






打卡
首先我们深度学习处理的数据不是可以直接输入进行处理,都是要经过数据处理,或者清洗的。
现在就看看,mindspore提供的简单的transforms形式
- 还是用系统提供的数据,下载处理
首先导入相关的包
import numpy as np
from download import download
from PIL import Image
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
Common Transforms
Vision Transforms
# vison transforms
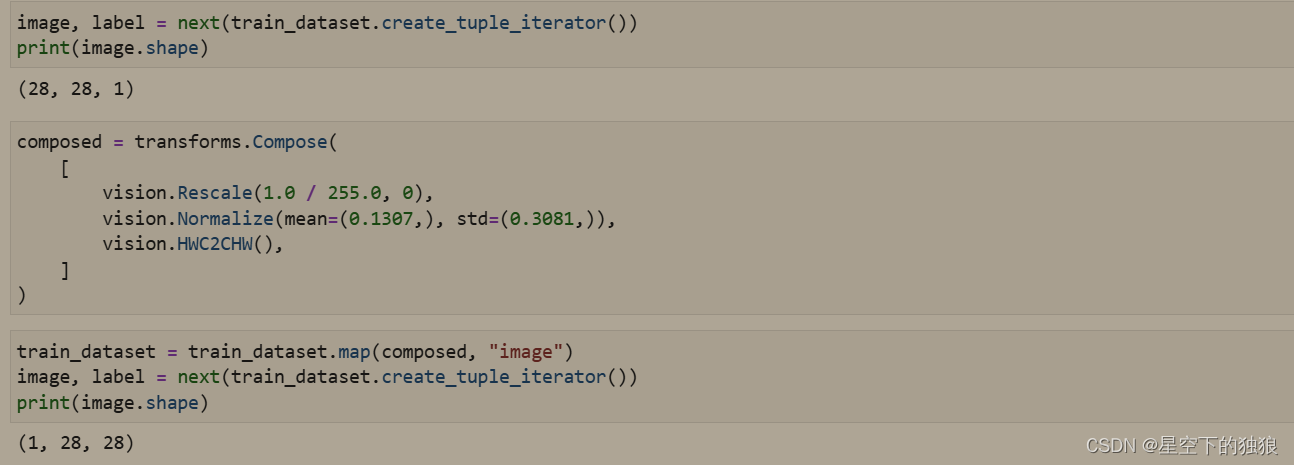
# Rescale 有两个参数 rescale 缩放因子 shift :平移因子
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
print(random_np)
)
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
print(rescaled_image)
# Normalize 三个参数 mean 图像每个通道均值,std:图像每个通道标准差 is_hwc bool值 True为(hwc) False(chw)
normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)
print(normalized_image
# hwc2chw
hwc_image = np.expand_dims(normalized_image, -1)
hwc2chw = vision.HWC2CHW()
chw_image = hwc2chw(hwc_image)
print(hwc_image.shape, chw_image.shape)
# Text Transforms
texts = ["Welcome to Beijing"]
test_dataset = GeneratorDataset(texts, "text")
# PythonTokenizer j进行分词
def my_tokenizer(content):
return content.split()
test_dataset = test_dataset.map(text.PythonTokenizer(my_tokenizer))
print(next(test_dataset.create_tuple_iterator()))
# lookup 词表映射变化 token->index
vocab = text.Vocab.from_dataset(test_dataset)
print(vocab.vocab())
# Token->Index
test_dataset = test_dataset.map(text.Lookup(vocab))
print(next(test_dataset.create_tuple_iterator()))
# Lambda Transforms 可以使用lambda表达式
test_dataset = GeneratorDataset([1,2,3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x:x * 2)
print(list(test_dataset.create_tuple_iterator()))
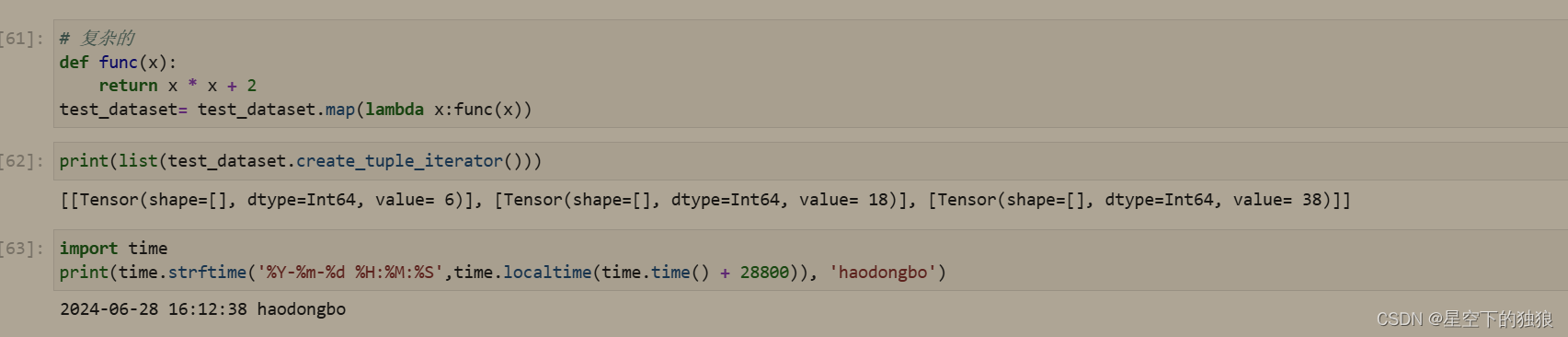
# 复杂的
def func(x):
return x * x + 2
test_dataset= test_dataset.map(lambda x:func(x))
print(list(test_dataset.create_tuple_iterator()))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









