







一.简单的获取网页
''' 简单的获取网页'''
import urllib.request
response = urllib.request.urlopen('https://baidu.com')
print(response.read().decode('utf-8'))
print(type(response))二.通过HTTPRreponse获取对象中主要的方法和属性的用法
'''获取HTTPResponse中主要的方法和属性'''
import urllib.request
response = urllib.request.urlopen('https://www.jd.com')
print('response的类型:',type(response))
print('status:',response.status, 'msg:',response.msg,'version:',response.version)
print('headers:',response.getheaders())
print('headers.Content-type',response.getheader('Content-Tpye'))
print(response.read().decode('utf-8'))三.发送post请求
httpbin.org/post是一个用于测试HTTP POST请求的网址,如果请求成功,服务端会将post请求信息原封不动的返回客户端。
'''发送post请求'''
import urllib.request
data = bytes(urllib.parse.urlencode({'name':'Bill', 'age':30}), encoding='utf-8')
#一旦指定data, urlopen就会向服务端提交post请求
response = urllib.request.urlopen('http://httpbin.org/post', data = data)
print(response.read().decode('utf-8'))
运行结果:
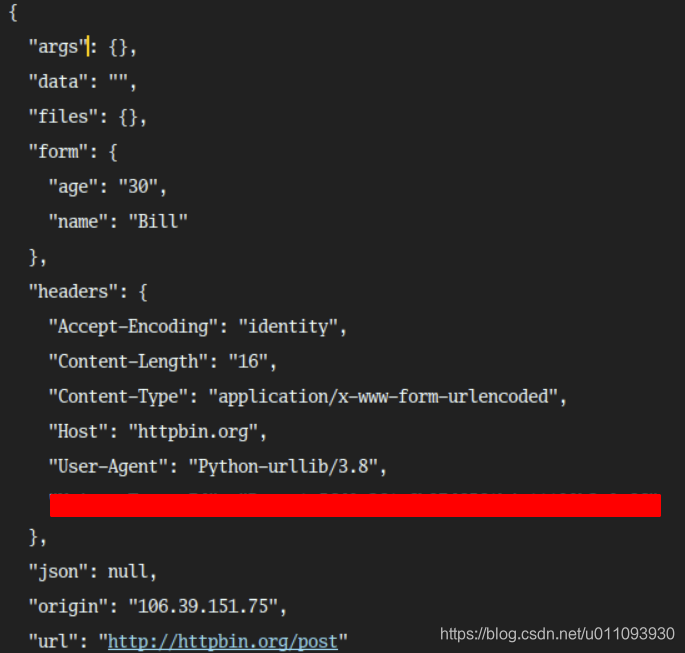
四.使用try...except捕获urlopen抛出的超时异常
'''使用try...except捕获urlopen抛出的超时异常'''
import urllib.request
import socket
import urllib.error
try:
#由于大多数网站都不太可能在0.1秒内响应客户端,所以timeout设为0.1基本都会超时异常
response = urllib.request.urlopen('http://httpbin.org/get', timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('超时')
print('继续')运行结果:
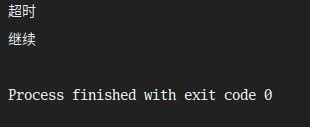
五.修改HTTP请求头,并添加自定义请求头who, 然后将修改后的请求头提交给httpbin.org,并输出最后结果
'''设置HTTP请求头'''
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_4_3) AppleWebKit/537.36(KHTML, like Gecko) Chorme/72.0.3626.109 Safari/537.36',
'Host' : 'httpbin.org' ,
'who' : 'Python Scrapy'
}
#定义表单数据
dict = {
'name' : 'km',
'age' : 18
}
#post请求得是bytes类型
data = bytes(parse.urlencode(dict), encoding='utf-8')
req = request.Request(url = url, data = data, headers = headers)
response = request.urlopen(req)
print(response.read().decode('utf-8'))运行结果:
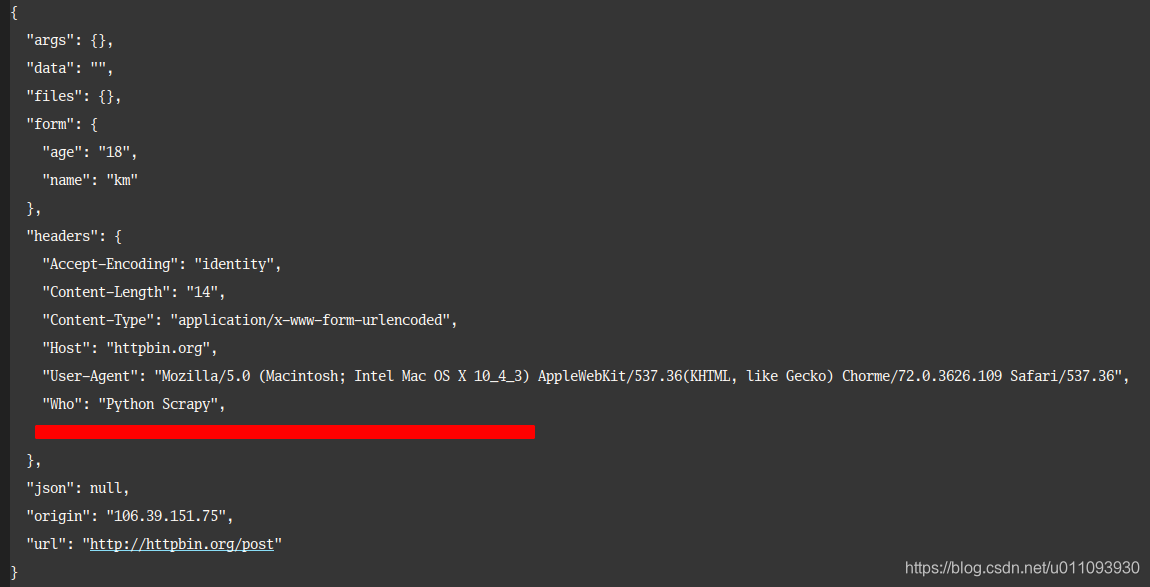
六.设置中英文HTTP请求头,并对其解码
'''设置HTTP请求头,并对其解码'''
from urllib import request
#注意不是直接import parse
from urllib.parse import unquote, urlencode
import base64
url = 'http://httpbin.org/post'
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_4_3) AppleWebKit/537.36(KHTML, like Gecko) Chorme/72.0.3626.109 Safari/537.36',
'Host' : 'httpbin.org', #这里没有/post
'Chinese1' : urlencode({'name':'玛丽',}), #用url编码格式设置中文HTTP请求头
'MyChinese' : base64.b64encode(bytes('这是b64中文请求头', encoding='utf-8')), #用base64编码格式设置中文HTTP请求头
'who' : 'Python Scrayp'
}
dict = {
'name' : 'Mary',
'age' : 18
}
data = bytes(urlencode(dict), encoding='utf-8')
#data 这个参数必须为bytes形式
req = request.Request(url = url, data = data, headers=headers, method='POST')
req.add_header('Chinese2', urlencode({'国籍' : '中国'}))
#用add_header方法设置url编码格式的中文HTTP请求头
response = request.urlopen(req)
value = response.read().decode('utf-8')
print(value)
import json
#将返回值转换为json
responseObj = json.loads(value)
#unquote()和urlencode对应
print(unquote(responseObj['headers']['Chinese1']))
print(unquote(responseObj['headers']['Chinese2']))
print(str(base64.b64decode(responseObj['headers']['Mychinese']), 'utf-8'))
#HTTP请求头的大小写问题,urllib自动将除了第一个字母外的英文都变成了小写,所以此处需要写成Mychinese运行结果:
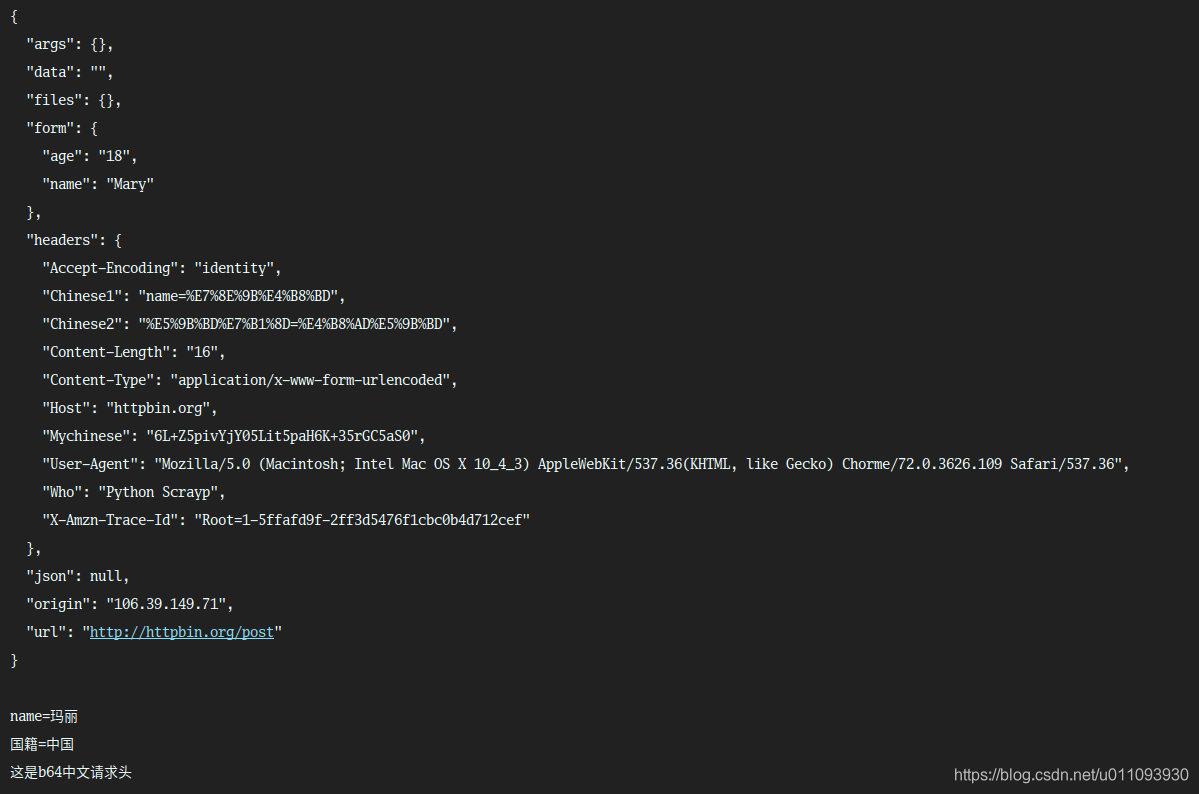


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









