







 本文介绍了如何通过少量数据生成大量同分布的随机数,特别是对于一维和二维正态分布的情况。通过基本理论和Matlab代码,展示了如何利用标准正态分布数据生成非标准正态分布数据,并利用Cholesky分解进行数据扩充。这种方法适用于正态分布和对数正态分布的数据,且可以扩展到高维数据生成。
本文介绍了如何通过少量数据生成大量同分布的随机数,特别是对于一维和二维正态分布的情况。通过基本理论和Matlab代码,展示了如何利用标准正态分布数据生成非标准正态分布数据,并利用Cholesky分解进行数据扩充。这种方法适用于正态分布和对数正态分布的数据,且可以扩展到高维数据生成。
引言
数据扩充加密(也可称为插值)是比较常见的数据操作,确定性数据的扩充比较简单,可以使用各种插值算法,如线性插值、拉格朗日插值、样条插值等等等;而当数据是随机的时候,有时候也需要插值加密,但比确定性情况复杂的多。
蒙特卡洛模拟中经常需要生成大量满足要求分布的数据,一般有两种方法:已知分布参数情况下,直接生成大量满足要求分布的数据;已知分布形式情况下,由少量数据生成大量数据,也可称为扩充加密。本文从一维到二维,分别探讨了通过少量数据生成同分布大量数据的算法,最后给出了Matlab代码供感兴趣的朋友尝试。
1 一维情况
基本理论
定义:若数据的平均值为,方差为 s 2 s^2 s2,则新数据的平均值为,方差为。反之,若 X X X表示均值为 μ μ μ方差为 σ σ σ的随机数序列,则方差为 a σ aσ aσ均值为 μ + b μ+b μ+b的随机数序列 Y Y Y可以表示为:
Y = a X + b (1) Y = \sqrt a X + b \tag{1} Y=aX+b(1)
以上公式也表明,只需有一组正态分布随机数,公式(1)可以用于生成特定标准差和均值的正态分布随机数。
利用标准正态分布数据生成非标准正态分布数据
若有少量假定满足(非标准)正态分布的n维初始随机数向量 X X X,要求扩充成大量 m m m维同分布的随机数向量 Y Y Y,则可以使用以下的扩充公式。
Y = 1 n ∑ i = 1 n ( x i − x ˉ ) × U + x ˉ (2) Y = \sqrt {\frac{1}{n}\sum\limits_{i = 1}^n {\left( { {x_i} - \bar x} \right)} } \times U + \bar x\tag{2} Y=n1i=1∑n(xi−xˉ)×U+xˉ(2)
其中,第一项是初始数据的标准差估计;第二项 U U U是满足标准正态分布的 m m m维随机数向量;第三项是均值估计。
2 二维情况
基本理论
一维数据可以表示为某条直线上的一系列点,只需要一列数据就可以唯一确定这些点的位置。
二维数据可以表示为二维平面上的一系列点,需要两列数据( x x x坐标和 y y y坐标)才能唯一确定这些点的位置。
二维和一维的不同点在于,多了用于衡量两个维度相关性的协方差,我们需要关心 x x x的变化会不会使 y y y产生相应的变化。因此,在二维情况中引入公式(3)所示的协方差矩阵来衡量两个维度的相关性:
Σ = [ C o v ( X , X ) C o v ( X , Y ) C o v ( Y , X ) C o v ( Y , Y ) ] (3) \Sigma = \left[ {\begin{array}{} {Cov\left( {X,X} \right)}&{Cov\left( {X,Y} \right)} \\ {Cov\left( {Y,X} \right)}&{Cov\left( {Y,Y} \right)} \end{array}} \right]\tag{3} Σ=[Cov(X,X)Cov(Y,X)Cov(X,Y)Cov(Y,Y)](3)
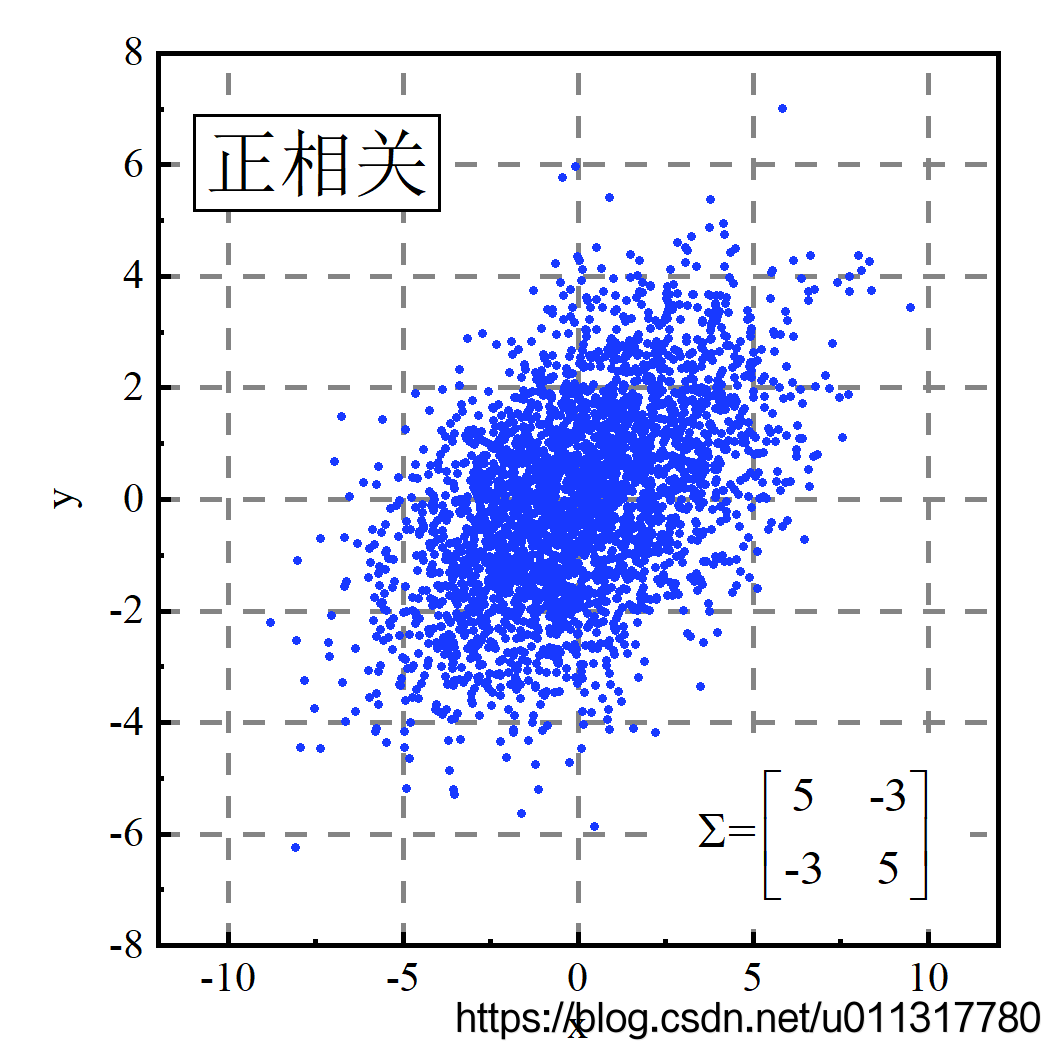
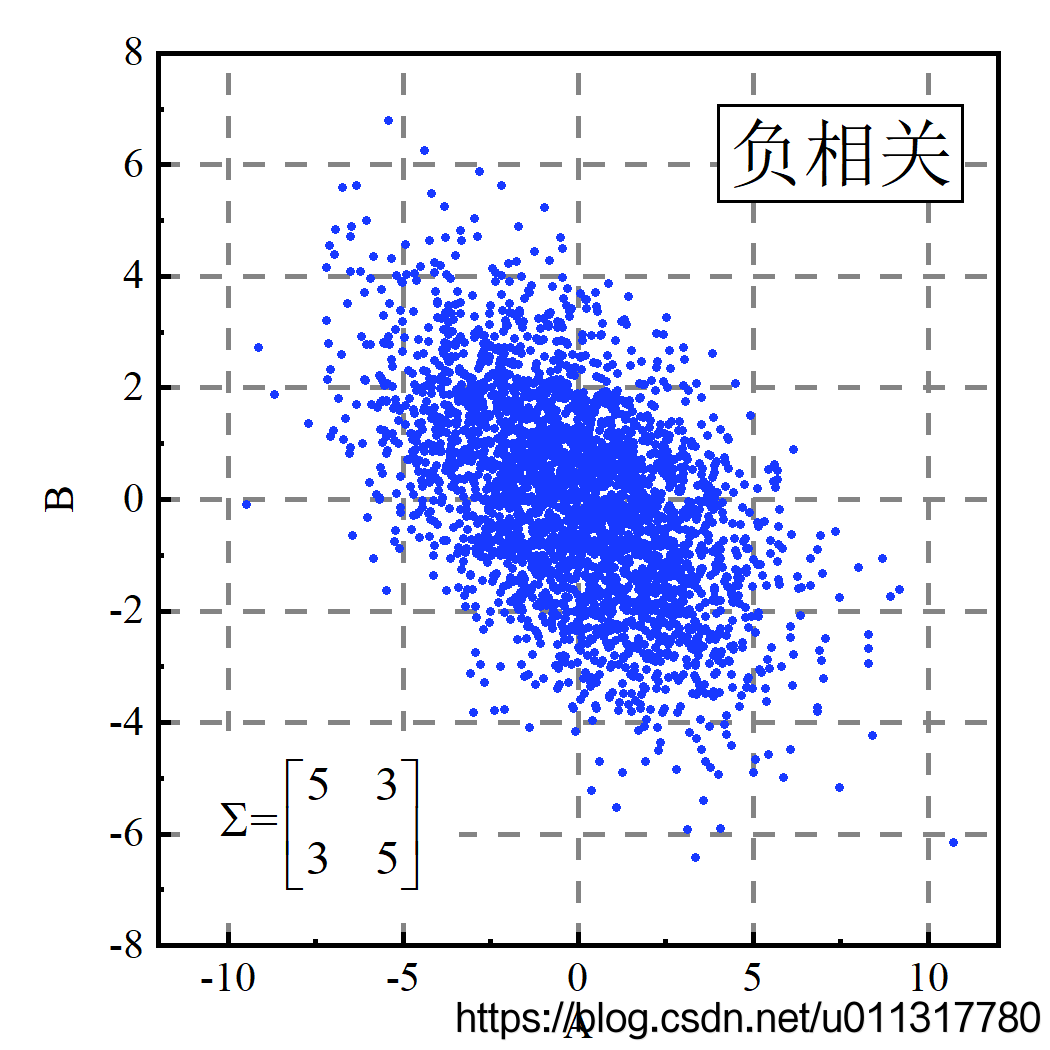
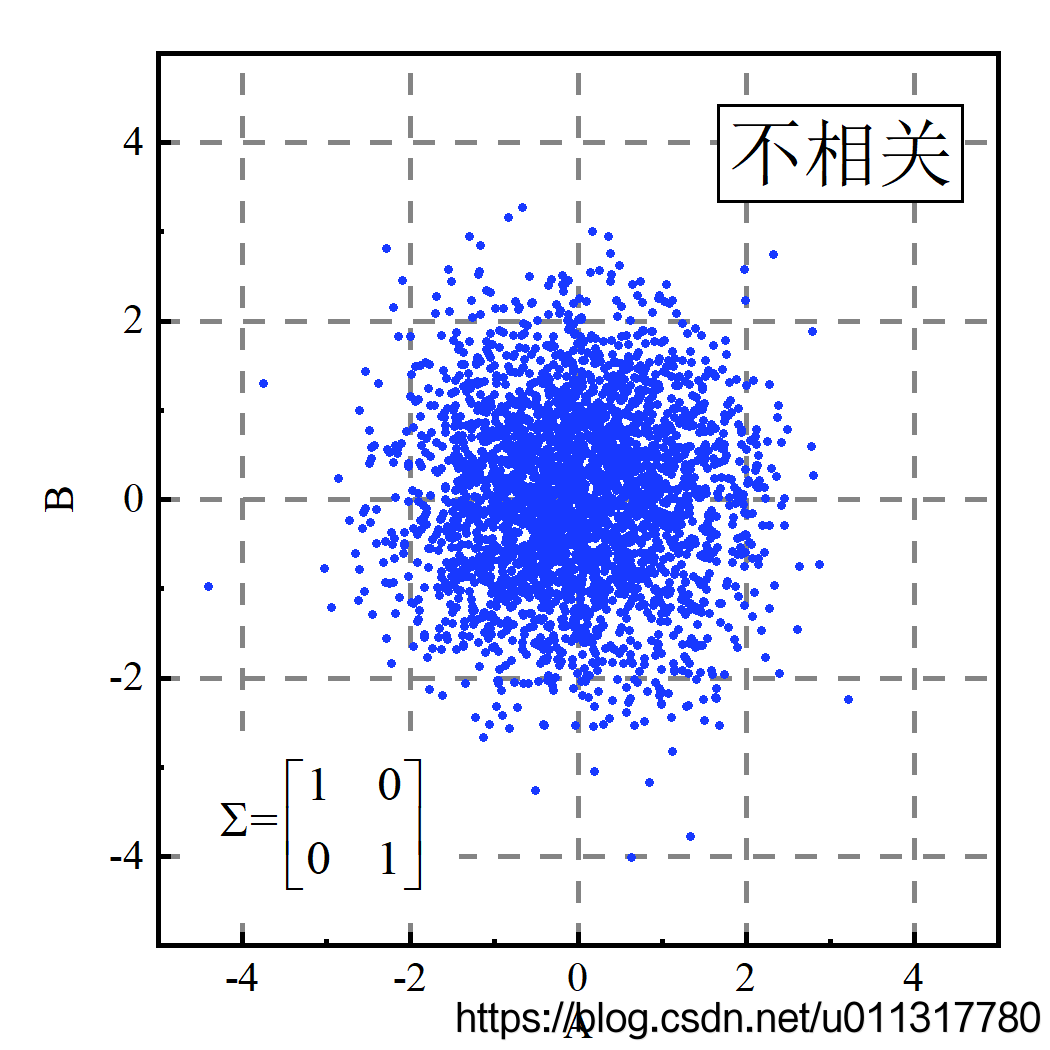
协方差矩阵中的主对角线是对应变量的方差,斜对角线是两个变量的协方差。从图中可以看到,当协方差为正时,两个维度正相关,表现为y具有随x的增大而增大的趋势;当协方差为负时,两个维度负相关,表现为 y y y具有随 x x x的增大而减小的趋势;当协方差为零时,两变量不相关, y y y随 x x x的变化没有明显的变化趋势。
利用标准正态分布数据生成非标准正态分布数据
若有相互独立的标准正态分布变量 X X X和 Y Y Y,及其线性组合后的随机变量 A = a X + b Y A=aX+bY A=aX+bY和 B = c X + d Y B=cX+dY B=cX+
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









