




 本文介绍了如何使用Python爬虫获取校图书馆的借书列表。通过分析登陆流程,获取_token值,然后利用requests库进行POST请求登录。成功登录后,GET请求借书清单页面,并使用BeautifulSoup解析HTML,提取所需信息。文章提到,由于没有验证码,流程相对简单,后续将探讨续借图书及图形验证码识别。
本文介绍了如何使用Python爬虫获取校图书馆的借书列表。通过分析登陆流程,获取_token值,然后利用requests库进行POST请求登录。成功登录后,GET请求借书清单页面,并使用BeautifulSoup解析HTML,提取所需信息。文章提到,由于没有验证码,流程相对简单,后续将探讨续借图书及图形验证码识别。
刚学python不久,看了些爬虫教程,决定拿校图书馆试试手
首先考虑登陆的问题,学校所有网站目前采取统一身份认证,任何需要登陆的校内站点都可以跳转到https://passport.ustc.edu.cn/login?service=xxxx获取身份认证,猜测是拿一个cookie,不过我们不用管
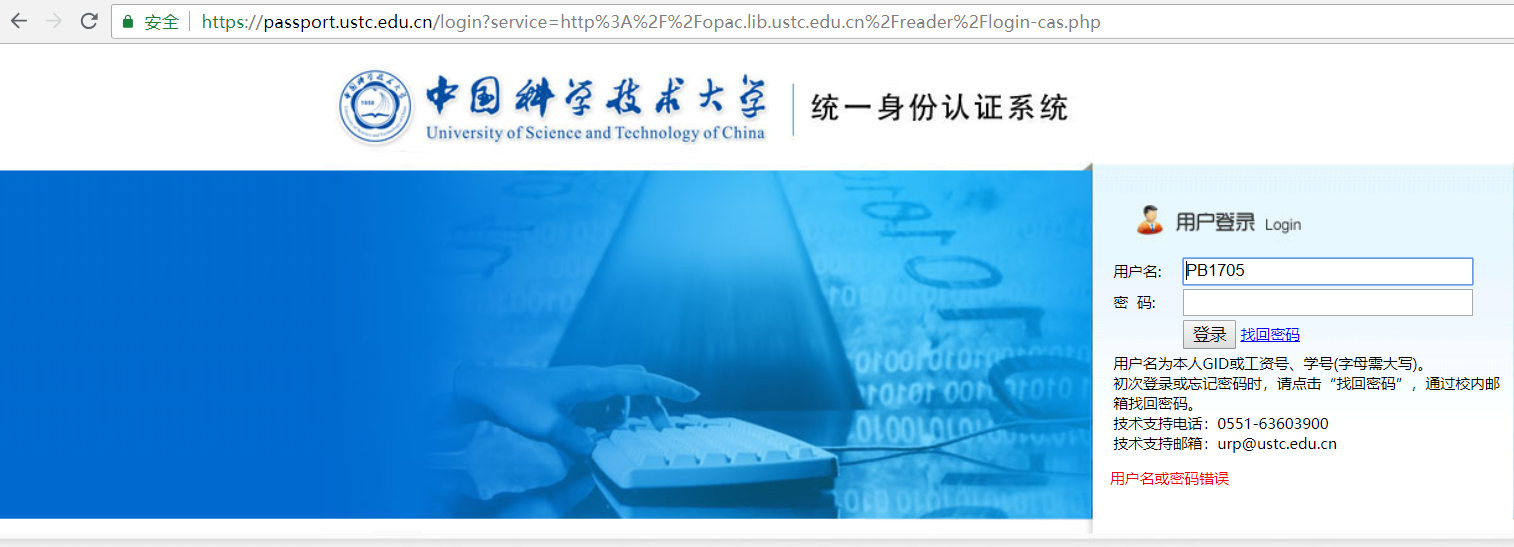
爬虫想要登陆,必须知道要提交数据的格式。打开登陆界面,调出F12工具,转到Network选项卡,随便输入用户密码登陆,一个个看Header,明显就是他了
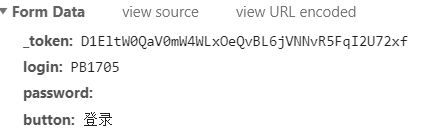
但是里面有一项_token我们不知道从哪里来的,那我们到网页里面找一找,转到Element选项卡,Ctrl+F搜索token,我们发现其数值在网页里清清楚楚的写了
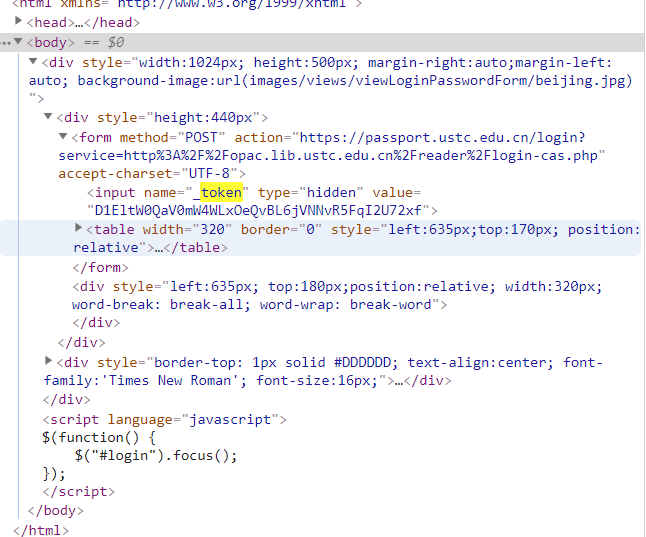
所以我们在登陆前需要先获取整个网页内容,然后查找出token数值,具体代码:
login_url = 'https://passport.ustc.edu.cn/login?service=http%3A%2F%2Fopac.lib.ustc.edu.cn%2Freader%2Flogin-cas.php' #登陆操作的url
session = requests.session() #新建一个空的session
res = session.get(login_url) #从指定url获取网页内容
selector = etree.HTML(res.content) #建立selector
_token = selector.xpath(r'//*[@name="_token"]/@value')[0] #获取网页中的_token
最后和xpath有关,意为所有name属性为"_token"标签中value属性的值,即为我们要的token。
这里不需要构造header,直接将数据表post过去就可以
login_data = {
'_token' : None,
'login': None,#'PB******',
'password': None,#'********',
'button': '登录'
}
login_data['_token'] = _token
login_data['login'] = input(u'输入学号:')
login_data['password'] = input(u'输入密码:')
res = session.post(login_url, login_data) #无需referencepost完毕,我们需要从http://opac.lib.ustc.edu.cn/reader/book_lst.php获取借书清单,先get到网页
res = session.get('http://opac.lib.ustc.edu.cn/reader/book_lst.php')有了网页剩下的就是要从网页中分辨出我们所需要的信息,我们先用浏览器登陆上去,看一下源码
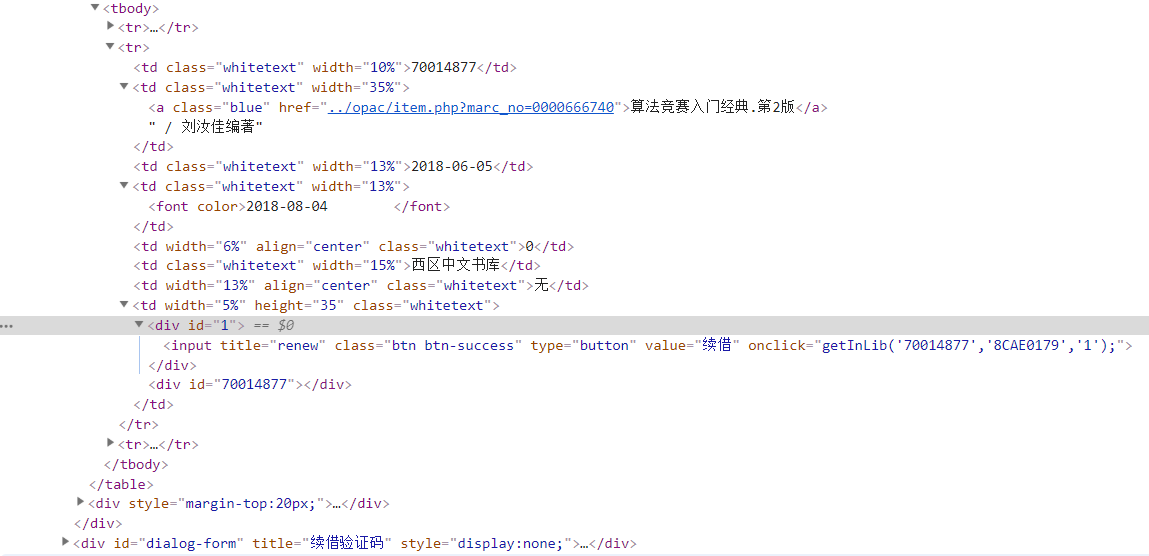
发现借阅的所有书籍信息都在tbody下,而每本书以及表头都在一个tr下,详细信息又分别在td或其子标签下,为了使打印出的数据好看,这里使用了PrettyTable库
selector = etree.HTML(res.text)
tr_class = selector.xpath(r'//tr')
chart_head = tr_class[0].xpath(r'td/text()')
chart_head.pop()
chart = PrettyTable(chart_head)
for i in tr_class:
new_arrow = i.xpath(r'td/text()')
new_arrow.pop()
if len(new_arrow) == 6:
new_arrow[1] = i.xpath(r'td/a/text()')[0] + new_arrow[1]
new_arrow.insert(3, i.xpath(r'td/font/text()')[0])
chart.add_row(new_arrow)
print(chart)详细过程就不说了,因为每个网站的结构不一样。
完整代码:
import requests
from lxml import etree
from prettytable import PrettyTable
login_url = 'https://passport.ustc.edu.cn/login?service=http%3A%2F%2Fopac.lib.ustc.edu.cn%2Freader%2Flogin-cas.php'
session = requests.session()
res = session.get(login_url)
selector = etree.HTML(res.content)
_token = selector.xpath(r'//*[@name="_token"]/@value')[0]
login_data = {
'login': None,#'PB******',
'_token' : None,
'password': None,#'********',
'button': '登录'
}
login_data['_token'] = _token
login_data['login'] = input(u'输入学号:')
login_data['password'] = input(u'输入密码:')
res = session.post(login_url, login_data)
selector = etree.HTML(res.text)
tr_class = selector.xpath(r'//tr')
chart_head = tr_class[0].xpath(r'td/text()')
chart_head.pop()
chart = PrettyTable(chart_head)
for i in tr_class:
new_arrow = i.xpath(r'td/text()')
new_arrow.pop()
if len(new_arrow) == 6:
new_arrow[1] = i.xpath(r'td/a/text()')[0] + new_arrow[1]
new_arrow.insert(3, i.xpath(r'td/font/text()')[0])
chart.add_row(new_arrow)
print(chart)结果
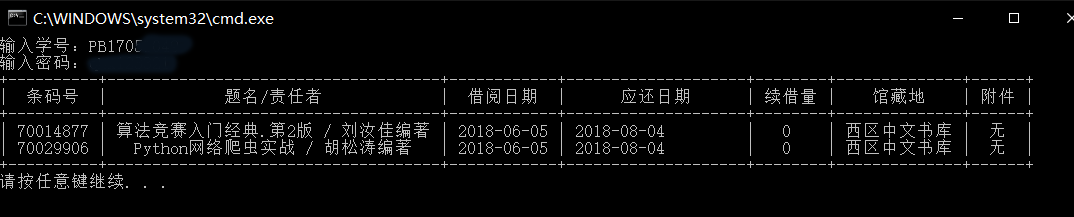
总体还是挺简单的,因为登陆不需要验证码,只要找token就行。在下一篇,我们会尝试续借图书并训练、使用tesseract识别图形验证码。

















 1244
1244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









