










最新资源获取地址:智库吧-专业资源共享平台 (zhikuba.com)
如果你还不会搭建hadoop大数据环境,如果你还不知道推荐系统该如何进行设计、如果你还不了解推荐系统的运行机制与优化,如果你还不懂推荐系统如何部署,如果你还没有你想要使用的数据,如果你想直接拿去当毕设(虽然可以,但是小编不推荐哈,好好学习才是立足之道),如果你想在实际工作中直接使用(这个肯定是需要根据实际业务更换一下数据的,也仅此而已),恭喜你,这篇文章会帮你解决以上所有问题,并不止于此!作为一个十多年的老码农,汉字都认识,但是已经不太会组合它们了,所以本篇文章主要以图文为主。
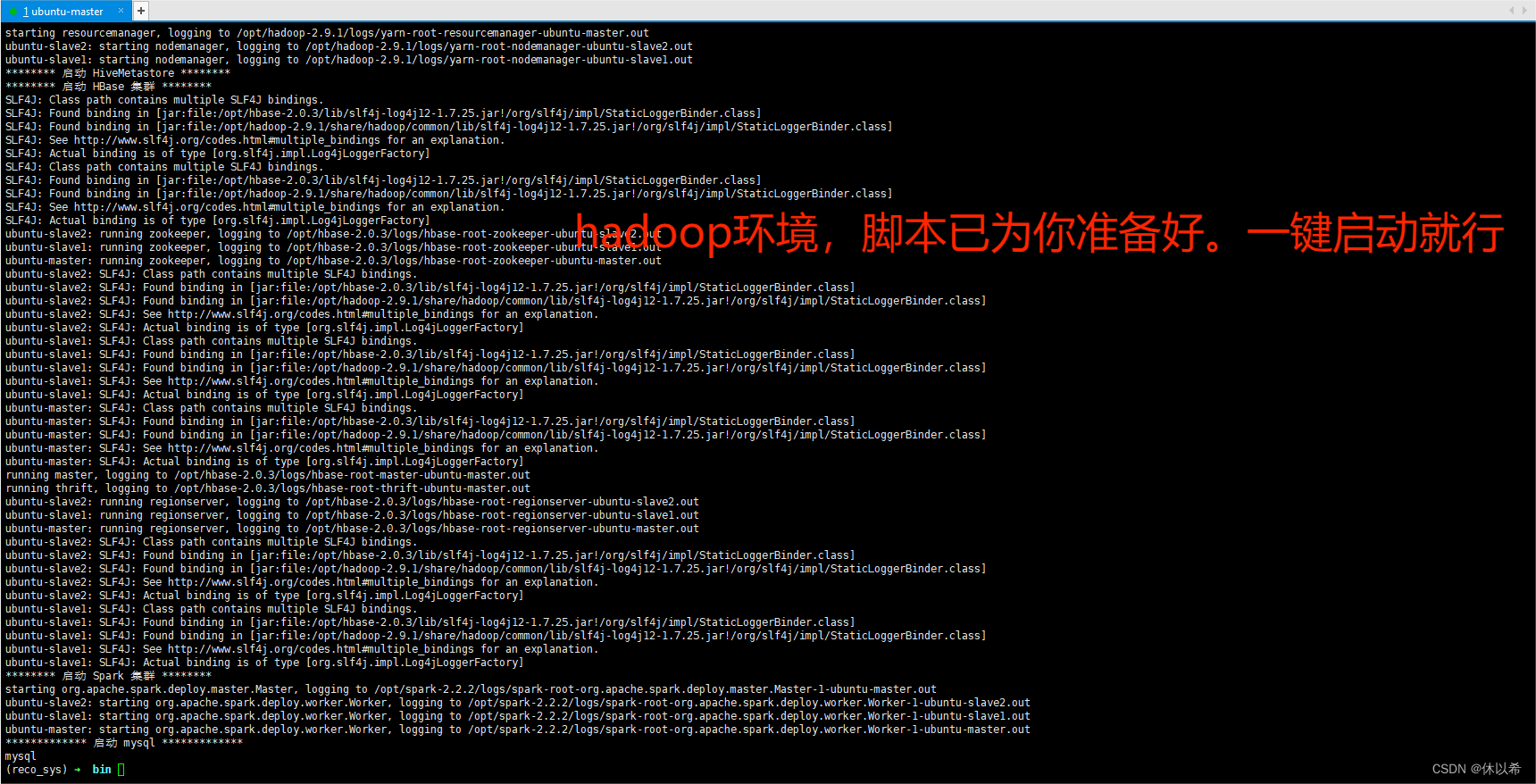
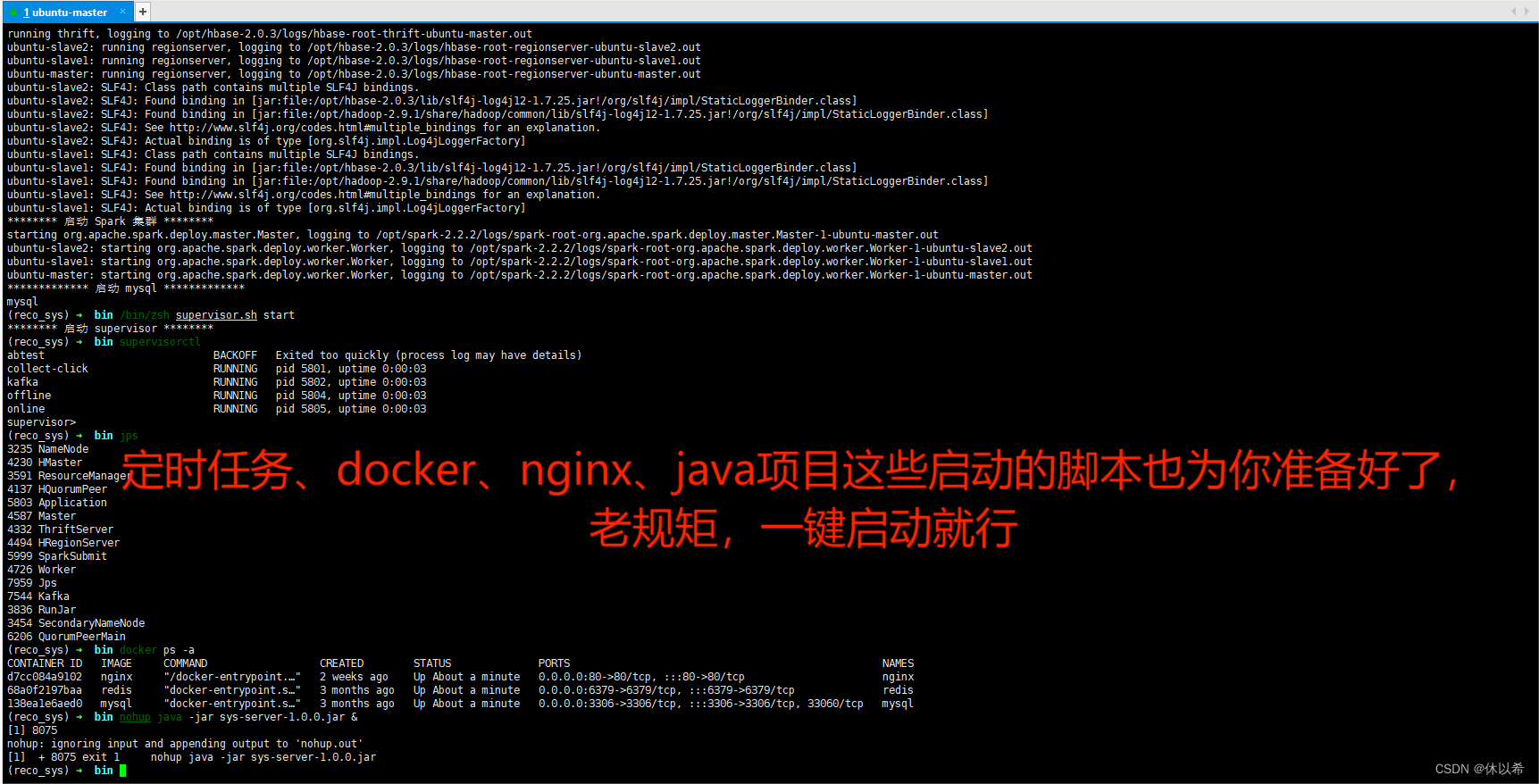
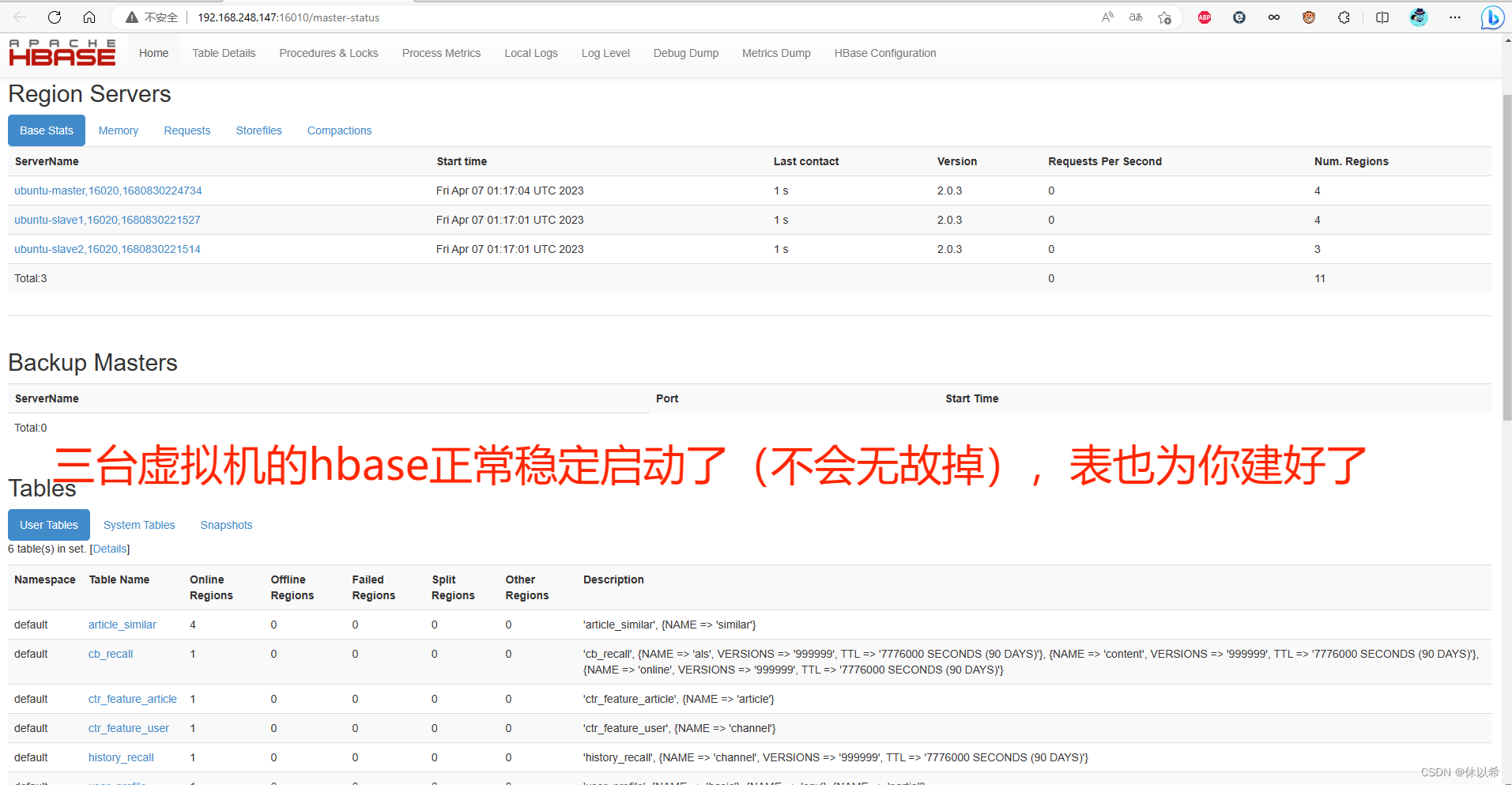
1、hadoop+spark+hbase+hive+kafka+redis+sqoop+flume大数据开发集群环境,考虑到大多数同学的学习和工作环境,一台master和两台slave共3太虚拟机(centos和ubuntu都有)
2、推荐算法跟黑马头条那个很相似,也是拿那个来优化完善的,离线、在线、协同过滤目前流行的推荐算法都会有,由于小编使用的是pytorch,所以排序算法不会使用TensorFlow
3、作为推荐系统关键部分的数据,小编已经为你准备好了新到编写本篇文章时还在采集的某某头条新闻,某SDN博客、某易音乐。。。,每个都是10W+的数据,随你咋玩(数据仅供学习交流,请勿用于商业用途)
4、大数据环境和推荐系统都跑好了,谁知道呢?那就简单做个web端展示吧(简单是说界面,功能的话你在实际工作中使用都够用了),后端SpringBoot、前端Vue+TypeScript.
实在组词能力太弱,估计你们也不想看,直接看图吧!

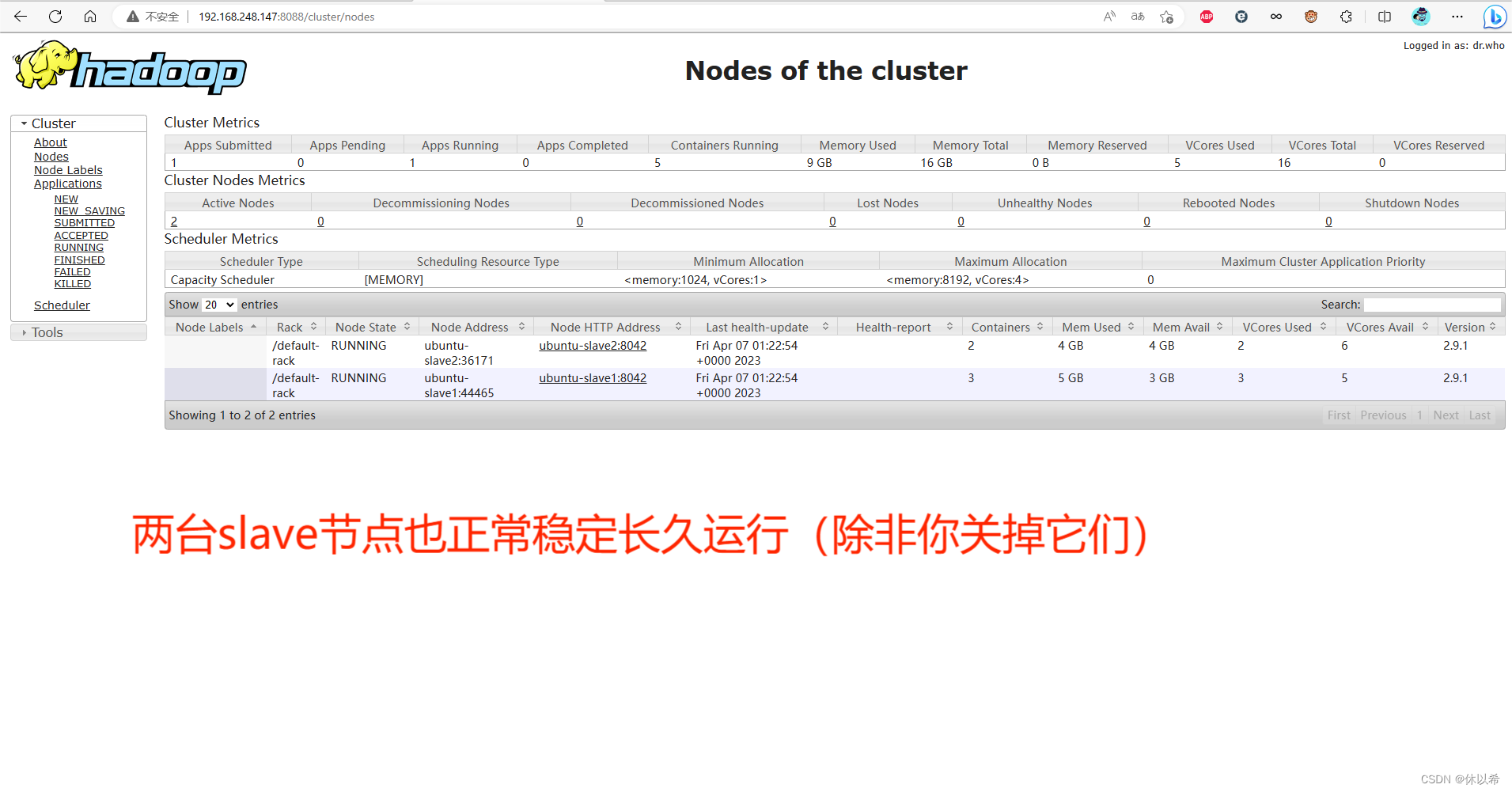
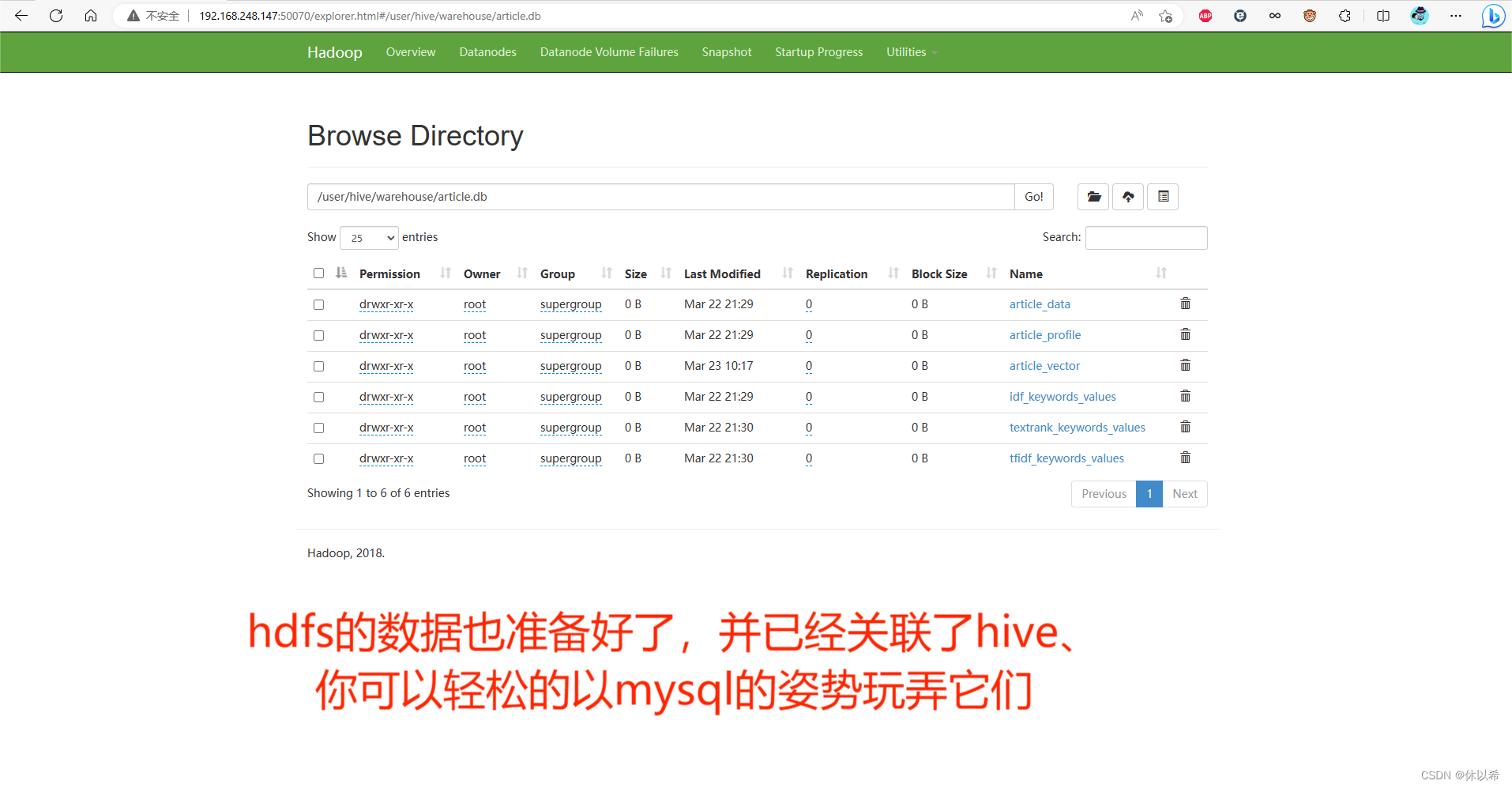
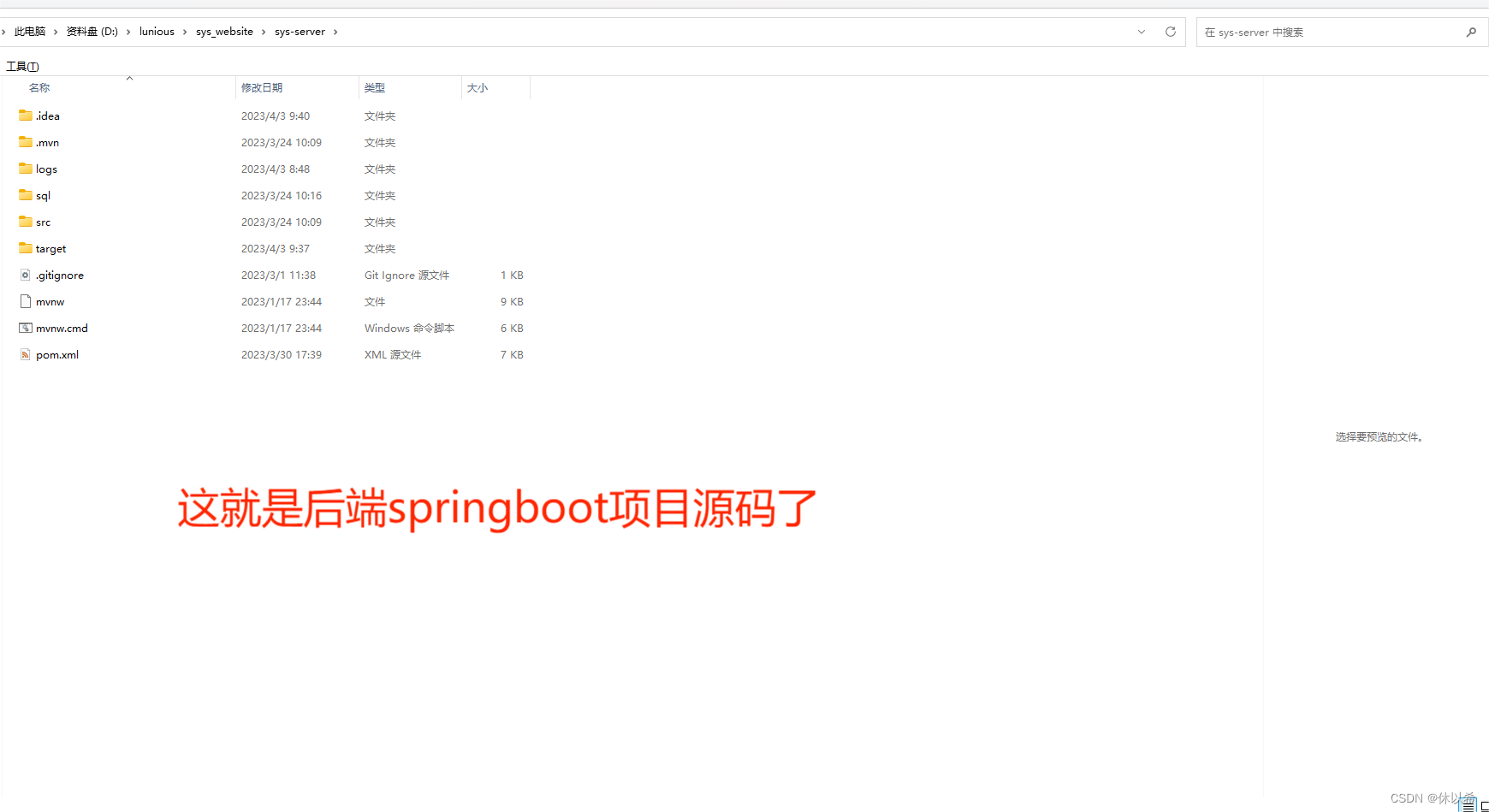
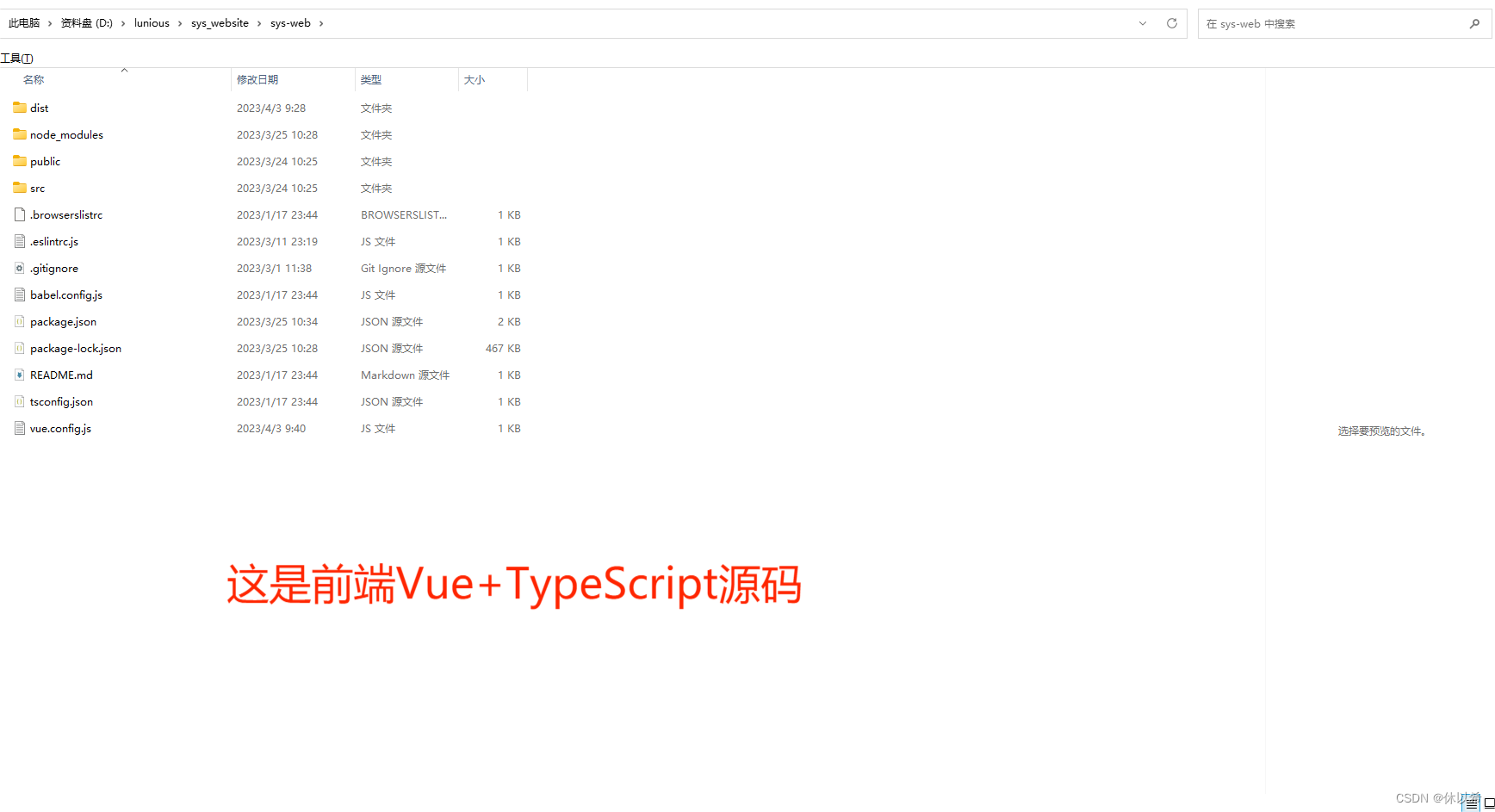
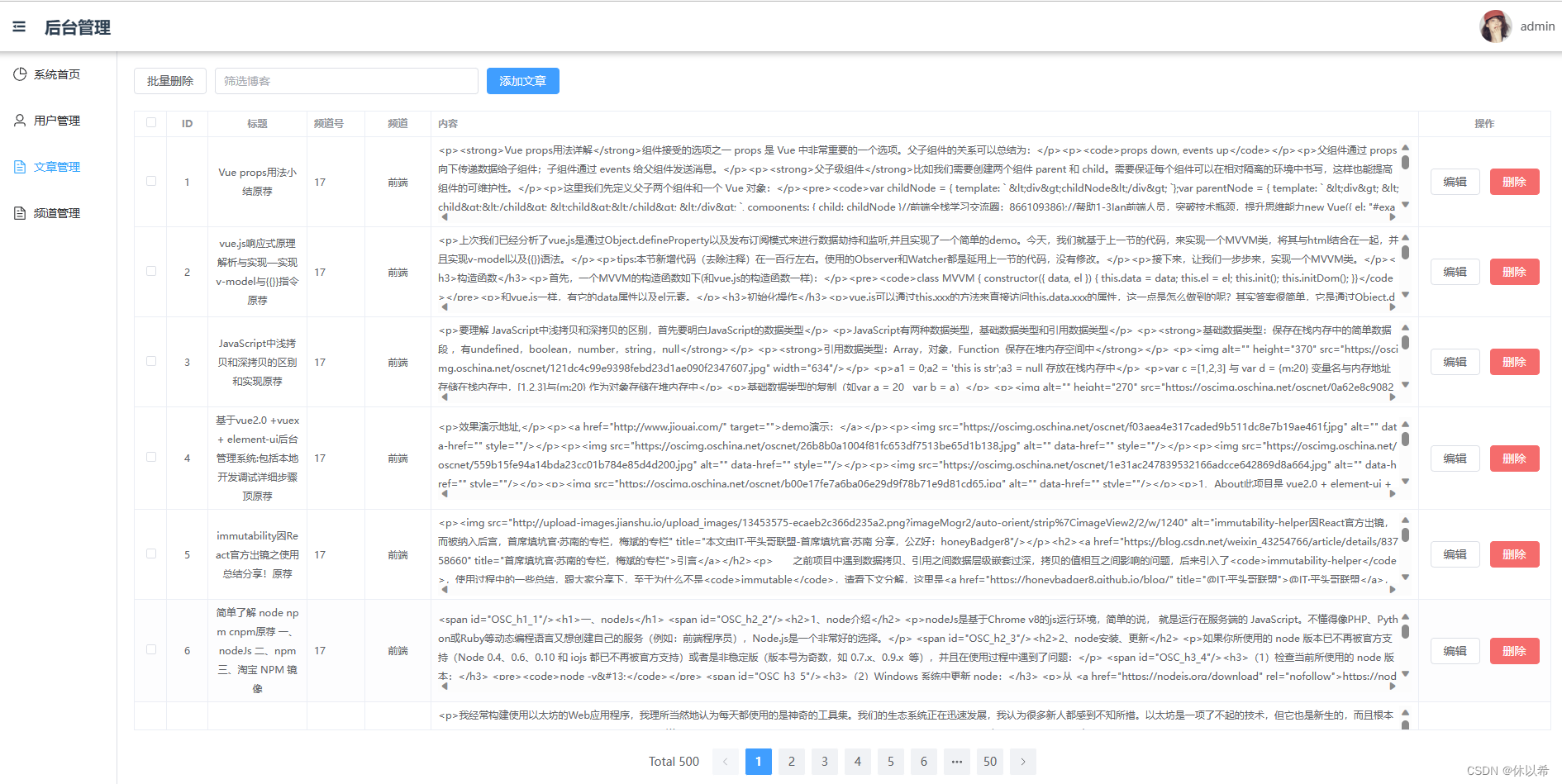
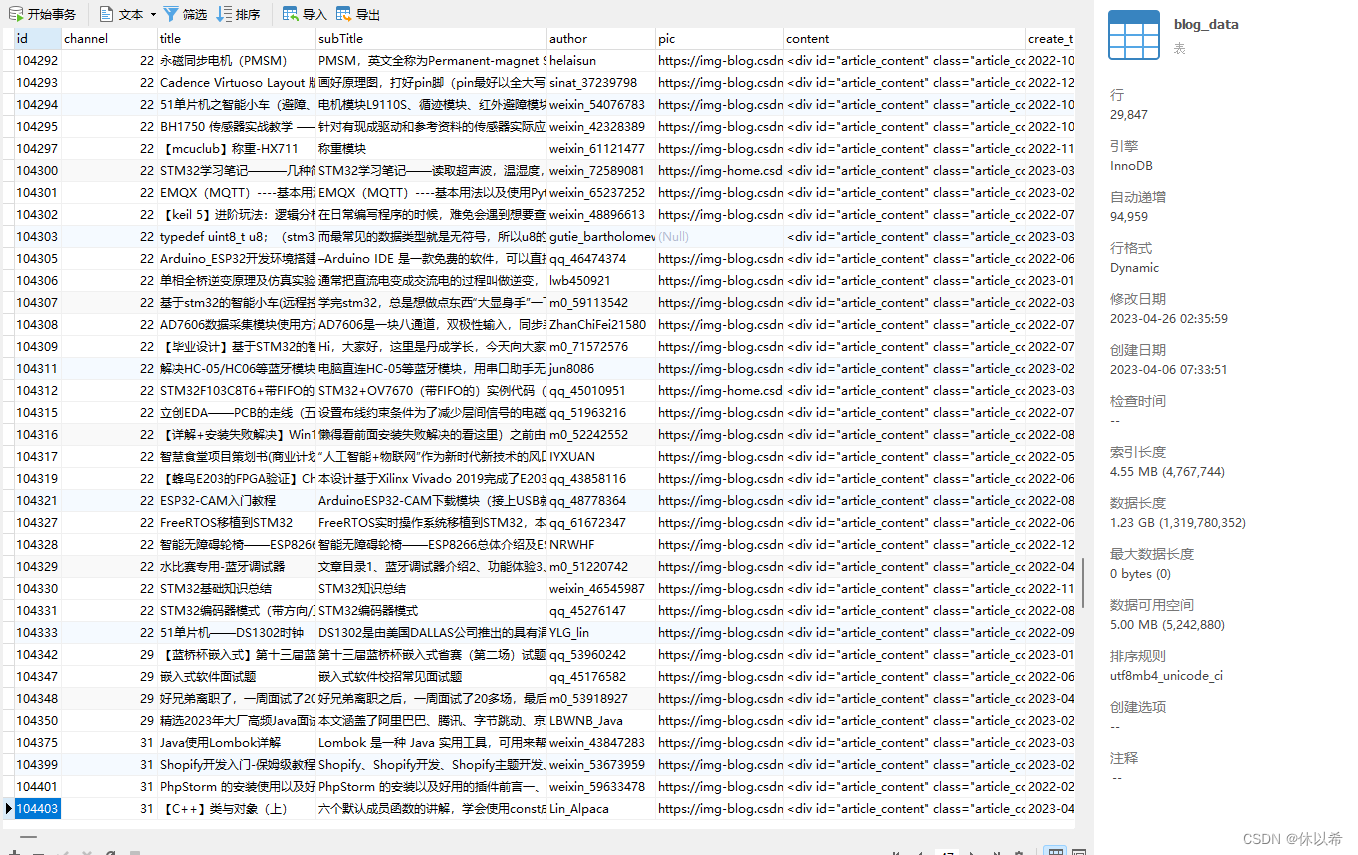
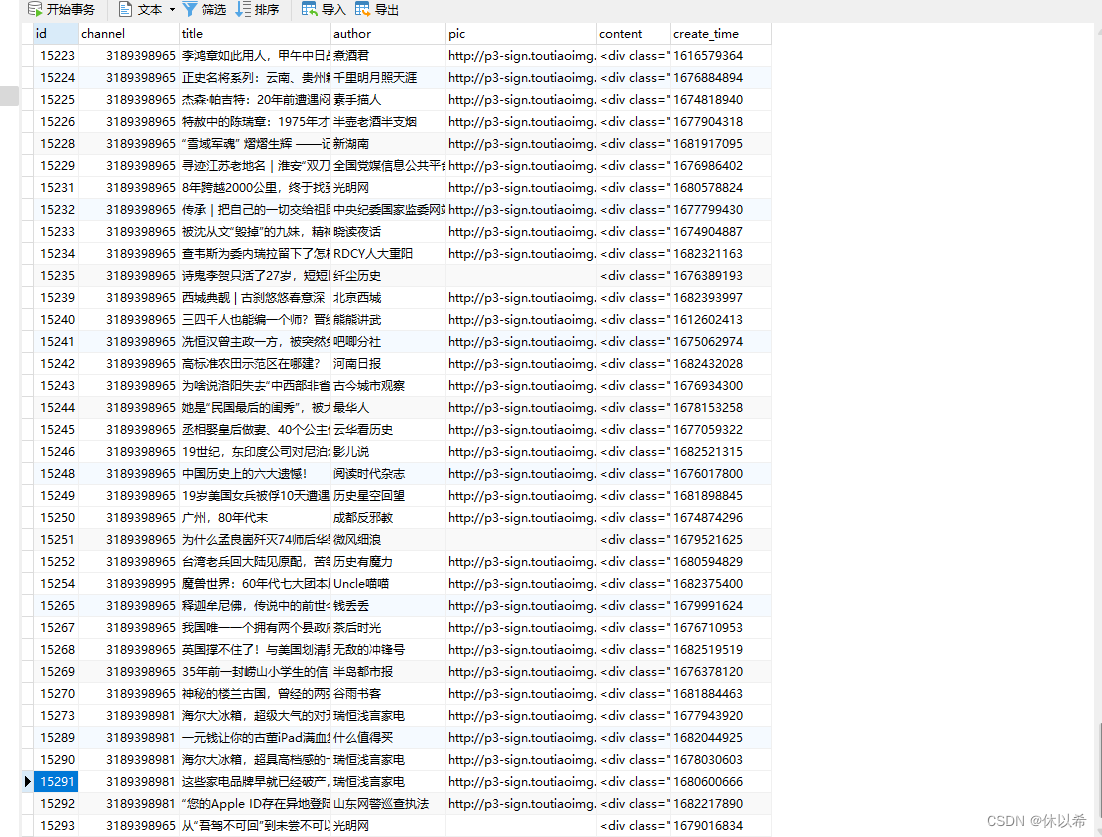
更新:新增管理端和某条某SDN数据
如果你文字和图都不想看,有疑问或者想跟我探讨一下,请私信或者加V(elancess )深入交流一下吧,祝你学习愉快!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











