







 文章讨论了在PyTorch中尝试同时训练两个模型时遇到的问题,特别是当一个模型的输出被用于另一个模型的学习时。作者提到了在计算图中使用detach()函数来防止不需要的梯度传播,以此解决报错问题。文章引用了AAE(对抗自编码器)的实现作为例子,强调在特定计算步骤后使用detach()的必要性。
文章讨论了在PyTorch中尝试同时训练两个模型时遇到的问题,特别是当一个模型的输出被用于另一个模型的学习时。作者提到了在计算图中使用detach()函数来防止不需要的梯度传播,以此解决报错问题。文章引用了AAE(对抗自编码器)的实现作为例子,强调在特定计算步骤后使用detach()的必要性。
20230302
引言
在进行具体的研究时,利用Torch进行编程,考虑到是不是能够同时训练两个模型呢?!而且利用其中一个模型的输出来辅助另外一个模型进行学习。这一点,在我看来应该是很简单的,例如GAN网络同时训练这个生成器和判别器。但是实际操作中,却发现一直报错。
之前的时候利用Keras进行AAE(对抗自编码器)的编程的时候,他是把其中一个模型的参数trainable(应该是这个名字)定义为了false。
分析
在帖子[1]中,基本上完整的说明了我的问题,首先是实际往后推梯度直接报错,如下图。然后提议把这个retain_graph设置好;

设置了之后呢,依然是会报错:

这个报错过程,跟我写的程序是一模一样的。另外一个帖子[2],两者给出的解答方式都是添加detach()。实际上,我理解哈,(之前最开始的时候看过计算图的相关内容,后来有点忘了),就是在第一个损失函数推完之后,这部分他的梯度已经没有了,那么再使用第一个模型中的输出变量与第二个模型进行计算的时候,这部分也会输出一部分梯度到这个第一个模型上,但是本质上,你已经不需要在进行计算了,而这个梯度可能还会遗留到后续,所以会出现这种报错。(通俗理解,可能内部细节更多)
而添加detach()之后,就是为了吧这个变量从计算图中取出来,但是不用计算梯度,见文章[3]。所以可以解决这个问题。如果这样话,其实retain_graph变量可以依然是false。具体可以看AAE这部分的代码
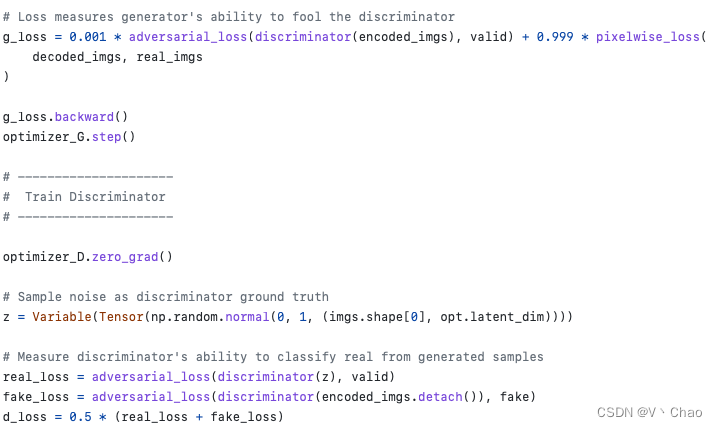
这部分核心在于最后部分计算的时候,encoded_img已经用过了,而且梯度也推完了,那么后面再次使用的时候,就需要加上detach()。
参考
[1]How to train Two models simultaneously?
[2]Training multiple models at the same time
[3]pytorch .detach() .detach_() 和 .data用于切断反向传播
[4]PyTorch-GAN/implementations/aae/aae.py

















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









