










文章目录
一. 支持向量机概述
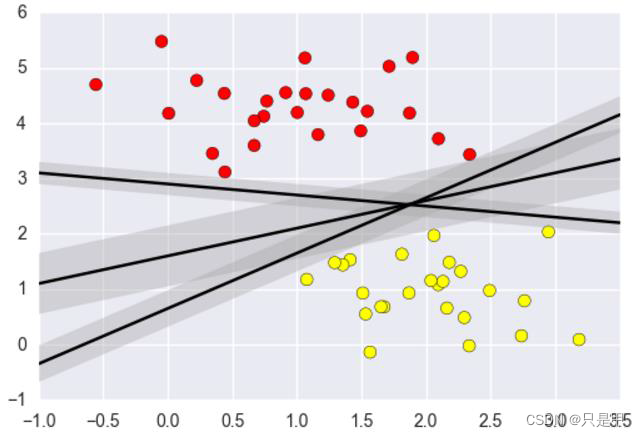
1.1 要解决的问题
- 什么样的决策边界才是最好的呢?
- 特征数据本身如果就很难分,怎么办呢?
- 计算复杂度怎么样?能实际应用吗?
目标:
基于上述问题对SVM进行推导
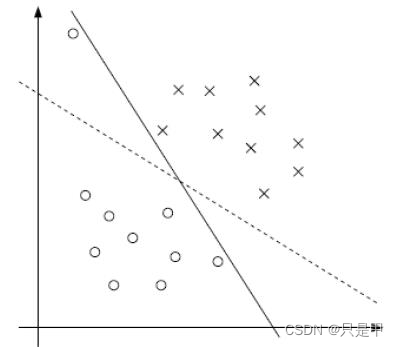
1.2 决策边界
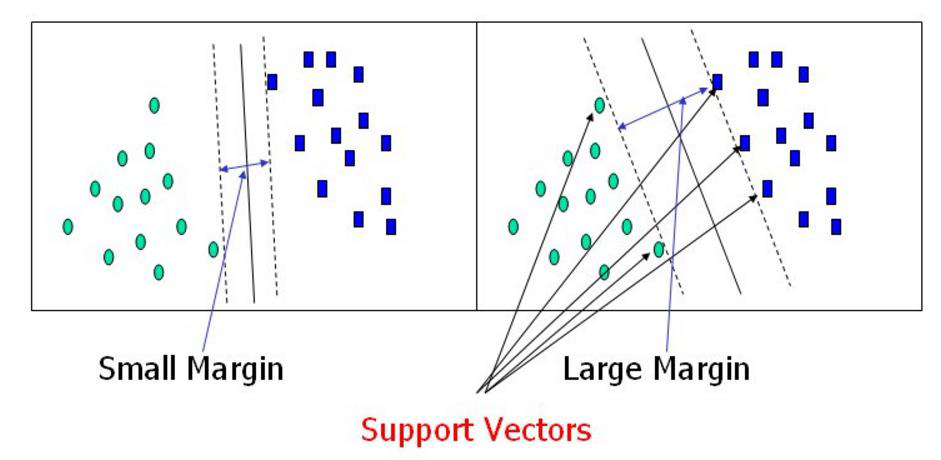
选出来离雷区最远的(雷区就是边界上的点,要Large Margin)
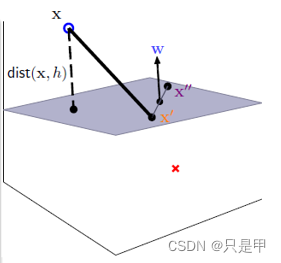
1.3 距离的计算

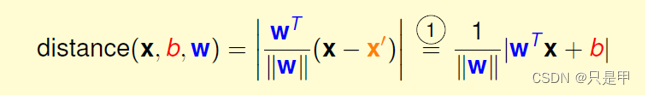
1.4 数据标签定义
数据集:(X1,Y1)(X2,Y2)…(Xn,Yn)
Y为样本的类别:当X为正例时候Y = +1 当X为负例时候Y = -1
决策方程:

1.5 优化的目标及目标函数
1.5.1 优化目标
通俗解释:
找到一个条线(w和b),使得离该线最近的点(雷区)
能够最远
将点到直线的距离化简得:
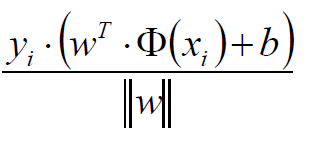
由于
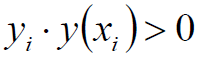
所以将绝对值展开原始依旧成立
1.5.2 目标函数
放缩变换:
对于决策方程(w,b)可以通过放缩使得其结果值|Y|>= 1
(之前我们认为恒大于0,现在严格了些)
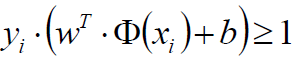
优化目标:
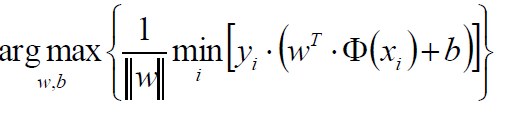
由于
只需要考虑
目标函数搞定!
当前目标:
约束条件:
常规套路:
将求解极大值问题转换成极小值问题
因为通过求导(梯度下降)可以求出极小值,所以很多数学问题最终都是用来求最小值。
至于为什么要加一个1/2,因为使用对数,刚好和平方那个消除了。
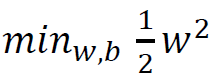
如何求解:
应用拉格朗日乘子法求解
1.6 拉格朗日乘子法
这里我们就不讲解拉格朗日乘子法,直接使用。
带约束的优化问题:
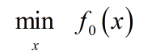
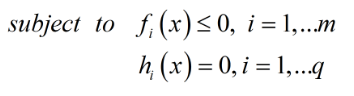
原式转换:
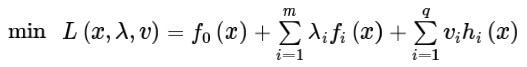
我们的式子:
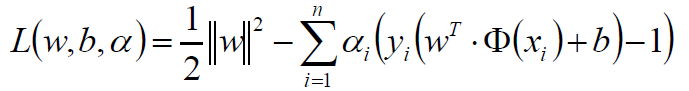
约束条件:
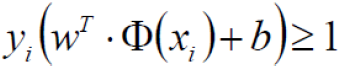
1.7 SVM求解
分别对w和b求偏导,分别得到两个条件(由于对偶性质)
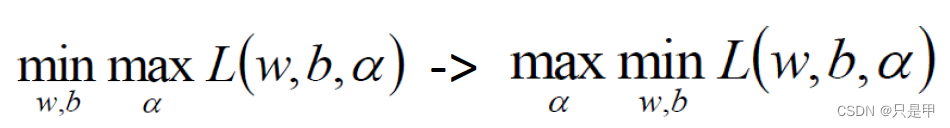
对w/b求偏导:
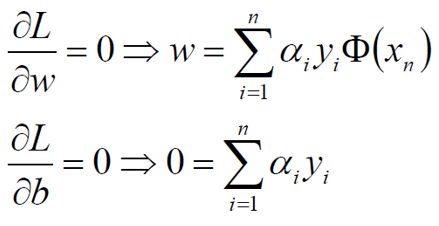
带入原式:
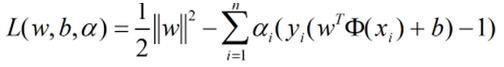

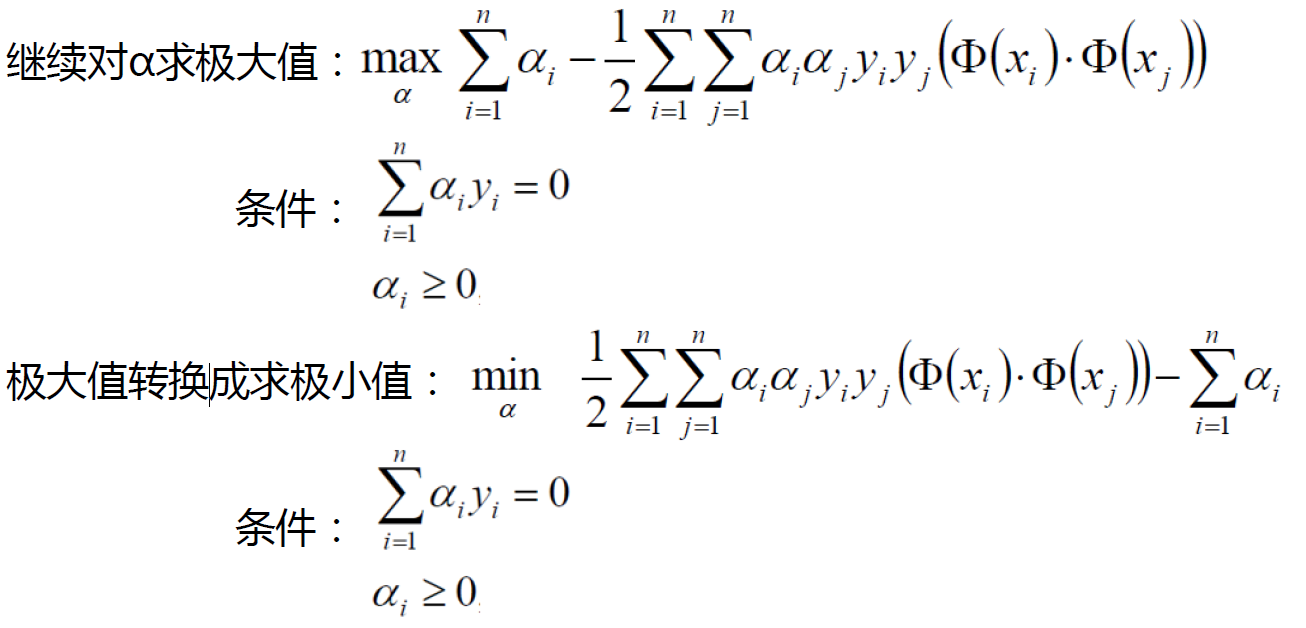
1.8 SVM求解实例
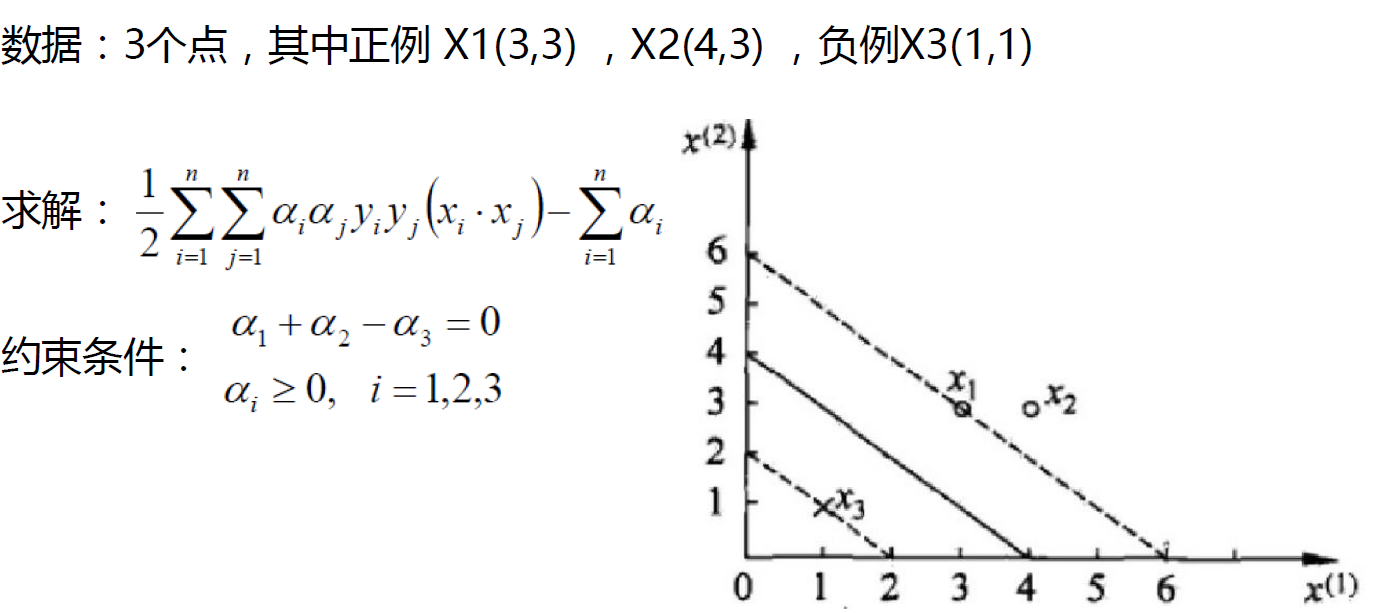
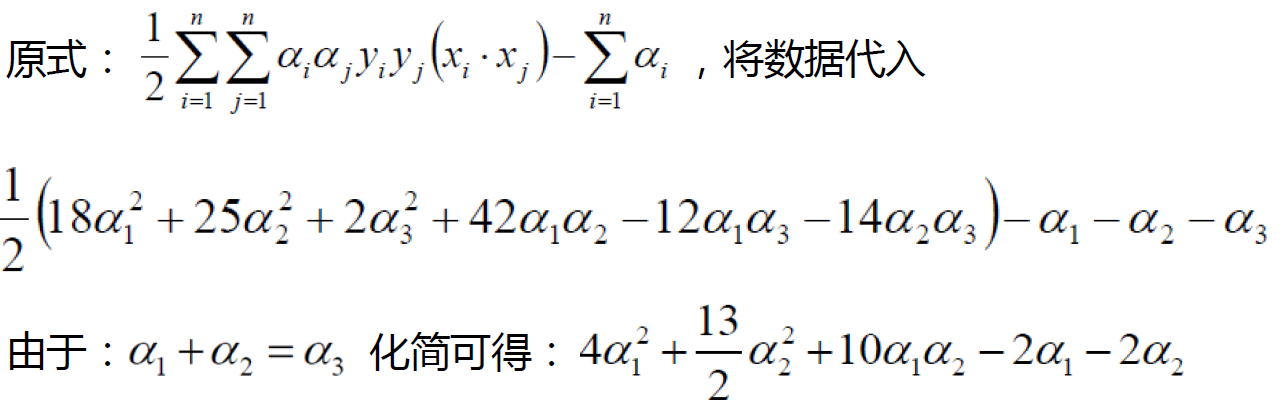

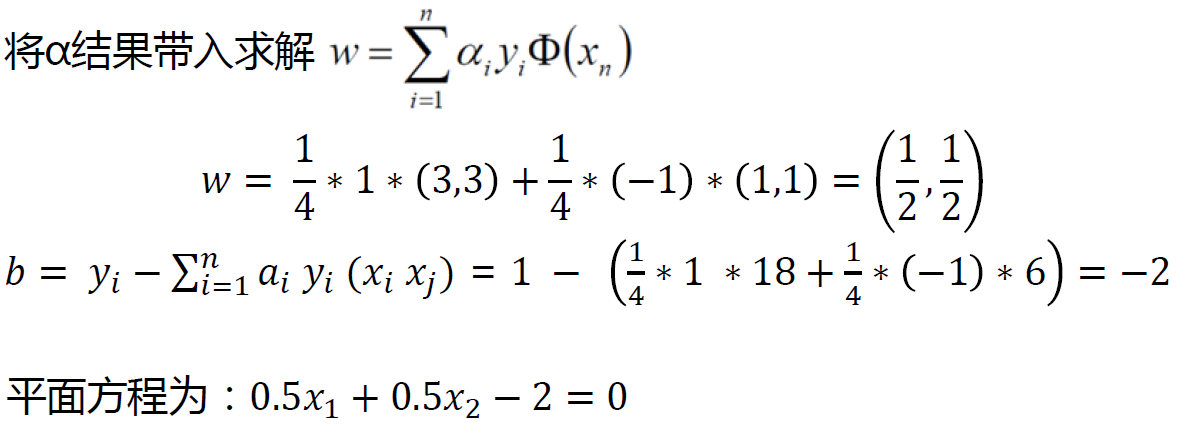
支持向量:真正发挥作用的数据点,ɑ值不为0的点支持向量机
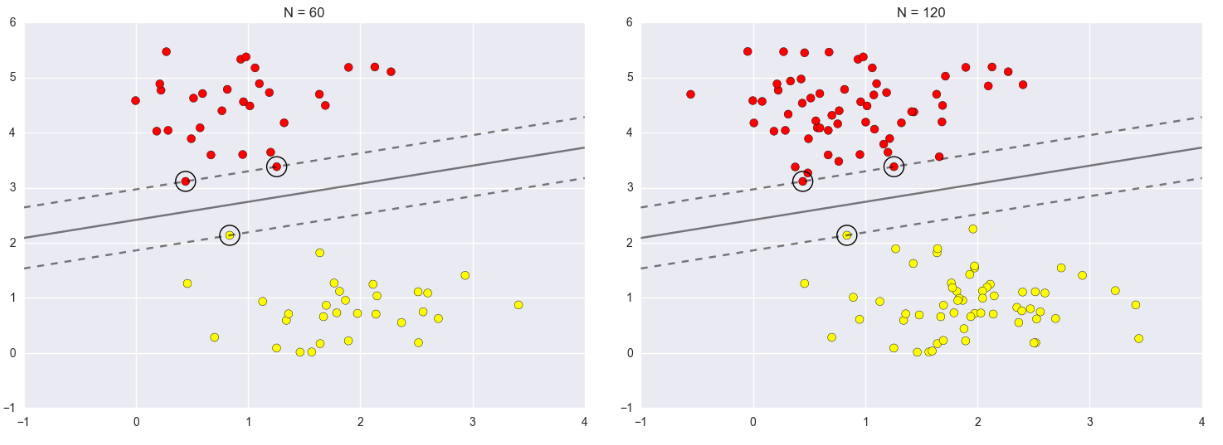
1.9 soft-margin
软间隔:
有时候数据中有一些噪音点,如果考虑它们咱们的线就不太好了
之前的方法要求要把两类点完全分得开,这个要求有点过于严格了,我们来放松一点!
为了解决该问题,引入松弛因子
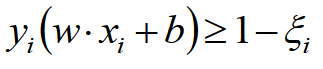
新的目标函数:
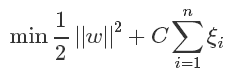
当C趋近于很大时:意味着分类严格不能有错误
当C趋近于很小时:意味着可以有更大的错误容忍
C是我们需要指定的一个参数!
拉格朗日乘子法:

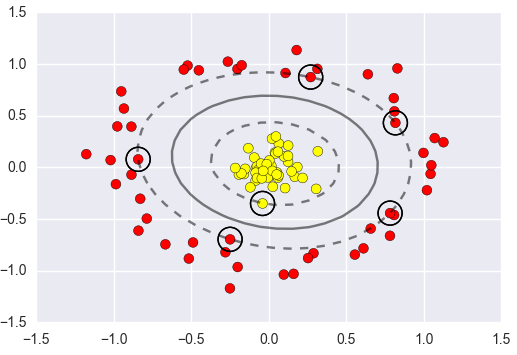
1.10 低维不可分问题
核变换:既然低维的时候不可分,那我给它映射到高维呢?
目标:找到一种变换的方法,也就是∅(x)
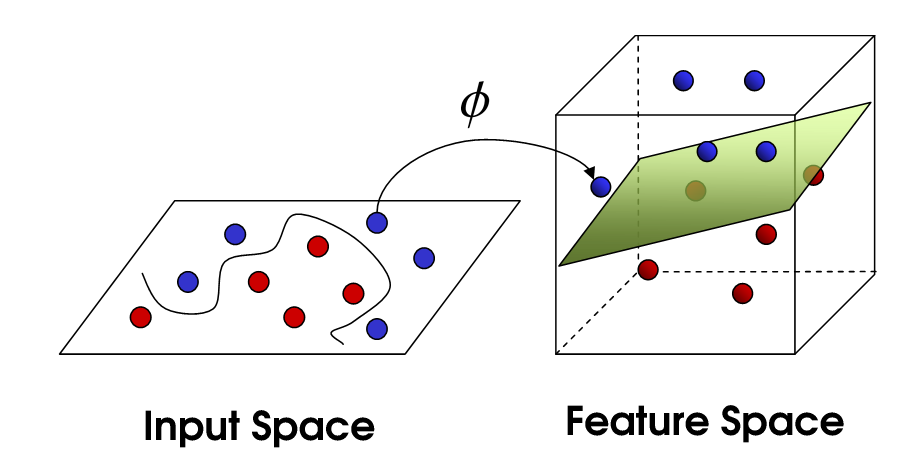
通过升级维度将我们的特征区分开,那么真正的情况我们是否升级了维度呢?
我们都知道,升级了维度,计算量呈指数型上升,别人的模型可能半个小时就跑出来,你的模型需要数天才可以跑出来,这样的话肯定是不行的。
核函数是在一个低维空间去完成高维样本内积的计算,计算量大大减少。

高斯核函数:
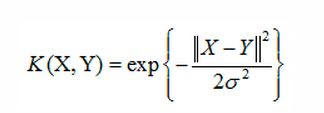
线性核函数:
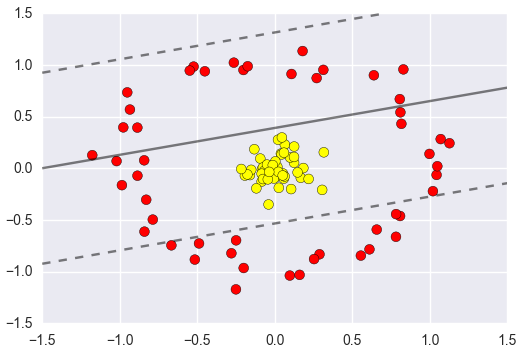
高斯和函数:
不一定是圆形,也可以是其它
参考:
- https://study.163.com/course/introduction.htm?courseId=1003590004#/courseDetail?tab=1


















 2912
2912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









