










正则化regulation
欠拟合与过拟合
欠拟合:在训练集上准确率较小
过拟合:表现为在训练集上准确率高,训练误差较小。而在测试集上准确率与训练集上的表现相差较远,测试误差较大。
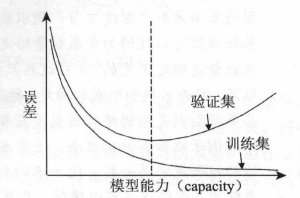
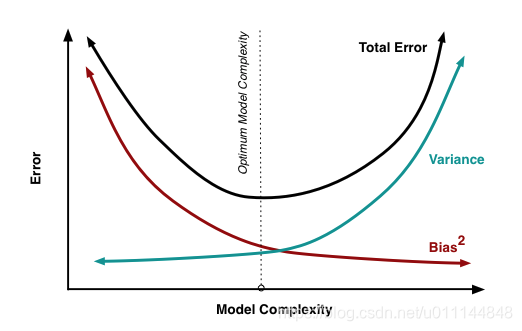
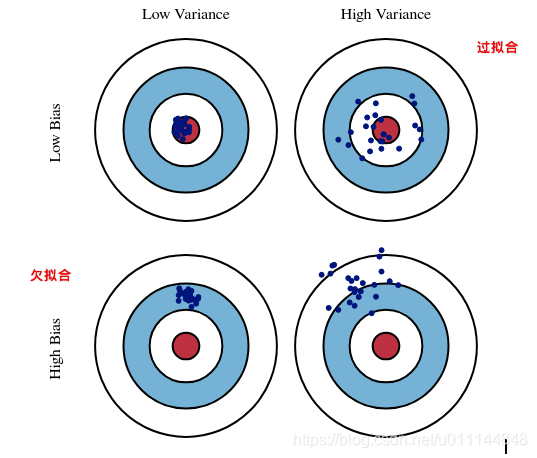
Bias-Variance:
L2 正则化(L2 regularization)
损失函数中加L2正则化项后:
l
′
(
W
)
=
L
(
W
)
+
α
∑
i
w
i
2
l^{'}(W)=L(W)+\alpha\sum_{i}{w_{i}^{2}}
l′(W)=L(W)+α∑iwi2
加入L2正则化惩罚项后,权重整体趋向于减小。
dropout
dropout是在深度学习中常用的一种正则化方法。简单的说就是在隐藏层以一定的概率使神经元失活,相等于特征得到随机组合,以此来减小模型复杂度,增强泛化能力。
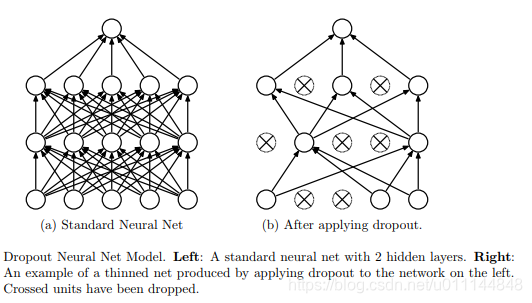
注意:
1、前向传播中,在隐藏层以一定的概率使个别神经元失活
2、前向传播中,要对没有失活的数据进行scale
3、反向传播中,在前向阶段失活的神经元依然保持失活
4、test 和应用阶段,不需要进行 dropout
其他防止过拟合的方法
1、增加训练数据(如图像数据可以通过,旋转、裁剪缩放等方法扩充数据)
2、增加噪声
3、减小模型复杂度
代码示例
```python
# 以一个2层的神经网络为例
# 一个前向传播的函数
def forward_propagation_with_dropout(X, parameters, keep_prob =0.5):
"""
一个简单的 droupout 示例,前向传播
1、在隐藏层,以一定的概率使某些神经元失活
2、对其他,未失活的数字进行 scale
"""
# 获取参数
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# 前向计算
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
D1 = np.random.rand(A2.shape[0],A2.shape[1])
D1 = D2<keep_prob
A1 = A2*D2 # 使某些神经元失活
A1 = A2/keep_prob # 对其余的值进行scale
Z2 = np.dot(W2, A1) + b2
A2 = relu(Z2)
D2 = np.random.rand(A2.shape[0],A2.shape[1])
D2 = D2<keep_prob
A2 = A2*D2 # 使某些神经元失活
A2 = A2/keep_prob # 对其余的值进行scale
Z3 = np.dot(W3, A2) + b3
A3 = sigmoid(Z3)
cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)
return A3, cache
# 反向传播
# 对于,前向传播中 失活的神经元,在反向传播的过程中依然失活
def backward_propagation_with_dropout(X,Y,cache,keep_prob):
"""
反向传播,链式法则
前向传播中 失活的神经元,在反向传播的过程中依然失活
"""
m = X.shape[1]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = 1./m * np.dot(dZ3, A2.T)
db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True)
dA2 = np.dot(W3.T, dZ3)
dA2 = dA2*D2
dA2 = dA2/keep_prob
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = 1./m * np.dot(dZ2, A1.T)
db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)
dA1 = np.dot(W2.T, dZ2)
dA1 = dA1*D1
dA1 = dA1/keep_prob
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = 1./m * np.dot(dZ1, X.T)
db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
参考
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
dropout
youtube: Machine Learning Fundamentals: Bias and Variance
wikipedia: regularization


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









