







一、背景:
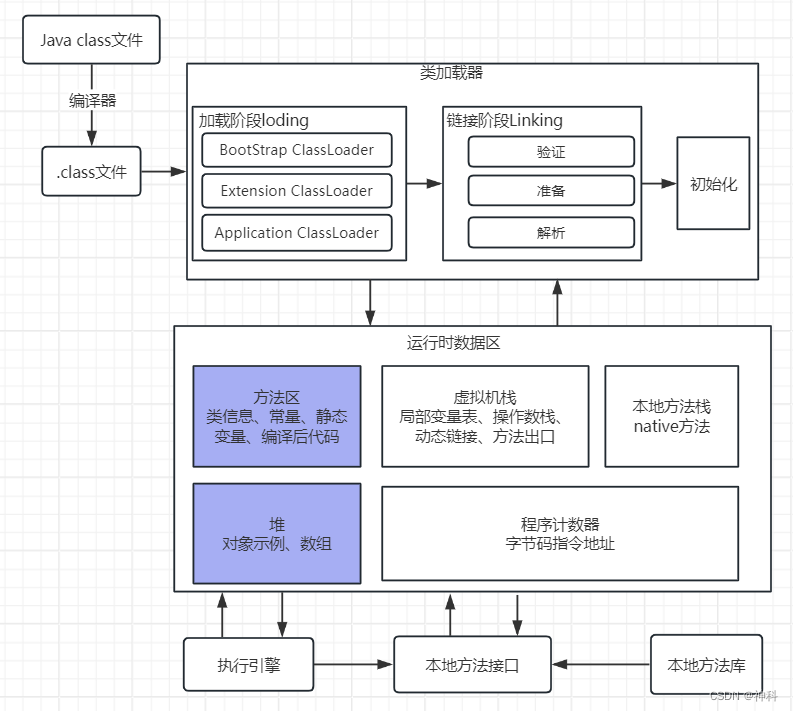
.class文件 -> 类加载器 -> 运行时数据区 -> 执行引擎 -> 本地方法 -> 执行指令
执行引擎:对命令进行解析,将字节码翻译程系统指令
本地库接口:调用其他语言的原生库为java所用
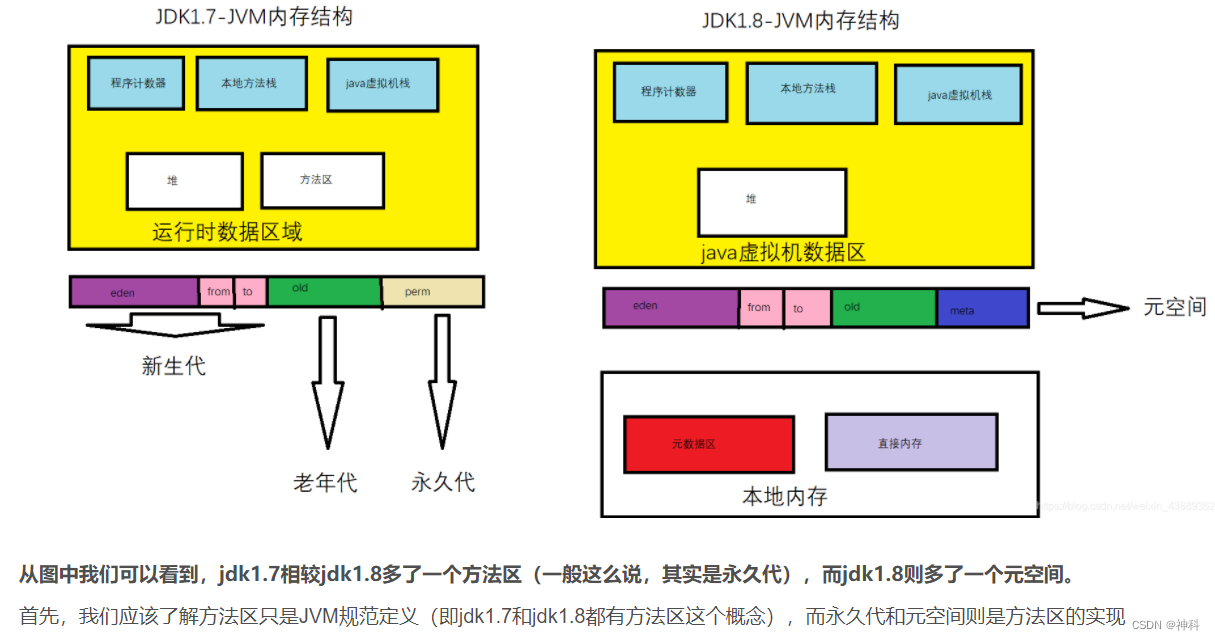
1、方法区:
线程共享
存储:虚拟机加载的类信息,编译器编译后的代码数据,运行时常量池(编译期生成的各种字面量和符号+运行期产生常量),【字符串常量池、静态变量 jdk1.7后移到堆中】。
问题:内存不足oom
别名Non-Heap 非堆,jdk1.7前永久代实现方法区,jdk1.8元空间实现方法区存在本地内存
回收内容:常量池废弃的常量+不再使用的类型
2、java堆:
线程共享
存储:对象实例和数组
问题:空间不足OOM
3、虚拟机栈:
线程私有
存储局部变量表、操作数栈、动态链接、方法出口等
问题:栈深度不足StackOverError,内存不足OOM
4、本地方法栈
线程私有
存储本地方法服务栈信息
5、程序计数器
线程私有
存储线程执行位置
没有溢出错误
掌握Java虚拟机(JVM)需考虑两方面,其一是理解垃圾回收、其二是JVM调优
1、垃圾回收:什么时候回收、回收哪些、怎么回收 三方面
2、JVM调优:提高应用响应速度、吞吐、资源利用率
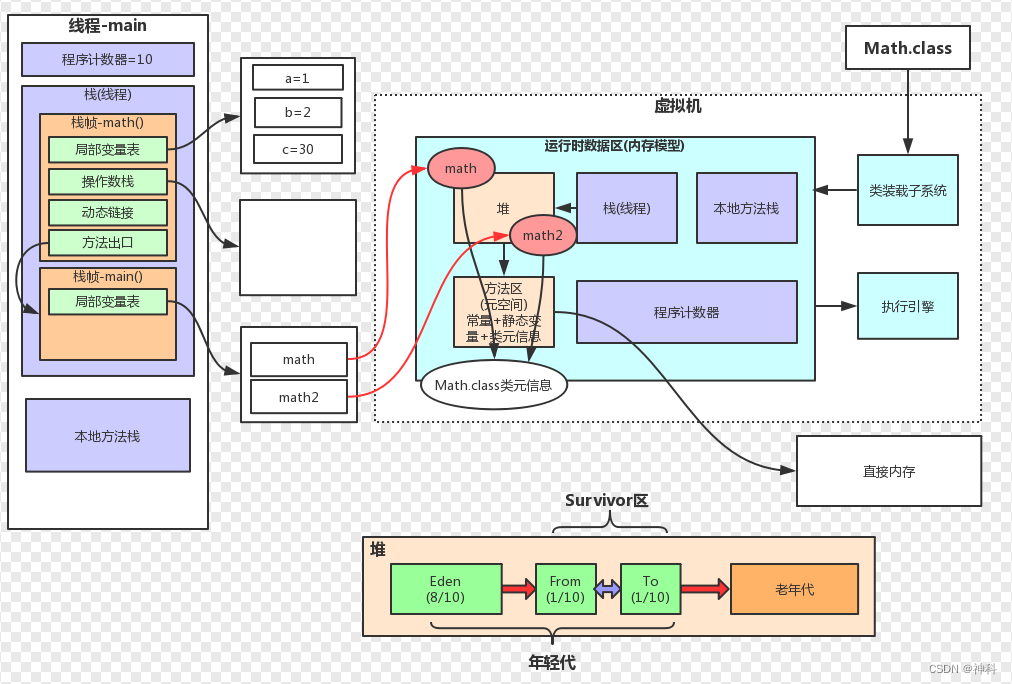
类加载器 -> 运行时数据区 -> 执行引擎 -> 本地库接口
二、垃圾回收
1、什么时候回收
Minor GC:Eden区空间不足,进行Minor GC,回收Eden区,未被回收存入Survivor,15次GC(参数:-XX:+MaxTenuringThreshold=15)后还存活,进入老年区
Full GC:
老年区空间不足:年轻对象多 或 大对象(15次 Minor GC后进入老年代空间不足)
方法区满了:(jdk及之后版本元空间替代永久代)
System.gc()调用
永久区满了:(jdk7及之前版本)
补充:1、方法区回收主要分为废弃的常量池和不在使用的类型。
判定废弃常量明确:常量池中的常量没有被任何地方引用,就可以被回收
判定不在使用的类型严格:
1)该类所有的实例都已经被回收,也就是 Java 堆中不存在该类及其任何派生子类的实例。
2)加载该类的类加载器已经被回收,这个条件除非是经过精心设计的可替换类加载器的场景,如 OSGi、JSP 的重加载等,否则通常是很难达成的。
3)该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法
2、jdk不同版本方法区调整

3、元空间替代永久代原因:
1)、永久代GC回收率低(full gc触发),调优困难,字符串存在永久代,容易出现内存溢出
2)、类及方法的信息大小难确定,永久代大小指定难,太小容易永久代溢出,太大容易老年代溢出
3)、元空间和类加载器生命周期一致,GC发现类加载器不在存活,会将相关空间都回收了
2、回收哪些
GC回收不在存活的对象,判断对象是否存活,有引用计数算法和可达性分析算法,其中引用计数算法难解决循环引用问题,当前主流语言采用可达性分析算法
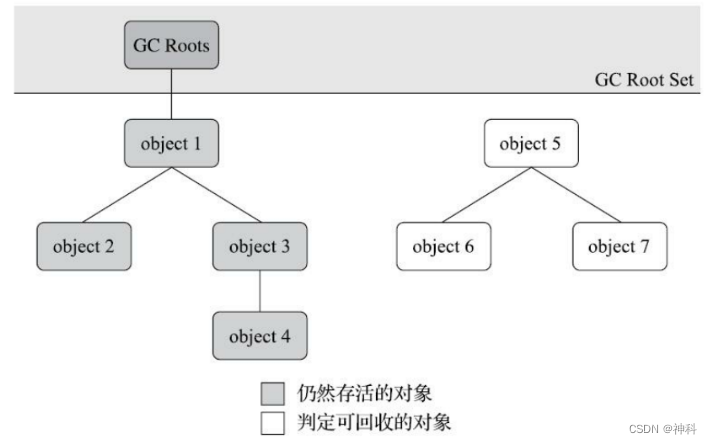
GC Roots对象:
1、栈中引用的对象
2、方法区中的静态引用对象
3、方法区中的常量引用对象
4、本地方法栈(native方法)引用对象
5、同步锁持有的对象
3、怎么回收
1、标记-清除(Mark-Sweep):标记无用对象,进行清除回收。缺点:效率不高,无法清除垃圾碎片
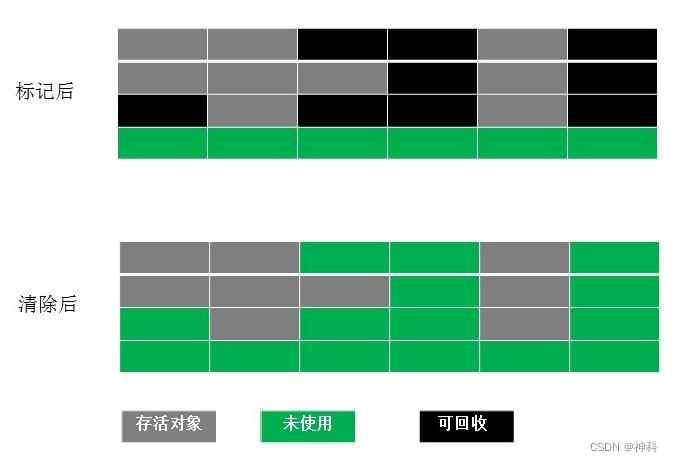
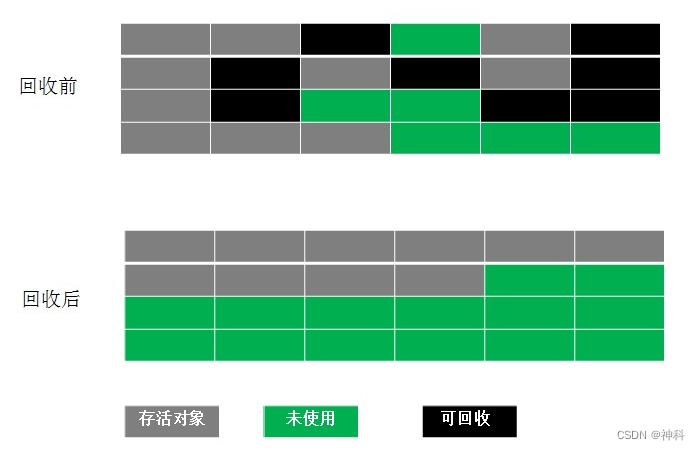
2、复制(Coping):解决Mark-Sweep缺陷 ,将可用内存一分为二两个相等内存块,当一块内存用完将存活对象复制到另外一块内存块,然后将已使用内存块清理掉。缺点:内存使用率不高,只有原来一半
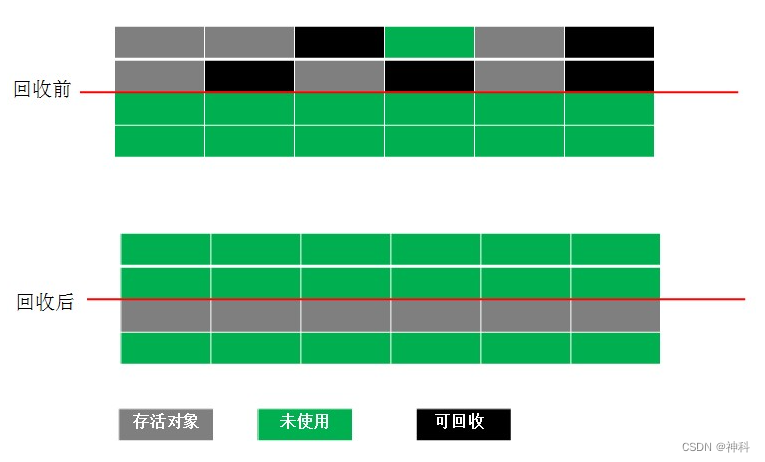
3、标记-整理(Mark-Compact):解决Coping算法缺陷,标记无用对象,存活的对象都向一端移动,然后清除掉端边界以外的内存。
4、分代(Generational Collection):根据对象存活周期将内存划分若干个不同区域。一般采用新生代和老年代,因为新生代大部分对象存活周期短,回收对象多(需要复制的操作少),采用复制算法;老年代特点存活周期长,回收对象少,采用标记整理算法
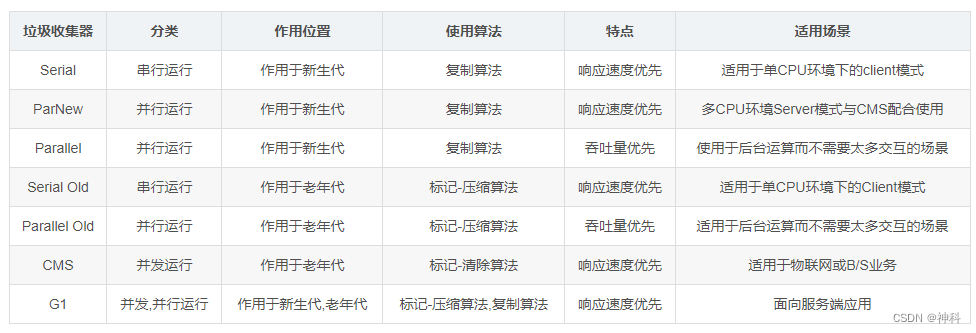
4、常见垃圾回收器 CMS - 6~8G - G1
1、CMS回收器:以最短回收停顿为目标的一款并发收集、低停顿。采用标记-清除算法,若干次后执行一次碎片清理
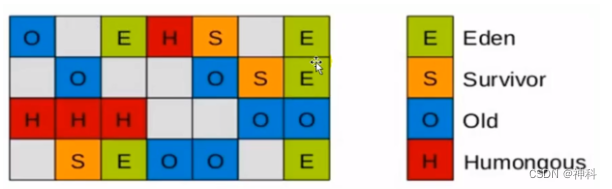
2、G1回收器:优点:空间整合+可预测的停顿时间模型;缺点:额外执行负载比CMS高。将java堆分成2048个相同独立Region块,根据堆空间大小动态控制在1~32MB且为2的N次幂带大小,基于“标记-整理”算法实现收集器
3、ZGC:指针染色技术 读屏障
4、其他收集器:
5、常见面试问题:<JVM笔记:内存与垃圾回收>7-方法区_java1.7方法区回收条件-优快云博客
1、百度:JVM内存模型,每个区作用
2、阿里:JVM为什么两个 survivor 区?eden和survivor设计解决问题
1)、JVM 为什么两个 survivor 区:解决内存碎片化,基于新生代Coping算法实现需要;
2)、eden和survivor设计解决问题:
A、提高垃圾回收率:新生代大部分对象存活周期短,回收对象多,Minor GC更容易对生命周期短对象回收;也避免Full GC的全区扫描,提高垃圾回收率
B、避免过早晋升到老年代:过早晋升老年代容易导致老年代空间不足触发Full GC
3、小米:JVM为什么设计新生代和老年代?
1)、对象存活周期不同
2)、回收算法不同
4、字节跳动:JVM什么时候对象会进入老年代?
1)、15次 Minor GC 后进入老年代:-XX:MaxTenuringThreshold
2)、survivor幸存区对象占用内存大于50%平均年龄以上对象进入老年代
3)、大对象直接进入老年代:-XX:PretenureSizeThreshold(避免大对象多次GC不清理,且多次在survivor内存复制)
4)、Minor GC后对象超过survivor
5)、老年代空间担保规则:XX:-HandlePromotionFailure=true jdk7参数移除
5、jvm 的方法区会发生垃圾回收吗?
A、废弃的常量池:常量池中的常量没有被任何地方引用,就可以被回收
B、不在使用的类型:
1)该类所有的实例都已经被回收,也就是 Java 堆中不存在该类及其任何派生子类的实例。
2)加载该类的类加载器已经被回收,这个条件除非是经过精心设计的可替换类加载器的场景,如 OSGi、JSP 的重加载等,否则通常是很难达成的。
3)该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法
三、JVM调优
1、jdk自带工具:
1)、jps:查看正在运行java进程 -l -v -m
2)、jstat:查看jvm统计信息:jstat -gc 27580 1s 3
3)、jmap:内存使用情况: jmap -dump:format=b,file=heapdump.hprof 27580
4)、jinfo:实时查看jvm配置参数
5)、jstack:打印jvm中线程快照:jstack -l 2990 > /sk/jstack.txt
四、arthas工具使用
Arthas使用教程(8大分类)-优快云博客^v100^pc_search_result_base2&utm_term=arthas%E4%BD%BF%E7%94%A8&spm=1018.2226.3001.4187
五、1.7和1.8区别:转载jvm内存模型jdk1.7和jdk1.8的区别_weixin_43889362的博客-优快云博客
- 主要成员
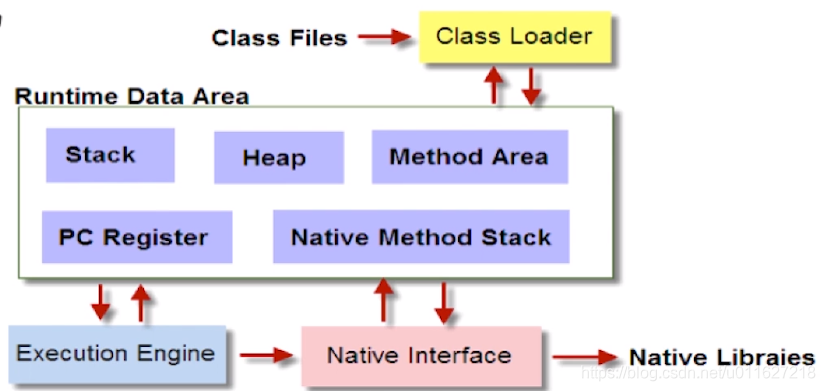
编译器:将java转换成.class字节码文件
类加载器(ClassLoader):将字节码二进制流加载到内存中,转换为JVM中的Class<>对象

运行时数据区(Runtime Data Area):
执行引擎(Execution Engine):对命令进行解析,将字节码翻译成底层系统指令
本地库接口(Native Interface):融合不同开发语言的原生库为java所用
组件的作用:
1、类加载器把 Java 代码(java文件)转换成字节码(.class)。再由不同平台的JVM解析,命令javac -xx.java转换成.class文件;javap -c xx.xlass对代码进行反汇编
2、运行时数据区(Runtime Data Area)再把字节码加载到内存中,而字节码文件只是 JVM 的一套指令集规范,并不能直接交给底层操作系统去执行,
自定义ClassLoader:
2.1、继承ClassLoader
2.2、重写findclass方法:自定义获取class,并调用defineClass
3、因此需要特定的命令解析器执行引擎(Execution Engine),将字节码翻译成底层系统指令,再交由 CPU 去执行
4、而这个过程中需要调用其他语言的本地库接口(Native Interface)来实现整个程序的功能。
- JVM运行时数据区
程序计数器(Program Counter Register):当前线程所执行的行号指示器,字节码解析器的工作室通过改变这个计数器的值,来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能,都需要依赖这个计数器来完成
Java虚拟机栈(Java Virtual Machine Stacks):用于存储局部变量表、操作数栈、动态链接、方法出口等信息
本地方法栈(Native Method Stack):与虚拟机栈的作用是一样的,只不过虚拟机栈是服务java方法的,而本地方法栈是为虚拟机调用本地方法服务的
Java堆(Java heap):Java虚拟机中内存最大的一块,是被所有线程共享的,几乎所有的对象示例都在这里分配内存
方法区(Methed Area):用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等数据
- 反射
动态获取信息和动态调用方法:把java类中映射各个对象
1、获取类:Class a = Class.forName("全路径");
2、初始化:a.newInstance();强转对象
3、获取方法对象:Method c = a.getDeclaredMethod("方法名",参数类.class);不能获取继承方法和所实现接口方法
Method c = a.getMethod("方法名",参数类.class);不能获取私有方法
4、调用方法:c.invoke(a,"参数");c.setAccessible(私有方法设置)
5、获取属性对象:Filed f = a.getDeclaredFiled(“属性名称”);
6、对象赋值:f.set("值")
- 类的加载方式
隐式加载 new
显示加载 loadClass forname(通过newinstance())
- 堆栈区别
功能:堆是用来存放数组或对象的,栈是用来执行程序的
共享性:堆是线程共享,栈是线程私有
空间:堆远大于栈
数据共享的有栈、寄存器、PC,线程共享的有:堆、全局变量、静态变量、方法区。栈和常量池中的数据可以共享,即可以有多个引用对象(int a=3,int b=3);堆来说,数据不可以共享(String a=new ("3")),String b = new String ("3");
- 双亲委派模型
如果一个类加载器收到了类加载的请求,它首先不会自己去加载这个类,而是把这个请求委派给父类加载器去完成,每一层的类加载器都是如此,这样所有的加载请求都会被传送到顶层的启动类加载器中,只有当父加载无法完成加载请求(它的搜索范围中没找到所需的类)时,子加载器才会尝试去加载类
-
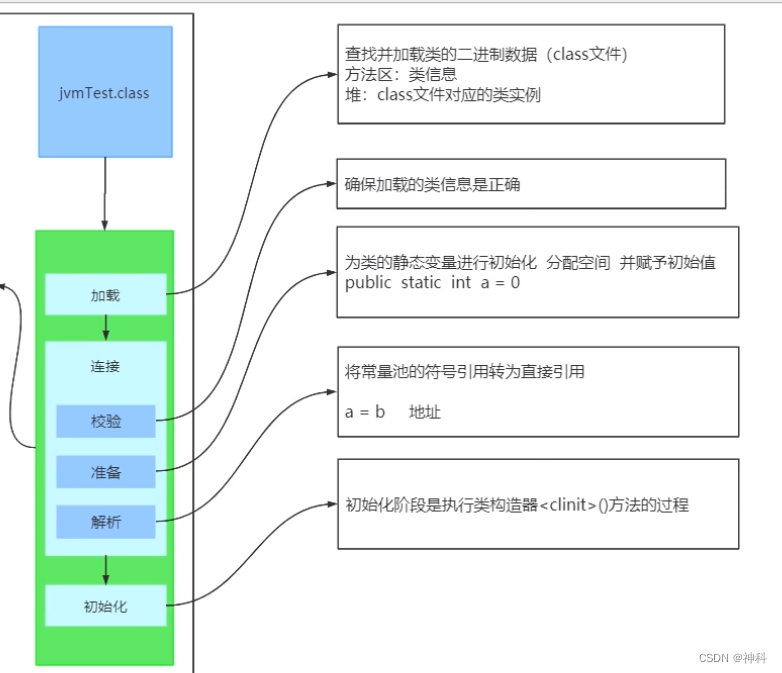
类装载过程
加载:通过classloader加载class文件字节码,生成.class对象
检查:检查加载class文件的正确性和安全性
准备:为类变量分配存储空间和设置类变量初始值
解析:JVM将常量池内的符号引用转换为直接引用
初始化:执行类变量赋值和代码块
- classloader和forname的区别
classloader:loadclass(name,false),解析为false,没有初始化。例如:spring ioc延迟加载
class.forname:
- java内存模型
线程私有:程序计数器、java虚拟机栈、本地方法栈(native)
线程共享:MetaSpace、Java堆
- java虚拟机栈
递归过深,栈帧数超出虚拟栈深度(引发java.lang.StackOverflowError)。每次递归,都会往栈里压一个栈帧,如果超过允许最大允许虚拟栈深度
解决思路:限制递归次数,或者使用循环的方法去替换递归
- MetaSpace(类加载信息)
jdk1.8之前:元数据(MetaSpace)与永久代(PermGen)
元数据使用本地内存,永久代使用的是jvm的内存
- MetaSpace比PermGen优势
字符串常量池存在永久代中,容易出现性能问题和内存溢出。jdk1.7把常量池移到堆内存中,jdk1.8移除永久代
类和方法的信息大小难易确定,给永久代的大小制定带来问题
永久代会为GC带来不必要的复杂性
- java堆(Heap 常量池、数组和类对象)
在虚拟机启动时创建,是对象实例的分配区域。占主要内存
GC的管理主要区域
- 判断对象是否被回收
引用计数器:为每个对象创建一个计数,有对象引用计数器+1,引用释放计数-1,当计数器为0时回收。缺点是不能解决循环引用问题
可达性分析:从GC Roots开始向下搜索,搜索所走过的路径称为引用链。当一个对象到GC Roots没有任何引用链时,此对象可以被回收
- 不同JDK版本之间的intern()方法的区别-JDK6 VS JDK6+(不同JDK版本之间的intern()方法的区别-JDK6 VS JDK6+ - zhangniuniu - 博客园)
JDK6:当调用intern()方法时,如果字符串常量池先前已创建出该字符串对象,则返回池中的该字符串的引用。否则,将此字符串对象添加到字符串常量池中,并且返回该字符串的引用。
我的理解:JDK6当调用intern()方法时,如果常量池存在不处理;如果常量池不存在,拷贝副本到常量池中。
JDK6+:当调用intern()方法时,如果字符串常量池先前已创建出该字符串对象,则返回池中的该字符串的引用。否则,如果该字符串对象已经存在于Java堆中,则将堆中此对象的引用添加到字符串常量池中,并且返回该引用;如果堆中不存在,则在池中创建该字符串并返回其引用。
我的理解:JDK6+当调用intern()方法时,如果常量池存在不处理;如果常量池不存在:堆已存在,将堆的引用存放在常量池中;堆不存在,在常量池创建
注:在JDK1.6的时候,字符串常量池是存放在Perm Space中的(PermSpace和堆是相隔而开的),在1.6+的时候,移到了堆内存中
- java引用类型
- JVM垃圾回收算法
标记-清除算法:标记无用对象,然后进行清除回收。缺点:效率不高,无法清除垃圾碎片。
标记-整理算法:标记无用对象,让所有存活的对象都向一端移动,然后直接清除掉端边界以外的内存。
复制算法:按照容量划分二个大小相等的内存区域,当一块用完的时候将活着的对象复制到另一块上,然后再把已使用的内存空间一次清理掉。缺点:内存使用率不高,只有原来的一半。
分代算法:根据对象存活周期的不同将内存划分为几块,一般是新生代和老年代,新生代基本采用复制算法,老年代采用标记整理算法。
-
Java Bean生命周期
-
JVM配置列表
-Xss:每个线程虚拟机栈大小
-Xms:java堆的初始值(一般设置和Xmx一致,防止堆扩展影响)
-Xmx:java堆达到最大值
- 内存分配策略
静态存储:编译时确定每个数据目标在运行时的存储空间需求
栈式存储:数据区需求在编译时未知,运行时模块入口
Linux查看进程和线程:
1、查看所有进程线程数:pstree -p | wc -l
2、查看指定进程线程数:pstree -p pid | wc -l
3、查看系统用户最大进程数:ulimit -u
4、查看系统支持最大线程数:cat /proc/sys/kernel/pid_max

















 1654
1654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









