







 本文深入解析HDFS中数据块管理机制,包括数据块副本的添加、删除流程,以及数据节点的添加、撤销和心跳处理。重点介绍了BlockManager如何处理数据块副本的状态转换,数据节点注册和数据块上报的细节。
本文深入解析HDFS中数据块管理机制,包括数据块副本的添加、删除流程,以及数据节点的添加、撤销和心跳处理。重点介绍了BlockManager如何处理数据块副本的状态转换,数据节点注册和数据块上报的细节。
数据块管理
在上一节介绍了BlockManager中的数据块副本状态,主要是保存各个数据块副本状态的存储对象。名字节点第二关系的管理包括数据块管理和数据节点管理,其对数据块的管理是依托于BlockManager类来实现的。
1、添加数据块副本
BlockManager.addStoredBlock()用于在blocksMap中添加/更新数据节点node上的数据块副本block。当DataNode上写入了一个新的数据块副本或者完成了数据块副本的复制操作后,其会调用远程方法DatanodeProtocol.blockReport()或者DatanodeProtocol.blockReceivedAndDeleted()向名字节点汇报该新增的副本,最终会调用BlockManager.addStoredBlock()方法,将数据块副本和数据节点信息更新到BlocksMap对象中。其基本流程及源码如下:
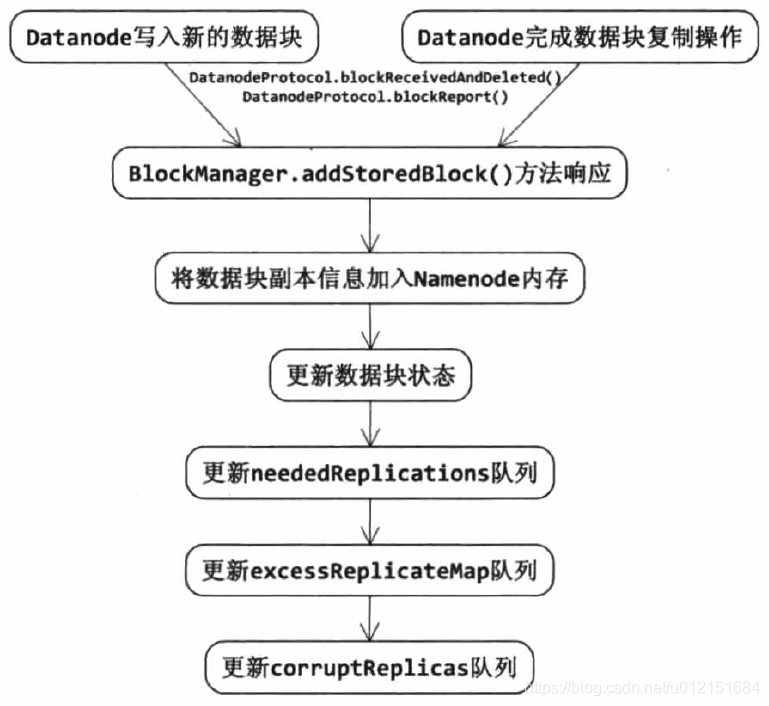
private Block addStoredBlock(final BlockInfo block,
DatanodeStorageInfo storageInfo,
DatanodeDescriptor delNodeHint,
boolean logEveryBlock)
throws IOException {
// ......
if (storedBlock == null || storedBlock.getBlockCollection() == null) {
// 当前block不属于任何inode
return block;
}
BlockCollection bc = storedBlock.getBlockCollection();
// add block to the datanode
// 在block->datanode映射中添加当前datanode
boolean added = storageInfo.addBlock(storedBlock);
// ......
// 判断副本对应的block状态并进行状态转换
if(storedBlock.getBlockUCState() == BlockUCState.COMMITTED &&
numLiveReplicas >= minReplication) {
storedBlock = completeBlock(bc, storedBlock, false);
} else if (storedBlock.isComplete() && added) {
namesystem.incrementSafeBlockCount(numCurrentReplica);
}
// if file is under construction, then done for now
if (bc.isUnderConstruction()) {
return storedBlock;
}
// do not try to handle over/under-replicated blocks during first safe mode
if (!namesystem.isPopulatingReplQueues()) {
return storedBlock;
}
// handle underReplication/overReplication
// 判断数据块副本数量是否满足,不满足则复制添加到BlockManager.neededReplications中
// 否则从neededReplications中移除
short fileReplication = bc.getBlockReplication();
if (!isNeededReplication(storedBlock, fileReplication, numCurrentReplica)) {
neededReplications.remove(storedBlock, numCurrentReplica,
num.decommissionedReplicas(), fileReplication);
} else {
updateNeededReplications(storedBlock, curReplicaDelta, 0);
}
// 判断副本数量是否超出设置,需要删除, 选择删除副本添加到excessReplicateMap中
if (numCurrentReplica > fileReplication) {
processOverReplicatedBlock(storedBlock, fileReplication, node, delNodeHint);
}
//
if ((corruptReplicasCount > 0) && (numLiveReplicas >= fileReplication))
invalidateCorruptReplicas(storedBlock);
return storedBlock;
}2、删除数据块副本
数据块副本的删除包括如下3种情况:
- 数据块副本所属的文件被删除,副本也就相应的删除掉。
- 数据块副本数多于副本系数,多余的副本会被删除。
- 数据块副本数已经损坏,也需要删除损坏的副本。
(1)删除文件拥有的数据块副本
当删除目录上的一个文件时(实现在FSDirectory.delete()中),文件拥有的数据块通过FSNamesystem.removePathAndBlocks()最终调用BlockManager.removeBlocks()调用ddToInvalidates()方法将数据块对应的所有副本添加到invalidateBlocks待删除对象中。然后再从BlockManager中的数据块保存对象中删除;包括从blocksMap中删除;删除corruptRelcas中可能存在的副本损坏记录;由于数据块被删除,即使有副本损坏,也都不需要再进行数据块复制,所有管理数据块复制对象中也需要删除:如pendingReplications、neededReplications等。
public void removeBlock(Block block) {
// ......
addToInvalidates(block);
removeBlockFromMap(block);
// Remove the block from pendingReplications and neededReplications
pendingReplications.remove(block);
neededReplications.remove(block, UnderReplicatedBlocks.LEVEL);
if (postponedMisreplicatedBlocks.remove(block)) {
postponedMisreplicatedBlocksCount.decrementAndGet();
}
}
private void addToInvalidates(Block b) {
if (!namesystem.isPopulatingReplQueues()) {
return;
}
for(DatanodeStorageInfo storage : blocksMap.getStorages(b, State.NORMAL)) {
final DatanodeDescriptor node = storage.getDatanodeDescriptor();
invalidateBlocks.add(b, node, false);
}
}
public void removeBlockFromMap(Block block) {
removeFromExcessReplicateMap(block);
blocksMap.removeBlock(block);
// If block is removed from blocksMap remove it from corruptReplicasMap
corruptReplicas.removeFromCorruptReplicasMap(block);
}(2)多余副本删除
addStoredBlock()方法最后阶段的处理中,移除多余副本使用了processOverReplicatedBlock()方法。这个方法其实只是为chooseExcessReplicates()准备数据,由于blocksMap保存着数据块的所有副本所在的数据节点,方法需要遍历这些数据节点,当节点同时满足下面3个条件时,才把它标记为”等待删除数据块“的候选数据节点,并保存在变量nonExcess中。
- 该节点信息不在excessReplicateMap中。
- 该节点不是一个处于”正在撤销“或”已撤销“的数据节点。
- 该节点保存的副本已经损坏
具体选择执行删除操作的数据节点的原则为:尽量保证删除之后的副本能均匀分布在不同的机架上,尽量从空间较少的节点上删除冗余副本。最终processOverReplicatedBlock()方法,代码如下:
private void processOverReplicatedBlock(final Block block,
final short replication, final DatanodeDescriptor addedNode,
DatanodeDescriptor delNodeHint) {
Collection<DatanodeStorageInfo> nonExcess = new ArrayList<DatanodeStorageInfo>();
Collection<DatanodeDescriptor> corruptNodes = corruptReplicas.getNodes(block);
for(DatanodeStorageInfo storage : blocksMap.getStorages(block, State.NORMAL)) {
final DatanodeDescriptor cur = storage.getDatanodeDescriptor();
if (storage.areBlockContentsStale()) {
postponeBlock(block);
return;
}
LightWeightLinkedSet<Block> excessBlocks = excessReplicateMap.get(cur
.getDatanodeUuid());
if (excessBlocks == null || !excessBlocks.contains(block)) {
if (!cur.isDecommissionInProgress() && !cur.isDecommissioned()) {
// exclude corrupt replicas
if (corruptNodes == null || !corruptNodes.contains(cur)) {
nonExcess.add(storage);
}
}
}
}
// 按照条件选出合适的DataNode,将需要删除的数据块副本加入到invalidateBlocks队列中
chooseExcessReplicates(nonExcess, block, replication,
addedNode, delNodeHint);
}(3)损坏副本删除
在客户端读文件或者数据节点上的数据块扫描器都可能回发现损坏的副本,它们会通过对应接口的reportBadBlocks()将损坏的数据块副本信息汇报给名字节点,最终由BlockManager.markBlocksAsCorrupt()方法进行处理。该方法会将损坏的数据块副本加入到corruptReplicas队列中,然后判断该数据块副本是否有足够的副本数量,否则加入到neededReplications队列中,等待进行数据块的复制操作。代码如下:
private void markBlockAsCorrupt(BlockToMarkCorrupt b,
DatanodeStorageInfo storageInfo,
DatanodeDescriptor node) throws IOException {
BlockCollection bc = b.corrupted.getBlockCollection();
if (bc == null) { // 数据块副本不属于任何文件 直接删除
addToInvalidates(b.corrupted, node);
return;
}
// Add replica to the data-node if it is not already there
if (storageInfo != null) {
storageInfo.addBlock(b.stored);
}
// Add this replica to corruptReplicas Map // 添加到损坏副本对象中
corruptReplicas.addToCorruptReplicasMap(b.corrupted, node, b.reason,
b.reasonCode);
NumberReplicas numberOfReplicas = countNodes(b.stored);
boolean hasEnoughLiveReplicas = numberOfReplicas.liveReplicas() >= bc
.getBlockReplication();
boolean minReplicationSatisfied =
numberOfReplicas.liveReplicas() >= minReplication;
boolean hasMoreCorruptReplicas = minReplicationSatisfied &&
(numberOfReplicas.liveReplicas() + numberOfReplicas.corruptReplicas()) >
bc.getBlockReplication();
boolean corruptedDuringWrite = minReplicationSatisfied &&
(b.stored.getGenerationStamp() > b.corrupted.getGenerationStamp());
// 如果有足够的副本数量,则直接删除这个副本
if (hasEnoughLiveReplicas || hasMoreCorruptReplicas
|| corruptedDuringWrite) {
// the block is over-replicated so invalidate the replicas immediately
invalidateBlock(b, node);
} else if (namesystem.isPopulatingReplQueues()) {
// 如果副本数不足,则复制这个数据块
// add the block to neededReplication
updateNeededReplications(b.stored, -1, 0);
}
}最终,其副本删除的逻辑流程整理后如下:
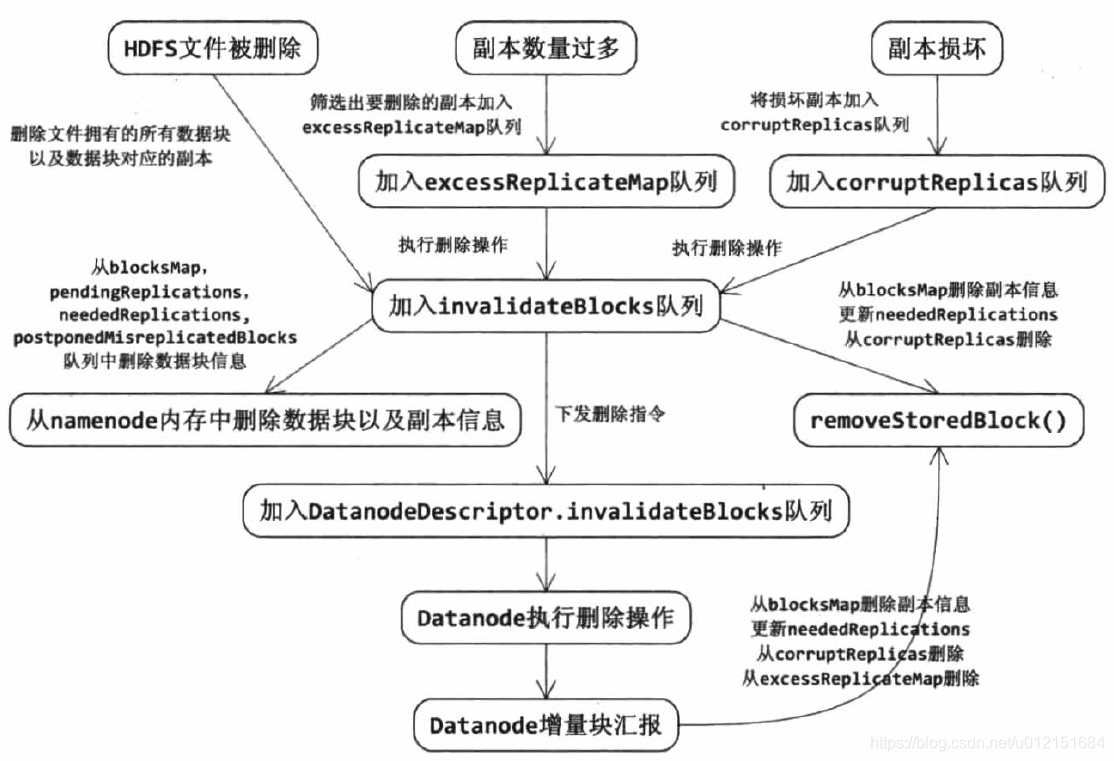
通过对副本删除逻辑的分析可以知道,BlockManager会将需要删除的数据块副本添加到BlockManager.invalidateBlocks队列中,等待生成对应的删除指令;在上文中对DatanodeDescriptor的分析中我们可以知道,NameNode生成对应DataNode的删除指令,只是简单的从DatanodeDescriptor.invalidateBlocks对象中取出该DataNode上需要删除的数据块,封装成对应的BlockCommand(DatanodeProtocol.DNA_INVALIDATE, blockPoolId, blks)即可;
接下来分析一下BlockManager是如何生成对应的删除指令,也即是如何将BlockManager.invalidateBlocks队列中待删除的副本对象封装添加到对应的DatanodeDescriptor.invalidateBlocks对象中,其具体分析过程如下:
在BlockManager对象中,其拥有一个内部的线程类ReplicationMonitor; 在BlockManager初始化构造启动中,该ReplicationMonitor线程也会启动,其会周期性的调用computeDatanodeWork()方法触发数据块副本的复制和删除任务,然后调用processPendingReplications()方法将已产生复制请求但超时处理的数据块副本重新添加到neededReplications队列中,等待重新生成复制指令。
private class ReplicationMonitor implements Runnable {
@Override
public void run() {
while (namesystem.isRunning()) {
try {
// Process replication work only when active NN is out of safe mode.
if (namesystem.isPopulatingReplQueues()) {
computeDatanodeWork(); // 执行对应的复制操作和删除操作
processPendingReplications();
}
Thread.sleep(replicationRecheckInterval);
} catch (Throwable t) {
// ......
}
}
}
}computeDatanodeWork()方法执行了以下两个操作过程:
- 复制操作:从blockManager中的待复制数据块列表neededReplications中选出若干个数据块执行复制操作,为这些数据块的复制操作选出source源节点以及target目标节点,然后将其封装成BlockTargetPair对象添加到DatanodeDescriptor.replicateBlocks中,等待下次该DataNode心跳的时候将构造复制指令带到目标节点以执行副本的复制操作。
- 删除操作:从blockManager中的待删除数据块列表invalidateBlocks中选出若干个副本,然后构造删除指令,也即是将blockManager.invalidateBlocks中的待删除数据块添加到对应的DatanodeDescriptor.invalidateBlocks中,等待下次该DataNode心跳的时候将构造删除指令带到目标节点以执行副本的删除操作。
其基本的复制、删除操作逻辑流程如下:


接下来针对数据块副本删除操作,详细的分析下computeDatanodeWork()方法的工作流程:
int computeDatanodeWork() {
final int numlive = heartbeatManager.getLiveDatanodeCount();
final int blocksToProcess = numlive // 计算出需要复制操作的数据块数量
* this.blocksReplWorkMultiplier;
final int nodesToProcess = (int) Math.ceil(numlive // 计算出需要删除操作的数据块数量
* this.blocksInvalidateWorkPct);
// 计算出需要进行复制的副本
int workFound = this.computeReplicationWork(blocksToProcess);
// Update counters
// ......
// 计算出需要进行删除的副本
workFound += this.computeInvalidateWork(nodesToProcess);
return workFound;
}// 针对删除操作
int computeInvalidateWork(int nodesToProcess) {
// 从invalidateBlocks选出所有存在无效数据块的DataNode
final List<DatanodeInfo> nodes = invalidateBlocks.getDatanodes();
Collections.shuffle(nodes);
nodesToProcess = Math.min(nodes.size(), nodesToProcess); // 一次删除的数据块数量
int blockCnt = 0;
for (DatanodeInfo dnInfo : nodes) {
// 对每个数据节点调用invalidateWorkForOneNode()将待删除的数据块副本
// 添加到对应的DatanodeDescriptor.invalidateBlocks对象中
int blocks = invalidateWorkForOneNode(dnInfo);
if (blocks > 0) {
blockCnt += blocks;
if (--nodesToProcess == 0) {
break;
}
}
}
return blockCnt;
}private int invalidateWorkForOneNode(DatanodeInfo dn) {
final List<Block> toInvalidate;
try {
DatanodeDescriptor dnDescriptor = datanodeManager.getDatanode(dn);
// 在此处将对应需要删除的数据块添加到DatanodeDescriptor中
toInvalidate = invalidateBlocks.invalidateWork(dnDescriptor);
} catch(UnregisteredNodeException une) {
// ......
}
//invalidateBlocks#invalidateWork()
synchronized List<Block> invalidateWork(final DatanodeDescriptor dn) {
// ......
// # blocks that can be sent in one message is limited
final int limit = blockInvalidateLimit;
final List<Block> toInvalidate = set.pollN(limit);
// If we send everything in this message, remove this node entry
if (set.isEmpty()) {
remove(dn);
}
// 调用DatanodeDescriptor.addBlocksToBeInvalidated将待删除的数据块列表添加到
// DatanodeDescriptor.invalidateBlocks中
dn.addBlocksToBeInvalidated(toInvalidate);
numBlocks -= toInvalidate.size();
return toInvalidate;
}数据节点管理
数据节点启动时,会和名字节点进行RPC通信,主要包括握手、注册并进行数据块上报,然后定期发送心跳信息,维护和名字节点的联系。接下来主要来关注名字节点是如何管理数据节点的,包括:添加和撤销数据节点,数据节点启动时名字节点上执行的流程,心跳处理和名字节点的指令如何产生并下发等流程。
1、添加和撤销数据节点
HDFS在需要增加集群容器时,可以动态地往集群添加新的数据节点。相反,如果希望缩小集群的规模,那么需要撤销已存在的数据节点。如果一个数据节点频繁地发生故障或者进行缓慢,也可以通过撤销操作,将节点下架。上述操作让HDFS有了一定的弹性,可根据应用规模进行扩展或收缩。HDFS提供了dfs.hosts文件和dfs.hosts.exclude文件来对能够连接到名字节点的数据节点和不能连接到名字节点的数据节点进行明确的管理,以保证数据节点受集群控制,也可以防止配置错误的数据节点接入名字节点。
命令refreshNodes其实是使用远程接口ClientProtocol.refreshNode(),通过名字节点更新Include和exclude文件。该远程方法最终会由DataNodeManager.refreshNode()方法响应,refreshNode()方法首先会调用refreshHostsReader()方法将include文件与exclude文件加载到hostFileManager中,而后调用refreshDatanodes()刷新所有的数据节点。
其主要实现逻辑如下:
public void refreshNodes(final Configuration conf) throws IOException {
refreshHostsReader(conf); // 加载include文件与exclude文件到hostFileManager中
namesystem.writeLock();
try {
refreshDatanodes(); // 刷新所有的数据节点
countSoftwareVersions();
} finally {
namesystem.writeUnlock();
}
}
private void refreshDatanodes() {
for(DatanodeDescriptor node : datanodeMap.values()) { // 遍历所有的DatanodeDescriptor对象
// Check if not include.
if (!hostFileManager.isIncluded(node)) { // 不在include文件中
node.setDisallowed(true); // case 2. // 将DatanodeDescriptor.disallowed设置为撤销状态
} else {
if (hostFileManager.isExcluded(node)) { // 在exclude文件中,开始撤销操作
startDecommission(node); // case 3.
} else { // 不在exclude文件中,开取消撤销操作
stopDecommission(node); // case 4.
}
}
}
}撤销节点通过exclude文件,将要撤销的节点增加到文件中,然后还是执行“hadoop dfsadmin - refreshNodes”命令,名字节点就会开始撤销数据节点。被撤销节点上的数据块会复制到集群的其他数据节点,这个过程中,数据节点处于“正在撤销”状态,数据复制完成后才会转移到“已撤销”,这个时候就可以关闭相应的数据节点了。
2、数据节点的启动
添加数据节点并启动节点时,执行的流程和正常的数据节点启动是一样的。数据节点启动时,需要和名字节点进行握手、注册和数据块上报。如果系统支持Append操作,还需要上报处于客户端写状态的数据块信息。在之前的文章中已经分析了DataNode启动时的操作(DataNode启动流程分析),现在来看下NameNode侧的响应调用,即远程接口DatanodeProtocol的versionRequest()、registerDataNode()和blockReport()方法在名字节点上的实现。
(1)握手:握手请求是由NameNodeRpcServer实现,并最终调用FSNamesystem.getNamespaceInfo()并返回命名空间的信息。
public NamespaceInfo versionRequest() throws IOException { // NameNodeRpcServer中
checkNNStartup();
namesystem.checkSuperuserPrivilege();
return namesystem.getNamespaceInfo();
}
NamespaceInfo unprotectedGetNamespaceInfo() { // FSNamesystem中
return new NamespaceInfo(getFSImage().getStorage().getNamespaceID(),
getClusterId(), getBlockPoolId(),
getFSImage().getStorage().getCTime());
}(2)注册:远程方法registerDataNode()的主要处理逻辑在FSNamesystem.registerDatanode()中,NameNode会为注册的DataNode分配唯一的storageId作为标识(storageId在dataNodeMap中作为key,用于获取DatanodeDescriptor对象)。需要注意到数据节点可以重复发送注册信息,所以需要对DataNode注册时的不同情况进行不同的处理。
名字节点需要根据不同情况,对注册请求进行不同的处理如下:(详细源代码在DataNodeManager.registerDatanode()中):
- 该数据节点没有注册过。
- 数据节点注册过,这次注册时重复注册。
- 数据节点注册过,但这次注册使用了新的数据节点存储标识(storageID),表明该数据节点存储空间已经被清理了,原有的数据块副本已经被删除。
首先,registerDatanode()需要为注册节点生成数据节点标识,名字节点不能完全信任数据节点发送过来的信息,它需要根据实际情况更新注册信息中携带的数据节点标识,然后,使用这个标识进行后续的处理。在DataNodeManager中维护者两个DatanodeDescriptor对象的映射关系:
- 用nodeS表示从DataNodeManager.datanodeMap中通过storageId获取的DatanodeDescriptor对象;
- 用nodeN表示从DataNodeManager.host2DataNodeMap中通过hostname获取的DatanodeDescriptor对象;
if (!hostFileManager.isIncluded(nodeReg)) {
throw new DisallowedDatanodeException(nodeReg);
}
DatanodeDescriptor nodeS = getDatanode(nodeReg.getDatanodeUuid());
DatanodeDescriptor nodeN = host2DatanodeMap.getDatanodeByXferAddr(
nodeReg.getIpAddr(), nodeReg.getXferPort());
1、数据节点未注册:nodeS==null && nodeN==null;创建新的数据节点描述符、获得节点的网络拓扑位置、添加节点到datanodeMap、host2DataNodeMap和心跳信息列表heartbeats中。
// 创建新的数据节点描述对象
DatanodeDescriptor nodeDescr
= new DatanodeDescriptor(nodeReg, NetworkTopology.DEFAULT_RACK);
boolean success = false;
try {
// resolve network location
// 更新网络拓扑
if(this.rejectUnresolvedTopologyDN) {
nodeDescr.setNetworkLocation(resolveNetworkLocation(nodeDescr));
nodeDescr.setDependentHostNames(getNetworkDependencies(nodeDescr));
} else {
nodeDescr.setNetworkLocation(
resolveNetworkLocationWithFallBackToDefaultLocation(nodeDescr));
nodeDescr.setDependentHostNames(
getNetworkDependenciesWithDefault(nodeDescr));
}
networktopology.add(nodeDescr);
nodeDescr.setSoftwareVersion(nodeReg.getSoftwareVersion());
// register new datanode
// 注册节点 添加节点到datanodeMap、host2DataNodeMap
addDatanode(nodeDescr);
checkDecommissioning(nodeDescr);
// 添加到心跳信息列表heartbeats中
heartbeatManager.addDatanode(nodeDescr);
success = true;
incrementVersionCount(nodeReg.getSoftwareVersion());
} finally {
// ......
}2、数据节点重复注册,nodeS!=null;由于名字节点已经拥有该节点的信息,这时只需用新的注册信息更新NameNode中保存的原有的DataNode信息即可,更新节点在网络拓扑中的位置和(可能的)心跳信息。
// 更新网络拓扑、节点信息
getNetworkTopology().remove(nodeS);
if(shouldCountVersion(nodeS)) {
decrementVersionCount(nodeS.getSoftwareVersion());
}
nodeS.updateRegInfo(nodeReg);
nodeS.setSoftwareVersion(nodeReg.getSoftwareVersion());
nodeS.setDisallowed(false); // Node is in the include list
// resolve network location
nodeS.setNetworkLocation(resolveNetworkLocation(nodeS));
nodeS.setDependentHostNames(getNetworkDependencies(nodeS));
getNetworkTopology().add(nodeS);
// also treat the registration message as a heartbeat
heartbeatManager.register(nodeS);3、使用新的数据节点存储标识(storageID)注册,nodeN!=null && nodeN!=nodeS;即原先在DataNode上保存的数据块失效,需要先清理NameNode中这个DataNode的信息。操作流程为:nodeN即是原有老数据节点标识,利用这个标识,通过DataNodeManager的removeDatanode()和wipeDatanode()方法,清理原有节点在名字节点中保存的信息,并将nodeN设置为空,后续的处理,就和请求一数据节点未注册情况是一致的。
if (nodeN != null && nodeN != nodeS) {
removeDatanode(nodeN); // 删除DatanodeDescriptor对象
wipeDatanode(nodeN); // 从datanodeMap、host2DataNodeMap中删除
nodeN = null;
}其中removeDatanode()删除了NameNode内存中所有该DataNode对应的DatanodeDescriptor对象,同时从BlockManager.blocksMap中删除该DataNode存储的数据块副本;wipeDatanode()方法将DataNodeManager内部的datanodeMap、host2DataNodeMap中包含的DatanodeDescriptor对象删除。
private void removeDatanode(DatanodeDescriptor nodeInfo) {
assert namesystem.hasWriteLock();
heartbeatManager.removeDatanode(nodeInfo);
blockManager.removeBlocksAssociatedTo(nodeInfo);
networktopology.remove(nodeInfo);
decrementVersionCount(nodeInfo.getSoftwareVersion());
namesystem.checkSafeMode();
}
private void wipeDatanode(final DatanodeID node) {
final String key = node.getDatanodeUuid();
synchronized (datanodeMap) {
host2DatanodeMap.remove(datanodeMap.remove(key));
}
blockManager.removeFromInvalidates(new DatanodeInfo(node));
}(3)数据块上报:成功注册的数据节点,接下来会进行数据块上报,向名字节点提供它的数据块信息,该请求的主要处理实现是BlockManager.processReport()中。在处理中,如果是第一次块汇报,则会调用processFirstBlockReport(),否则调用processReport()方法进行处理;其基本区别如下(具体分析可参照源码):
- processFirstBlockReport:将块汇报中所有有效的副本快速加入到NameNode中,其并不会考虑和操作存储数据块副本的队列(如corruptReplicas)
- processReport:将块汇报中的数据块副本和NameNode中保存的副本状态做对比,并将其添加到不同的副本状态管理对象中。如方法变量toInvalidate中就保存了要删除的数据块副本,这些副本最终通过addToInvalidates()方法,添加到BlockManager的成员变量invalidateBlocks中。
public boolean processReport(final DatanodeID nodeID,
final DatanodeStorage storage,
final BlockListAsLongs newReport, BlockReportContext context,
boolean lastStorageInRpc) throws IOException {
try {
// ......
if (storageInfo.getBlockReportCount() == 0) {
// 第一次数据块汇报
processFirstBlockReport(storageInfo, newReport);
} else {
// 不是第一次数据块汇报 调用私有的processReport()方法
invalidatedBlocks = processReport(storageInfo, newReport);
}
boolean staleBefore = storageInfo.areBlockContentsStale();
storageInfo.receivedBlockReport();
}
// ......
}3、心跳
在BPServiceActor.offerService()中,数据节点利用循环向节点发送心跳信息,维护它们间的关系,上报负载信息并获取名字节点指令。名字节点和数据节点心跳相关的代码可以分为两部分:心跳信息处理和心跳检查。
(1)心跳信息处理:NameNodeRpcServer.sendHeartbeat()被DataNodeManager.handleHeartbeat()响应调用,心跳信息处理如下:
- 首先是对发送请求的数据节点进行检查,判断该节点是否能连接到名字节点。同时也判断数据节点是否已经注册过,未注册的数据节点会收到DatanodeCommand.REGISTER指令,这时,节点要重新注册并上报数据块信息。
- 名字节点利用心跳信息中的负载信息,调用heartbeatManager.updateHeartbeat()方法更新整个HDFS系统的负载信息。DatanodeDescriptor.updateHeartbear()不但更新节点负载,同时也更新了节点的心跳时间。
- 名字节点会为这个数据节点产生名字节指令,并通过远程调用的返回值返回。其中DatanodeCommand.REGISTER,就是一种名字节点指令。
handleHeartbet()方法一般通过DatanodeDescriptor的对应方法产生名字节点指令,下面代码中的删除数据块副本指令,就是通过getInvalidateBlocks()方法获得,其从DatanodeDescriptor中成员变量invalidateBlocks中获取要删除的副本列表,并根据列表创建删除命令。代码如下:
/** Handle heartbeat from datanodes. */
public DatanodeCommand[] handleHeartbeat(DatanodeRegistration nodeReg,
StorageReport[] reports, final String blockPoolId,
long cacheCapacity, long cacheUsed, int xceiverCount,
int maxTransfers, int failedVolumes
) throws IOException {
synchronized (heartbeatManager) {
synchronized (datanodeMap) {
DatanodeDescriptor nodeinfo = null;
// 未注册,则先发送注册指令进行注册
try {
nodeinfo = getDatanode(nodeReg);
} catch(UnregisteredNodeException e) {
return new DatanodeCommand[]{RegisterCommand.REGISTER};
}
// Check if this datanode should actually be shutdown instead.
if (nodeinfo != null && nodeinfo.isDisallowed()) {
setDatanodeDead(nodeinfo);
throw new DisallowedDatanodeException(nodeinfo);
}
if (nodeinfo == null || !nodeinfo.isAlive) {
return new DatanodeCommand[]{RegisterCommand.REGISTER};
}
// 负载信息及心跳时间的更新
heartbeatManager.updateHeartbeat(nodeinfo, reports,
cacheCapacity, cacheUsed,
xceiverCount, failedVolumes);
// If we are in safemode, do not send back any recovery / replication
// requests. Don't even drain the existing queue of work.
if(namesystem.isInSafeMode()) {
return new DatanodeCommand[0];
}
// ......
// 名字节点指令的生成,此处只展示删除数据块指令
//check block invalidation
Block[] blks = nodeinfo.getInvalidateBlocks(blockInvalidateLimit);
if (blks != null) {
cmds.add(new BlockCommand(DatanodeProtocol.DNA_INVALIDATE,
blockPoolId, blks));
}
if (!cmds.isEmpty()) {
return cmds.toArray(new DatanodeCommand[cmds.size()]);
}
}
}
return new DatanodeCommand[0];
}(2)心跳检查:心跳信息的处理由远程方法sendHeartbeat()实现。DatanodeManager中和心跳相关的另一部分代码是心跳检查,由HeartbeatManager类实现,其拥有自己的线程Monitor,并定期通过调用heartbeatCheck()执行检查逻辑。心跳检查的间隔保存在成员变量heartbeatRechekInterval中,默认值是5分钟,可以通过配置项${dfs.namenode.heartbeat.recheck-interval}配置。代码如下:
private class Monitor implements Runnable {
private long lastHeartbeatCheck;
private long lastBlockKeyUpdate;
@Override
public void run() {
while(namesystem.isRunning()) {
try {
final long now = Time.now();
if (lastHeartbeatCheck + heartbeatRecheckInterval < now) {
heartbeatCheck(); // 检查心跳更新情况(会有对应的故障处理)
lastHeartbeatCheck = now;
}
// ......
} catch (Exception e) {
// ......
}
try {
Thread.sleep(5000); // 5 seconds
} catch (InterruptedException ie) {
}
}
}
}
















 2143
2143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









