







 文章分析了在网络发送端发送组播数据到运行在同一物理机上的四个虚拟机时出现的大量丢包现象。问题源于macvlan驱动的工作队列处理,当虚拟机数量增加时,CPU负载导致数据分发不均。通过将工作队列从system_wq改为system_unbound_wq,实现任务的负载均衡,从而优化了数据传输并减少了丢包。优化后iperf测试结果显示性能提升。
文章分析了在网络发送端发送组播数据到运行在同一物理机上的四个虚拟机时出现的大量丢包现象。问题源于macvlan驱动的工作队列处理,当虚拟机数量增加时,CPU负载导致数据分发不均。通过将工作队列从system_wq改为system_unbound_wq,实现任务的负载均衡,从而优化了数据传输并减少了丢包。优化后iperf测试结果显示性能提升。
目录
简介
业务环境
网络接收端:四个虚拟机(kernel-5.4.18)。这四个虚拟机安装在同一个物理机上(kernel-4.19)。
网络发送端:任意机器。
现象说明
网络发送端发送组播数据,四个虚拟机同时接收,测试程序是iperf。
多次测试发现,接收端物理机不会丢包 或者 丢包极少,但是虚拟机中会有大量丢包。本文将分析此问题的机理。
物理机中向虚拟机分发网络数据的大致流程
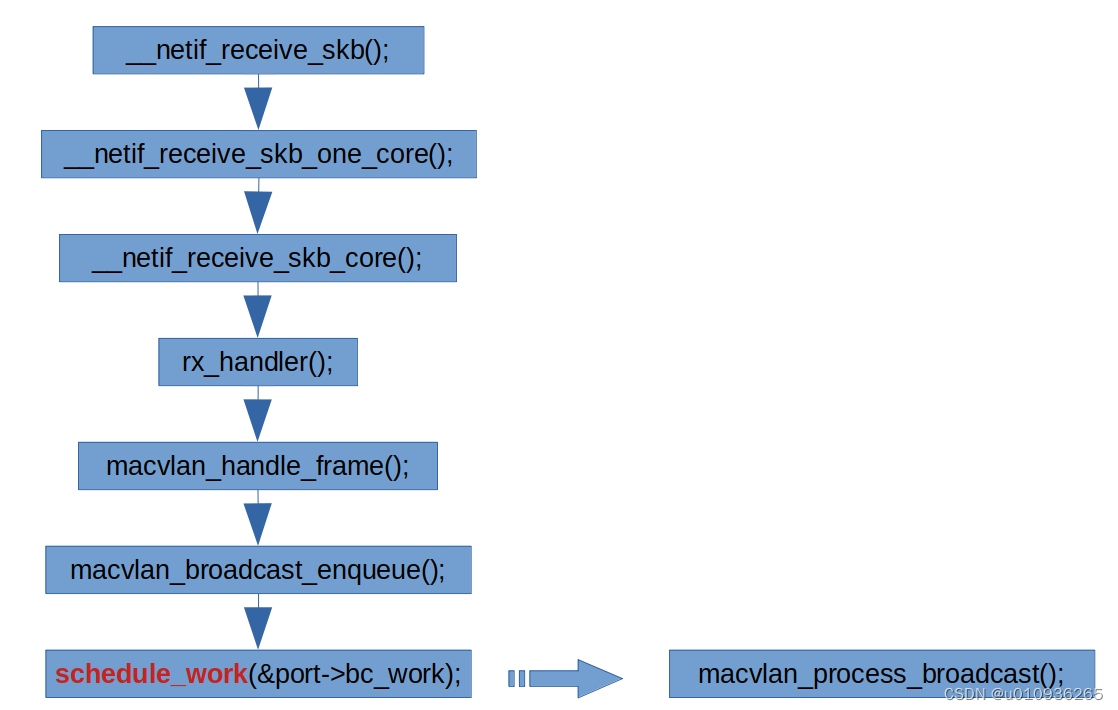
macvlan 驱动里通过代码“schedule_work(&port->bc_work);” 将 port->bc_work 添加到内核的全局工作队列(system_wq)里。port->bc_work 的处理函数是 macvlan_process_broadcast()。
当虚拟机数量(macvtap 虚拟网口数量)大于等于 4 个时,macvlan 的组播处理函数 macvlan_process_broadcast()需要向更多的虚拟网口发送组播数据,导致其所在的 CPU 的那个核负载达到 100% 。因为使用的是全局工作队列,而全局工作队列是绑定到处理器的工作队列,导致达到 100%负载的那个核无法通过负载均衡把负载分给其他核,进而导致虚拟机内无法收到部分网络数据。
优化方法
原始的 macvlan 驱动通过 schedule_work()函数将任务进行排队,这回导致任务绑定在固定的核上运行,不参与负载
均衡。现在需要让任务参与负载均衡,方法如下:
将
schedule_work(&port->bc_work);
改为
queue_work(system_unbound_wq, &port->bc_work);优化前后的测试数据对比
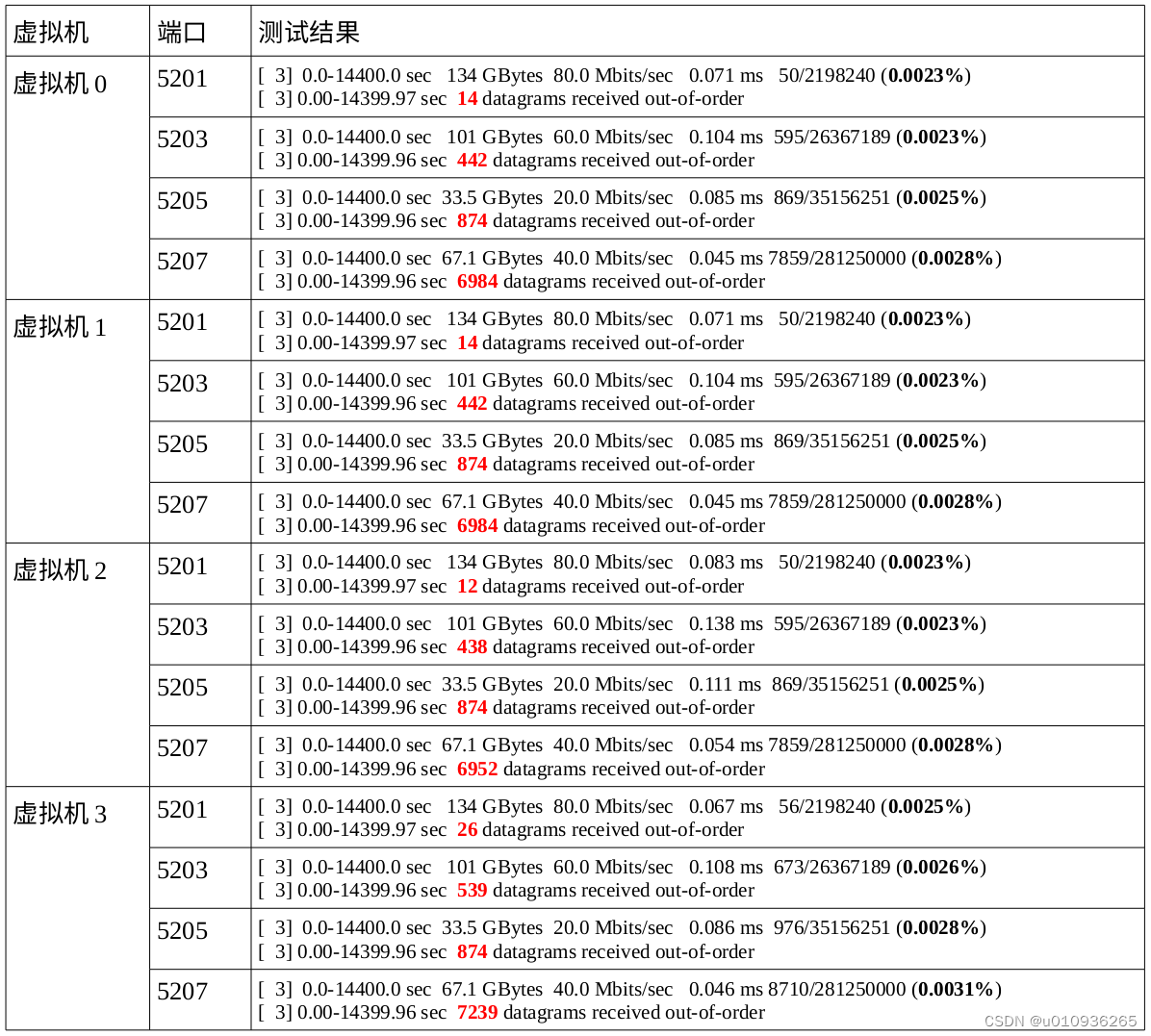
优化前的iperf测试结果
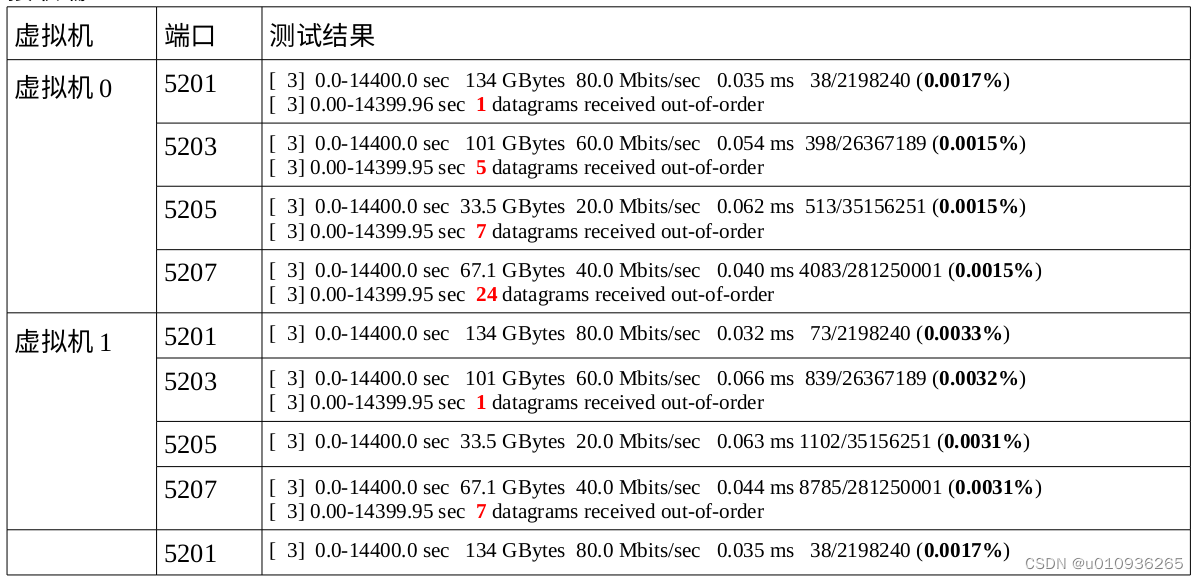
优化后的iperf测试结果

参考
《Linux 内核深度解析》P445

















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









