







 本文详细介绍了如何使用deeplabv3+进行图像语义分割任务的全过程,包括环境搭建、数据集处理及训练配置等关键步骤。
本文详细介绍了如何使用deeplabv3+进行图像语义分割任务的全过程,包括环境搭建、数据集处理及训练配置等关键步骤。
环境
我使用的deeplab的开源代码地址:(框架是pytorch)
https://github.com/jfzhang95/pytorch-deeplab-xception.git环境的安装不说,conda新建一个环境,按照需求下载.....blabla;
- ubuntu18.04
- pytorch1.2
- pycharm
- python3.7
- GTX2080ti
准备数据集
我没有很多分割的数据集,也懒得去标注。所以我就去biying 搜索了以下,找到了知乎的一篇文章,有一些开源的数据集:https://zhuanlan.zhihu.com/p/195699093
磁瓦缺陷数据集
中国科学院自动所一个课题组收集的数据集,是“Saliency of magnetic tile surface defects”这篇论文的数据集。收集了6种常见磁瓦缺陷的图像,并做了语义分割的标注。
这个就是为下载的数据集
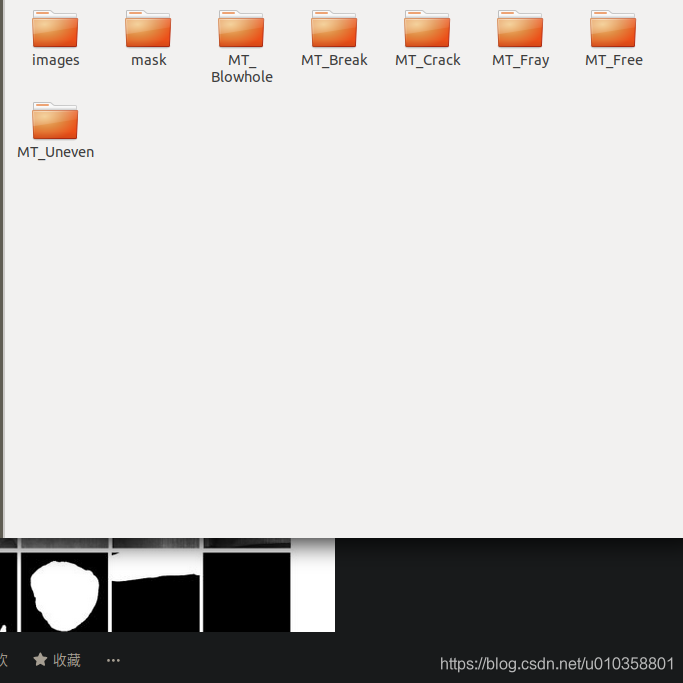
前面的 images 和 mask 是为处理过后的:
大概说一下这个数据集,处理这个数据集花了为2天时间,因为在工作,所以断断续续的;
首先这个数据集分了6个类; MT_Blowhole MT_Break MT_Crack MT_Fray MT_Uneven MT_Free
这几个文件夹结构不统一
如:
-MT_Break
--img
---1.jpg
---1.png
-MT_Fray
--1.jpg
--1.png
多了一个文件夹,所以各位 先统一以下,我是按照 第二种方式来的2 处理完之后,就开始分析数据集
你会发现MT_Free 的数据比其他五个大很多,就是样本不均衡,
但是其实你仔细看看,就会发现MT_Free 的数据的PNG 都是黑的 ,说明MT_Free 是作为背景处理的,在工业上有些是OK品却被当作了NG品处理--吴识别的图片集,你们可以这么理解
3 初次尝试 我先排除了MT_Free 这个数据集,先训练其他五个数据集
因此,我先将其他五个文件夹中的JPG 和 PNG 分离出来 放到images 和 mask 里面去
分离之后的结构大概是
-images
--MT_Fray
---1.jpg
---2.jpg
....
n.jpg
--MT_Crack
---1.jpg
---2.jpg
....
n.jpg
...
--MT_Break
---1.jpg
---2.jpg
....
n.jpg
-mask
--MT_Fray
---1.png
---2.png
....
n.png
--MT_Crack
---1.png
---2.png
....
n.png
...
--MT_Break
---1.png
---2.png
....
n.png
4 分完之后 再将抽取0.1 * 每个种类的总数 作为验证集 ,然后制作成如下方式
-ciwa_soft
--ImagesSets
train.txt # 存放对应.jpg 的位置,最好是绝对路径
val.txt
--JPEGImages
---1.jpg
---2.jpg
....
n.jpg
--SegmentationClass
---1.png
---2.png
....
n.png
修改配置
要训练自己数据集,要修改以下几个配置,包括将自己数据集添加进去:
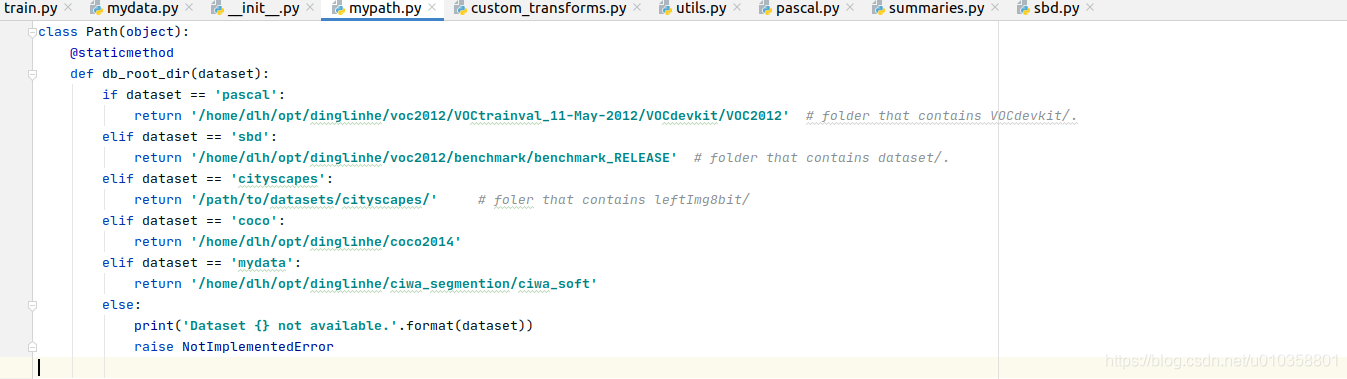
- 在mypath.py文件中,定义自己的数据集,把刚才的路径添加进去,我的数据集名字叫做mydata,如下:
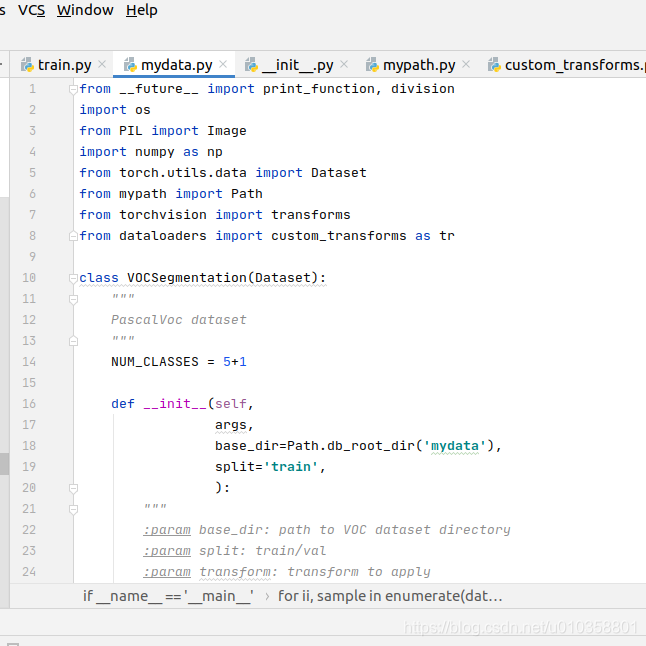
- 然后在dataloaders/datasets路径下创建自己的数据集文件,这里创建为mydata.py,因为我们是按照VOC数据集格式,所以直接将pascal.py内容复制过来修改,这里将类别数和数据集改成自己的数据集,类别记得加上背景类,我这里一共是5+1类:
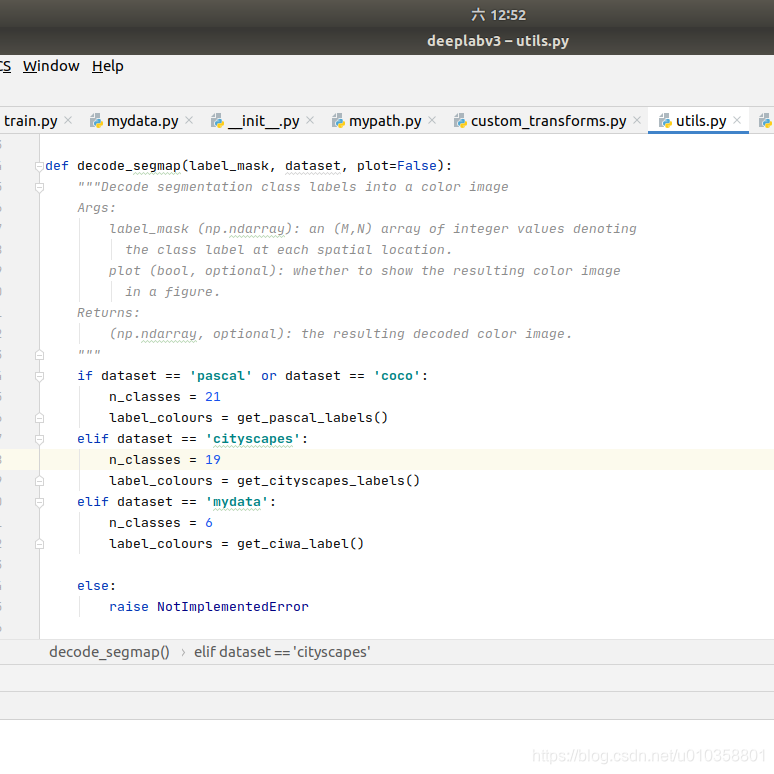
- 修改dataloaders/utils.py,在文件中创建一个get_ciwa_label()函数,根据自己的类别数,我这里只有5类,一类是背景,5个类是我要分割的类,因此有6个类的颜色
定义颜色
def get_ciwa_label():
return np.asarray([[0, 0, 0], [1, 1, 1], [2, 2, 2], [3, 3, 3],
[4, 4, 4], [5, 5, 5]])使用该代码 在utils
修改号之后跑一下 mydata.py 出现了问题
问题 出现:
Traceback (most recent call last):
File "/home/***/opt/*****/deeplabv3/dataloaders/datasets/mydata.py", line 130, in <module>
segmap = decode_segmap(tmp, dataset='mydata')
File "/home/***/opt/****/deeplabv3/dataloaders/utils.py", line 48, in decode_segmap
rgb[:, :, 0] = r / 255.0
ValueError: could not broadcast input array from shape (513,513,3) into shape (513,513)通过打印格式 并且 和 pascal 的数据对比发现

我的数据 print(rgb.shape,r.shape) --> (513, 513, 3) (513, 513, 3)
pascal数据 print(rgb.shape,r.shape) --> (513, 513, 3) (513, 513)一直追个溯源,发现了问题所在
pascal 图片读取的 用PIL.Image 读取的,它有一个模式叫 P 模式,类似一种压缩手段,而我的数据图片也是同样方式读取出来的 却是RGB 模式 所以问题就是如何转换成P模式,找到了 一些博客https://blog.youkuaiyun.com/icamera0/article/details/50843196
通过在 mydata.py 有一个函数叫做
def _make_img_gt_point_pair(self, index):
_img = Image.open(self.images[index]).convert('RGB')
_target = Image.open(self.categories[index])
_target = _target.convert('P') # zeng增加在这里即可
return _img, _target至此,运行mydata.py 数据正常。接下来就是训练了。待续 2020.12.12
参考博客
https://blog.youkuaiyun.com/icamera0/article/details/50843196
https://blog.youkuaiyun.com/qq_39056987/article/details/106455828


















 3334
3334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









