






Tinyid实现原理
首先生成全局唯一ID有如下三个思路
- 基于数据库生成;
- 基于分布式集群协调器生成(ZooKeeper, Consul ,Etcd等);
- 划分命名空间并行生成(Snowflake为代表
Tinyid 基于第一种思路生成全局唯一ID。如果使用db的auto_increment,虽然实现简单、但性能比较差,对db访问比较频繁,db的压力会比较大。
优化手段一、号段
Tinyid解决了该问题,主要实现思路为一批id,可以看成是一个id范围,例如(1000,2000],这个1000到2000也可以称为一个"号段",我们一次向db申请一个号段,加载到内存中,然后采用自增的方式来生成id,这个号段用完后,再次向db申请一个新的号段,这样对db的压力就减轻了很多,同时内存中直接生成id,性能则提高了很多。
所以Tinyid数据库表设计时,只需要满足能存储一个范围即可,一个端点(Tinyid使用右端点)和一个步长可以确定一个范围。
| id | biz_type | max_id | step | version |
|---|---|---|---|---|
| 1 | 1000 | 2000 | 1000 | 0 |
- biz_type : 业务类型,不同业务的id隔离
- max_id :当前号段最大可用id,即右端点
- step:步长,根据每个业务的qps来设置一个合理的长度
- version : 当前版本,用于实现乐观锁,每次更新都加上version,能够保证并发更新的正确性
@Override
@Transactional(isolation = Isolation.READ_COMMITTED)
public SegmentId getNextSegmentId(String bizType) {
// 获取nextTinyId的时候,有可能存在version冲突,需要重试
for (int i = 0; i < Constants.RETRY; i++) {
// select id, biz_type, begin_id, max_id, step, delta, remainder, create_time, update_time, version
// from tiny_id_info where biz_type = ?
TinyIdInfo tinyIdInfo = tinyIdInfoDAO.queryByBizType(bizType);
if (tinyIdInfo == null) {
throw new TinyIdSysException("can not find biztype:" + bizType);
}
Long newMaxId = tinyIdInfo.getMaxId() + tinyIdInfo.getStep();
Long oldMaxId = tinyIdInfo.getMaxId();
// update tiny_id_info set max_id= ?, update_time=now(), version=version+1
// where id=? and max_id=? and version=? and biz_type=?
// CAS
int row = tinyIdInfoDAO.updateMaxId(tinyIdInfo.getId(), newMaxId, oldMaxId, tinyIdInfo.getVersion(),
tinyIdInfo.getBizType());
if (row == 1) {
tinyIdInfo.setMaxId(newMaxId);
SegmentId segmentId = convert(tinyIdInfo);
logger.info("getNextSegmentId success tinyIdInfo:{} current:{}", tinyIdInfo, segmentId);
return segmentId;
} else {
logger.info("getNextSegmentId conflict tinyIdInfo:{}", tinyIdInfo);
}
}
throw new TinyIdSysException("get next segmentId conflict");
}
以上是获取号段代码,基于CAS(Compare and Swap)思想 。这里比较值得注意一点是该方法事务的隔离级别设置为READ_COMMITTED(提交读),主要为了考虑以下两点:
- Transactional标记保证query和update使用的是同一连接。
- MySQL默认事务隔离级别为REPEATABLE_READ(可重复读, MySQL底层使用MVCC),保证同一个事务中读到的version字段相同(循环调用
tinyIdInfoDAO.queryByBizType(bizType)获取的结果是没有变化的),感知不到其他事务对version字段的改变,可能会导致CAS失败。
优化手段二、双缓存
在一个号段用完后,需要向数据库申请下一个号段,此时客户端需要等待,造成性能波动。有没有解决方案呢?
Tinyid使用双缓存(重数据库加载到内存中的号段)解决这个问题,在号段用到一定程度(默认20%)的时候,就去异步加载下一个号段,保证内存中始终有可用号段,则可避免性能波动。
protected SegmentIdService segmentIdService;
protected volatile SegmentId current; // 当前号段
protected volatile SegmentId next; // 下一号段
private volatile boolean isLoadingNext; // 是否正在加载下一号段
private Object lock = new Object();
private ExecutorService executorService = Executors.newSingleThreadExecutor(new NamedThreadFactory("tinyid-generator")); // 加载下一号段的异步线程池
nextId()方法用于从缓存中获取一个id。
@Override
public Long nextId() {
while (true) {
if (current == null) {
// 懒加载,申请当前号段
loadCurrent();
continue;
}
// 从当前号段缓存中获取一个id
Result result = current.nextId();
// 当前号段缓存的id用尽
if (result.getCode() == ResultCode.OVER) {
loadCurrent();
} else {
// 当前号段用到一定程度,触发异步加载下一号段
if (result.getCode() == ResultCode.LOADING) {
loadNext();
}
return result.getId();
}
}
}
loadCurrent() 加载当前号段,使用synchronized关键字保证线程安全。有两个地方可能用到这个方法,一个是初始化时懒加载当前号段,另一个是当前号段缓存的id用尽,使用下一号段替换当前号段。
public synchronized void loadCurrent() {
if (current == null || !current.useful()) {
if (next == null) {
// 从数据库中查询一个号段
SegmentId segmentId = querySegmentId();
this.current = segmentId;
} else {
// 用下一号段替换当前号段
current = next;
next = null;
}
}
}
当前号段用到一定程度,调用loadNext()方法异步加载下一号段。
public void loadNext() {
// double check
if (next == null && !isLoadingNext) {
synchronized (lock) {
if (next == null && !isLoadingNext) {
isLoadingNext = true;
executorService.submit(new Runnable() {
@Override
public void run() {
try {
// 无论获取下个segmentId成功与否,都要将isLoadingNext赋值为false
next = querySegmentId();
} finally {
isLoadingNext = false;
}
}
});
}
}
}
}
优化手段三、多db支持
只有一个数据库时,可用性难以保证,当主库挂了会造成申请号段不可用。另外扩展性差,性能有上限,因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且难以扩展。
为了解决此问题,Tinyid 可以增加主库,避免写入单点。为了保证各主库生成的ID不重复,需要为每个主库设置不同的auto_increment初始值,以及相同的增长步长。
例如,有三个主库DB-0,DB-1,DB-2,将auto_increment初始值分别设置为0,1,2,步长都为3,则库DB-0生成0,3,6,9…,库DB-1生成1,4,7,10,库DB-2生成2,5,8,11…;
但数据库需要增加两个字段delta和remainder,分别表示增长步长和auto_increment初始值。
| id | biz_type | max_id | step | delta | remainder | version |
|---|---|---|---|---|---|---|
| 1 | 1000 | 2000 | 1000 | 2 | 0 | 0 |
但是这里有个问题,比如从申请到号段(1000,2000]后,如果delta=3, remainder=0,则这个号段从哪个id开始分配,肯定不是1001,所以这里就需要计算。设置好初始id之后,就以delta的方式递增分配。因为会先递增,所以会浪费一个id,所以做了一次减delta的操作,实际会从999开始增,第一个id还是1002。
public Result nextId() {
init();
// 先自增
long id = currentId.addAndGet(delta);
if (id > maxId) {
return new Result(ResultCode.OVER, id);
}
if (id >= loadingId) {
return new Result(ResultCode.LOADING, id);
}
return new Result(ResultCode.NORMAL, id);
}
public void init() {
if (isInit) {
return;
}
// double check
synchronized (this) {
if (isInit) {
return;
}
long id = currentId.get();
if (id % delta == remainder) {
isInit = true;
return;
}
for (int i = 0; i <= delta; i++) {
id = currentId.incrementAndGet();
if (id % delta == remainder) {
// 避免浪费 减掉系统自己占用的一个id
currentId.addAndGet(0 - delta);
isInit = true;
return;
}
}
}
}
在决定数据源时,使用一下方法
@Override
protected Object determineCurrentLookupKey() {
// 只有一个数据源时
if(dataSourceKeys.size() == 1) {
return dataSourceKeys.get(0);
}
// 多个数据源时,随机选择一个
Random r = new Random();
return dataSourceKeys.get(r.nextInt(dataSourceKeys.size()));
}
从上面可以看出,如果有多个数据源,则随机选择一个,所有生成的id不是严格单调递增的,而是趋势递增,能满足大部分业务场景。
优化手段四、分布式部署
虽然数据库单点问题解决了,但是还是单个服务选择多个数据库,服务挂了怎么办?服务单点问题并没有解决。
一个简单的解决方案就是将服务部署到多个机房的多台机器。但是问题又随之而来,多个服务之间怎么协调?What?在Spring Cloud中微服务多实例部署,可以将其注册到服务注册中心,然后在客户端使用负载均衡算法访问服务。或者在服务端使用反向代理,为多实例做负载均衡。
但是Tinyid 作为一个独立服务部署,引入这些组件将增加维护成本,所以呢,Tinyid 提供了SDK,在SDK中做了客户端负载均衡(随机算法)。
private String chooseService(String bizType) {
List<String> serverList = TinyIdClientConfig.getInstance().getServerList();
String url = "";
if (serverList != null && serverList.size() == 1) {
url = serverList.get(0);
} else if (serverList != null && serverList.size() > 1) {
// 多实例部署时,随机选择一个服务
Random r = new Random();
url = serverList.get(r.nextInt(serverList.size()));
}
url += bizType;
return url;
}
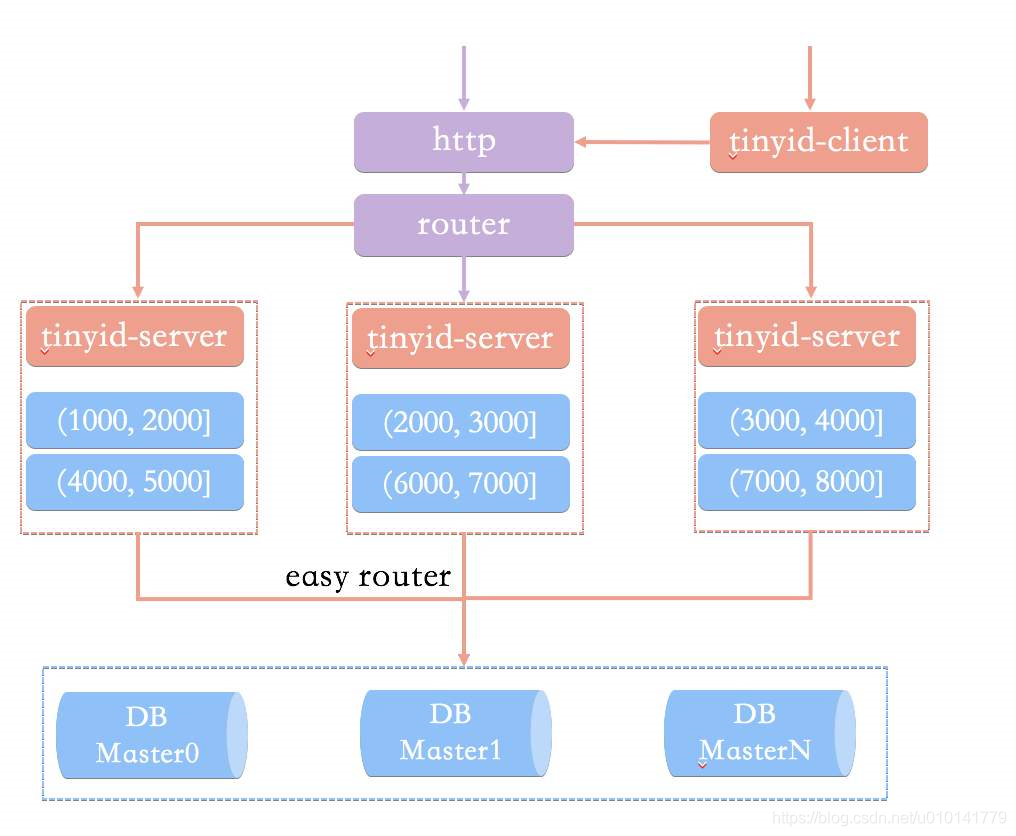
最后,附上Tinyid系统架构图

















 1475
1475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









