






MySql中,锁是是用来处理并发问题。在MySql中有三种级别的锁,全局锁、表级锁、行锁。
全局锁
获取锁指令为 Flush tables with read lock,释放指令是unlock tabls。全局锁会将库中所有数据表设置为只读,任何数据修改都会被堵塞(数据更新语句、数据定义语句、更新类事务的提交语句)。全局锁的典型使用场景是,做全库逻辑备份。但是在innodb中,可以通过MySql官方的MySqlDump工具使用–single-transaction参数,在同步之前开启一致性视图,来保证数据的一致性。对于不支持可重复读隔离级别的存储引擎,只能使用全局锁来做备份。
MySqlDump使用-single-transaction,但是当全库数据量太大,导致备份时间过长,使得可重复读事务太长,占用资源,有可能会导致MySql服务重启。
在处理备份时,只要保证数据库只读,为什么选择全局锁而不是set global readonly=true?
1 在有些系统中,readonly 的值会被用来做其他逻辑,比如用来判断一个库是主库还是备库。因此,修改 global 变量的方式影响面更大,我不建议你使用。
2在异常处理机制上有差异。如果执行 FTWRL 命令之后由于客户端发生异常断开,那么 MySQL 会自动释放这个全局锁,整个库回到可以正常更新的状态。而将整个库设置为 readonly 之后,如果客户端发生异常,则数据库就会一直保持 readonly 状态,这样会导致整个库长时间处于不可写状态,风险较高。
表级锁
表锁:获取锁指令 lock tables t1 read、t2 write ,释放指令时unlock tables。在还没有出现更细粒度的锁的时候,表锁是最常用的处理并发的方式。而对于 InnoDB 这种支持行锁的引擎,一般不使用 lock tables 命令来控制并发,毕竟锁住整个表的影响面还是太大。元数据锁(MDL):线程在遍历表中数据时会自动获取MDL读锁,保证数据结构再次期间不会变更。而对表进行DDL时,会获取MDL的写锁。在事务中,锁是在事务提交时才会释放。因此,在对产线数据表进行DDL时,需要选择业务低峰时间。
行锁
MySql的行锁由各个存储引擎实现,比如MyIsam没有实现行锁,因此只能使用表锁来处理并发。但是Innodb实现了行锁,这也是Innodb替代MyIsam的原因之一。行锁是针对数据表中行记录的锁,比如事务 A 更新了一行,而这时候事务 B 也要更新同一行,则必须等事务 A 的操作完成后才能进行更新。
两段锁协议
行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。因此在事务中,尽量将容易造成锁冲突的、最容易影响并发度的行放在后面执行。
死锁
数据库中,多个事务互相等待各自持有的所资源的现象称为死锁。
针对死锁有两种解决方案:
innodb_lock_wait_timeout:设置死锁等待超时时间,但是该时间长短很难把控。
死锁检测:设置innodb_deadlock_detect=on 开启innodb的死锁检测功能。事务堵塞时,主动检测释当前事务的加入释放会导致死锁,发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。但是这种检测功能的时间复杂度为N,效率很慢,占用CPU时间。因此需要在客户端或者MySql服务端、表设计操作时控制并发度,降低对资源的占用,提升效率。
排查MySQL查询长时间不返回的思路
1)select * from performance_scheam.processlist;(show processlist后面版本会被废弃) 查看当前时间下所有请求的连接状态
2)步骤1中出现Waiting for table metadata lock,表示当前连接在等待MDL,需要通过select * from sys.schema_table_lock_waits查询持有mdl锁的processid(blocking_pid字段)。然后kill 对应的pid即可关闭持有mdl锁的连接。
3)步骤1中出现Waiting for table flush,表示当前连接在等态其他线程执行完flush 操作。正常情况下flush table操作会很快,不会造成堵塞现象。但是当指定表在执行慢查询时,flush table操作需要等待慢查询执行完。这种情况下,通过processlist即可找到慢查询processid,直接kill即可。
4)通过select * from sys.innodb_lock_waits可查询行锁的情况(长事务更新数据未提交,其他事务需要该表的读锁),直接执行sql_kill_blocking_connection的内容,断开持有写锁的事务连接,回滚该事务。
a 在MySQL5.5以后,lock table t write实际上就是通过获取MDL的写锁来阻止其他线程访问当前表。
b flush操作指令如下:
flush tables t with read lock;关闭指定表
flush tables with read lock;关闭所有"打开"(正常执行查询操作)的表
c 正常情况下读表操作不会涉及到行级的读锁,可以通过select * from t where id=1 lock in share mode来获取指定行的读锁
幻读
幻读指的是一个事务在前后两次查询同一个范围的时候,后一次查询看到了前一次查询没有看到的行。此外需要注意的是:
1)在可重复读隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。因此,幻读在“当前读”下才会出现。
2)幻读仅专指新插入的数据行,更新操作之后出现的"新行"并不能算是幻读。
为了解决幻读;MySQL引入间隙锁,将行与行之间的间隙锁住,那么新增数据将无法插入。数据行是可以加上锁的实体,数据行之间的间隙,也是可以加上锁的实体。但是间隙锁跟我们之前碰到过的锁都不太一样。行锁的读写操作之间会互斥,具体规则如下:
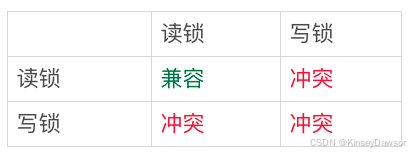
间隙锁不一样,跟间隙锁存在冲突关系的,是“往这个间隙中插入一个记录”这个操作。间隙锁之间都不存在冲突关系。
在实际分析的时候可以将间隙锁与行锁合并为next-lock key,每个next-lock key是左开右闭的。在执行SQL时,锁是实际上加载索引上的(因此会出现二级索引被锁,但是主键索引没有被锁的情况),具体的加锁规则如下(不同的版本可能会有差异):
1)加锁的基本单位是 next-key lock。
2)查找过程中访问到的对象才会加锁。
3)索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
4)索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
5)唯一索引上的范围查询会访问到不满足条件的第一个值为止。
6)分析时可以用 next-key lock 来分析,但是实际上加锁的操作会分为间隙锁以及行锁两端来执行的。
Lock in share mode&for update的区别
谨记锁是加上索引上的,而一张表可能会有多个索引。执行for update时,MySQL会认为你需要更新数据,因此在主键索引上,将满足条件的数据行加上行锁。而lock in share mode只会在扫描的索引上加上锁。
当条件字段没有索引时,需要全表扫描。因此在这种情况下会扫过全表的间隙。如果条件字段上有普通索引,那么可以精准定位符合条件的第一个间隙,继续扫描直到不符合条件的第一个值位置。唯一索引只要精准定位到符合条件的第一个间隙,如果有匹配值,那么会退化为行锁。
间隙锁的引入,可能会导致同样的语句锁住更大的范围,这其实是影响了并发度的。因此可以在实际操作中,考虑将隔离级别改成读题交,且将binlog的格式改成row模式。这样就避免了幻读,也就没有了间隙锁带来的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









