









一. 数据源准备
建表:
CREATE TABLE `mysql_cdc` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
写存储过程批量插入数据:
DELIMITER //
CREATE PROCEDURE p5()
BEGIN
declare l_n1 int default 1;
while l_n1 <= 30000000 DO
insert into mysql_cdc (id,name) values (l_n1,concat('test',l_n1));
set l_n1 = l_n1 + 1;
end while;
END;
//
DELIMITER ;
二. Flink CDC 将MySQL源数据写入到Hudi并同步到Hive
启动Yarn Session
$FLINK_HOME/bin/yarn-session.sh -jm 16384 -tm 16384 -d 2>&1 &
/home/flink-1.14.5/bin/sql-client.sh embedded -s yarn-session
Flink SQL 代码:
-- 设置checkpoint的时间间隔
set execution.checkpointing.interval=60sec;
-- 设置任务结束后不清空checkpoint文件,便于后续恢复
set execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION;
-- 同时只能有一个checkpoint进程
set execution.checkpointing.max-concurrent-checkpoints=1;
CREATE TABLE flink_mysql_cdc1 (
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'hp8',
'port' = '3306',
'username' = 'root',
'password' = 'abc123',
'database-name' = 'test',
'table-name' = 'mysql_cdc',
'server-id' = '5409-5415',
'scan.incremental.snapshot.enabled'='true'
);
CREATE TABLE flink_hudi_mysql_cdc1(
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
'connector' = 'hudi',
'path' = 'hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc1',
'table.type' = 'MERGE_ON_READ',
'changelog.enabled' = 'true',
'hoodie.datasource.write.recordkey.field' = 'id',
'write.precombine.field' = 'name',
'compaction.async.enabled' = 'true',
'hive_sync.enable' = 'true',
'hive_sync.table' = 'flink_hudi_mysql_cdc1',
'hive_sync.db' = 'test',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://hp5:9083',
'hive_sync.conf.dir'='/home/apache-hive-3.1.2-bin/conf'
);
set table.exec.resource.default-parallelism=4;
insert into flink_hudi_mysql_cdc1 select * from flink_mysql_cdc1;
三. 通过Spark SQL处理Hudi数据
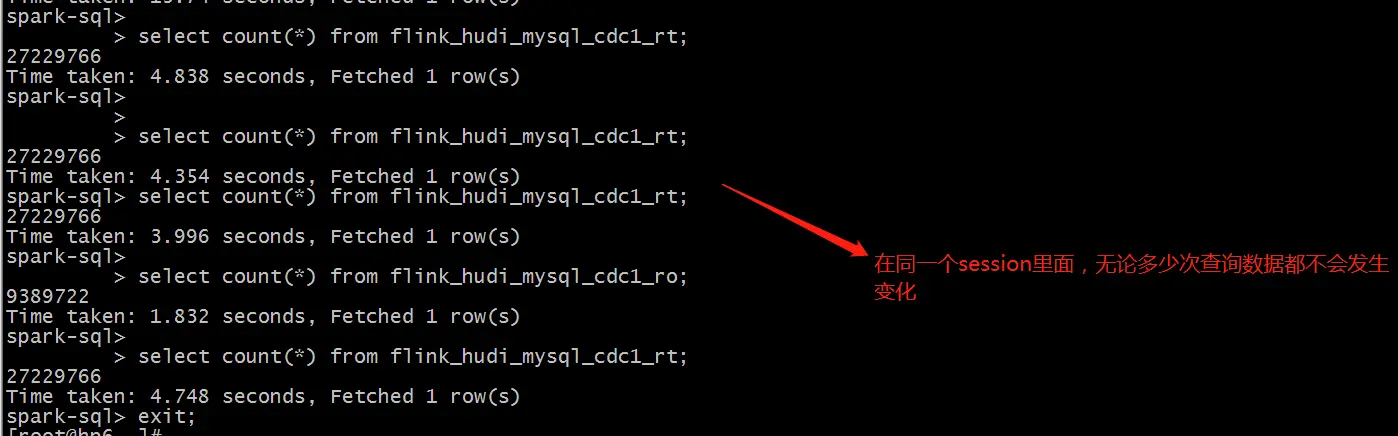
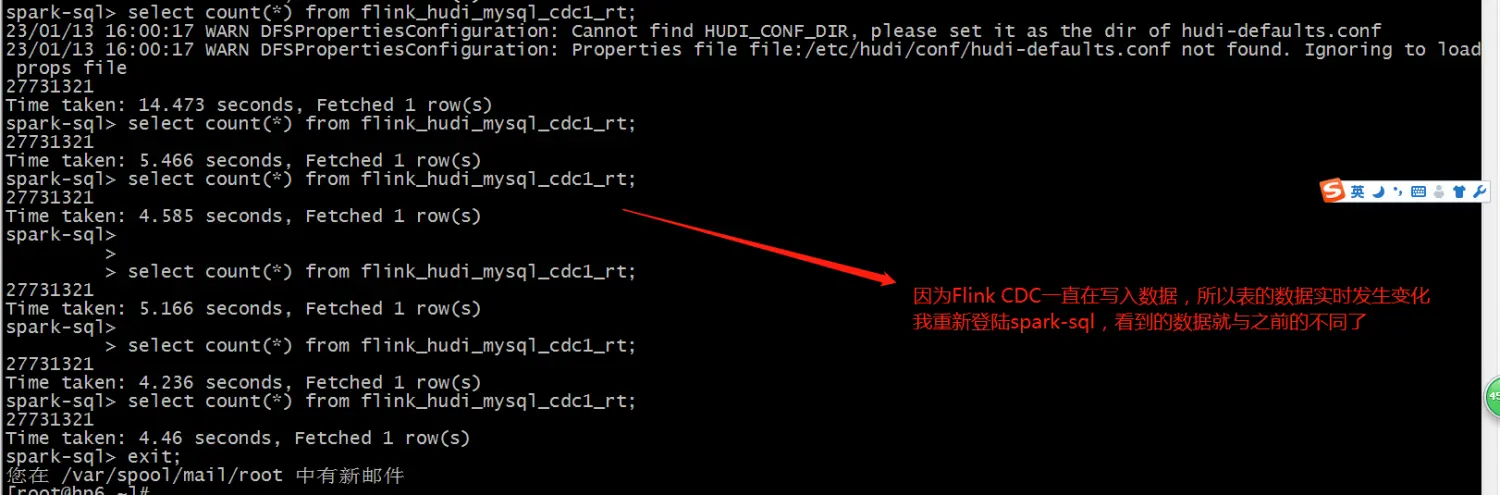
因为数据已经同步到了Hive,Spark SQL默认可以读取Hive表的数据,所以可以直接进行操作。
spark-sql
或者
# Spark 3.3
spark-sql --packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









