







redis 为什么块
数据存在于于内存中,多路io复用 , 单线程
Kafka,Mq,Redis作为消息队列使用时的差异?
redis 消息推送(基于分布式 pub/sub)多用于实时性较高的消息推送,并不保证可靠。
其他的mq和kafka保证可靠但有一些延迟(非实时系统没有保证延迟)。redis-pub/sub断电就清空,而使用redis-list作为消息推送虽然有持久化,但是又太弱智,也并非完全可靠不会丢。
另外一点,redis 发布订阅除了表示不同的 topic 外,并不支持分组,比如kafka中发布一个东西,多个订阅者可以分组,同一个组里只有一个订阅者会收到该消息,这样可以用作负载均衡。
比如,kafka 中发布:topic = "发布帖子" data="文章1" 这个消息,后面有一百台服务器每台服务器都是一个订阅者,都订阅了这个 topic,但是他们可能分为三组,A组50台,用来真的做发布文章,A组50台里所有 subscriber 都订阅了这个topic。
由于在同一组,这条消息 (topic="发布帖子", data="文章1")只会被A组里面一台当前空闲的机器收到。而B组25台服务器用于统计,C组25台服务器用于存档备份,每组只有一台会收到。
和很多专业的消息队列系统(例如Kafka、RocketMQ)相比,Redis的发布订阅略显粗糙,例如无法实现消息堆积和回溯。但胜在足够简单。
redis能否将数据持久化,如何实现?
能,将内存中的数据异步写入硬盘中,两种方式:RDB(默认)和AOF
RDB持久化原理:(1) 通过bgsave命令触发,然后父进程执行fork操作创建子进程,子进程创建RDB文件,服务器进程(父进程)仍然可以继续处理命令,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换(定时一次性将所有数据进行快照生成一份副本存储在硬盘中)
(2) 通过save命令生成rdb文件,会阻塞redis服务器的进程,知道rdb文件创建完成为止,在阻塞过程中,服务器不能处理任何命令。
和创建rdb文件不同,RDB文件的载入工作是服务器自动执行的,没有专门的载入rdb文件的命令只要检测到rdb文件的存在,就会自动载入。
服务状态中 会 保存 所有的save选项设置的保存条件,任意条件满足时候,自动会执行bgsave命令。
eg: save 900 1 // 900s 内 对数据库进行至少1次操作
save 300 10 // 300s 内 10 次
rdb 结构
| REDIS | db_version | databases | EOF | check_num |
优点:是一个紧凑压缩的二进制文件,Redis加载RDB恢复数据远远快于AOF的方式。
缺点:由于每次生成RDB开销较大,非实时持久化。
AOF持久化(Append-Only-File),与RDB持久化不同,AOF持久化是通过保存Redis服务器锁执行的写状态来记录数据库的。
具体来说,RDB持久化相当于备份数据库状态,而AOF持久化是备份数据库接收到的命令,所有被写入AOF的命令都是以redis的协议格式来保存的。
在AOF持久化的文件中,数据库会记录下所有变更数据库状态的命令,除了指定数据库的select命令,其他的命令都是来自client的,这些命令会以追加(append)的形式保存到文件中。
服务器配置中有一项appendfsync,这个配置会影响服务器多久完成一次命令的记录:
always:将缓存区的内容总是即时写到AOF文件中。everysec:将缓存区的内容每隔一秒写入AOF文件中。no:写入AOF文件中的操作由操作系统决定,一般而言为了提高效率,操作系统会等待缓存区被填满,才会开始同步数据到磁盘。
redis默认实用的是everysec。
redis在载入AOF文件的时候,会创建一个虚拟的client,把AOF中每一条命令都执行一遍,最终还原回数据库的状态,它的载入也是自动的。在RDB和AOF备份文件都有的情况下,redis会优先载入AOF备份文件
优点:实时持久化。
缺点:所以AOF文件体积逐渐变大,需要定期执行重写操作来降低文件体积,加载慢
AOF更安全,可将数据及时同步到文件中,但需要较多的磁盘IO,AOF文件尺寸较大,文件内容恢复相对较慢, 也更完整。RDB持久化,安全性较差,它是正常时期数据备份及master-slave数据同步的最佳手段,文件尺寸较小,恢复数度较快。-
比较:
1、aof文件比rdb更新频率高,优先使用aof还原数据。
2、aof比rdb更安全也更大
3、rdb性能比aof好
4、如果两个都配了优先加载AOF
主从复制模式下,主挂了怎么办?redis提供了哨兵模式(高可用)
何谓哨兵模式?就是通过哨兵节点进行自主监控主从节点以及其他哨兵节点,发现主节点故障时自主进行故障转移。
故障转移的过程:
1 Sentinel 会挑选 master 下的一个从服务器 为 主服务器
2 向原来master下的从服务器发送新的复制命令,让他们成为新的主服务器的从服务器
3 sentinel 也会挑选已经下线的原maste,如果重新上线,让它成为主服务器的从服务器。
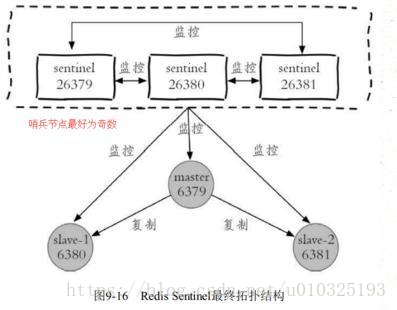
哨兵模式实现原理?
1.三个定时监控任务:
1.1 每隔10s,每个S节点(哨兵节点)会向主节点和从节点发送info命令获取最新的拓扑结构
1.2 每隔2s,每个S节点会向某频道上发送该S节点对于主节点的判断以及当前Sl节点的信息,
同时每个Sentinel节点也会订阅该频道,来了解其他S节点以及它们对主节点的判断(做客观下线依据)
1.3 每隔1s,每个S节点会向主节点、从节点、其余S节点发送一条ping命令做一次心跳检测(心跳检测机制),来确认这些节点当前是否可达
2.主客观下线:
2.1主观下线:根据第三个定时任务对没有有效回复的节点做主观下线处理
2.2客观下线:若主观下线的是主节点,会咨询其他S节点对该主节点的判断,超过半数,对该主节点做客观下线
3.选举出某一哨兵节点作为领导者,来进行故障转移。
选举方式:raft算法。每个S节点有一票同意权,哪个S节点做出主观下线的时候,就会询问其他S节点是否同意其为领导者。获得半数选票的则成为领导者。基本谁先做出客观下线,谁成为领导者。
4.故障转移(选举新主节点流程):
(1)如何选举出一个领头的sentinal?
(2) 新的主服务器是如何选举出来的?

















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









