







1. 先来简单看一下入门的WordCount程序
1、首先数据源会产生随机的数字数据流(0-10内的数字)形式,然后通过flink的transformation将数据进行单词计数,再print输出
// wordcount 计数demo代码
public class WordCountDemo {
public static void main(String[] args) throws Exception {
// conf设置,避免调试的时候心跳超时
Configuration configuration = new Configuration();
configuration.setLong(HeartbeatManagerOptions.HEARTBEAT_INTERVAL, 10 * 60 * 1000);
configuration.setLong(HeartbeatManagerOptions.HEARTBEAT_TIMEOUT, 20 * 60 * 1000);
configuration.setString(AkkaOptions.ASK_TIMEOUT, "600 s");
configuration.setString(AkkaOptions.WATCH_HEARTBEAT_INTERVAL, "600 s");
configuration.setString(AkkaOptions.WATCH_HEARTBEAT_PAUSE, "1000 s");
configuration.setString(AkkaOptions.TCP_TIMEOUT, "600 s");
configuration.setString(AkkaOptions.TRANSPORT_HEARTBEAT_INTERVAL, "600 s");
configuration.setString(AkkaOptions.LOOKUP_TIMEOUT, "600 s");
configuration.setString(AkkaOptions.CLIENT_TIMEOUT, "600 s");
configuration.setLong(WebOptions.TIMEOUT, 10 * 60 * 1000L);
// local环境初始化
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironment(1, configuration);
// 添加自定义的数据源(每秒随机产生一个范围在(0-10)的数字)
DataStream<Integer> dataStream = streamExecutionEnvironment.addSource(new RandomSource()).returns(Integer.class);
dataStream.map(new MapFunction<Integer, Tuple2<String, Integer>>() { // 生成 k-v对
@Override
public Tuple2<String, Integer> map(Integer value) throws Exception {
return new Tuple2<>("i" + value, 1);
}
}).keyBy(0).timeWindow(Time.seconds(5)).reduce(new ReduceFunction<Tuple2<String, Integer>>() { // 每5s按照key进行统计计数
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
value2.f1 = value1.f1 + value2.f1;
return value2;
}
}).filter(new FilterFunction<Tuple2<String, Integer>>() {
@Override
public boolean filter(Tuple2<String, Integer> value) throws Exception {
return value.f0.compareTo("i5") != 0;
}
}).print();
streamExecutionEnvironment.execute("word count run");
}
}
// 数据源产生器
public class RandomSource extends RichSourceFunction<Integer> {
private Random random;
private volatile Boolean running = false;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
random = new Random();
running = true;
}
@Override
public void close() throws Exception {
super.close();
random = null;
}
@Override
public void run(SourceContext<Integer> sourceContext) throws Exception {
while (running) {
Integer out = random.nextInt(10);
sourceContext.collect(out);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running = false;
}
}在数据源产生器中,主要关注运行的run方法,其会源源不断的产生随机的数据并形成dataStream供后续flink transformation的操作
1、StreamExecutionEnvironment简单说明
以dataStream.map(MapFunction(...))作为flink算子操作分析的入口,查看StreamExecutionEnvironment源码可以知道流式计算环境中几个重要的数据结构;
StreamExecutionEnvironment中包含:
- ExecutionConfig config = new ExecutionConfig(); // 程序执行时的配置;主要包括默认并行度,序列化器,执行模式(Batch or Pipelined)等等;
- CheckpointConfig checkpointCfg = new CheckpointConfig(); // ckp检查点相关的配置;主要包括检查点模式(EXACTLY_ONCE or AT_LEAST_ONCE),检查点时间间隔,检查点在程序退出后是否删除等等;
- StateBackend defaultStateBackend; // 流式计算中设置存储中间状态、检查点、保存点的存储介质(MemoryStateBackend,FsStateBackend,RocksDBStateBackend等);
- TimeCharacteristic timeCharacteristic; // 流式计算中的处理时间设置
- List<Tuple2<String, DistributedCache.DistributedCacheEntry>> cacheFile; // 需要分布式缓存的文件
- List<StreamTransformation<?>> transformations = new ArrayList<>(); // 存储用户定义的flink transformation的算子操作
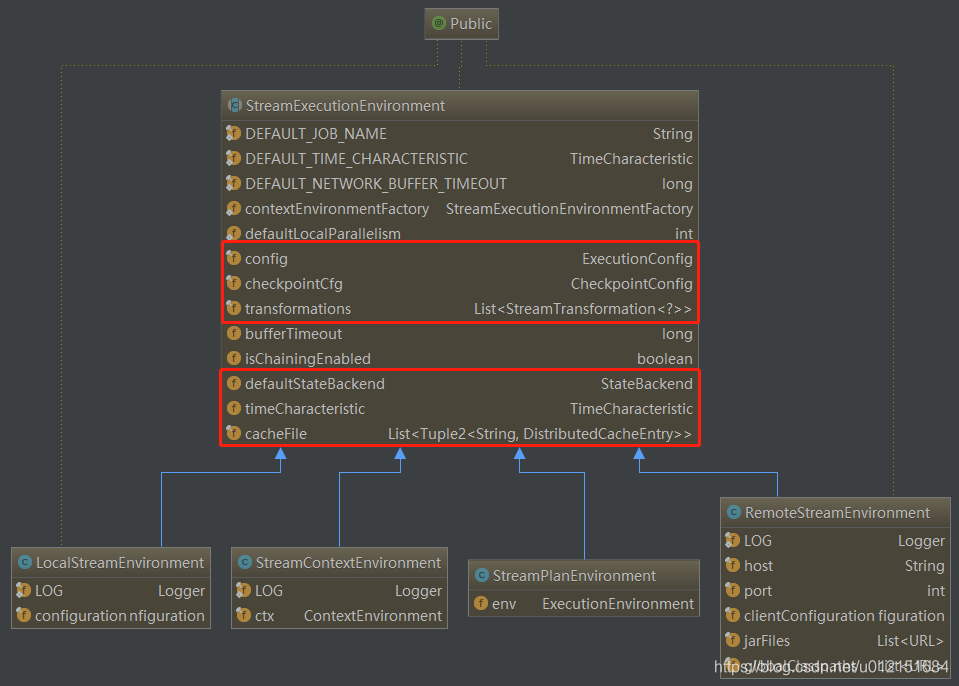
其下有四个实现的子类,主要是 本地执行环境、远程执行环境、CliContext交互式执行环境、Plan-web端执行环境;
在调用了execute()方法后,其具体执行由子类实现,子类实现大致逻辑:获取
- 生成StreamGraph。代表程序的拓扑结构,是从用户代码定义的transformation算子直接生成的图。
- 生成JobGraph。这个图是要交给flink去生成task的图。
- 生成一系列配置
- 将JobGraph和配置交给flink集群去运行。如果不是本地运行的话,还会把jar文件通过网络发给其他节点。
- 以本地模式运行的话,可以看到启动过程,如启动性能度量、web模块、JobManager、ResourceManager、taskManager等等
- 启动任务。值得一提的是在启动任务之前,先启动了一个用户类加载器,这个类加载器可以用来做一些在运行时动态加载类的工作。
2、flink算子(Operator)的注册、声明
在程序中以env.addSource()和dataStream.map(...)来跟踪分析flink transformation算子的注册、声明streamExecutionEnvironment.addSource(new RandomSource()).returns(Integer.class); // 添加自定义的输入源跟踪源代码可以知道
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function, String sourceName, TypeInformation<OUT> typeInfo) {
if (typeInfo == null) { // 根据数据源方法反射解析数据的输出类型
if (function instanceof ResultTypeQueryable) {
typeInfo = ((ResultTypeQueryable<OUT>) function).getProducedType();
} else {
try {
typeInfo = TypeExtractor.createTypeInfo(
SourceFunction.class,
function.getClass(), 0, null, null);
} catch (final InvalidTypesException e) {
typeInfo = (TypeInformation<OUT>) new MissingTypeInfo(sourceName, e);
}
}
}
boolean isParallel = function instanceof ParallelSourceFunction; // 是否并行
clean(function);
StreamSource<OUT, ?> sourceOperator;
if (function instanceof StoppableFunction) {
sourceOperator = new StoppableStreamSource<>(cast2StoppableSourceFunction(function));
} else {
sourceOperator = new StreamSource<>(function); // 构建包装StreamSource数据产生源
}
return new DataStreamSource<>(this, typeInfo, sourceOperator, isParallel, sourceName); // 构建返回 DataStreamSource 数据源
}DataStreamSource数据产生源中,使用SourceTransformation类封装了StreamSource类,其包含用户自定义的SourceFunction;后续flink transformation算子转换操作的数据源头DataStream具体子类就是DataStreamSource;接下来进行.map()算子操作的分析:
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper) {
TypeInformation<R> outType = TypeExtractor.getMapReturnTypes(clean(mapper), getType(),
Utils.getCallLocationName(), true);
return transform("Map", outType, new StreamMap<>(clean(mapper)));
}
public <R> SingleOutputStreamOperator<R> transform(String operatorName, TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType(); // 获取当前算子的输出
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation, // 当前dataStream转换算子
operatorName,
operator, // 进行变换的转换操作
outTypeInfo,
environment.getParallelism()); // 将当前
@SuppressWarnings({ "unchecked", "rawtypes" })
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform);
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
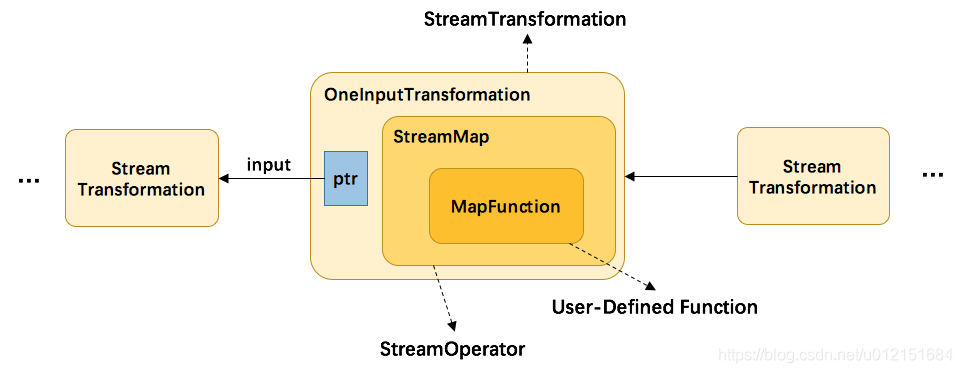
}首先会根据当前DataStream也就是初始的DataStreamSource的输出类型以及当前的转换函数MapFunction去确定当前Map transformation算子转换之后的输出类型; 然后将当前Map transformation算子使用OneInputTransformation类封装了StreamMap类,其包含用户自定义的MapFunction,并将其添加到streamExecutionEnvironment中的transformations算子列表中;并将SingleOutputStreamOperator作为map算子作用后输出的DataStream;
在算子中,每一个StreamTransformation代表了生成 DataStream 的操作,每一个 DataStream 的底层都有对应的一个 StreamTransformation。在 DataStream 上面通过 map 等算子不断进行转换,就得到了由 StreamTransformation 构成的图。当需要执行的时候,底层的这个图就会被转换成 StreamGraph。StreamTransformation 在运行时并不一定对应着一个物理转换操作,有一些操作只是逻辑层面上的,比如 split/select/partitioning 等。
每一个 StreamTransformation 都有一个关联的 Id,这个 Id 是全局递增的。除此以外,还有 uid, slotSharingGroup, parallelism 等信息。
StreamTransformation有很多具体的子类,如SourceTransformation、OneInputStreamTransformation、TwoInputTransformation、SideOutputTransformation、SinkTransformation等等,这些分别对应了DataStream 上的不同转换操作。
其映射过程如下所示:
最终可以根据程序有以下DataStream以及transformation算子转换形式:
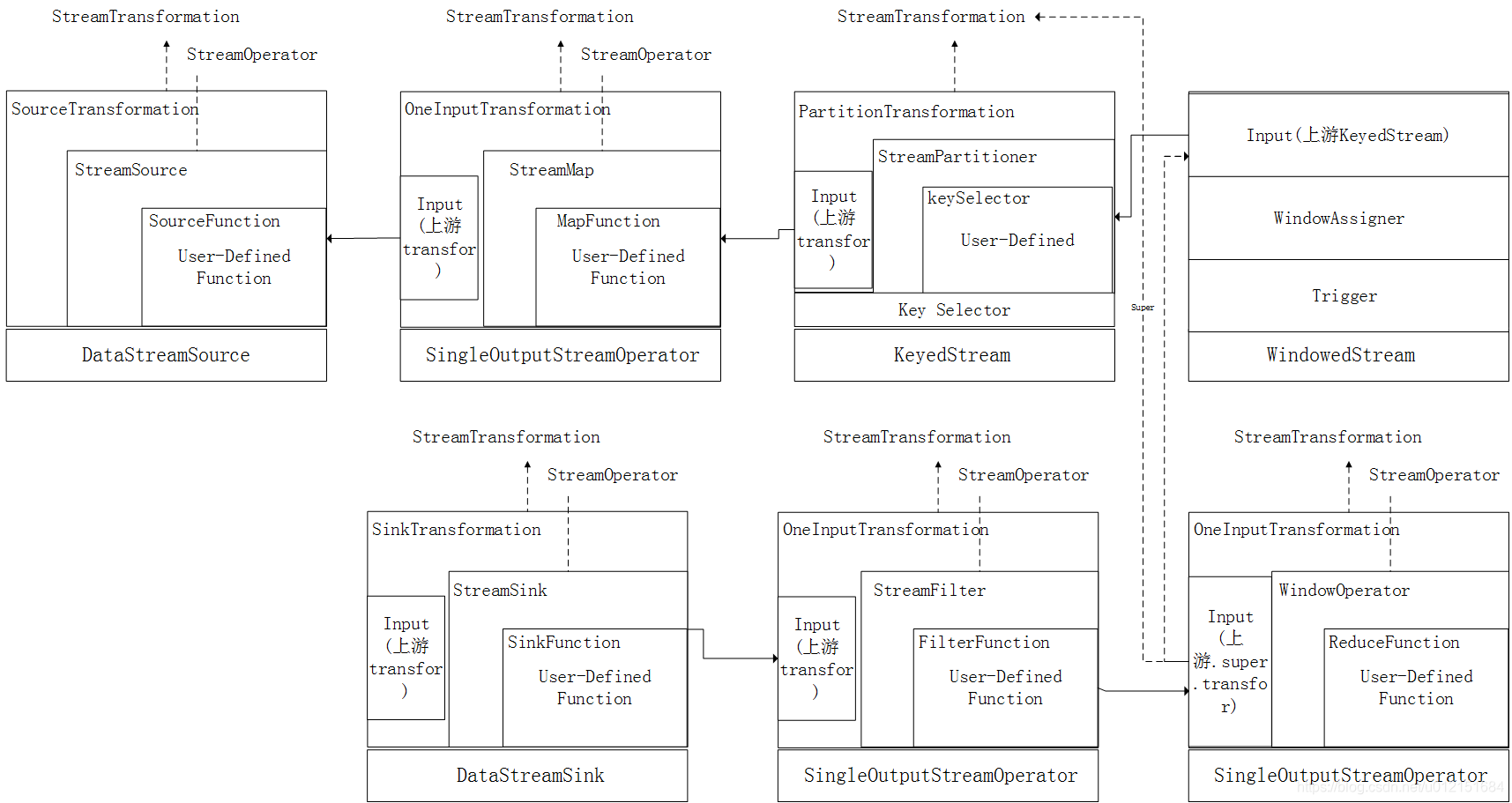 可以看到WindowStream负责生成对应的时间窗口、窗口触发器等,在flink中,其会将KeyStream、windowStream作为其下游聚合数据的来源,也就是说key-window-reduce的上下游transformation作为统一的一个transformation进行添加,其余的DataStream都会对应自己的StreamTransformation,这些StreamTransformation都会添加到streamExecutionEnvironment中的transformations算子列表(source和window相关的被下游算子持有引用):
可以看到WindowStream负责生成对应的时间窗口、窗口触发器等,在flink中,其会将KeyStream、windowStream作为其下游聚合数据的来源,也就是说key-window-reduce的上下游transformation作为统一的一个transformation进行添加,其余的DataStream都会对应自己的StreamTransformation,这些StreamTransformation都会添加到streamExecutionEnvironment中的transformations算子列表(source和window相关的被下游算子持有引用):
- OneInputTransformation{id=2, name='Map', outputType=Java Tuple2<String, Integer>, parallelism=1};
表示Map操作的OneInputTransformation对象,其input属性指向的是数据源的转换SourceTransformation; - OneInputTransformation{id=4, name='Window(TumblingProcessingTimeWindows(5000), ProcessingTimeTrigger, ReduceFunction$2, PassThroughWindowFunction)', outputType=Java Tuple2<String, Integer>, parallelism=1};
表示reduce操作的OneInputTransformation对象,其input属性指向的是表示keyBy的转换PartitionTransformation,而PartitionTransformation的input属性指向的是Map转换的OneInputTransformation; - OneInputTransformation{id=5, name='Filter', outputType=Java Tuple2<String, Integer>, parallelism=1};
表示filter操作的OneInputTransformation对象,其input属性指向的是reduce转化的OneInputTransformation对象; - SinkTransformation{id=6, name='Print to Std. Out', outputType=GenericType<java.lang.Object>, parallelism=1};
表示sink操作对应的SinkTransformation对象,其input属性指向的是fliter转化的OneInputTransformation对象;
3、StreamGraph的生成
在transformations算子被注册、声明后,env.executor()会调用StreamGraph streamGraph = getStreamGraph(); 其会调用基类的streamGraph生成方法;StreamGraphGenerator.generate(env, transformations);其中的transformations就是记录我们在流式转换的transform方法中放进来的转换算子的list列表;在遍历List<StreamTransformation>生成StreamGraph的时候,会递归调用StreamGraphGenerator#transform方法。对于每一个StreamTransformation,确保当前其上游已经完成转换。
StreamTransformations会被转换为StreamGraph中的节点StreamNode,并为上下游节点添加连接两个StreamNode节点的数据流边StreamEdge。其中涉及到StreamGraph生成的代码主要为两大块:
private Collection<Integer> transform(StreamTransformation<?> transform) { // 针对单个transformation进行转化
if (alreadyTransformed.containsKey(transform)) { // 由于是递归调用的,可能已经完成了转换,避免多次重复转化
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " + transform);
if (transform.getMaxParallelism() <= 0) {
// if the max parallelism hasn't been set, then first use the job wide max parallelism
// from theExecutionConfig.
int globalMaxParallelismFromConfig = env.getConfig().getMaxParallelism();
if (globalMaxParallelismFromConfig > 0) {
transform.setMaxParallelism(globalMaxParallelismFromConfig);
}
}
// call at least once to trigger exceptions about MissingTypeInfo
transform.getOutputType();
// 这里对操作符的类型进行判断,并调用相应转换操作的图处理逻辑
// 主要核心功能是递归的将该节点和节点的上游节点加入图
Collection<Integer> transformedIds;
if (transform instanceof OneInputTransformation<?, ?>) {
transformedIds = transformOneInputTransform((OneInputTransformation<?, ?>) transform);
} else if (transform instanceof TwoInputTransformation<?, ?, ?>) {
transformedIds = transformTwoInputTransform((TwoInputTransformation<?, ?, ?>) transform);
} else if (transform instanceof SourceTransformation<?>) {
transformedIds = transformSource((SourceTransformation<?>) transform);
} else if (transform instanceof SinkTransformation<?>) {
transformedIds = transformSink((SinkTransformation<?>) transform);
} else if (transform instanceof UnionTransformation<?>) {
transformedIds = transformUnion((UnionTransformation<?>) transform);
} else if (transform instanceof SplitTransformation<?>) {
transformedIds = transformSplit((SplitTransformation<?>) transform);
} else if (transform instanceof SelectTransformation<?>) {
transformedIds = transformSelect((SelectTransformation<?>) transform);
} else if (transform instanceof FeedbackTransformation<?>) {
transformedIds = transformFeedback((FeedbackTransformation<?>) transform);
} else if (transform instanceof CoFeedbackTransformation<?>) {
transformedIds = transformCoFeedback((CoFeedbackTransformation<?>) transform);
} else if (transform instanceof PartitionTransformation<?>) {
transformedIds = transformPartition((PartitionTransformation<?>) transform);
} else if (transform instanceof SideOutputTransformation<?>) {
transformedIds = transformSideOutput((SideOutputTransformation<?>) transform);
} else {
throw new IllegalStateException("Unknown transformation: " + transform);
}
// need this check because the iterate transformation adds itself before
// transforming the feedback edges
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
// ..................... 进行一些资源和配置上的设置
return transformedIds;
}以最典型的transformOneInputTransform为例进行转化StreamNode节点的操作分析:
private <IN, OUT> Collection<Integer> transformOneInputTransform(OneInputTransformation<IN, OUT> transform) {
Collection<Integer> inputIds = transform(transform.getInput()); // 首先先确保上游节点都完成转换
// the recursive call might have already transformed this
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
String slotSharingGroup = determineSlotSharingGroup(transform.getSlotSharingGroup(), inputIds); // 确定资源共享组,用户如果没有指定,默认是default
streamGraph.addOperator(transform.getId(), // 向StreamGraph中添加Operator, 这一步会生成对应的StreamNode
slotSharingGroup,
transform.getCoLocationGroupKey(),
transform.getOperator(),
transform.getInputType(),
transform.getOutputType(),
transform.getName());
if (transform.getStateKeySelector() != null) {
TypeSerializer<?> keySerializer = transform.getStateKeyType().createSerializer(env.getConfig());
streamGraph.setOneInputStateKey(transform.getId(), transform.getStateKeySelector(), keySerializer);
}
streamGraph.setParallelism(transform.getId(), transform.getParallelism());
streamGraph.setMaxParallelism(transform.getId(), transform.getMaxParallelism());
for (Integer inputId: inputIds) { // 依次连接到上游节点, 创建并生成对应的StreamEdge
streamGraph.addEdge(inputId, transform.getId(), 0);
}
return Collections.singleton(transform.getId());
}具体的StreamNode节点生成过程,在生成StreamNode中,保存了对应的 StreamOperator (从 StreamTransformation 得到),并且还引入了变量 jobVertexClass 来表示该节点在 TaskManager 中运行时的实际任务类型;AbstractInvokable是所有可以在TaskManager中运行的任务的抽象基础类,包括流式任务和批任务。StreamTask是所有流式任务的基础类,其具体的子类包括SourceStreamTask, OneInputStreamTask, TwoInputStreamTask等等。
protected StreamNode addNode(Integer vertexID,
String slotSharingGroup,
@Nullable String coLocationGroup,
Class<? extends AbstractInvokable> vertexClass,
StreamOperator<?> operatorObject,
String operatorName) {
if (streamNodes.containsKey(vertexID)) {
throw new RuntimeException("Duplicate vertexID " + vertexID);
}
StreamNode vertex = new StreamNode(environment, // 创建StreamNode,这里保存了StreamOperator和vertexClass的信息
vertexID,
slotSharingGroup,
coLocationGroup,
operatorObject,
operatorName,
new ArrayList<OutputSelector<?>>(),
vertexClass);
streamNodes.put(vertexID, vertex);
return vertex;
}前面提到,在每一个物理节点的转换上,会调用 StreamGraph#addEdge 在输入节点和当前节点之间建立边的连接;对于一些不包含物理转换操作的 StreamTransformation,如 Partitioning, split/select, union,并不会生成 StreamNode,而是生成一个带有特定属性的虚拟节点。当添加一条有虚拟节点指向下游节点的边时,会找到虚拟节点上游的物理节点,在两个物理节点之间添加边,并把虚拟转换操作的属性附着上去。
private void addEdgeInternal(Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
List<String> outputNames,
OutputTag outputTag) {
//先判断是不是虚拟节点上的边,如果是,则找到虚拟节点上游对应的物理节点
//在两个物理节点之间添加边,并把对应的 StreamPartitioner,或者 OutputTag 等补充信息添加到StreamEdge中
if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {
......
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag);
} else {
//两个物理节点
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
// If no partitioner was specified and the parallelism of upstream and downstream
// operator matches use forward partitioning, use rebalance otherwise.
if (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner<Object>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
if (partitioner instanceof ForwardPartitioner) {
if (upstreamNode.getParallelism() != downstreamNode.getParallelism()) {
throw new UnsupportedOperationException("Forward partitioning does not allow " +
"change of parallelism. Upstream operation: " + upstreamNode + " parallelism: " + upstreamNode.getParallelism() +
", downstream operation: " + downstreamNode + " parallelism: " + downstreamNode.getParallelism() +
" You must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");
}
}
//创建 StreamEdge,保留了StreamPartitioner等属性
StreamEdge edge = new StreamEdge(upstreamNode, downstreamNode, typeNumber, outputNames, partitioner, outputTag);
//分别将StreamEdge添加到上游节点和下游节点
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
}
}//StreamGraphGenerator#transformPartition
private <T> Collection<Integer> transformPartition(PartitionTransformation<T> partition) {
StreamTransformation<T> input = partition.getInput();
List<Integer> resultIds = new ArrayList<>();
//递归地转换上游节点 (若上游已转换则直接返回转换ids)
Collection<Integer> transformedIds = transform(input);
for (Integer transformedId: transformedIds) {
int virtualId = StreamTransformation.getNewNodeId();
//添加虚拟的 Partition 节点
streamGraph.addVirtualPartitionNode(transformedId, virtualId, partition.getPartitioner());
resultIds.add(virtualId);
}
return resultIds;
}
// StreamGraph#addVirtualPartitionNode
public void addVirtualPartitionNode(Integer originalId, Integer virtualId, StreamPartitioner<?> partitioner) {
if (virtualPartitionNodes.containsKey(virtualId)) {
throw new IllegalStateException("Already has virtual partition node with id " + virtualId);
}
//添加一个虚拟节点,后续添加边的时候会连接到实际的物理节点
virtualPartitionNodes.put(virtualId,
new Tuple2<Integer, StreamPartitioner<?>>(originalId, partitioner));
}针对上一节分析的WordCountDemo代码进行转化操作具体分析:1、针对第一个Map操作进行具体生成StreamNode节点的分析如下:
1、OneInputTransformation{id=2, name='Map', outputType=Java Tuple2<String, Integer>, parallelism=1};
表示Map操作的OneInputTransformation对象,其input属性指向的是数据源的转换SourceTransformation;
- 其会先第一步对其Map#OneInputTransformation的上游输入input#SourceTransformation进行生成StreamNode节点处理;其会进一步调用streamGraph.addSource(),添加Source所对应的StreamNode节点,其会包括Source源#StreamOperator和可执行任务类型jobVertexClass#SourceStreamTask;
- 后面则会对Map#OneInputTransformation当前算子进行处理,生成StreamNode节点;其会包括StreamMap#MapFunction和可执行任务类型jobVertexClass#OneInputStreamTask;
- 之后便会对当前算子Map以及其上游输入Source算子进行StreamEdge的数据连接边的添加;最终形成Node#Source-- StreamEdge--Node#Map 这样的形式;
StreamNode#Source(Custom Source-1;inEdges=null, outEdges=StreamEdge#(sourceVertex=StreamNode#Source, targetVertex=StreamNode#Map))
StreamEdge#(Source: Custom Source-1 -> Map-2, typeNumber=0, selectedNames=[], outputPartitioner=FORWARD, outputTag=null)
StreamNode#Map(Map-2;inEdges=StreamEdge#(sourceVertex=StreamNode#Source, targetVertex=StreamNode#Map), outEdges=null))
所有针对上诉转化代码,有最终的StreamGraph 图拓扑结构形成如下:
如下transformations算子列表(source和window相关的被下游算子持有引用):
1、OneInputTransformation{id=2, name='Map', outputType=Java Tuple2<String, Integer>, parallelism=1};
表示Map操作的OneInputTransformation对象,其input属性指向的是数据源的转换SourceTransformation(StreamNode#1);
2、OneInputTransformation{id=4, name='Window(TumblingProcessingTimeWindows(5000), ProcessingTimeTrigger, ReduceFunction$2, PassThroughWindowFunction)', outputType=Java Tuple2<String, Integer>, parallelism=1};
表示reduce操作的OneInputTransformation对象,其input属性指向的是表示keyBy的转换PartitionTransformation,而PartitionTransformation的input属性指向的是Map转换的OneInputTransformation;
3、OneInputTransformation{id=5, name='Filter', outputType=Java Tuple2<String, Integer>, parallelism=1};
表示filter操作的OneInputTransformation对象,其input属性指向的是reduce转化的OneInputTransformation对象;
4、SinkTransformation{id=6, name='Print to Std. Out', outputType=GenericType<java.lang.Object>, parallelism=1};
表示sink操作对应的SinkTransformation对象,其input属性指向的是fliter转化的OneInputTransformation对象;
1、StreamNode#1(SourceTransformation) --> StreamEdge --> StreamNode#2(MapTransformation)
2、StreamNode#2(MapTransformation) --> (先指向PartitionTransformation所在的虚拟节点StreamNode#3) --> StreamNode#4(WindowTransformation);最终会使用StreamEdge 替换虚拟节点来连接两个实体StreamNode,其StreamEdge上包含虚拟节点所有的转换属性;
StreamNode#2(MapTransformation) --> StreamEdge --> StreamNode#4(WindowTransformation);
3、StreamNode#4(WindowTransformation) --> StreamEdge --> StreamNode#5(FilterTransformation);
4、StreamNode#5(FilterTransformation) --> StreamEdge --> StreamNode#6(SinkTransformation);

针对上述转化过程,其对数据流的相关转换操作,都可以通过streamExecutionEnvironment.getStreamGraph().getStreamingPlanAsJSON()来获取到StreamGraph实例的json字符串;将获取到的json字符串放如到 http://flink.apache.org/visualizer/ ,可以转化为图形表示,如下:


















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









