







 本文探讨了联邦学习的概念,如何解决数据隐私问题,介绍了其历史发展,包括不同类型的联邦学习(横向、纵向、迁移),并聚焦于参与者的特点和实例。重点讲解了迁移学习和CNN在联邦学习中的应用,以及其在保护用户隐私的同时提升模型性能的作用。
本文探讨了联邦学习的概念,如何解决数据隐私问题,介绍了其历史发展,包括不同类型的联邦学习(横向、纵向、迁移),并聚焦于参与者的特点和实例。重点讲解了迁移学习和CNN在联邦学习中的应用,以及其在保护用户隐私的同时提升模型性能的作用。
参考
什么是联邦学习(Federated Learning)?【知多少】
前景
数据越多,训练出的模型效果就越好
你有数据,我有数据,那么让大家的数据都集中在一起,然后训练出更好的模型后共享使用,岂不美哉?
nono,现实中不是这样的
因为现实世界中,数据是属于用户的,我们既不能申请使用他们,同时还要保护数据的隐私性
提出问题
数据的协作和隐私问题:那有没有办法实现安全和高效的 数据合作 呢?
答案之一就是联邦学习
历史
2016 年,Google 提出,在用户手机中训练模型,之后上传训练后的数据,替代直接上传隐私数据,一定程度上保证了个人数据的私密。
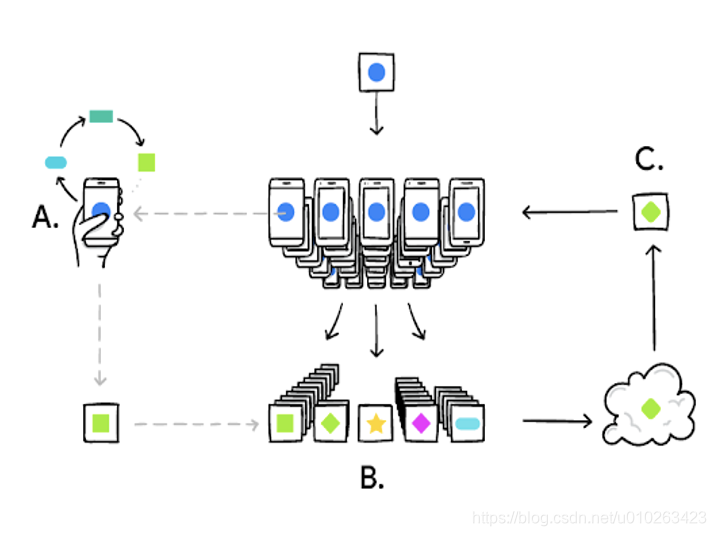
Google 提出通过一个中央服务器协调众多松散的智能终端实现语言预测模型更新。
- 原始数据存储在本地,不进行交换或传输。
- 只传输有限的中间结果,用于进行必需的聚合,以实现机器学习
- 多轮迭代学习
开源框架:FATE,Pysyft,Tensorflow Fedrated(TFF)等
分类
| 横向联邦学习/特征对齐的联邦学习 | 纵向联邦学习/ 样本对齐的联邦学习 | 联邦迁移学习 | |
|---|---|---|---|
| 参与者特点 | 业务相似,数据的特征重叠多,样本重叠少 | 样本重叠多,特征重叠少 | 样本、特征重合都不多 |
| 参与者例子 | 不同地区的两家银行 | 同一区域的银行和电商 | - |
| 说明 | 上传参数,在服务器中聚合更新模型,再将最新的参数下方,完成模型效果的提升 | (需要先进行样本对其,由于不能直接比对,我们需要加密算法的帮助RSA,让参与者在不暴露不重叠的样本的情况下,找出相同的样本后联合他们的特征进行学习) | 如果样本和特征重合都不多,希望利用数据提升模型能力,就需要将参与者的模型和数据迁移到同一空间中运算 |
个人总结
联邦学习就是为了训练更好的模型的同时,不泄露用户隐私的前提下提供特征数据,进行模型优化训练的手段。
前提:迁移学习
利用已有的经验解决相似任务
将训练好的猫狗分类网络的前几层直接拿来用
再用 苹果+梨 训练新的全连接层
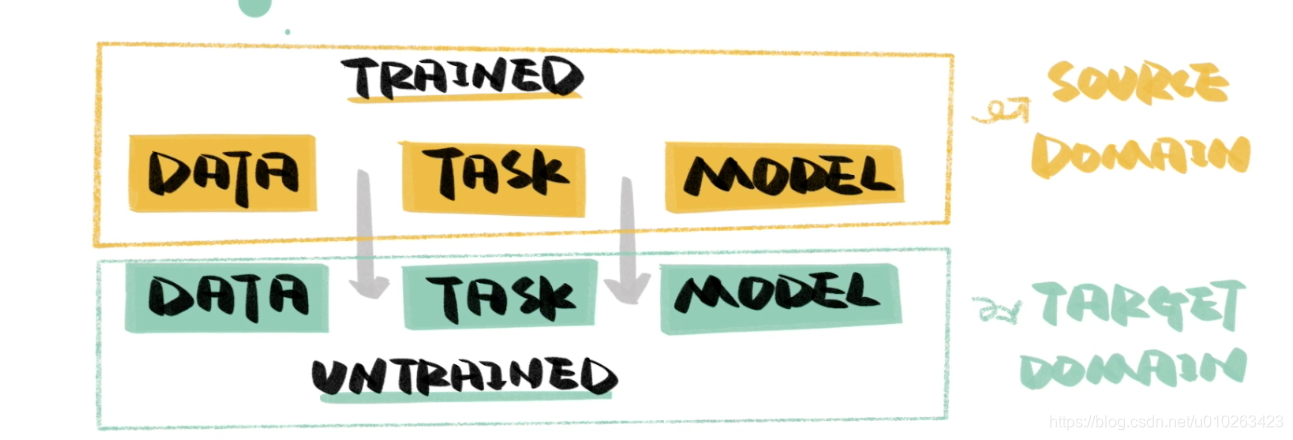
概念:利用数据、任务、模型间的相似性,将训练好的内容应用到新的任务上。
CNN 卷积神经网络
提取图像特征
卷积
计算方法,卷积核和图片矩阵(RGB) 对齐后,相乘再相加
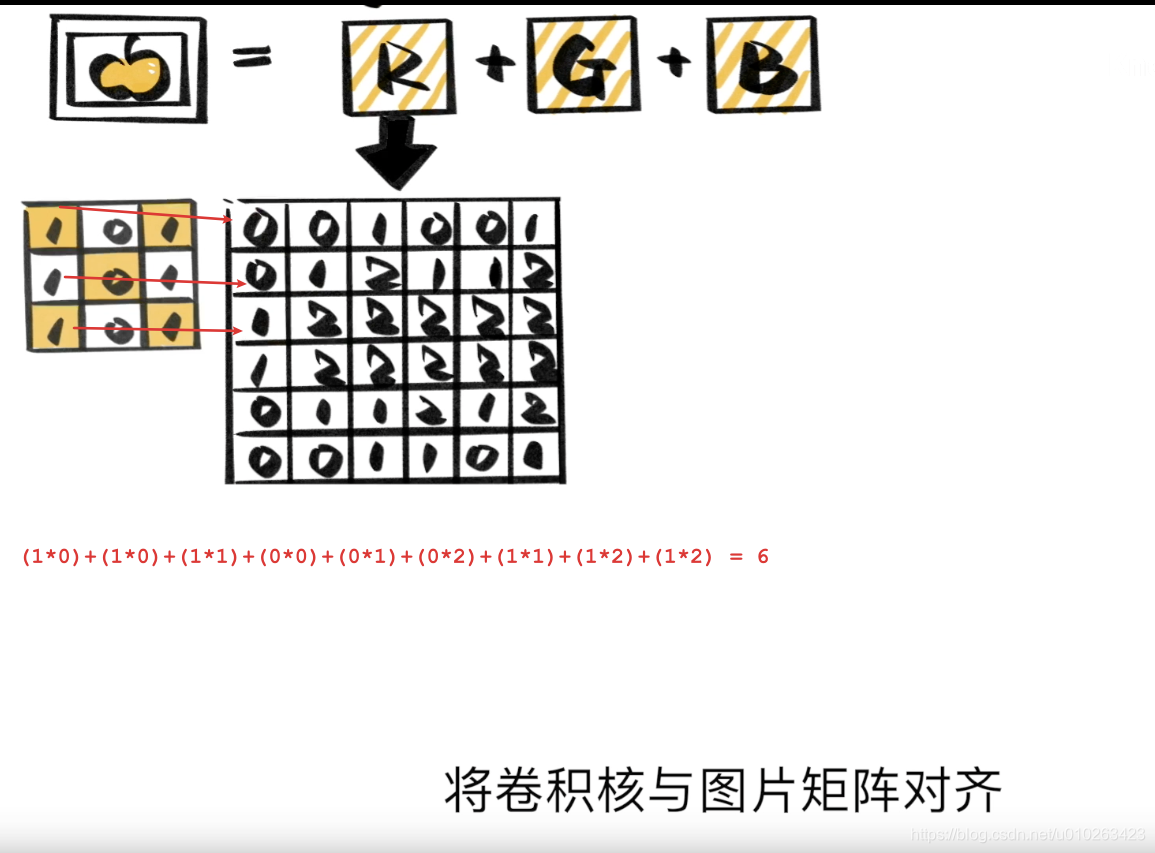
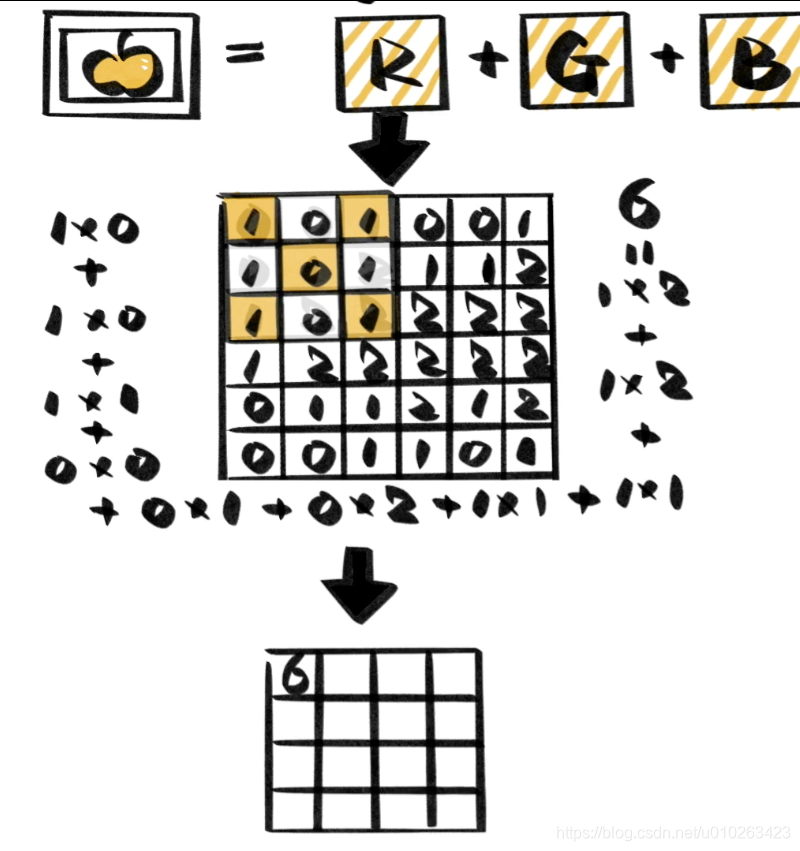
步长:卷积核以一定的距离在图像上移动预算
得到的新矩阵能反映图像的部分特征
训练:根据已有标签,自动确定卷积核中的数字。
前几层:提取图像特征
全连接层:进行分类
应用
将声音当做图谱处理能够完成语音识别
词语当做向量处理能够完成机器翻译


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









