







C++学习链接
常见字符
*
- 注释:/* 这是一个注释*/
- 乘法:a * b
- 取值运算符(间接值/解除引用/解引用运算符):*指针变量,int a = 4;int *p=&a; *p
- 指针变量:数据类型 *变量名, int *no = &bh,代表了no是一个指针
- 数据类型:int*:整型指针类型、char* 字符指针类型,char* c=(char *) &b。int no=38,int* ptr=&no, &no和ptr是一个东西,no和*ptr是一个东西。
注意:int *no 和 int* no什么区别
1. 实际上没有区别
2. int* a, b; 这里 a 是指向 int 的指针,而 b 只是一个普通的 int 整数变量。
3. int *a, *b; 这样的声明清晰地表明 a 和 b 都是指向 int 的指针。
::
- 变量属于哪个域:std::count<<"no"
- 当局部变量和全局变量名称相同时,会屏蔽全局变量使用局部变量,如果想使用全局变量,使用::,:: a。
常见关键词
typedef
数据类型的别名
static(静态)
静态局部变量
- 主要作用:会影响变量的存储期和作用域。
- 只会被初始化一次
- 静态局部变量:static修饰的局部变量生命周期和程序相同。即在函数调用结束后不会被销毁,而是保持其值直到下次调用。
- 静态类成员:用 static 声明的类成员属于整个类,而不是类的各个实例。
const(常量)
- 主要作用:增强程序的安全性
- 初始化之后,值不能被修改
- 当 const 修饰类的成员函数时,表示该函数不会修改类的任何成员变量
指针
- 常量指针:const 数据类型 *变量名;不能通过解引用的方法修改内存地址中的值(用原始的变量名是可以修改的)。
-
Int a=3,b=4;
const int* p=&a; #报错
*p = 13; p=&b; #不报错
-
- 指针常量
- 数据类型 * const 变量名;
- 指向的变量(对象)不可改变。
- 在定义的同时必须初始化,否则没有意义。
- 可以通过解引用的方法修改内存地址中的值。
-
Int a=3,b=4;
const int* p=&a; #不报错
*p = 13; p=&b; #报错
-
新名字:引用
-
常指针常量
-
const 数据类型 * const 变量名;
-
指向的变量(对象)不可改变,不能通过解引用的方法修改内存地址中的值。
-
新名字:常引用。
-
常量指针:指针指向可以改,指针指向的值不可以更改。
指针常量:指针指向不可以改,指针指向的值可以更改。
常指针常量:指针指向不可以改,指针指向的值不可以更改。
记忆秘诀:*表示指针,指针在前先读指针;指针在前指针就不允许改变。
常量指针:const 数据类型 *变量名
指针常量:数据类型 * const 变量名
-
void
- 函数的返回值用void,表示函数没有返回值。
- 函数的参数填void,表示函数不需要参数(或者让参数列表空着)。
- 函数的形参用void *,表示接受任意数据类型的指针。
- 注意:
- 不能用void声明变量,它不能代表一个真实的变量,但是,用void *可以。
- 不能对void *指针直接解引用(需要转换成其它类型的指针)。
- 把其它类型的指针赋值给void*指针不需要转换。
- 把void *指针赋值给把其它类型的指针需要转换。
内存
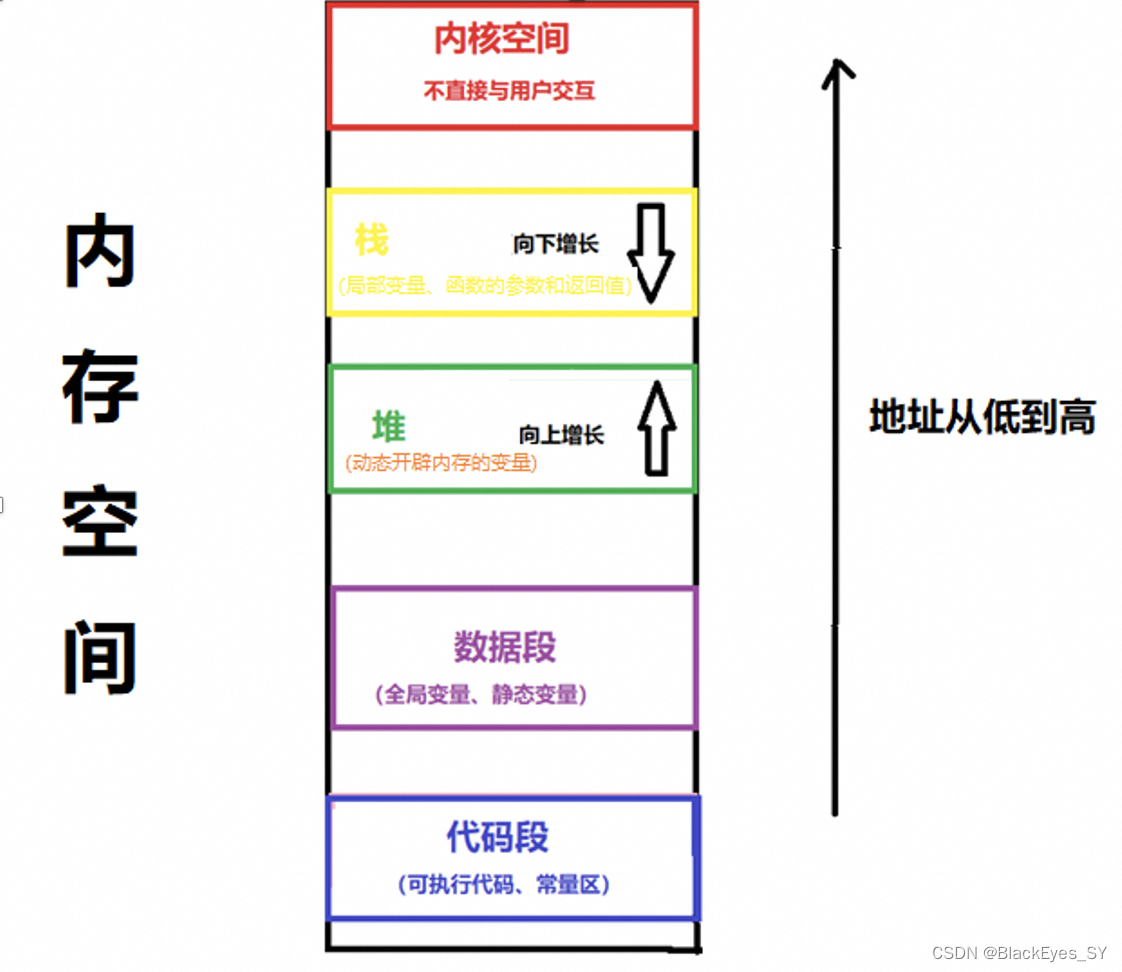
内存分为内核空间和用户空间,内核空间由操作系统管理,与程序员没什么关系。我们写的程序运行在用户空间。一个c++源程序编译成可执行程序后,二进制文件的大小是固定的,最多几十兆。
程序运行时,内存主要分成四个区,分别是栈、堆、数据段和代码段。
1)栈:存储局部变量、函数参数和返回值。不管计算机的内存是8G还是16G,分配给栈的只有几兆。修改系统参数可以调整栈的大小。auto 变量通常在栈上分配。
2)堆:存储动态开辟内存的变量。内存越大,分配的内存就越大。
3)数据段:存储全局变量和静态变量。
4)代码段:存储可执行程序的代码和常量(例如字符常量),此存储区不可修改。
注意:栈和堆的主要区别:
1)管理方式不同:栈是系统自动管理的,在出作用域时,将自动被释放;堆需手动释放,若程序中不释放,程序结束时由操作系统回收。
2)空间大小不同:堆内存的大小受限于物理内存空间;而栈就小得可怜,一般只有8M(可以修改系统参数)。
3)分配方式不同:堆是动态分配;栈有静态分配和动态分配(都是自动释放)。
4)分配效率不同:栈是系统提供的数据结构,计算机在底层提供了对栈的支持,进栈和出栈有专门的指令,效率比较高;堆是由C++函数库提供的。
栈的效率非常高,堆是用链表来管理的,效率会低一点。
5)是否产生碎片:对于栈来说,进栈和出栈都有着严格的顺序(先进后出),不会产生碎片;而堆频繁的分配和释放,会造成内存空间的不连续,容易产生碎片,太多的碎片会导致性能的下降。
6)增长方向不同:栈向下增长,以降序分配内存地址;堆向上增长,以升序分配内存地址。
空指针
- 用0或NULL都可以表示空指针。int* p=0,表示还没有指向任何地址。
- 如果对空指针使用delete运算符,系统将忽略该操作,不会出现异常。
-
用0和NULL表示空指针会产生歧义,C++11建议用nullptr表示空指针,也就是(void *)0。
野指针
出现野指针的情况主要有三种:
1)指针在定义的时候,如果没有进行初始化,它的值是不确定的(乱指一气)。
2)如果用指针指向了动态分配的内存,内存被释放后指针不会置空,但是,指向的地址已失效。
3)指针指向的变量已超越变量的作用域(变量的内存空间已被系统回收),让指针指向了函数的局部变量,或者把函数的局部变量的地址作为返回值赋给了指针。
规避方法:
1)指针在定义的时候,如果没地方指,就初始化为nullptr。
2)动态分配的内存被释放后,将其置为nullptr。
3)函数不要返回局部变量的地址。
注意:野指针的危害比空指针要大很多,在程序中,如果访问野指针,可能会造成程序的崩溃。是可能,不是一定,程序的表现是不稳定,增加了调试程序的难度。
函数指针
- 声明函数指针;
-
函数指针的声明是:
int (*pfa)(int,string);
bool (*pfb)(int,string);
bool (*pfc)(int);
pfa、pfb、pfc是函数指针名
-
- 让函数指针指向函数的地址;
-
函数指针的赋值:函数指针名=函数名;
-
- 通过函数指针调用函数。
-
(*函数指针名)(实参); C
函数指针名(实参); C++
-
数组
初始化:
1)数据类型 数组名[数组长度] = { 值1,值2,值3, ...... , 值n};
2)数据类型 数组名[ ] = { 值1,值2,值3, ...... , 值n};
3)数据类型 数组名[数组长度] = { 0 }; // 把全部的元素初始化为0。
4)数据类型 数组名[数组长度] = { }; // 把全部的元素初始化为0。
数组相关函数
sizeof(数组名):可以得到整个数组占用内存空间的大小
memset():把数组中全部的元素清零。void *memset(void *s, int c, size_t n);
memcpy():把数组中全部的元素复制到另一个相同大小的数组。头文件#include <string.h>。函数原型:void *memcpy(void *dest, const void *src, size_t n);
数组的地址
a)数组在内存中占用的空间是连续的。
b)C++将数组名解释为数组第0个元素的地址。
c)数组第0个元素的地址和数组首地址的取值是相同的。
double a[5];
cout << "a的值是:" << (long long) a << endl;
cout << "&a的值是:" << (long long)&a << endl;
cout << "a[0]的地址是:" << (long long) &a[0] << endl;
/*这三个值一样*/指针的数组表示
在C++内部,用指针来处理数组。
C++编译器把 数组名[下标] 解释为 *(数组首地址+下标)
C++编译器把 地址[下标] 解释为 *(地址+下标)
int a[5] = [3,5,6,7,8,9,10,11];
int *p = a;
for(int ii=0; ii<5;ii++)
{
count<<"a["<<ii<<"的值是:"<<a[ii]<<end;
count<<"*(p+"<<ii<<")的值是:"<<*(p+ii)<<end;
count<<"p["<<ii<<"的值是:"<<p[ii]<<end;
}一维数组的排序qsort
void qsort(void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *));
- 为什么需要第三个形参size_t size?
- 在函数内部不是按照函数类型操作的,而是按照内存块来操作的,交换两个元素,不是用赋值,而是memcpy()函数。
- size_t是C标准库中定义的,在64位系统中是8字节无符号整型(unsigned long long)。typedef unsigned long long size_t
动态分配内存new
用new动态创建变量
- 申请内存的语法:new 数据类型(初始值); new int(5) // C++11支持{}
- 如果动态分配的内存不用了,必须用delete释放它,否则有可能用尽系统的内存。
用new动态创建一维数组
1)数组的内存:普通数组在栈上分配内存,栈很小;如果需要存放更多的元素,必须在堆上分配内存。
2)创建:动态创建一维数组的语法:数据类型 *指针=new 数据类型[数组长度];
3)释放:释放一维数组的语法:delete [] 指针;
注意:
- 不要用delete[]来释放不是new[]分配的内存。
- C语言的malloc()函数也可以动态分配内存,malloc()函数分配的内存要用free()函数来释放,不能用delete。
- 指针指向的地址是栈上的变量,普通变量的地址也不能用delete。int a[1000]; a[1000]=8;
- 不要用delete[]释放同一个内存块两次(否则等同于操作野指针)。
- 对空指针用delete[]是安全的(释放内存后,应该把指针置空nullptr)。
- 不写[],只会释放第0个元素的内存空间
- 如果内存不足,调用new会产生异常,导致程序中止;如果在new关键字后面加(std::nothrow)选项,则返回nullptr,不会产生异常。int a[100000]; a[100000]=8;内存不足,会崩溃掉。int *a = new int[1000000000]; a[10000000000]=8;内存不足,会崩溃掉。
for (int ii = 1; ii > 0; ii++)
{
int* p = new int[100000]; // 一次申请100000个整数。
cout << "ii="<<ii<<",p=" << p << endl;
}内存会螺旋式越来越大,(一会大一会小,是因为系统有交换区)
C风格的字符串
- string是C++的类,封装了C风格的字符串。
- string能自动扩展,不用担心内存问题。
-
C语言约定:如果字符型(char)数组的末尾包含了空字符\0(也就是0),那么该数组中的内容就是一个字符串。
- 一个中文汉字占两个字节。
- string str='XYZ', str[0]显示字符,int(str[0]) 显示ascii码。
初始化
char name[11]; // 可以存放10个字符,没有初始化,里面是垃圾值。
char name[11] = "hello"; // 初始内容为hello,系统会自动添加0。
char name[] = { "hello" }; // 初始内容为hello,系统会自动添加0,数组长度是6。
char name[11] = { "hello" }; // 初始内容为hello,系统会自动添加0。
char name[11] { "hello" }; // 初始内容为hello,系统会自动添加0。C++11标准。
char name[11] = { 0 }; // 把全部的元素初始化为0。
注:
char name[11];
count<<"name="<<name<<end;
11个字节,一个汉字是两个字节,应该显示5个烫,为什么显示这么多?
不管是C还是C++,处理字符串的时候,从字符数组的起始地址开始,遇到0才结束。没遇到0就继续找。

相关函数
-
memset(name,0,sizeof(name)); // 把全部的元素置为0。
-
strcpy()字符串复制或赋值。
char *strcpy(char* dest, const char* src);
功 能: 将参数src字符串拷贝至参数dest所指的地址。注:C++风格的字符串可以用等号赋值,C风格的字符串不能用等号赋值,要用strcpy。
-
strncpy()字符串复制或赋值
-
strlen()获取字符串的长度
-
strcat()字符串拼接
-
strncat()字符串拼接
-
strcmp()和strncmp()字符串比较
-
strchr()和strrchr()查找字符
-
strstr()查找字符串
-
注意事项:
-
操作字符串的函数,遇到0字符串才结束,不会判断数组是否越界,因为操作字符串的函数行参是指针,只存放了字符串的起始地址,没有数组长度参数。
-
不要在子函数中对字符指针用sizeof运算,因为得到的是指针占用内存空间的大小,都是8字节,不是数组的大小。所以,不能在子函数中对传入的字符串进行初始化,除非字符串的长度也作为参数传入到了子函数中。
-
二维数组
行指针(数组指针)
声明行指针的语法:数据类型 (*行指针名)[行的大小]; // 行的大小即数组长度。
int (*p1)[3]; // p1是行指针,用于指向数组长度为3的int型数组。
double (*p3)[5]; // p3是行指针,用于指向数组长度为5的double型数组。
注:
int (*p2) [5]: 行指针
int* p2[5] 指针数组
存储类
-
auto:这是默认的存储类说明符,通常可以省略不写。auto 指定的变量具有自动存储期,即它们的生命周期仅限于定义它们的块(block)。auto 变量通常在栈上分配。
-
static:用于定义具有静态存储期的变量或函数,它们的生命周期贯穿整个程序的运行期。在函数内部,static变量的值在函数调用之间保持不变。在文件内部或全局作用域,static变量具有内部链接,只能在定义它们的文件中访问。
-
extern:用于声明具有外部链接的变量或函数,它们可以在多个文件之间共享。默认情况下,全局变量和函数具有 extern 存储类。在一个文件中使用extern声明另一个文件中定义的全局变量或函数,可以实现跨文件共享。
-
mutable (C++11):用于修饰类中的成员变量,允许在const成员函数中修改这些变量的值。通常用于缓存或计数器等需要在const上下文中修改的数据。
-
thread_local (C++11):用于定义具有线程局部存储期的变量,每个线程都有自己的独立副本。线程局部变量的生命周期与线程的生命周期相同。
结构体
函数
- 清空结构体:memset(&stgirl, 0, sizeof(stgirl));可以把结构体中全部的成员清零。
- 清空结构体:bzero(&stgirl, sizeof(stgirl));可以把结构体中全部的成员清零。
- 复制结构体:memcpy:把结构体中全部的元素复制到另一个相同类型的结构体.
- 复制结构体:=
链表
- 都是动态分配内存,没有静态一说。
重载(派生类使用基类函数)
继承
-
友元函数不是类成员,不能继承。
构造函数/析构函数
-
构造函数不能继承,创建派生类对象时,先执行基类构造函数,再执行派生类构造函数。
-
析构函数不能继承,而销毁派生类对象时,先执行派生类析构函数,再执行基类析构函数。
构造基类
- 基类构造函数负责初始化被继承的数据成员(基类成员变量必须有基类的构造函数初始化);派生类构造函数主要用于初始化新增的数据成员。
- 基类的私有成员在派生类不可见,派生类没办法初始化基类的私有成员。
- 所有派生类构造函数都初始化基类数据,属于重复,不符合继承的理念。
访问权限
公有继承
| 各成员 | 派生类中 | 基类与派生类外 |
| 基类的公有成员 | 直接访问 | 直接访问 |
| 基类的保护成员 | 直接访问 | 调用公有函数访问 |
| 基类的私有成员 | 调用公有函数访问 | 调用公有函数访问 |
| 从基类继承的公有成员 | 直接访问 | 直接访问 |
| 从基类继承的保护成员 | 直接访问 | 调用公有函数访问 |
| 从基类继承的私有成员 | 调用公有函数访问 | 调用公有函数访问 |
| 派生类中定义的公有成员 | 直接访问 | 直接访问 |
| 派生类中定义的保护成员 | 直接访问 | 调用公有函数访问 |
| 派生类中定义的私有成员 | 直接访问 | 调用公有函数访问 |
私有继承
| 第一级派生类中 | 第二级派生类中 | 基类与派生类外 | |
| 基类的公有成员 | 直接访问 | 不可访问 | 不可访问 |
| 基类的保护成员 | 直接访问 | 不可访问 | 不可访问 |
| 基类的私有成员 | 调用公有函数访问 | 不可访问 | 不可访问 |
多态(基类使用派生类函数)(基类指针可以指向派生类对象)
-
基类指针只能调用基类的成员函数,不能调用派生类的成员函数。
-
有了virtual虚函数,基类指针指向基类对象时就使用基类的成员函数和数据,指向派生类对象时就使用派生类的成员函数和数据,
virtual/虚函数
- 在基类的成员函数前加virtual 关键字,把它声明为虚函数,基类指针就可以调用派生类中同名的成员函数,通过派生类中同名的成员函数,就可以访问派生对象的成员变量。
| 基类调用派生类情况 | ||
| 有virtual函数 | 基类指针指向派生类对象,调用派生类函数 | |
| 有virtual函数 | 基类指针指向派生类对象,加基类的域,调用基类函数 | |
| 没virtual函数 | 基类指针指向派生类对象,调用基类函数 |
纯虚函数
-
纯虚函数只有函数名、参数和返回值类型,没有函数体,具体实现留给该派生类去做。
抽象类
-
含有纯虚函数的类被称为抽象类,不能实例化对象,可以创建指针和引用。
-
派生类必须重定义抽象类中的纯虚函数,否则也属于抽象类。
dynamic_cast
运行阶段类型识别。语法:派生类指针 = dynamic_cast<派生类类型 *>(基类指针);
dynamic_cast只适用于包含虚函数的类。因为要查虚函数表。
final
- 限制某个类不能被继承
- 或者某个虚函数不能被重写
override
- 重写基类的虚函数
#pragma once
#pragma once用来防止某个头文件被多次include。只要在头文件的最开始加入这条指令就能够保证头文件被编译一次。
#ifndef,#define,#endif用来防止某个宏被多次定义。
内联函数
在C++中,内联函数可代替有参数的宏,效果更好。
宏
宏和const
结构体和类
STL
| 逻辑结构 | 物理结构 | 底层 | ||
| string | ||||
| list | 链表 | |||
| vector | 数组 | |||
| pair | ||||
| map | ||||
| unordered map | 数组+链表 | |||
| queue | 队列 | 数组或链表 | ||
| array | 静态数组 | |||
| deque | 双端队列 | |||
| forward_list | 单链表 | |||
| multimap | 红黑树 | |||
| set&multiset | 红黑树 | |||
| unordered_multimap | ||||
| unordered_set&unordered_multiset | ||||
| priority_queue | 有权值的单向队列queue | deque和list | ||
| stack | deque和list |
vector
封装的是数组
list
封装的是链表
pair
- 类模板
- 实现是结构体
- make_pair()返回的临时对象。//auto p5 = make_Pair<int, string>(5, "西施5");
红黑树
- 如果数据量很小,数组+二分查找法;如果数据量很大(几万),用红黑树。;如果数据量达到了上千万
map
- 封装了红黑树(平衡二叉排序树)
- map容器的元素是pair键值对。
unordered_map哈希表
- 容器封装了哈希表
- 数组+链表
- 效率
- 插入不需要比较
- 删除元素与查找元素的效率相同
queue
- queue容器的逻辑结构是队列,物理结构可以是数组或链表
- queue容器不支持迭代器。
智能指针
unique_ptr
- 独享它指向的对象
- 因此没有赋值和拷贝功能,因为要独享。
- 不要用同一个裸指针初始化多个unique_ptr对象。
shared_ptr
- 共享它指向的对象
-
make_shared:
std::make_shared是一种用于创建std::shared_ptr的便利函数
weak_ptr
裸指针 vs智能指针
- 裸指针
- 内存泄漏:内存没有被正确释放
- 悬空指针(dangling pointer):指针所指向的内存被释放后,指针未置为
nullptr - 多次释放等:同一个指针被多次释放,通常会导致程序崩溃。
- 智能指针
auto
-
自动推导类型
-
它们的生命周期仅限于定义它们的块(block)。auto 变量通常在栈上分配。
-
explicit
- 关闭类型自动转换的特性
常见知识点
运行C++程序
Mac运行cpp程序:g++ -o demo demo.cpp
标准
- C++98
- C++11现在用的比较多
- C++14:落地要过几年
内存
| 位置 | |
| 智能指针 | 栈 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









