







1. 跳跃表简介
- 跳跃表(skiplist)是一个有序结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的
- 跳跃表的平均查询时间复杂度为O(logN),最坏O(N)
- 为什么选择跳跃表?
- 大部分情况下性能与平衡树媲美
- 实现比平衡树更为简单
2. 跳跃表的实现
- Redis的跳跃表有两个结构定义
- 节点结构为zskiplistNode
- 跳跃表信息zskiplist:图5-1最左边
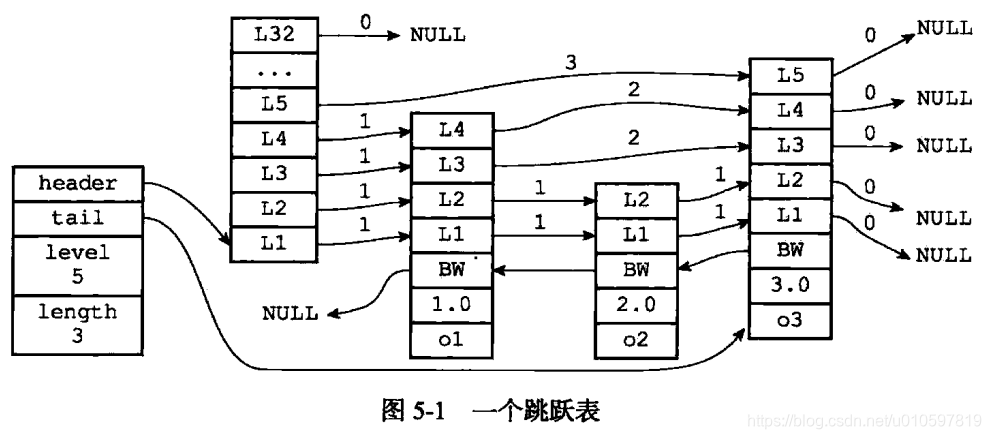
- zskiplist结构属性
- header:指向跳跃表表头节点
- tail:指向跳跃表表尾节点
- level:指跳跃表当前层数最大那个节点的层数(表头层数不计算在内)
- length:记录跳跃表的长度,跳跃表当前节点数量(表头节点不计算在内)
- zskiplistNode结构属性
- 层(Level):节点中用L1、L2、L3等表示,每层都带有两个属性:前进指针与跨度。前进指针用于访问表尾方向的其他节点;跨度记录了前进指针指向节点与当前节点距离
- 后退(backward)指针:节点中用BW表示,指向当前节点的前一个节点
- 分值(score):各个节点中的1.0、2.0、3.0是节点的分值,在跳跃表中,节点按各自保存的分支从小到大排序
- 成员对象(object):各个节点中的o1、o2、o3是节点所保存的对象
3. 跳跃表节点

3.1 层
- 跳跃表节点的level数组可以包含多个元素,一般来说层数越多访问其他节点的速度越快。
- 每次创建一个新跳跃表节点的时候,程序根据幂次定律(power law,越大的数出现的频率越小)随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是层的“高度”
3.2 前进指针
每个层都有一个指向表尾方向下一个节点的前进指针。图5-3用虚线表示出了程序从表头向表尾方向,遍历跳跃表中所有节点的路径:
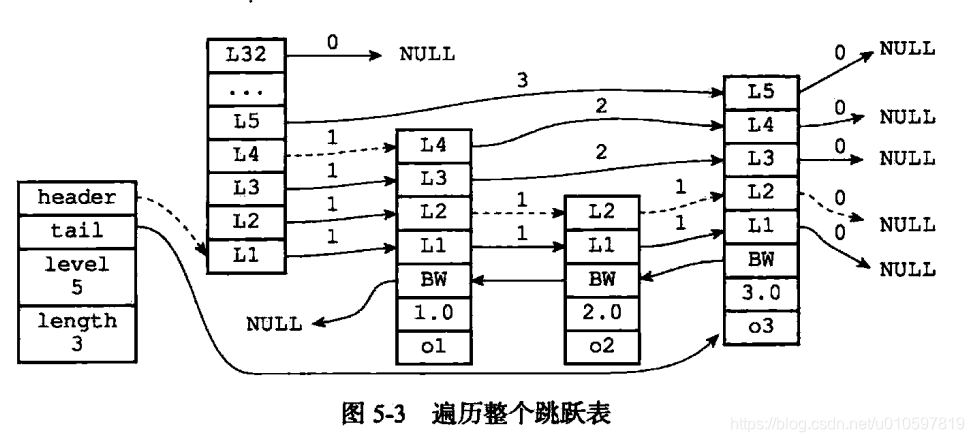
- 迭代程序首先访问跳跃表中的第一个节点(表头),然后从第四层的前进指针移动到第一个节点
- 在第二个节点时,程序沿着第二层的前进指针移动到第三个节点
- 在第三个节点时,程序沿着第二层的前进指针移动到第四个节点
- 当程序继续沿着第二层的前进指针移动时,它碰到一个null,程序知道这时已经达到了跳跃表表尾,结束本次遍历
问题:为什么从所有跨度为1的前进指针中选择层数最高的指针进行遍历?
答
- 因为层数最高跳跃的步进越大且过滤掉的数据越大,类似于二叉树,先过滤掉一半数据,层数最高如果只有两步,且刚好是中间位置,则就是二叉树的第一步二分,可以滤掉更多的数据。
- 并且可以判断,如果前进是超过了当前目标值,则说明目标值就在当前与下个跳跃节点之间,那么可以用同样的方式判断递减一层的数据,直至找到最低层,从最底层开始查找目标值,这样保证了遍历的链表元素是最少的,小于log(N)复杂度
3.3 跨度
3.4 后退指针
3.5 分值和成员
4. 跳跃表插入
原图地址:https://en.wikipedia.org/wiki/File:Skip_list_add_element-en.gif
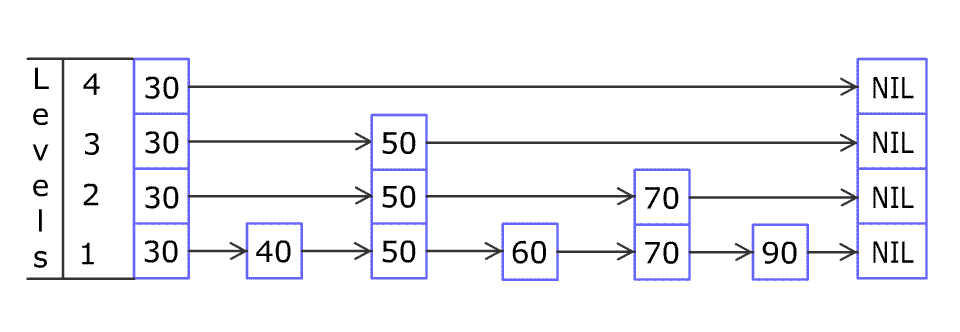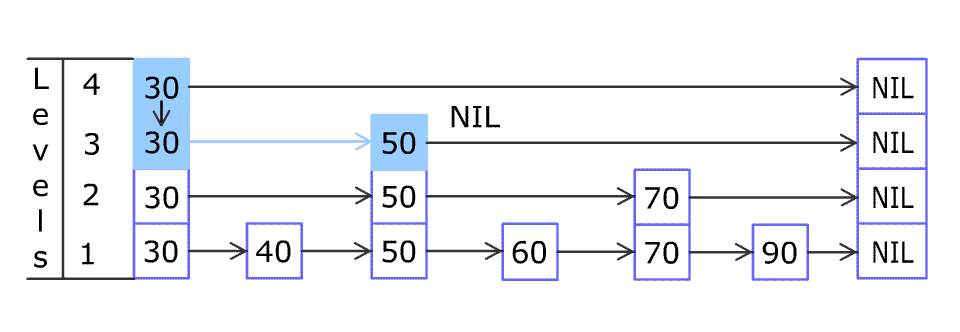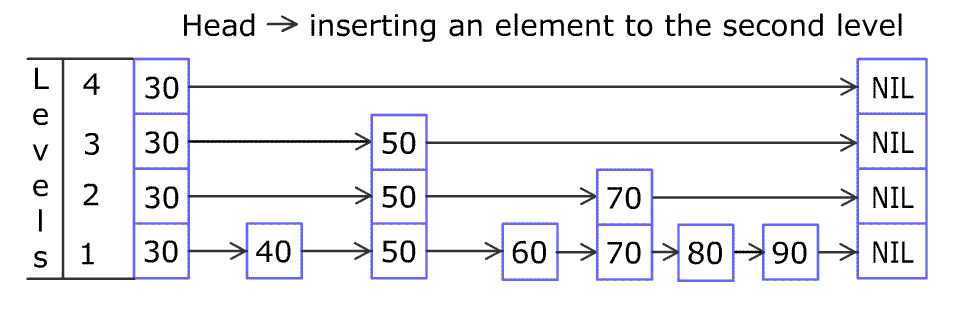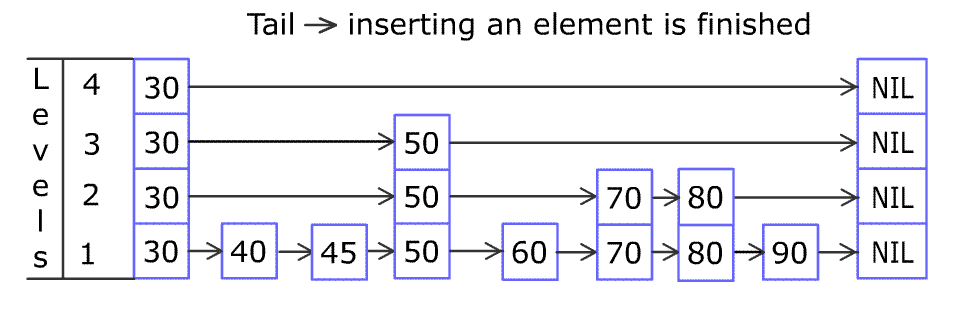

















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









