仅磁盘2份
六、Spark 缓存策略详解
是否使用磁盘(useDisk)
是否使用内存(useMemory)
是否使用对外(useOffHeap)
使用使用序列化的方式(deserialized)
副本系数是1 (replication)
是否存磁盘
磁盘2份呢
仅仅只存内存呢
内存是两份呢
磁盘和内存使用
磁盘和内存使用两份
对外的
对应下面的图


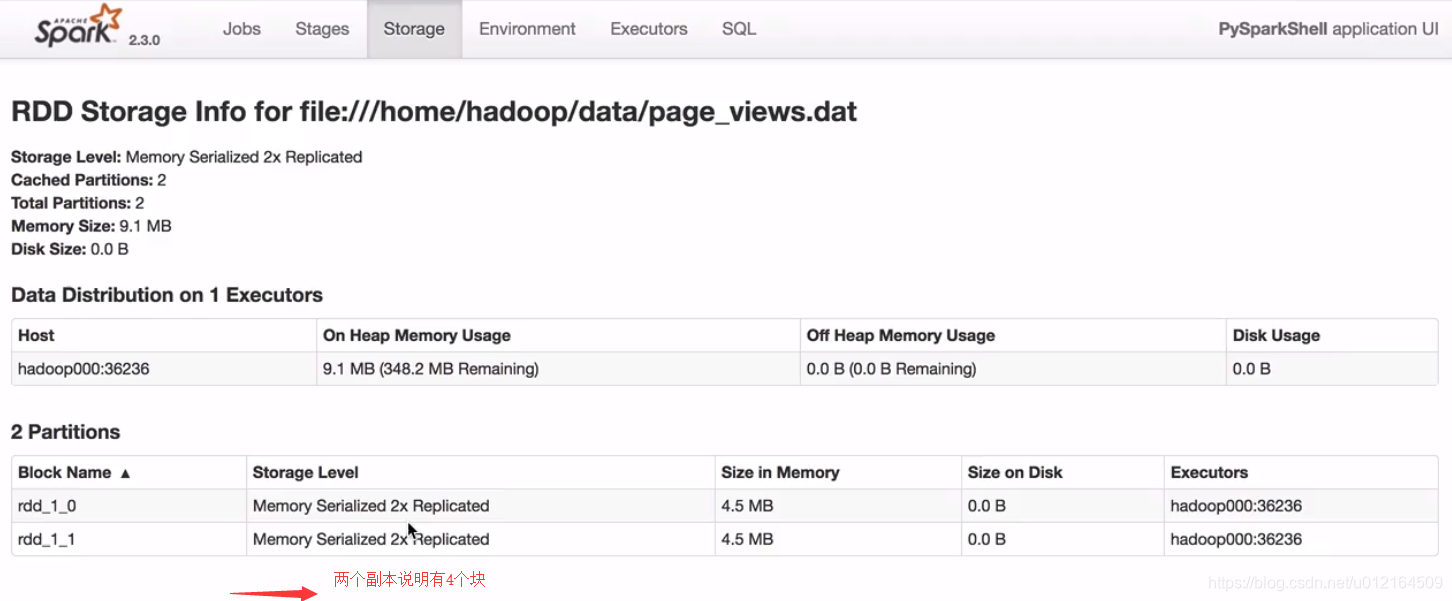
六 Spark 缓存策略选择依据
Which Storage Level to Choose 缓存的策略
要做一个权衡的,是内存使用还是cpu效率
时间换空间 还是空间换时间 做取舍
- RDD能使用默认存储策略搞定也就是MEMORY_ONLY ,因为cpu更高效率
- 如果内存不够了,总是缓存不了,计算都是从源头计算,会影响性能,尝试用MEMONLY_SER内存序列化,使对象更能节省空间,但是可以接受,适应于JAVA and Scala
- 建议不要把数据写入磁盘 ,从磁盘读过滤大数据集,你可以从原始数据取读,可能性能差不了多少,可能会更快,对比你从磁盘取读
- 缓存不建议使用多副本 ,建议单副本,尽可能内存搞定,如果内存搞不定就用MEMORY_ONLY_SER
七 Spark Lineage机制
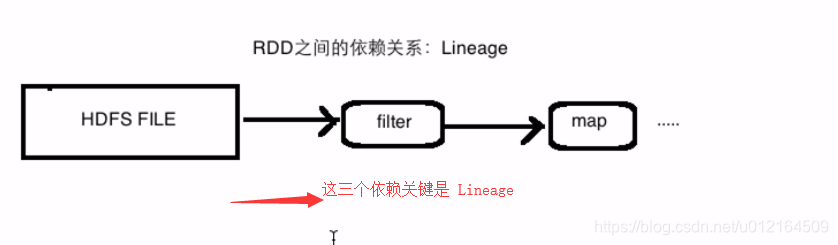
map的父亲是fiter
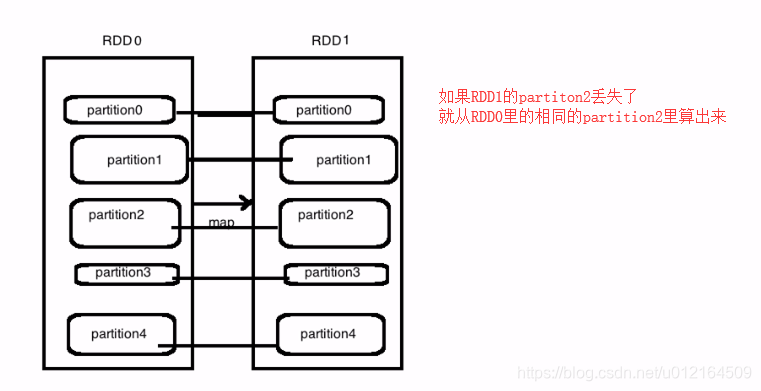
当每一个RDD计算的时候,map某个盘丢失了,每一个数据丢失了 从上一个filter算出来,以此类推,最差从源头去找
父亲都有,很好的容错,丢了哪一部分,就直接从父亲那一部分取把这个东西计算出来就可以了
对一个RDD做map操作,其实就对里面所有的partition,都做map操作
八 Spark窄依赖和宽依赖
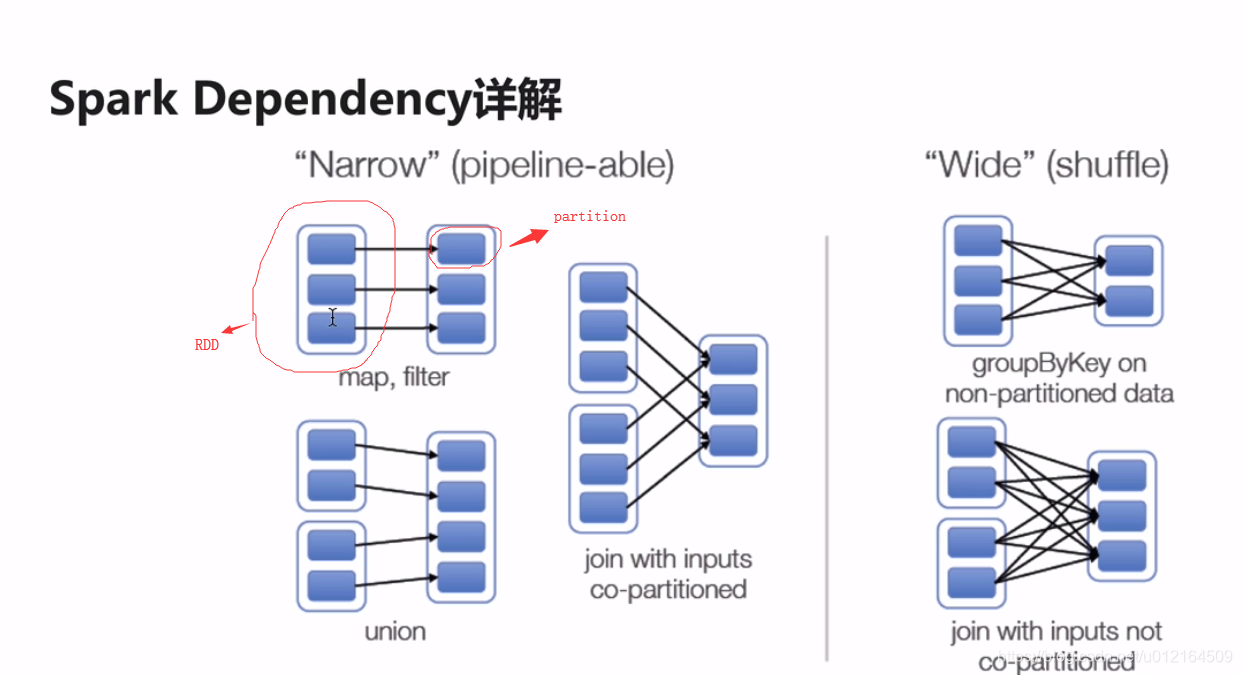
后面的RDD是从前面的RDD转化过来的
窄依赖: 一个父RDD的partition之多被子RDD的某个partition使用一次
父RDD的分区(partition)最多被子使用一次
宽依赖: 一个父RDD的partition会被子RDD的partition使用多次,有shuffle

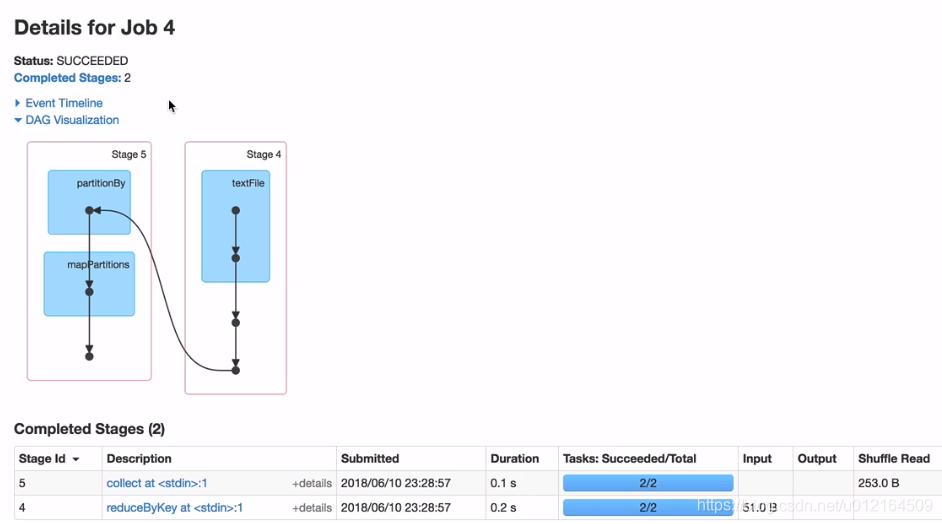
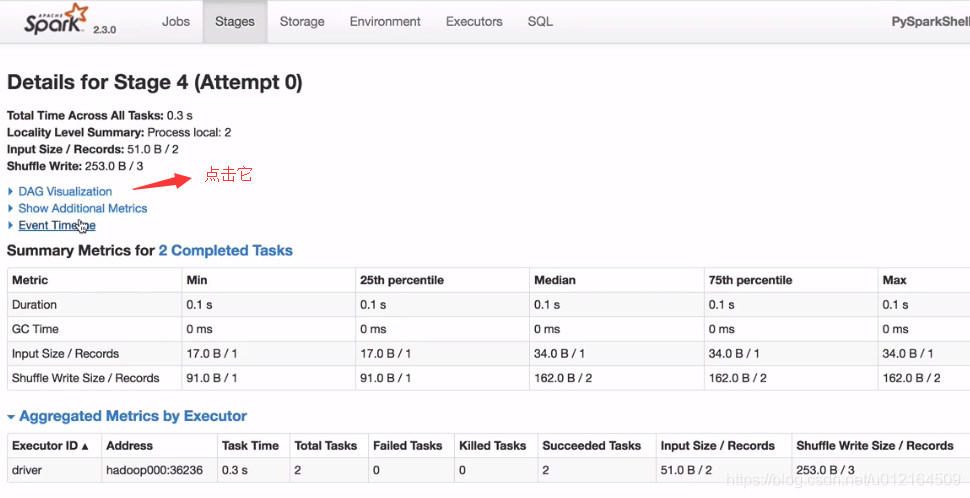
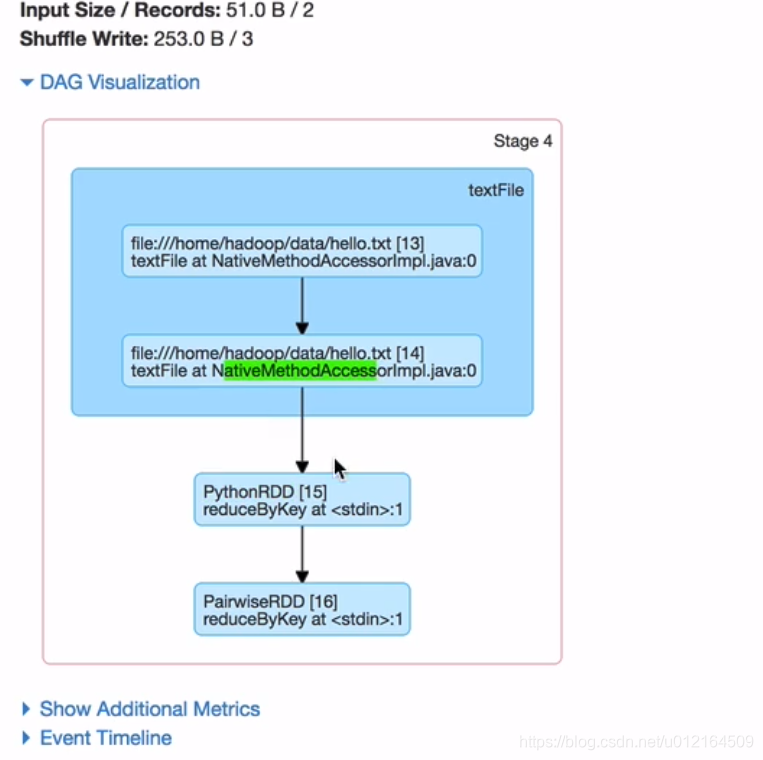
九 Spark shuffle
Spark中的某些操作会触发一个称为shuffle的事件。shuffle是spark的一种机制,用于重新分发数据,以便在不同的分区中对其进行分组。这通常涉及到跨执行器和机器复制数据,比较昂贵
看到ByKey,除了counting ,其余都是shuffle
性能影响
Shuffle是一个昂贵的操作,因为它涉及磁盘I/O、数据序列化和网络I/O.要为Shuffle组织数据,Spark会生成一组任务—映射任务来组织数据,还原任务集来聚合数据,与spark的map和reduce操作没有直接关系
案例
数据在HDFS里面
RDD 3个分区
words RDD 分区
reduceByKey预先在本地算下的,粉色hadoop有2个 ,合成了一个hadoop,2
遇到一个reduceByKey就是一个shuffle ,就会左右一拆变成 stage0 stage1
会把相同的key分到一个上面去
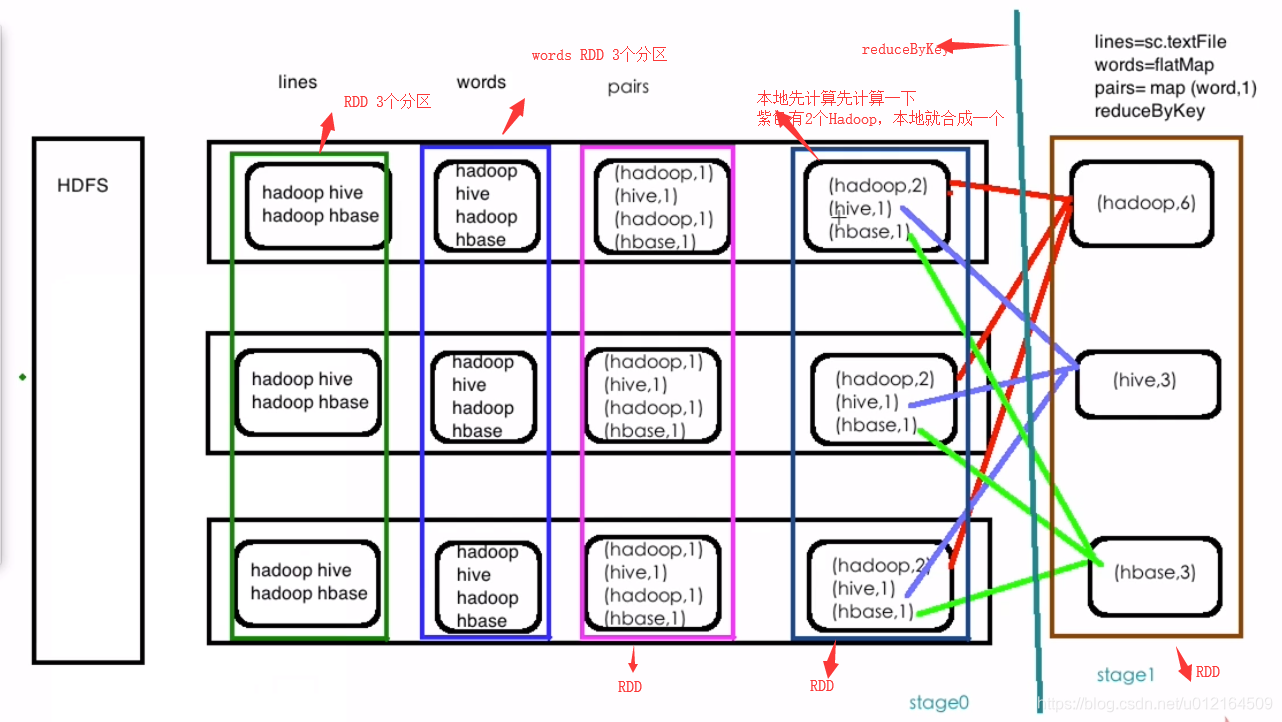
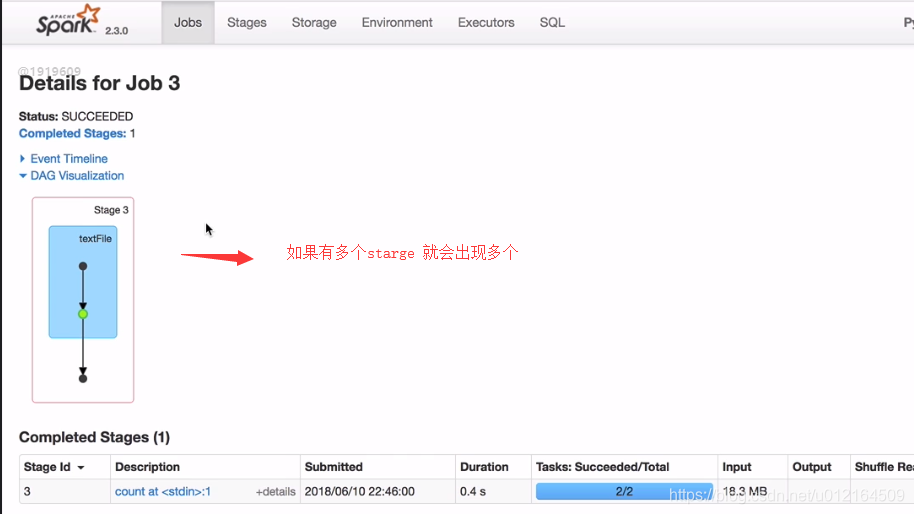
宽依赖就会有shuffle,就会把stage拆分两个
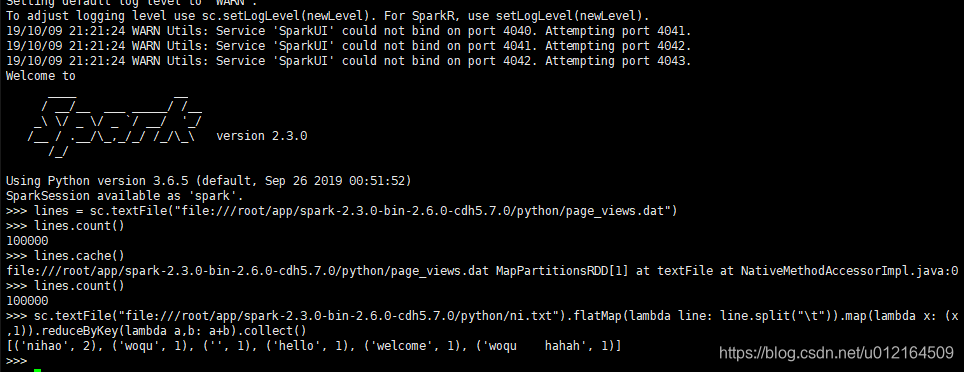
sc.textFile("file:///root/app/spark-2.3.0-bin-2.6.0-cdh5.7.0/python/ni.txt").flatMap(lambda line: line.split("\t")).map(lambda x: (x,1)).reduceByKey(lambda a,b: a+b).collect()


















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











