







 面对非平衡数据集,模型训练效果往往受到严重影响。准确率、召回率和F1分数等传统指标不能准确反映不平衡数据的效果。混淆矩阵、AUC作为评估工具,能更好地分析模型性能。对于不平衡数据,模型可能倾向于输出多数类,导致少数类识别不足。AUC作为二分类模型的评价指标,尤其适用于样本不平衡场景。
面对非平衡数据集,模型训练效果往往受到严重影响。准确率、召回率和F1分数等传统指标不能准确反映不平衡数据的效果。混淆矩阵、AUC作为评估工具,能更好地分析模型性能。对于不平衡数据,模型可能倾向于输出多数类,导致少数类识别不足。AUC作为二分类模型的评价指标,尤其适用于样本不平衡场景。
在做实验中遇到了非平衡数据集,导致实验结果很忧伤,数据类别不均对模型训练有挺大影响,尤其是在类别极度不均的时候。目前还没有很好的解决方法,还处于查找资料,比着葫芦找葫芦的过程中,记录一下,或许能有所启发。
对于不平衡数据,其实类别精度(precise)和召回率(recall),或者是准确率(accuracy)这些指标并不能很好的反映出来效果如何。比如97个正样本,3个负样本,在识别的时候,全部识别为正样本,则准确率就会达到97%,但是一个负样本都木有检测出来,如果用作异常检测,这也是毫无作用的。
从知乎专栏找了有关评价标准的一些表述,感觉很通俗易懂,借鉴一下,若侵犯版权,请告知,删掉。
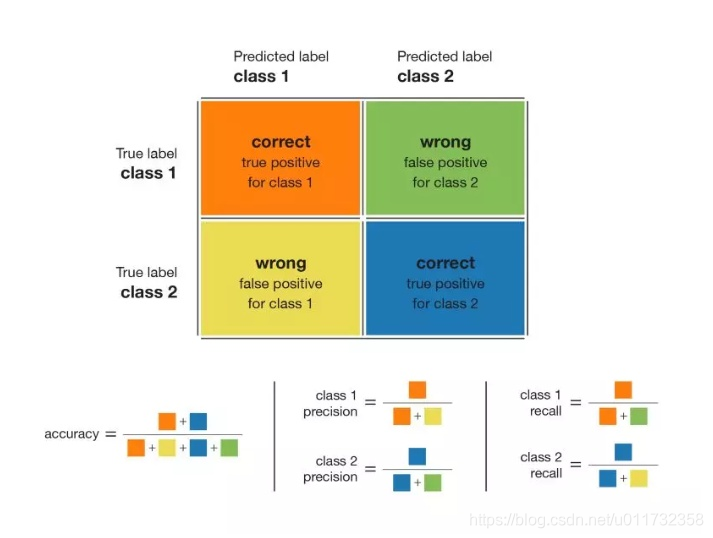
混淆矩阵、精度、召回率和 F1
在处理分类问题时,一个很好且很简单的指标是混淆矩阵(confusion matrix)。该指标可以很好地概述模型的运行情况。因此,它是任何分类模型评估的一个很好的起点。上图总结了从混淆矩阵中可以导出的大部分指标:
准确率(accuracy)就是正确预测的数量除以预测总数;
类别精度(precision)表示当模型判断一个点属于该类的情况下,判断结果的可信程度。
类别召回率
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1920
1920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









