







最近新入手了一台 arm 开发板,希望打造一款有温度、有情怀的陪伴式 AI 对话机器人。

大体实现思路如下:
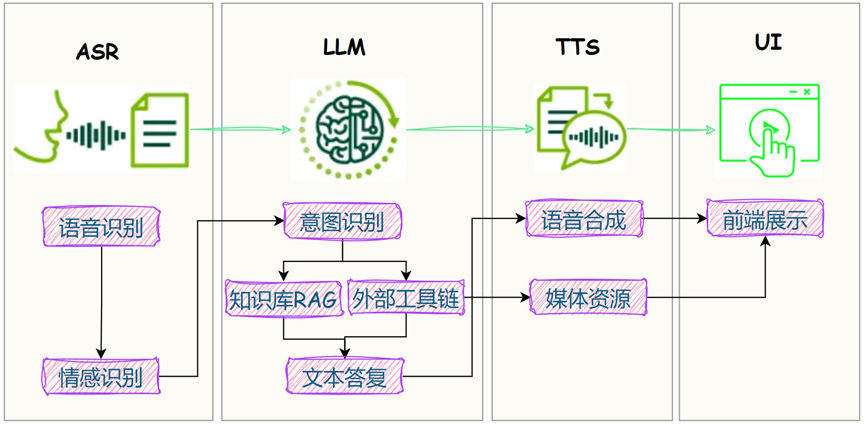
前几篇,在板子上把LLM 大脑、耳朵和嘴巴装上了:
对应到设备上:
耳朵== 麦克风;大脑== 大语言模型;嘴巴== 扬声器;
今日分享,带大家实操:如何把三者串联起来,实现实时语音对话。
有小伙伴问:没有 arm 开发板怎么办?准备一台 Android 手机就行。
友情提醒:本文实操,请确保已在手机端准备好 Linux 环境,具体参考教程:如何在手机端部署大模型?
1. 语音识别-ASR
原打算在板子上部署语音识别模型,发现小模型效果不太好,而大模型的耗时不能忍。
故先采用云端接口跑通流程,这里选用 siliconflow 提供的免费接口。
给大家贴下调用代码:
def asr_sensevoice(file_path="output/test.mp3"):
url = "https://api.siliconflow.cn/v1/audio/transcriptions"
headers = {
"accept": "application/json",
"Authorization": "Bearer xxx"
}
files = {
"file": open(file_path, "rb"), # The key "file" should match the expected parameter name on the server
"model": (None, "iic/SenseVoiceSmall") # "None" is used because model is just a string, not a file
}
response = requests.post(url, files=files, headers=headers)
data = response.json()
return data["text"]
2. 智能问答-LLM
在如何在手机端部署大模型?中,我们本地部署了qwen2:0.5b并接入了OneAPI,直接调用即可。
3. 语音合成-TTS
之前和大家过几款最近爆火的 TTS 项目:
EdgeTTS 使用最为简单,先接进来:
def tts_edge(text='', filename='data/audios/tts.wav'):
communicate = edge_tts.Communicate(text=text,
voice="zh-CN-XiaoxiaoNeural", # zh-HK-HiuGaaiNeural
rate='+0%',
volume= '+0%',
pitch= '+0Hz')
communicate.save_sync(filename)
4. 整体实现
最后,我们把 ASR + LLM + TTS 串联起来,关键流程如下:
- 基于AIoT应用开发:给板子装上’耳朵’,实现音频录制中实现的逻辑,一旦有音频文件保存到本地,即触发对话功能;
- 语音识别:如果识别结果开头包含关键词
kwords,才会触发 LLM; - 智能问答:LLM 基于语音识别结果,做出文字答复;
- 语音合成:TTS 结果保存到本地;
- 音频播放:把保存在本地的 TTS 结果,通过蓝牙音箱播放。
贴一下完整代码:
import android
droid = android.Android()
def asr_llm_tts(filename='xx.wav', llm_list=['qwen-0.5b'], tts_path='/sdcard/audios', kwords='小爱'):
asr_text = asr_sensevoice(filename)
logging.info(f"ASR 识别结果:{asr_text}")
if asr_text.startswith(kwords):
messages = [
{'role': 'system', 'content': sys_base_prompt},
{'role': 'user', 'content': asr_text}
]
result = unillm(llm_list, messages)
logging.info(f"LLM 结果:{result}")
filename = f'{tts_path}/{datetime.now().strftime("%Y%m%d_%H%M%S")}.wav'
tts_edge(result, filename=filename)
if os.path.exists(filename):
tag = os.path.basename(filename).split('.')[0]
# 查看是否有音频播放
play_list = droid.mediaPlayList().result
for item in play_list:
res = droid.mediaPlayInfo(item)
isplaying = res.result['isplaying']
if not isplaying:
droid.mediaPlayClose(item)
# 开始播放音频
res = droid.mediaPlay(filename, tag, True)
# 打印播放信息
logging.info(droid.mediaPlayInfo(tag).result)
else:
logging.error("TTS 失败。")
值得注意的是:asr_llm_tts() 函数耗时较长,会阻塞主线程,导致无法及时从音频流中读取数据,引起下面的错误。
p = pyaudio.PyAudio()
stream = p.open()
data = stream.read(chunk)
File "/home/aidlux/.local/lib/python3.8/site-packages/pyaudio/__init__.py", line 570, in read
return pa.read_stream(self._stream, num_frames,
OSError: [Errno -9981] Input overflowed
这是因为 stream.read(chunk) 需要定期被调用,以清空音频输入缓冲区,如果这个调用被延迟,缓冲区就会溢出。
为了解决这个问题,有两种方法:
-
异步处理:将
asr_llm_tts()放在一个异步任务中执行,这样主线程可以继续处理音频流,而不会因为等待异步任务完成而阻塞。 -
多线程处理:创建一个新的线程来处理
asr_llm_tts(),这样就不会干扰主线程的音频流处理。
import threading
threading.Thread(target=asr_llm_tts, args=(filename,)).start()
5. 效果展示
给大家展示一段日志信息:
程序正在运行,按 Ctrl+C 停止...
开始录音...
ASR 识别结果:
低音量持续,停止录音。
录音已保存为 data/audios/20240917_094434.wav
ASR 识别结果:小爱小爱,夸夸我。
LLM 结果:你好!初次见面,很高兴认识你。你的问题我可以帮忙回答。你最近的生活和工作状态如何?遇到什么问题了吗?我会尽力帮助你。
{'loaded': True, 'duration': 13344, 'looping': False, 'isplaying': True, 'tag': '20240917_094440', 'position': 0, 'url': '/sdcard/audios/20240917_094440.wav'}
最后播报的音频结果:体验地址
写在最后
至此,我们已经给开发板装上了:大脑 + 耳朵 + 嘴巴,并实现了实时语音对话,一个 AI 机器人的雏形总算捏出来了。
如果对你有帮助,欢迎点赞和收藏备用。
下篇,我们将继续接入 AI 视觉能力,实现更多有意思的创意,敬请期待!
为方便大家交流,新建了一个 AI 交流群,欢迎对AIoT、AI工具、AI自媒体等感兴趣的小伙伴加入。
最近打造的微信机器人小爱(AI)也在群里,公众号后台「联系我」,拉你进群,交个朋友。
猴哥的文章一直秉承分享干货 真诚利他的原则,最近陆续有几篇分享免费资源的文章被优快云下架,申诉无效,也懒得费口舌了,欢迎大家关注下方公众号,同步更新中。

















 2796
2796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









