







 本文深入解析了一致性Hash算法在解决分布式系统负载均衡问题上的应用,对比了普通余数Hash算法的不足,介绍了一致性Hash如何通过Hash环实现服务器增减时的数据迁移最小化。同时,探讨了大数据场景下,如何利用Hash函数高效处理海量数据,确保相同字符串落在同一服务器,以提升处理效率。
本文深入解析了一致性Hash算法在解决分布式系统负载均衡问题上的应用,对比了普通余数Hash算法的不足,介绍了一致性Hash如何通过Hash环实现服务器增减时的数据迁移最小化。同时,探讨了大数据场景下,如何利用Hash函数高效处理海量数据,确保相同字符串落在同一服务器,以提升处理效率。
1)一致性hash的总结
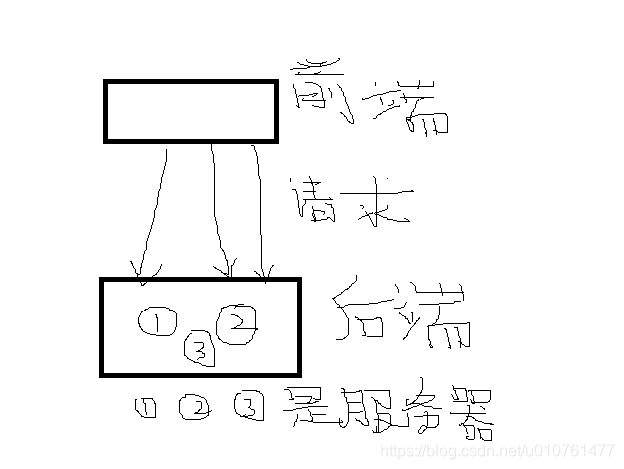
经典的服务器结构
前端有相同的hash函数然后经过mod%3把文件均匀的存储在1号、2号、3号服务器上这样可以让服务器负载均衡
但是如果服务增加或者减少的话又要重新的进行hash函数的映射比如服务器增加到100台的话原来是hash(“hello”)%3现在要变成hash(“hello”)%100这样原理存储在1号2号3号服务器的数据就要重新进行迁移这样的数据量非常的大
一致性hash就是为了解决服务器的增加和减少的问题
一、一致性hash函数的思想
在解决分布式系统中负载均衡的问题时候可以使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡的作用。
但是普通的余数hash(hash(比如用户id)%服务器机器数)算法伸缩性很差,当新增或者下线服务器机器时候,用户id与服务器的映射关系会大量失效。一致性hash则利用hash环对其进行了改进。
二、一致性Hash概述
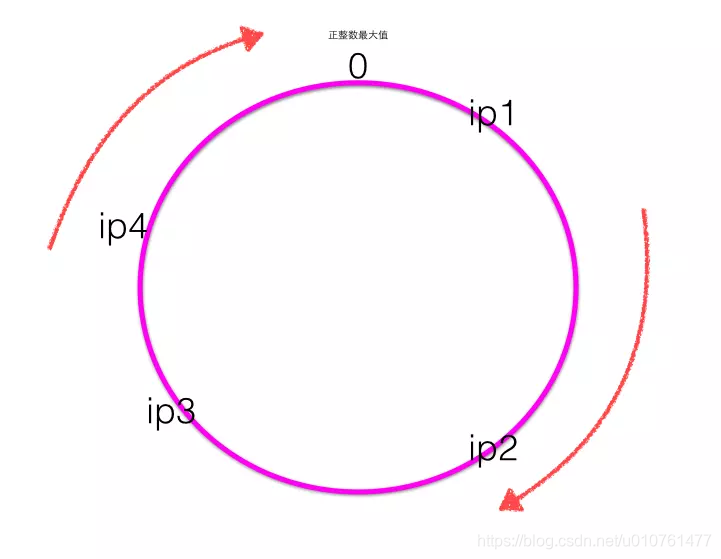
为了能直观的理解一致性hash原理,这里结合一个简单的例子来讲解,假设有4台服务器,地址为ip1,ip2,ip3,ip4。
一致性hash是首先计算四个ip地址对应的hash值
hash(ip1),hash(ip2),hash(ip3),hash(ip3),计算出来的hash值是0~最大正整数直接的一个值,这四个值在一致性hash环上呈现如下图:
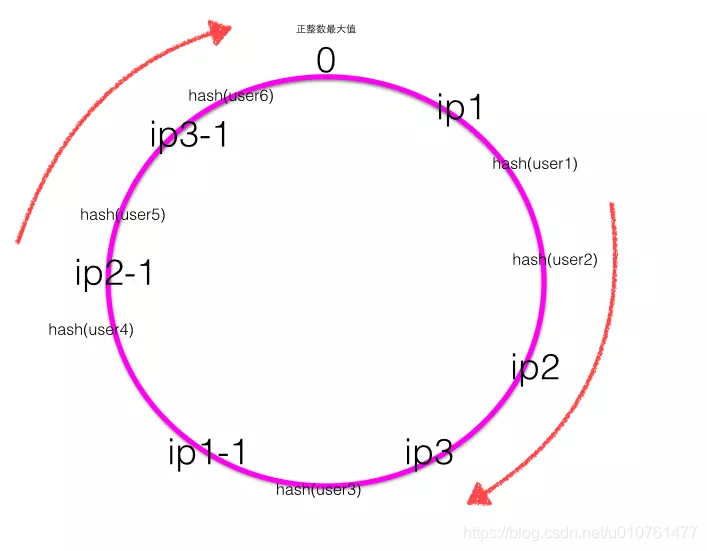
三、虚拟节点
当服务器节点比较少的时候会出现上节所说的一致性hash倾斜的问题,一个解决方法是多加机器,但是加机器是有成本的,那么就加虚拟节点,比如上面三个机器,每个机器引入1个虚拟节点后的一致性hash环的图如下:
路由表和虚拟节点技术
路由表:真实的物理机器去查有哪些虚拟节点
虚拟节点技术:从虚拟节点反查真实的物理机器
2)大数据经典问题

这道题目是经典的大数据题目假设有m种相同字符串那么如果有1000台服务器那么可以把大文件里面的数据快速的读取每一行然后经过hash函数%1000放在对应的服务器上,这样相同的字符串一定在同一套服务器上但是可能其他的字符串也可能会出现在这个服务器上所以还要在这个服务器上统计相同的字符串
总结:关于大数据的问题一般都是关于hash函数的
利用hash函数两个重要的性质
1相同输入一定有相同输出
2不同输入均匀分布

















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









