







 本文介绍了几种常见的神经网络激活函数,包括Sigmoid、tanh、ReLU、Leaky ReLU和Softmax。Sigmoid和tanh存在梯度消失问题,ReLU因其线性特性加速了训练,但可能导致神经元死亡;Leaky ReLU是ReLU的改进版,解决负区梯度消失问题;Softmax用于多分类任务,输出概率分布。在选择激活函数时,优先考虑ReLU家族,避免使用sigmoid和tanh在隐藏层。
本文介绍了几种常见的神经网络激活函数,包括Sigmoid、tanh、ReLU、Leaky ReLU和Softmax。Sigmoid和tanh存在梯度消失问题,ReLU因其线性特性加速了训练,但可能导致神经元死亡;Leaky ReLU是ReLU的改进版,解决负区梯度消失问题;Softmax用于多分类任务,输出概率分布。在选择激活函数时,优先考虑ReLU家族,避免使用sigmoid和tanh在隐藏层。
1.Sigmoid
Sigmoid散活函数是将一个实数输入转化至 0 ~ 1 之间的输出, 具体来说也就是将越大的负数转化到越靠近 0 ,越大的正数转化到越靠近1。多用于二分类。


缺点:
1).Sigmoid 函数会造成梯度消失。一个非常不好的特点就是 Sigmoid 函数在靠近1和0 的两端时,梯度会几乎变成 0,会导致无法更新参数, 即梯度消失。
2). Sigmoid 输出不是以 O 为均值,这就会导致经过 Sigmoid 激活函数之后的输出,作为后面一层网络的输入的时候是非 0 均值的,这个时候如果输入进入下一层神经元的时候全是正的,这就会导致梯度全是正的,那么在更新参数的时候永远都是正梯度。
2.tanh
将输入的数据转化到一 1 ~ 1 之间,可以通过图像看出它将输出变成了 O 均值,在一定程度上解决了 Sigmoid 函数的第二个问题,但是它仍然存在梯度淌夫的问题。因
此实际上 Tanh 激活用数总是比 Sigmoid 激活函数更好。
3.ReLU
ReLU函数又称为修正线性单元(Rectified Linear Unit),是一种分段线性函数,其弥补了sigmoid函数以及tanh函数的梯度消失问题。
![]()
优点:
(1) 相比于 Sigmoid 激活函数和 Tanh ì.敖活函数, ReLU i脚舌函数能够极大地加速随机梯度下降法的收敛速度,这因为它是线性的,且不存在梯度消失的问题 。
( 2 )相比于 Sigmoid 激活民l数和 Tanh 激活函数的复杂计算而言,ReLU 的计算方法更加简单.只需要一个闽值过滤就可以得到结果,不需要进行一大堆复杂的运算 。
缺点:
训练的时候很脆弱.比如一个很大的梯度经过 ReLU 激活函数更新参数之后,会使得这个神经元不会对任何数据有激活现象 。 如果发生这种情况之后,经过 ReLU 的梯度永远都会是 0 ,也就意味着参数无法再更新了,因为 ReLU 激活函数本质上是一个不可逆的过程,因为它会直接去掉输入小于 O 的部分 。 在实际操作中可以通过设置比较小的学习率来避免这个小问题 。
4. Leaky ReLU
Leaky ReLU 激活雨数是 ReLU 激活雨数的变式,主要是为了修复 ReLU 激活函数中训练比较脆弱的这个缺点.不将 x<O 的部分变成 0 ,而给它一个很小的负的斜率,比如 0.01。
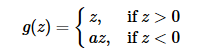
a取值在(0,1)之间.(0,1)之间。
Leaky ReLU函数解决了ReLU函数在输入为负的情况下产生的梯度消失问题。 但是再对所有情况都有效,目前也不清楚 。
5.Softmax
Softmax-用于多分类神经网络的输出
Softmax函数计算事件超过'n'个不同事件的概率分布。一般来说,这个函数将会计算每个目标类别在所有可能的目标类中的概率。计算出的概率将有助于确定给定输入的目标类别。
使用Softmax的主要优点是输出概率的范围,范围为0到1,所有概率的和将等于1。
总结:
选择激活函数时,优先选择ReLU及其变体,而不是sigmoid或tanh。同时ReLU及其变体训练起来更快。如果ReLU导致神经元死亡,使用Leaky ReLU或者ReLU的其他变体。sigmoid和tanh受到消失梯度问题的困扰,不应该在隐藏层中使用。隐藏层使用ReLU及其变体较好。使用容易求导和训练的激活函数。
参考及引用:
[1] https://www.cnblogs.com/lliuye/p/9486500.html
[2] 《深度学习之pytorch》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









