







 本文详细介绍了Kafka的主题和日志管理,包括主题的逻辑概念和分区,日志的存储结构,以及日志的删除策略(基于时间、空间和日志起始偏移量)。此外,还探讨了日志压缩的过程,如何保留最新版本的消息并优化存储空间。
本文详细介绍了Kafka的主题和日志管理,包括主题的逻辑概念和分区,日志的存储结构,以及日志的删除策略(基于时间、空间和日志起始偏移量)。此外,还探讨了日志压缩的过程,如何保留最新版本的消息并优化存储空间。
- 本文作者: lemon
- 本文链接: https://lemon2013.github.io/2019/10/20/kafka入门之主题与日志/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 许可协议。转载请注明出处!
主题
主题是存储消息的一个逻辑概念,可以简单理解为一类消息的集合,有使用方去创建。Kafka中的主题一般会有多个订阅者去消费对应主题的消息,也可以存在多个生产者往主题中写入消息。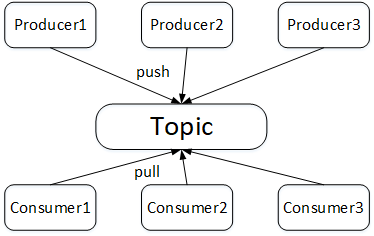
每个主题又可以划分成多个分区,每个分区存储不同的消息。当消息添加至分区时,会为其分配一个位移offset(从0开始递增),并保证分区上唯一,消息在分区上的顺序由offset保证,即同一个分区内的消息是有序的,如下图所示
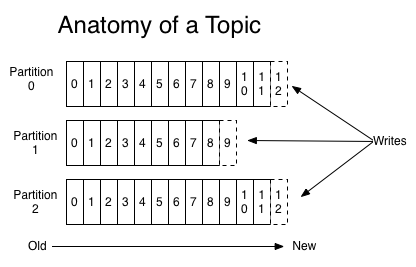
同一个主题的不同分区会分配在不同的节点上(broker),分区时保证Kafka集群具有水平扩展的基础。
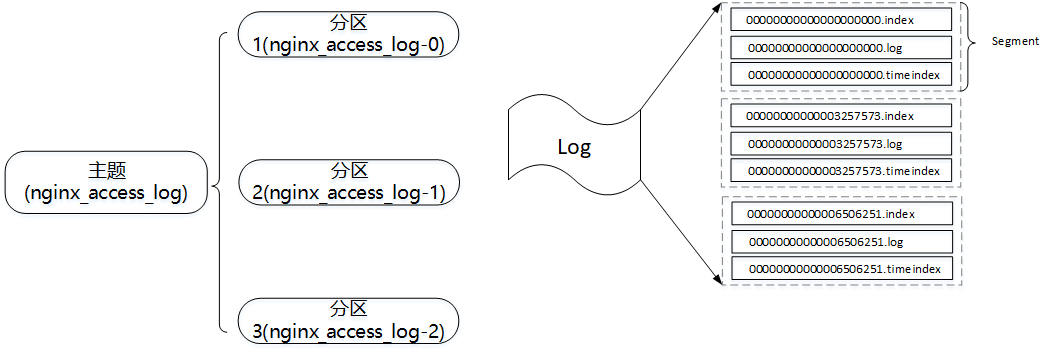
以主题nginx_access_log为例,分区数为3,如上图所示。分区在逻辑上对应一个日志(Log),物理上对应的是一个文件夹。
1 2 3 | drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx_access_log-0/ drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx_access_log-1/ drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx_access_log-2/ |
消息写入分区时,实际上是将消息写入分区所在的文件夹中。日志又分成多个分片(Segment),每个分片由日志文件与索引文件组成,每个分区大小是有限的(在kafka集群的配置文件log.segment.bytes配置,默认为1073741824byte,即1GB),当分片大小超过限制则会重新创建一个新的分片,外界消息的写入只会写入最新的一个分片(顺序IO)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | -rw-r--r-- 1 root root 1835920 10月 11 19:18 00000000000000000000.index -rw-r--r-- 1 root root 1073741684 10月 11 19:18 00000000000000000000.log -rw-r--r-- 1 root root 2737884 10月 11 19:18 00000000000000000000.timeindex -rw-r--r-- 1 root root 1828296 10月 11 19:30 00000000000003257573.index -rw-r--r-- 1 root root 1073741513 10月 11 19:30 00000000000003257573.log -rw-r--r-- 1 root root 2725512 10月 11 19:30 00000000000003257573.timeindex -rw-r--r-- 1 root root 1834744 10月 11 19:42 00000000000006506251.index -rw-r--r-- 1 root root 1073741771 10月 11 19:42 00000000000006506251.log -rw-r--r-- 1 root root 2736072 10月 11 19:42 00000000000006506251.timeindex -rw-r--r-- 1 root root 1832152 10月 11 19:54 00000000000009751854.index -rw-r--r-- 1 root root 1073740984 10月 11 19:54 00000000000009751854.log -rw-r--r-- 1 root root 2731572 10月 11 19:54 00000000000009751854.timeindex -rw-r--r-- 1 root root 1808792 10月 11 20:06 00000000000012999310.index -rw-r--r-- 1 root root 1073741584 10月 11 20:06 00000000000012999310.log -rw-r--r-- 1 root root 10 10月 11 19:54 00000000000012999310.snapshot -rw-r--r-- 1 root root 2694564 10月 11 20:06 00000000000012999310.timeindex -rw-r--r-- 1 root root 10485760 10月 11 20:09 00000000000016260431.index -rw-r--r-- 1 root root 278255892 10月 11 20:09 00000000000016260431.log -rw-r--r-- 1 root root 10 10月 11 20:06 00000000000016260431.snapshot -rw-r--r-- 1 root root 10485756 10月 11 20:09 00000000000016260431.timeindex -rw-r--r-- 1 root root 8 10月 11 19:03 leader-epoch-checkpoint |
一个分片包含多个不同后缀的日志文件,分片中的第一个消息的offset将作为该分片的基准偏移量,偏移量固定长度为20,不够前面补齐0,然后将其作为索引文件以及日志文件的文件名,如00000000000003257573.index、00000000000003257573.log、00000000000003257573.timeindex、相同文件名的文件组成一个分片(忽略后缀名),除了.index、.timeindex、 .log后缀的日志文件外其他日志文件,对应含义如下:
| 文件类型 | 作用 |
|---|---|
| .index | 偏移量索引文件,记录<相对位移,起始地址>映射关系,其中相对位移表示该分片的第一个消息,从1开始计算,起始地址表示对应相对位移消息在分片.log文件的起始地址 |
| .timeindex | 时间戳索引文件,记录<时间戳,相对位移>映射关系 |
| .log | 日志文件,存储消息的详细信息 |
| .snaphot | 快照文件 |
| .deleted | 分片文件删除时会先将该分片的所有文件加上.delete后缀,然后有delete-file任务延迟删除这些文件(file.delete.delay.ms可以设置延时删除的的时间) |
| .cleaned | 日志清理时临时文件 |
| .swap | Log Compaction 之后的临时文件 |
| .leader-epoch-checkpoint |
日志索引
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传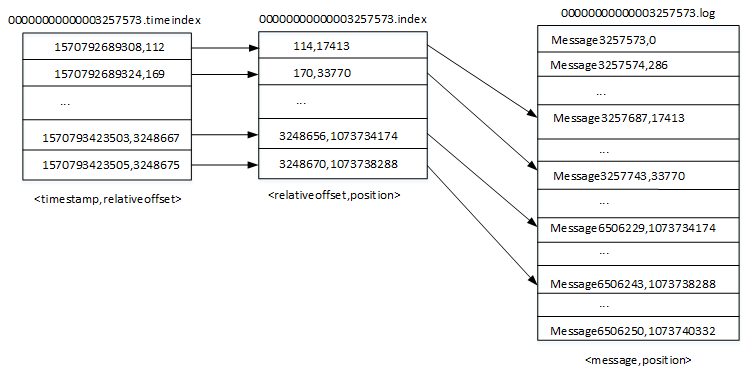
首先介绍下.index文件,这里以文件00000000000003257573.index为例,首先我们可以通过以下命令查看该索引文件的内容,我们可以看到输出结构为<offset,position>,实际上索引文件中保存的并不是offset而是相对位移,比如第一条消息的相对位移则为0,格式化输出时加上了基准偏移量,如上图所示,<114,17413>表示该分片相对位移为114的消息,其位移为3257573+114,即3257687,position表示对应offset在.log文件的物理地址,通过.index索引文件则可以获取对应offset所在的物理地址。索引采用稀疏索引的方式构建,并不保证分片中的每个消息都在索引文件有映射关系(.timeindex索引也是类似),主要是为了节省磁盘空间、内存空间,因为索引文件最终会映射到内存中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | # 查看该分片索引文件的前10条记录 bin/kafka-dump-log.sh --files /tmp/kafka-logs/nginx_access_log-1/00000000000003257573.index |head -n 10 Dumping /tmp/kafka-logs/nginx_access_log-1/00000000000003257573.index offset: 3257687 position: 17413 offset: 3257743 position: 33770 offset: 3257799 position: 50127 offset: 3257818 position: 66484 offset: 3257819 position: 72074 offset: 3257871 position: 87281 offset: 3257884 position: 91444 offset: 3257896 position: 95884 offset: 3257917 position: 100845 # 查看该分片索引文件的后10条记录 $ bin/kafka-dump-log.sh --files /tmp/kafka-logs/nginx_access_log-1/00000000000003257573.index |tail -n 10 offset: 6506124 position: 1073698512 offset: 6506137 position: 1073702918 offset: 6506150 position: 1073707263 offset: 6506162 position: 1073711499 offset: 6506176 position: 1073716197 offset: 6506188 position: 1073720433 offset: 6506205 position: 1073725654 offset: 6506217 position: 1073730060 offset: 6506229 position: 1073734174 offset: 6506243 position: 1073738288 |
比如查看offset为
6506155的消息:首先根据offset找到对应的分片,65061所对应的分片为00000000000003257573,然后通过二分法在00000000000003257573.index文件中找到不大于6506155的最大索引值,得到<offset: 6506150, position: 1073707263>,然后从00000000000003257573.log的1073707263位置开始顺序扫描找到offset为650155的消息
kafka从0.10.0.0版本起,为分片日志文件中新增了一个.timeindex的索引文件,可以根据时间戳定位消息。同样我们可以通过脚本kafka-dump-log.sh查看时间索引的文件内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | # 查看该分片时间索引文件的前10条记录 bin/kafka-dump-log.sh --files /tmp/kafka-logs/nginx_access_log-1/00000000000003257573.timeindex |head -n 10 Dumping /tmp/kafka-logs/nginx_access_log-1/00000000000003257573.timeindex timestamp: 1570792689308 offset: 3257685 timestamp: 1570792689324 offset: 3257742 timestamp: 1570792689345 offset: 3257795 timestamp: 1570792689348 offset: 3257813 timestamp: 1570792689357 offset: 3257867 timestamp: 1570792689361 offset: 3257881 timestamp: 1570792689364 offset: 3257896 timestamp: 1570792689368 offset: 3257915 timestamp: 1570792689369 offset: 3257927 # 查看该分片时间索引文件的前10条记录 bin/kafka-dump-log.sh --files /tmp/kafka-logs/nginx_access_log-1/00000000000003257573.timeindex |tail -n 10 Dumping /tmp/kafka-logs/nginx_access_log-1/00000000000003257573.timeindex timestamp: 1570793423474 offset: 6506136 timestamp: 1570793423477 offset: 6506150 timestamp: 1570793423481 offset: 6506159 timestamp: 1570793423485 offset: 6506176 timestamp: 1570793423489 offset: 6506188 timestamp: 1570793423493 offset: 6506204 timestamp: 1570793423496 offset: 6506214 timestamp: 1570793423500 offset: 6506228 timestamp: 1570793423503 offset: 6506240 timestamp: 1570793423505 offset: 6506248 |
比如我想查看时间戳
1570793423501开始的消息:1.首先定位分片,将1570793423501与每个分片的最大时间戳进行对比(最大时间戳取时间索引文件的最后一条记录时间,如果时间为0则取该日志分段的最近修改时间),直到找到大于或等于1570793423501的日志分段,因此会定位到时间索引文件00000000000003257573.timeindex,其最大时间戳为1570793423505;2.通过二分法找到大于或等于1570793423501的最大索引项,即<timestamp: 1570793423503 offset: 6506240>(6506240为offset,相对位移为3247667);3.根据相对位移3247667去索引文件中找到不大于该相对位移的最大索引值<3248656,1073734174>;4.从日志文件00000000000003257573.log的1073734174位置处开始扫描,查找不小于1570793423501的数据。
日志删除
与其他消息中间件不同的是,Kafka集群中的消息不会因为消费与否而删除,跟日志一样消息最终会落盘,并提供对应的策略周期性(通过参数log.retention.check.interval.ms来设置,默认为5分钟)执行删除或者压缩操作(broker配置文件log.cleanup.policy参数如果为“delete”则执行删除操作,如果为“compact”则执行压缩操作,默认为“delete”)。
基于时间的日志删除
| 参数 | 默认值 | 说明 |
|---|---|---|
| log.retention.hours | 168 | 日志保留时间(小时) |
| log.retention.minutes | 无 | 日志保留时间(分钟),优先级大于小时 |
| log.retention.ms | 无 | 日志保留时间(毫秒),优先级大于分钟 |
当消息在集群保留时间超过设定阈值(log.retention.hours,默认为168小时,即七天),则需要进行删除。这里会根据分片日志的最大时间戳来判断该分片的时间是否满足删除条件,最大时间戳首先会选取时间戳索引文件中的最后一条索引记录,如果对应的时间戳值大于0则取该值,否则为最近一次修改时间。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传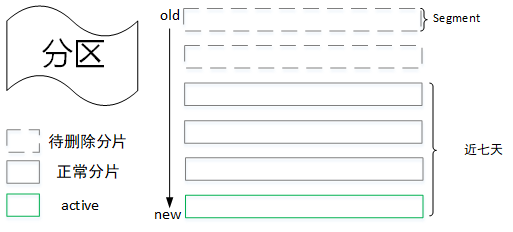
这里不直接选取最后修改时间的原因是避免分片日志的文件被无意篡改而导致其时间不准。
如果恰好该分区下的所有日志分片均已过期,那么会先生成一个新的日志分片作为新消息的写入文件,然后再执行删除参数。
基于空间的日志删除
| 参数 | 默认值 | 说明 |
|---|---|---|
| log.retention.bytes | 1073741824(即1G),默认未开启,即无穷大 | 日志文件总大小,并不是指单个分片的大小 |
| log.segment.bytes | 1073741824(即1G) | 单个日志分片大小 |
首先会计算待删除的日志大小diff(totalSize-log.rentention.bytes),然后从最旧的一个分片开始查看可以执行删除操作的文件集合(如果diff-segment.size>=0,则满足删除条件),最后执行删除操作。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
基于日志起始偏移量的日志删除
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传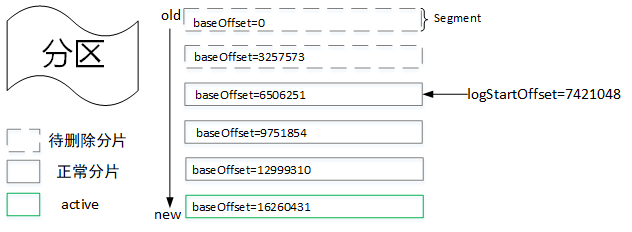
一般情况下,日志文件的起始偏移量(logStartOffset)会等于第一个日志分段的baseOffset,但是其值会因为删除消息请求而增长,logStartOffset的值实际上是日志集合中的最小消息,而小于这个值的消息都会被清理掉。如上图所示,我们假设logStartOffset=7421048,日志删除流程如下:
- 从最旧的日志分片开始遍历,判断其下一个分片的baseOffset是否小于或等于logStartOffset值,如果满足,则需要删除,因此第一个分片会被删除。
- 分片二的下一个分片baseOffset=6506251<7421048,所以分片二也需要删除。
- 分片三的下一个分片baseOffset=9751854>7421048,所以分片三不会被删除。
日志压缩
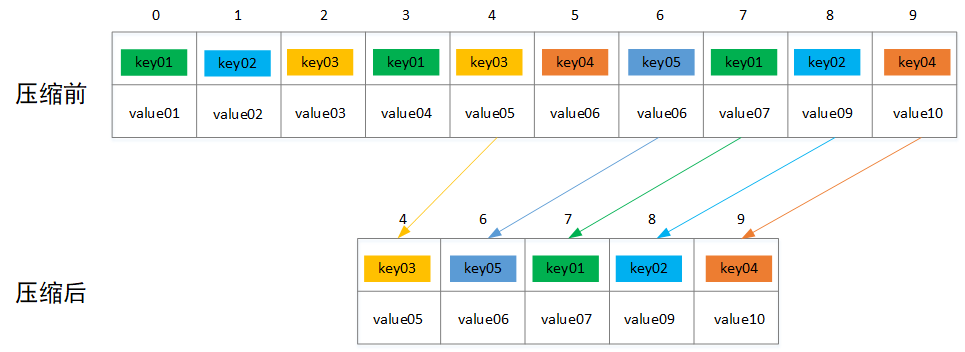
前面提到当broker配置文件log.cleanup.policy参数值设置为“compact”时,则会执行压缩操作,这里的压缩跟普通意义的压缩不一样,这里的压缩是指将相同key的消息只保留最后一个版本的value值,如下图所示,压缩之前offset是连续递增,压缩之后offset递增可能不连续,只保留5条消息记录。
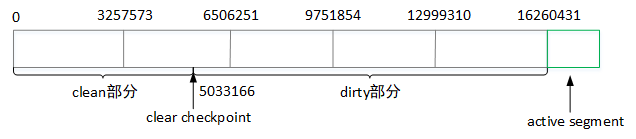
Kafka日志目录下cleaner-offset-checkpoint文件,用来记录每个主题的每个分区中已经清理的偏移量,通过这个偏移量可以将分区中的日志文件分成两个部分:clean表示已经压缩过;dirty表示还未进行压缩,如下图所示(active segment不会参与日志的压缩操作,因为会有新的数据写入该文件)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | -rw-r--r-- 1 root root 4 10月 11 19:02 cleaner-offset-checkpoint drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx_access_log-0/ drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx_access_log-1/ drwxr-xr-x 2 root root 4096 10月 11 20:07 nginx_access_log-2/ -rw-r--r-- 1 root root 0 9月 18 09:50 .lock -rw-r--r-- 1 root root 4 10月 16 11:19 log-start-offset-checkpoint -rw-r--r-- 1 root root 54 9月 18 09:50 meta.properties -rw-r--r-- 1 root root 1518 10月 16 11:19 recovery-point-offset-checkpoint -rw-r--r-- 1 root root 1518 10月 16 11:19 replication-offset-checkpoint #cat cleaner-offset-checkpoint nginx_access_log 0 5033168 nginx_access_log 1 5033166 nginx_access_log 2 5033168 |
日志压缩时会根据dirty部分数据占日志文件的比例(cleanableRatio)来判断优先压缩的日志,然后为dirty部分的数据建立key与offset映射关系(保存对应key的最大offset)存入SkimpyoffsetMap中,然后复制segment分段中的数据,只保留SkimpyoffsetMap中记录的消息,压缩之后的相关日志文件大小会减少,为了避免出现过小的日志文件与索引文件,压缩时会对所有的segment进行分组(一个组的分片大小不会超过设置的log.segment.bytes值大小),同一个分组的多个分片日志压缩之后变成一个分片。
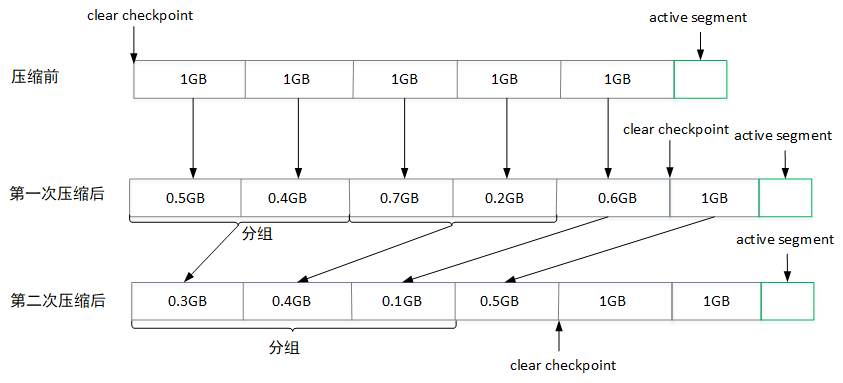
如上图所示,所有消息都还没压缩前
clean checkpoint值为0,表示该分区的数据还没进行压缩,第一次压缩后,之前每个分片的日志文件大小都有所减少,同时会移动clean checkpoint的位置到这一次压缩结束的offset值。第二次压缩时,会将前两个分片{0.5GB,0.4GB}组成一个分组,{0.7GB,0.2GB}组成一个分组进行压缩,以此类推。
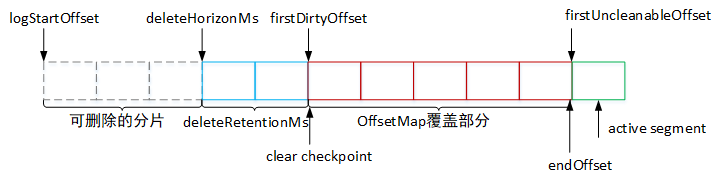
如上图所示,日志压缩的主要流程如下:
- 计算
deleteHorizonMs值:当某个消息的value值为空时,该消息会被保留一段时间,超时之后会在下一次的得日志压缩中被删除,所以这里会计算deleteHorizonMs,根据该值确定可以删除value值为空的日志分片。(deleteHorizonMs = clean部分的最后一个分片的lastModifiedTime - deleteRetionMs,deleteRetionMs通过配置文件log.cleaner.delete.retention.ms配置,默认为24小时)。 - 确定压缩dirty部分的offset范围[firstDirtyOffset,endOffset):其中
firstDirtyOffset表示dirty的起始位移,一般会等于clear checkpoint值,firstUncleanableOffset表示不能清理的最小位移,一般会等于活跃分片的baseOffset,然后从firstDirtyOffset位置开始遍历日志分片,并填充key与offset的映射关系至SkimpyoffsetMap中,当该map被填充满或到达上限firstUncleanableOffset时,就可以确定日志压缩上限endOffset。 - 将[logStartOffset,endOffset)中的日志分片进行分组,然后按照分组的方式进行压缩。

















 5074
5074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









