



聚类算法总结
原文:http://blog.chinaunix.net/uid-10289334-id-3758310.html
聚类算法的种类:
基于划分聚类算法(partition clustering)

基于层次聚类算法:

基于密度聚类算法:

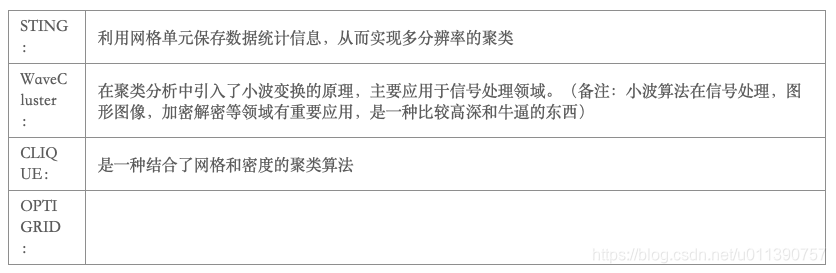
基于网格的聚类算法:
基于神经网络的聚类算法:

基于统计学的聚类算法:

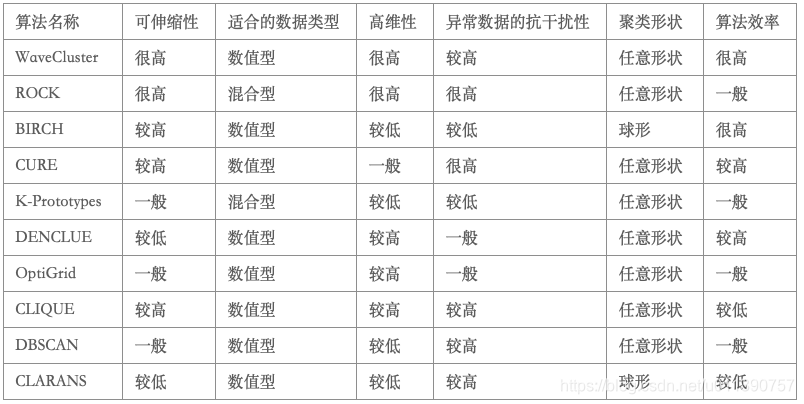
几种常用的聚类算法从可伸缩性、适合的数据类型、高维性(处理高维数据的能力)、异常数据的抗干扰度、聚类形状和算法效率6个方面进行了综合性能评价,评价结果如表1所示:
目前聚类分析研究的主要内容:
对聚类进行研究是数据挖掘中的一个热门方向,由于以上所介绍的聚类方法都存在着某些缺点,因此近些年对于聚类分析的研究很多都专注于改进现有的聚类方法或者是提出一种新的聚类方法。以下将对传统聚类方法中存在的问题以及人们在这些问题上所做的努力做一个简单的总结:
1 从以上对传统的聚类分析方法所做的总结来看,不管是k-means方法,还是CURE方法,在进行聚类之前都需要用户事先确定要得到的聚类的数目。然而在现实数据中,聚类的数目是未知的,通常要经过不断的实验来获得合适的聚类数目,得到较好的聚类结果。
2 传统的聚类方法一般都是适合于某种情况的聚类,没有一种方法能够满足各种情况下的聚类,比如BIRCH方法对于球状簇有很好的聚类性能,但是对于不规则的聚类,则不能很好的工作;K-medoids方法不太受孤立点的影响,但是其计算代价又很大。因此如何解决这个问题成为当前的一个研究热点,有学者提出将不同的聚类思想进行融合以形成新的聚类算法,从而综合利用不同聚类算法的优点,在一次聚类过程中综合利用多种聚类方法,能够有效的缓解这个问题。
3 随着信息时代的到来,对大量的数据进行分析处理是一个很庞大的工作,这就关系到一个计算效率的问题。有文献提出了一种基于最小生成树的聚类算法,该算法通过逐渐丢弃最长的边来实现聚类结果,当某条边的长度超过了某个阈值,那么更长边就不需要计算而直接丢弃,这样就极大地提高了计算效率,降低了计算成本。
4 处理大规模数据和高维数据的能力有待于提高。目前许多聚类方法处理小规模数据和低维数据时性能比较好,但是当数据规模增大,维度升高时,性能就会急剧下降,比如k-medoids方法处理小规模数据时性能很好,但是随着数据量增多,效率就逐渐下降,而现实生活中的数据大部分又都属于规模比较大、维度比较高的数据集。有文献提出了一种在高维空间挖掘映射聚类的方法PCKA(Projected Clustering based on the K-Means Algorithm),它从多个维度中选择属性相关的维度,去除不相关的维度,沿着相关维度进行聚类,以此对高维数据进行聚类。
5 目前的许多算法都只是理论上的,经常处于某种假设之下,比如聚类能很好的被分离,没有突出的孤立点等,但是现实数据通常是很复杂的,噪声很大,因此如何有效的消除噪声的影响,提高处理现实数据的能力还有待进一步的提高。
分类算法总结
原文:http://blog.youkuaiyun.com/chl033/article/details/5204220
目前看到的比较全面的分类算法,总结的还不错.
2.4.1 主要分类方法介绍解决分类问题的方法很多[40-42] ,单一的分类方法主要包括:决策树、贝叶斯、人工神经网络、K-近邻、支持向量机和基于关联规则的分类等;另外还有用于组合单一分类方法的集成学习算法,如Bagging和Boosting等。
(1)决策树
决策树是用于分类和预测的主要技术之一,决策树学习是以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的实例中推理出以决策树表示的分类规则。构造决策树的目的是找出属性和类别间的关系,用它来预测将来未知类别的记录的类别。它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性值判断从该节点向下的分支,在决策树的叶节点得到结论。
主要的决策树算法有ID3、C4.5(C5.0)、CART、PUBLIC、SLIQ和SPRINT算法等。它们在选择测试属性采用的技术、生成的决策树的结构、剪枝的方法以及时刻,能否处理大数据集等方面都有各自的不同之处。
(2)贝叶斯
贝叶斯(Bayes)分类算法是一类利用概率统计知识进行分类的算法,如朴素贝叶斯(Naive Bayes)算法。这些算法主要利用Bayes定理来预测一个未知类别的样本属于各个类别的可能性,选择其中可能性最大的一个类别作为该样本的最终类别。由于贝叶斯定理的成立本身需要一个很强的条件独立性假设前提,而此假设在实际情况中经常是不成立的,因而其分类准确性就会下降。为此就出现了许多降低独立性假设的贝叶斯分类算法,如TAN(Tree Augmented Na?ve Bayes)算法,它是在贝叶斯网络结构的基础上增加属性对之间的关联来实现的。
(3)人工神经网络
人工神经网络(Artificial Neural Networks,ANN)是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。在这种模型中,大量的节点(或称”神经元”,或”单元”)之间相互联接构成网络,即”神经网络”,以达到处理信息的目的。神经网络通常需要进行训练,训练的过程就是网络进行学习的过程。训练改变了网络节点的连接权的值使其具有分类的功能,经过训练的网络就可用于对象的识别。
目前,神经网络已有上百种不同的模型,常见的有BP网络、径向基RBF网络、Hopfield网络、随机神经网络(Boltzmann机)、竞争神经网络(Hamming网络,自组织映射网络)等。但是当前的神经网络仍普遍存在收敛速度慢、计算量大、训练时间长和不可解释等缺点。
(4)k-近邻
k-近邻(kNN,k-Nearest Neighbors)算法是一种基于实例的分类方法。该方法就是找出与未知样本x距离最近的k个训练样本,看这k个样本中多数属于哪一类,就把x归为那一类。k-近邻方法是一种懒惰学习方法,它存放样本,直到需要分类时才进行分类,如果样本集比较复杂,可能会导致很大的计算开销,因此无法应用到实时性很强的场合。
(5)支持向量机
支持向量机(SVM,Support Vector Machine)是Vapnik根据统计学习理论提出的一种新的学习方法[43] ,它的最大特点是根据结构风险最小化准则,以最大化分类间隔构造最优分类超平面来提高学习机的泛化能力,较好地解决了非线性、高维数、局部极小点等问题。对于分类问题,支持向量机算法根据区域中的样本计算该区域的决策曲面,由此确定该区域中未知样本的类别。
(6)基于关联规则的分类
关联规则挖掘是数据挖掘中一个重要的研究领域。近年来,对于如何将关联规则挖掘用于分类问题,学者们进行了广泛的研究。关联分类方法挖掘形如condset→C的规则,其中condset是项(或属性-值对)的集合,而C是类标号,这种形式的规则称为类关联规则(class association rules,CARS)。关联分类方法一般由两步组成:第一步用关联规则挖掘算法从训练数据集中挖掘出所有满足指定支持度和置信度的类关联规则;第二步使用启发式方法从挖掘出的类关联规则中挑选出一组高质量的规则用于分类。属于关联分类的算法主要包括CBA[44] ,ADT[45] ,CMAR[46] 等。
(7)集成学习(Ensemble Learning)
实际应用的复杂性和数据的多样性往往使得单一的分类方法不够有效。因此,学者们对多种分类方法的融合即集成学习进行了广泛的研究。集成学习已成为国际机器学习界的研究热点,并被称为当前机器学习四个主要研究方向之一。
集成学习是一种机器学习范式,它试图通过连续调用单个的学习算法,获得不同的基学习器,然后根据规则组合这些学习器来解决同一个问题,可以显著的提高学习系统的泛化能力。组合多个基学习器主要采用(加权)投票的方法,常见的算法有装袋[47] (Bagging),提升/推进[48, 49] (Boosting)等。
有关分类器的集成学习见图2-5。集成学习由于采用了投票平均的方法组合多个分类器,所以有可能减少单个分类器的误差,获得对问题空间模型更加准确的表示,从而提高分类器的分类准确度。
图2-5:分类器的集成学习
以上简单介绍了各种主要的分类方法,应该说其都有各自不同的特点及优缺点。对于数据库负载的自动识别,应该选择哪种方法呢?用来比较和评估分类方法的标准[50] 主要有:(1)预测的准确率。模型正确地预测新样本的类标号的能力;(2)计算速度。包括构造模型以及使用模型进行分类的时间;(3)强壮性。模型对噪声数据或空缺值数据正确预测的能力;(4)可伸缩性。对于数据量很大的数据集,有效构造模型的能力;(5)模型描述的简洁性和可解释性。模型描述愈简洁、愈容易理解,则愈受欢迎。

















 5608
5608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









