






阅读前言
本文以QNX系统官方的文档英文原版资料为参考,翻译和逐句校对后,对QNX操作系统的相关概念进行了深度整理,旨在帮助想要了解QNX的读者及开发者可以快速阅读,而不必查看晦涩难懂的英文原文,这些文章将会作为一个或多个系列进行发布,从遵从原文的翻译,到针对某些重要概念的穿插引入,以及再到各个重要专题的梳理,大致分为这三个层次部分,分不同的文章进行发布,依据这样的原则进行组织,读者可以更好的查找和理解。
1. QNX Neutrino 微内核(二)
本文接上一篇文章:《2-2-18-2 QNX Neutrino 微内核(一)》
1.5. 同步服务
QNX Neutrino RTOS提供了POSIX标准的线程级的同步原语,其中一些甚至在不同进程的线程之间也很有用。
同步服务至少包括以下内容:
| 同步服务 | 支持跨进程 | 支持跨 QNX Neutrino 局域网 |
| Mutexes【互斥锁】 | Yesa | No |
| Condvars【条件变量】 | Yes | No |
| Barriers【屏障】 | Yesa | No |
| Sleepon locks【睡眠锁】 | No | No |
| Reader/writer locks【读写锁】 | Yesa | No |
| Semaphores【信号量】 | Yes | Yes (named only) |
| Send/Receive/Reply【发送/接收/回复】 | Yes | Yes |
| Atomic operations【原子操作】 | Yes | No |
注:在进程之间共享这种类型的对象可能是一个安全问题;请参阅本章后面的“Safely sharing mutexes, barriers, and reader/writer locks between processes”。
以上同步原语都是由内核直接实现的,除了:
- Sleepon locks【睡眠锁】, 和 Reader/writer locks【读锁/写锁】(基于mutex和condvar构建);
- Atomic operations【原子操作】(要么由处理器直接实现,要么在内核中模拟实现);
你应该只在常规内存映射中分配mutexes, condvars, barriers, reader/writer locks, and semaphores,以及你计划使用原子操作的对象。在某些处理器上,如果对象分配在未缓存的内存中,(如 pthread_mutex_lock() 这种)原子操作和函数调用将导致故障。
1.5.1. Mutexes:互斥锁
互斥锁(Mutexes或mutual exclusion locks)是同步服务中最简单的。互斥锁用于确保了对在各线程之间共享的数据的独占访问。
互斥锁请求(pthread_mutex_lock()或pthread_mutex_timedlock())释放pthread_mutex_unlock())通常都是围绕访问共享数据(通常是临界区)的代码进行设置的。
在任何给定时间,只有一个线程可以锁定互斥锁。试图锁定已锁定互斥锁的线程将进入阻塞状态,直到拥有该互斥锁的线程将其解锁。当线程解锁了互斥锁时,等待锁定互斥锁的最高优先级线程将解除阻塞状态并成为互斥锁的新所有者。通过这种方式,线程将按照优先级顺序对临界区的访问进行排序。
在大多数情况下,请求互斥锁并不需要进入内核获取一个自由的互斥锁。在x86处理器上使用compare-and-swap opcode,在大多数ARM处理器上使用 load/store conditional opcode。
如果互斥锁已经被持有,那么在请求时必须进入内核,只有这样线程才能被加入阻塞列表;如果有其他线程正在该互斥锁上等待解除阻塞,则“进入内核”会在退出时完成【译者注:正在使用资源的线程退出使用时?】。这使得正常的获取和释放无竞争的临界区或资源变得非常快,而操作系统只需要解决竞争问题。
非阻塞加锁函数(pthread_mutex_trylock())可用于测试互斥锁当前是否被锁定。为了获得最佳性能,临界段的执行时间应该很短,并且持续时间有限。如果线程可能在临界区域内阻塞,则应使用condvar(条件变量)。
优先级继承和互斥锁
默认情况下,如果一个优先级高于互斥锁所有者的线程试图锁定一个互斥锁,那么互斥锁当前所有者的有效优先级将被提高到被阻塞的高优先级线程的有效优先级(参见下文)。互斥锁所有者的有效优先级会在解锁互斥锁时再次调整回来;它的新优先级将会是它自己的优先级和它仍然直接或间接阻塞的线程的优先级的最大值。
该方案不仅保证了高优先级线程在尽可能短的时间内被阻塞等待互斥锁,而且解决了经典的优先级反转问题。
通过pthread_mutexattr_init()函数将协议策略设置为PTHREAD_PRIO_INHERIT以允许此行为;你可以调用pthread_mutexattr_setprotocol()来覆盖此设置。pthread_mutex_trylock()函数不会改变线程优先级,因为它不会阻塞。
如果等待互斥锁的线程以特权优先级运行,而互斥锁所有者的进程没有启用PROCMGR_AID_PRIORITY功能,会发生什么情况?在这种情况下,拥有互斥锁的线程被提升到最高的非特权优先级。有关更多信息,请参阅本章前面的“Scheduling priority”和C库参考中的 procmgr_ability()。
其它属性的设置
你也可以在初始化互斥锁之前修改互斥锁的其他属性:
- 使用
pthread_mutexattr_settype()允许互斥锁由同一线程递归锁定。这将会,允许当前线程,试图再次锁定当前线程已经锁定了的互斥锁,对于这样的例程很有用。【支持递归锁定,意味着能够在递归调用中使用,也就是可以多次上锁,并且需要对应次数的释放才能真正解锁】 - (QNX Neutrino 7.0 或 更高版本)使用
pthread_mutexattr_setrobust()来设置互斥锁的【robustness】健壮性,如果互斥锁的所有者在持有它时意外终止了,【robustness】健壮性将帮助你恢复互斥锁。非POSIX的内核调用SyncMutexEvent()为恢复互斥锁提供了一种不同的(互斥)机制。 - 使用pthread_mutexattr_setprioceiling()为互斥锁设置优先级上限。
请注意,健壮的互斥锁、具有优先级上限的互斥锁以及使用SyncMutexEvent()的互斥锁,会比其他互斥锁消耗更多的系统资源。
1.5.2. Condvars:条件变量
条件变量(condvar)用于阻塞处于临界区域内的线程,直到满足某些条件。条件可以是任意复杂的,并且独立于condvar。然而,为了实现监视器【用于监视条件是否满足】,condvar必须始终与互斥锁一起使用。
@>> 阅读总结:
- 必须在持有互斥锁的情况下调用pthread_cond_wait(),因为在等待条件变量时会自动释放互斥锁,并在被唤醒后重新尝试获取互斥锁。
- 唤醒操作(信号或广播)与等待操作之间的条件判断可能存在竞态条件,因此通常需要在循环中检查条件是否满足。
条件变量(condvar)支持三种操作:
- wait(
pthread_cond_wait()),等待 - signal(
pthread_cond_signal()),信号 - broadcast(
pthread_cond_broadcast()),广播
注意,condvar信号和 POSIX 信号之间没有连接。
@>> 阅读总结:
Condvars在QNX操作系统中的作用可以概括为以下几点:
- 条件等待:线程在访问共享资源或执行某个任务时,可能需要等待某个条件成立。使用条件变量,线程可以在条件不满足时挂起自己,释放互斥锁,从而允许其他线程执行并可能改变条件。
- 条件满足时的唤醒:当条件变量关联的条件被满足时(通常是由另一个线程通过某种操作改变了条件),等待该条件变量的一个或多个线程将被唤醒,并重新尝试获取之前释放的互斥锁以继续执行。
- 广播和信号:条件变量支持两种唤醒方式:广播(Broadcast)和信号(Signal)。广播会唤醒所有等待该条件变量的线程,而信号则只唤醒等待该条件变量的一个线程(具体唤醒哪个线程取决于操作系统的调度策略)。
- 避免忙等:使用条件变量可以避免线程在条件不满足时进行忙等(即不断循环检查条件是否满足),从而提高程序的效率和响应性。
下面是condvar用法的一个典型例子:
pthread_mutex_lock( &m );
. . .
while (!arbitrary_condition) {
pthread_cond_wait( &cv, &m );
}
. . .
pthread_mutex_unlock( &m );在这个代码示例中,互斥锁是在测试条件之前获得的。这确保了只有这个线程可以访问被检查的任意条件。当条件为真时,代码示例将阻塞在wait调用,直到其他线程在当前condvar上执行信号或广播。
至于代码中条件检查需要使用while循环,有两个原因。首先,POSIX不能保证不会发生错误唤醒(例如,多处理器系统)。其次,当另一个线程修改了条件时,我们需要重新检查条件以确保针对条件的修改是否符合我们的判断标准。当等待线程被阻塞以允许另一个线程进入临界区时,pthread_cond_wait()会自动解锁相关的互斥锁。
执行信号的线程,将会解除队列中最高优先级线程的阻塞状态,而广播将会解除队列中所有线程的阻塞状态。相关的互斥锁由最高优先级的未阻塞线程自动锁定;然后,线程必须在处理完临界区代码之后解除互斥锁。
condvar等待操作,有一个版本的函数(pthread_cond_timedwait()),允许指定超时时间。进行等待的线程可以在超时到期时被解除阻塞。
应用程序在有条件变量时,不应该使用
PTHREAD_MUTEX_RECURSIVE互斥锁,因为对pthread_cond_wait()或pthread_cond_timedwait()执行的隐式解锁,可能造成实际上无法释放互斥锁(如果它被多次锁定)。如果发生这种情况,则没有其他线程可以满足表语条件。
1.5.3. Barriers(屏障)
屏障【barrier】是一种同步机制,它允许你“圈定”几个协作线程(例如,在矩阵计算中),迫使它们在某个特定的点等待,直到所有线程都完成后,所有线程才能继续执行。
与等待线程终止的pthread_join()函数不同,在使用屏障【barrier】的情况下,等待线程在某一个点进行会合。当指定数量的线程到达屏障时,我们解除对所有线程的阻塞,使它们能够继续运行。
首先使用pthread_barrier_init()创建一个barrier:
#include <pthread.h>
int pthread_barrier_init (pthread_barrier_t *barrier,
const pthread_barrierattr_t *attr,
unsigned int count);这会在传递的地址处创建一个屏障【barrier】对象(【barrier】中有一个指向屏障对象的指针),其属性由attr指定。count成员则指定了必须调用pthread_barrier_wait()函数的线程的数量。
屏障【barrier】一旦被创建,则每个线程都将通过调用pthread_barrier_wait()来表示它已经完成特定的工作:
#include <pthread.h>
int pthread_barrier_wait (pthread_barrier_t *barrier);当线程调用pthread_barrier_wait()时,会进入阻塞状态,直到pthread_barrier_init()函数初始化时所指定的数量的线程都调用了pthread_barrier_wait()(并且也进入了阻塞状态)。当线程数量达标时,所有这些线程将会同时解除阻塞状态。
以下是示例代码:
/*
* barrier1.c
*/
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <time.h>
#include <pthread.h>
#include <sys/neutrino.h>
pthread_barrier_t barrier; // barrier synchronization object
void* thread1 (void *not_used)
{
time_t now;
time (&now);
printf ("thread1 starting at %s", ctime (&now));
// do the computation
// let's just do a sleep here...
sleep (20);
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in thread1() done at %s", ctime (&now));
}
void* thread2 (void *not_used)
{
time_t now;
time (&now);
printf ("thread2 starting at %s", ctime (&now));
// do the computation
// let's just do a sleep here...
sleep (40);
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in thread2() done at %s", ctime (&now));
}
int main () // ignore arguments
{
time_t now;
// create a barrier object with a count of 3
pthread_barrier_init (&barrier, NULL, 3);
// start up two threads, thread1 and thread2
pthread_create (NULL, NULL, thread1, NULL);
pthread_create (NULL, NULL, thread2, NULL);
// at this point, thread1 and thread2 are running
// now wait for completion
time (&now);
printf ("main() waiting for barrier at %s", ctime (&now));
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in main() done at %s", ctime (&now));
pthread_exit( NULL );
return (EXIT_SUCCESS);
}主线程创建了barrier对象,并使用线程总数初始化该屏障对象,这些线程必须在继续运行之前,都同步到该屏障。在上述例子中,我们使用了数量3:一个会用于main()线程,另一个用于thread1()线程,还有一个用于thread2()。
然后我们启动thread1()和thread2()。为了简化这个示例,我们让线程执行了休眠以便产生延迟,就像正在进行计算一样。要实现同步,主线程只需在barrier上阻塞自己,因为主线程知道只有在另两个工作线程也加入到了该barrier之后,barrier才会解除对所有线程的阻塞。
在当前版本(QNX Neutrino 7.1)中,包含以下屏障函数:
| Function | Description |
| 获取屏障的进程共享属性值 | |
| 销毁屏障的属性对象 | |
| 初始化屏障的属性对象 | |
| 设置屏障的进程共享属性值 | |
| 销毁屏障 | |
| 初始化屏障 | |
| 阻塞等待,用于同步屏障上的所有参与线程 |
1.5.4. Sleepon locks(休眠锁)
休眠锁【Sleepon locks】与条件变量【condvars】非常相似,只是有一些细微的区别。
与条件变量condvars一样,睡眠锁(pthread_sleepon_lock())也可以用于阻塞线程,直到条件变为true(例如,内存位置改变了数值)。但是,与必须为每个要被检查的条件都分配条件变量【condvar】不同的是,休眠锁【Sleepon locks】基于单个互斥锁以及动态分配的条件变量【condvar】进行创建,复用了它们的功能,而不管要检查的条件有多少个。条件变量【condvar】的最大数量最终会等于被阻塞线程的最大数量。QNX中的这些休眠锁就是按照UNIX内核中常用的休眠锁进行设计的。
1.5.5. Reader/writer locks(读写锁)
更正式的说法应该是“Multiple readers, single writer locks”,当数据结构的访问模式由许多读取数据的线程和(最多)一个写入数据的线程组成时,使用Reader/writer locks【读写锁】。读写锁比互斥锁更“昂贵”,但对于这种数据访问模式很有用。
这种类型的锁的工作原理是,允许所有请求读访问锁(pthread_rwlock_rdlock())的线程成功地完成它们的请求。但是当一个想要写的线程请求锁(pthread_rwlock_wrlock())时,请求会被拒绝,直到所有当前的读线程释放了它们的读锁(pthread_rwlock_unlock())。
在等待写入机会时,多个写线程可以(按优先级顺序)排队,所有被阻塞的写线程将会在允许读线程再次访问之前运行。不会考虑读线程的优先级。
还有一些调用(pthread_rwlock_tryrdlock()和pthread_rwlock_trywrlock())允许线程在不阻塞的情况下测试请求锁。这两个函数调用可能返回一个成功的锁,也可能返回一个状态,表明锁不能被立即授予。
读写锁【Reader/writer locks】不是直接在内核中实现的,而是基于内核所提供的互斥锁【mutex】和条件变量【condvar】进行构建的。
1.5.6. 在进程之间安全地共享Mutexes、barriers和Reader/Writer locks
你可以在进程之间共享大多数的同步对象,但安全性可能是一个需要考虑的问题。
大多数讨论都只涉及到互斥锁【Mutexes】,但是屏障【barriers】和读写锁【Reader/Writer locks】是由互斥锁构建的,所以对于互斥锁的讨论也适用于它们。
注意:为了让进程共享同步对象,这些进程还必须共享同步对象所在的内存。
共享互斥锁的问题在于,任何进程中的一个线程都可以声明(在任何进程中的)另一个线程拥有这个互斥锁;当应用了优先级继承时,后者的优先级将提高到前者的优先级。如果应用程序需要在不同的进程之间共享互斥锁,那么它必须决定是否将自己暴露在不相关进程的潜在干扰因素之下,无论是禁用共享互斥锁的优先级继承,还是强制让针对共享互斥锁的所有操作都进入内核态(通常不会这样做),这两种方法都会导致性能损失。
在QNX Neutrino 7.0.1或更高版本中,可以将内核配置为拒绝尝试锁定共享互斥锁,除非所有的互斥锁操作都进入内核,否则这(对共享互斥锁的锁定尝试)会导致优先级继承。这对使用优先级继承协议策略的共享互斥锁的性能有着重大的影响,但保证了非协作线程之间不会相互干扰。为了安全地使用共享互斥锁,必须做到以下几点:
- 为procnto指定-s选项,强制所有支持优先级继承的共享互斥锁上的操作都进入内核。
- 通过
pthread_mutexattr_setprotocol()设置PTHREAD_PRIO_NONE标志来禁用互斥锁的优先级继承,或者通过pthread_mutexattr_setpshared()并使用PTHREAD_PROCESS_SHARED标志来设置进程共享属性,从而显式地标识互斥锁为共享的。
如果指定了-s选项,对于设置了PTHREAD_PRIO_INHERIT标志但没有设置PTHREAD_PROCESS_SHARED标志的互斥锁,内核将拒绝任何锁定尝试。在这种情况下, pthread_mutex_lock()和SyncMutexLock()都会返回EINVAL错误。
类似地,如果你使用procnto的-s选项,并且你在进程之间共享了屏障【barriers】或读写锁【Reader/Writer locks】,则应该使用pthread_barrierattr_setpshared()或pthread_rwlockattr_setpshared()将其进程共享属性设置为PTHREAD_PROCESS_SHARED。
1.5.7. Semaphore(信号量)
信号量【Semaphores】是一种常见的同步形式,它允许线程在信号量上“发布”和“等待”,以控制线程何时可以唤醒或休眠。
信号量与其他同步原语的不同之处在于,它们是“异步安全的”,可以由signal handlers操作。如果期望的效果是让signal handler唤醒线程,那么使用信号量是正确的选择。
QNX Neutrino 实现的信号量支持命名信号量和未命名信号量(参见下面的“Named and unnamed semaphores”)。
使用信号量还是互斥锁?
信号量相对于互斥锁的一个关键优势是,信号量被定义为在进程之间操作。
虽然我们的互斥锁也能在进程之间工作,但是“POSIX线程标准”认为这只是一个可选的功能。因此,如果你的代码依赖于进程之间的互斥锁,为了确保可移植性,你可能应该使用信号量取代互斥锁。
然而,根据你的需要,在考虑以下因素后,你也有可能希望使用互斥锁而不是信号量:
- 一般来说,互斥锁比信号量要快得多,信号量总是需要一个内核入口(会切换至内核态)。
- 对于单个进程中线程之间的同步服务,互斥锁会比信号量更有效。
- 信号量不会影响线程的有效优先级;如果需要优先级继承,请使用互斥锁(参见本章的“Mutexes: mutual exclusion lock”)。
使用信号量
发布【post】(sem_post())操作将会增加信号量;等待【wait】(sem_wait())操作会使其递减。
如果等待的信号量为正,则不会阻塞。等待非正的信号量将会发生阻塞,直到其他线程执行了post操作。在等待之前post一次或多次都是有效的。这种用法允许一个或多个线程在不阻塞的情况下执行等待。
由于信号量和条件变量一样,可以由于错误唤醒而合法返回非零值,因此需要使用循环才能正确判断:
while (sem_wait(&s) && (errno == EINTR)) { do_nothing(); }
do_critical_region(); /* Semaphore was decremented */有关你可以使用的信号量的函数的完整列表,请参阅 C Library Reference 中的sem_*()函数。
命名信号量和未命名信号量
未命名的信号量用sem_init()进行创建,用sem_destroy()进行销毁。它们可以被同一进程中的多个线程使用。但是,在进程之间使用未命名的信号量需要共享内存对象,这意味着要有很大的内存开销。
命名信号量使用sem_open()创建,并使用sem_close()关闭。与未命名的信号量一样,它们也可以被同一进程中的多个线程使用。然而,与未命名信号量不同的是,命名信号量可以很容易地在不同进程中的线程之间进行共享。
除了匿名的命名信号量之外,命名信号量都有一个路径和一个名称,因此可以在进程之间找到它们,而不需要使用共享内存对象,也不需要为共享内存对象花费隐含的开销。因此,对于进程间通信,命名信号量比未命名信号量更有用。
此外,命名信号量(包括匿名命名信号量)可以通过sigevent(例如,从ISR返回或由服务器交付)进行发布,并且可以在父进程和子进程之间通过fork()共享,而无需共享内存映射。
匿名的命名信号量,不像其他命名信号量那样有路径和名称,但是它们同样具有上面所提到的其他所有优点。有关匿名的命名信号量的更多信息,请参阅C库参考中的sem_open()的内容。
1.5.8. 通过消息传递进行同步
我们的消息传递IPC服务(发送/接收/回复),通过其阻塞特性实现了隐式同步。在许多情况下,这些IPC服务可以使其他同步服务变得不那么必要。它们也是唯一可以在整个网络中使用的同步原语和IPC原语(除了建立在消息传递之上的命名信号量)。
有关更多信息,请参阅下一章中的“Synchronous message passing”中的内容。
1.5.9. 通过原子操作进行同步
在某些情况下,你可能希望执行一个很短的操作(例如增加一个变量),并保证该操作将原子地执行,也就是说,该操作不会被另一个线程或ISR(中断服务例程)抢占。
QNX Neutrino RTOS提供以下原子操作:
- adding a value,【添加值】
- subtracting a value,【减去一个值】
- clearing bits,【清除比特位】
- setting bits,【设置比特位】
- toggling (complementing) bits,【翻转(求补码)比特位】
这些原子操作可以通过包含C头文件<atomic.h>中的函数来实现。
虽然你可以在任何地方使用这些原子操作,但你会发现它们在以下两种情况下会特别有用:
- 在ISR和线程之间
- 两个线程之间(SMP或单处理器)
由于ISR可以在任何给定点抢占线程,线程保护自己的唯一方法就是禁用中断。鉴于你应该避免在实时系统中禁用中断,所以我们建议你使用 QNX Neutrino 所提供的原子操作。
在SMP系统上,多个线程可以并发地运行。同样,我们会遇到与上面的中断相同的情况,你应该在适用的情况下使用原子操作,以消除对禁用中断以及重新启用中断的需求。
1.5.10. 同步服务实现
下表列出了各种微内核调用和由它们所构造的高级的POSIX调用:
| Microkernel call | POSIX call | Description |
| 为互斥锁、条件变量和信号量创建对象 | ||
| 销毁同步对象 | ||
| 在一个条件变量上阻塞 | ||
| 唤醒那些因条件变量阻塞的线程 | ||
| 锁定一个互斥锁 | ||
| 解锁一个互斤锁 | ||
| 发布一个信号量 | ||
| 等待一个信号量 |
1.6. 时钟和定时器服务
时钟服务用于维护一天的时间,而内核定时器调用又使用它来实现间隔定时器。
QNX Neutrino 系统的有效日期范围从1970年1月到至少2038年。time_t 数据类型是一个无符号 32 位数字,它为许多应用程序把这个范围扩展到 2106 年。内核本身使用无符号 64 位数字来计算自 1970年1月以来的纳秒数,因此可以处理到 2554 年的日期。如果你的系统必须在 2554 年之后运行,并且无法在现场对系统进行升级或修改,则必须特别注意系统日期(请与我们联系以获得帮助)。
使用ClockTime()内核调用,允许你获取或设置由ID(CLOCK_REALTIME)所指定的系统时钟,该系统时钟用于维护系统时间。设置后,系统时间根据系统时钟的分辨率增加一些纳秒数。可以使用ClockPeriod()函数调用查询或更改此分辨率,该调用允许你将系统定时器设置为若干纳秒;操作系统内核会尽其所能,用可用的硬件满足所请求的精度。
根据底层硬件定时器的精度,指定分辨率选择的间隔始终四舍五入到整数倍。当然,将其设置为极小值,可能会导致为了服务于定时器中断而消耗很大一部分CPU性能。
在系统页(system page,一个内存中的数据结构)中,有一个64位字段(nsec),用于保存自从系统启动以来的纳秒数值。该字段总是单调递增的,不受通过ClockTime()或ClockAdjust()进行当前时间设置的影响。但可以通过SYSPAGE_ENTRY(qtime)->nsec宏命令访问该字段。
ClockCycles()函数的作用是:返回一个可自由运行的64位周期计数器的当前值。这是在每个处理器上实现的,作为对短时间间隔定时的高性能机制。例如,在Intel x86处理器上,会使用读取处理器时间戳计数器的操作码实现该周期计数器。其他CPU架构也有类似的指令。
在硬件未实现这样的指令的处理器上,内核将会模拟这样一条指令。这个模拟的指令所提供的时间分辨率,会比硬件所提供指令的时间分辨率更低(在IBM pc兼容系统上为838.095345纳秒)。
在所有情况下,SYSPAGE_ENTRY(qtime)->cycles_per_sec字段给出了每秒内ClockCycles()的增量。
QNX Neutrino要求在SMP系统上的所有处理器上同步底层的硬件ClockCycles()。如果不是这样,你可能会遇到一些意想不到的行为,例如时间和定时器的漂移。
ClockId()函数会返回一个特殊的时钟ID,你可以使用它来跟踪进程或线程所使用的CPU时间。有关更多信息,请参阅 QNX Neutrino 程序员指南 “理解微内核的时间概念” 章节中的“Monitoring execution times” 的内容。
| 微内核调用 | POSIX调用 | 描述 |
| 获取或设置一天中的时间(使用64位值,以纳秒为单位,范围从1970到2554年) | ||
| N/A | 应用小的时间调整来同步时钟。 | |
| N/A | 读取64位自由运行的高精度计数器。 | |
| 获取或设置时钟周期 | ||
| 获取进程或线程cpu时钟的时钟ID |
为了减少功耗,内核可以在tickless模式下运行,但tickless这个词有点用词不当。因为系统仍然有时钟滴答声,除非系统处于空闲状态,否则一切还是正常运行。只有当系统完全空闲时,内核才会关闭时钟滴答声,实际上它所做的是减慢时钟,以便下一个滴答声中断恰好发生在下一个活动定时器启动之后,这样定时器就会立即启动。要启用tickless操作,请为startup-*代码指定-Z选项。
1.6.1. 跟踪时间
要保持 QNX Neutrino 时钟跟踪,有以下选项可供你选择:
ClockAdjust()
为了便于对CLOCK_REALTIME应用时间进行校正,而不会使系统在时间上经历突然的“步进”(甚至会出现时间向后跳),ClockAdjust()调用提供了一个选项来指定应用时间校正的间隔。这具有在指定的间隔内加速或延迟时间的效果,直到系统已同步到指定的当前时间。该服务可用于实现网络上多个节点之间的网络协调时间的平均。
libmod_timecc.a
内核模块libmod_timecc.a使用ClockCycles()作为时间源,通过将其值(从启动开始定时的值)转换为纳秒值来更新CLOCK_MONOTONIC。更多信息请参见ClockCycles()。
当发生如下情况时,强烈建议使用libmod_timecc.a:
- 使用高分辨率定时器
- 启用 tickless 操作
- 对于重要周期【nontrivial periods】,任何实体都可能延迟系统在 CPU0 上的 tick
根据系统的需求,你可以决定漂移是否是重要的【nontrivial】。如果需要将系统与外部事件同步,则需要根据典型和最坏的情况,以及负载场景来描述漂移。
要使用libmod_timecc.a,你需要修改目标构建文件以包含libmod_timecc.a内核模块,通过在构建文件包含procnto*的行中添加[module=timecc]前缀:
[module=timecc] PATH=/proc/boot ./procnto-smp-instr -vv
有关更多信息,请参阅mkifs页面中的module属性。
确保将qtime中的timer_prog_time变量设置为零(0)。这可以通过startup-*中的-f选项来完成。请记住,在startup-*中使用-f选项时,不需要设置timer_freq选项。无论是自动设置还是通过命令行设置,QTIME_FLAG_TIMECC标志都不是通过startup-*设置的。内核设置这个标志,只有在procnto运行时才可见。设置此标志时,表示libmod_timecc.a模块正在使用。请参阅qtime了解更多信息。
为了避免干扰模块的时序,不要从其他进程附加任何libmod_timecc.a所使用的中断。只有libmod_timecc.a所使用的定时器硬件可以是同一个中断级别上的中断源。这意味着中断级别不能被共享。在x86_64系统上,该中断源是LAPIC Timer。在Armv8-A系统上,它是Generic Timer。
当使用InterruptHookIdle2()时,_NTO_IH_RESP_SYNC_TIME位被忽略。
有些系统需要特别考虑。对于x86_64系统,执行以下操作:
- 确保目标具有支持
TSC-Deadline模式的本地高级可编程中断控制器(LAPIC,Local Advanced Programmable InterruptController)。 - 配置
startup-*使用LAPIC定时器。 - 确保
intrinfo将LAPIC作为列表中的首个中断控制器。 - 不能在
startup-*中使用-z或-zz选项。
对于Armv8-A系统:
- 配置您的系统使用CPU0的 Generic Timer 作为 system tick。
如果你使用的是QNXOS for Safety,则必须使用libmod_timecc-safety.a。
1.6.2. 定时器
QNX Neutrino RTOS 直接提供了全套的 POSIX 定时器功能。由于这些定时器可以快速创建和操作,因此它们是内核中廉价的资源。
POSIX定时器模型非常丰富,提供了定时器到期的能力:
- an absolute date
- a relative date (i.e., n nanoseconds from now)
- cyclical (i.e., every n nanoseconds)
循环模式非常重要,因为定时器最常见的用途往往是作为事件的周期性触发源,“踢一下”线程进入存活状态,以进行一些处理,然后返回睡眠状态,直到下一个事件发生。如果线程必须为每个事件重新编程定时器,则存在时间滑动的危险,除非线程正在编程一个绝对时间点。更糟糕的是,如果线程没有在定时器事件上运行(因为一个优先级更高的线程正在运行),那么被编程到定时器中的下一次的时间点可能已经过去了!
循环模式通过要求线程设置一次定时器,然后简单地响应生成的周期性事件源,从而避免了这些问题。
由于定时器是操作系统中的另一个事件源,因此它们还利用了操作系统的事件传递系统。因此,应用程序可以请求在发生超时时将任何 QNX neutrino 支持的事件传递给应用程序。
操作系统提供的一个经常需要的超时服务是,能够指定应用程序准备等待任何给定的内核调用或请求完成的最大时间。在抢占式实时操作系统中使用通用操作系统定时器服务的一个问题是,在给定线程的超时规范与其对服务的请求之间的时间间隔内,高优先级的线程可能已经运行并抢占原始线程的时间足够长,以至于在请求服务之前超时就已经过期。然后,应用程序将在已经超时的情况下请求服务(即没有超时)。这个时间窗口可能会导致 “挂起” 进程、数据传输协议出现无法解释的延迟,以及其他问题。
alarm(...);
...
... ← Alarm fires here
...
blocking_call();我们的解决方案是服务请求本身的超时请求原子形式。一种方法可能是为每个可用的服务请求提供一个可选的超时参数,但这会使传递参数的服务请求过于复杂,而这些参数通常不会被使用。
QNX Neutrino 提供了一个TimerTimeout()内核调用,允许应用程序指定一个阻塞状态列表,以启动一个指定的超时。稍后,当应用程序向内核发出请求时,如果应用程序即将阻塞在某个指定的状态上,内核将自动启用先前配置的超时。
由于操作系统的阻塞状态非常少,因此该机制的工作非常简洁。在服务请求或超时结束时,计时器将被禁用,控制权将被交还给应用程序。
TimerTimeout(...);
...
...
...
blocking_call();
... ← Timer atomically armed within kernel| 微内核调用 | POSIX调用 | 描述 |
| 设置进程alarm | ||
| 创建间隔定时器 | ||
| 销毁间隔定时器 | ||
| 获取间隔定时器上的剩余时间 | ||
| 获取间隔定时器上的超时次数 | ||
| 启动间隔定时器 | ||
| sleep(), nanosleep(), sigtimedwait(), pthread_cond_timedwait(), pthread_mutex_trylock() | 为任何阻塞状态“武装”一个内核超时 |
每个 clock tick 最多生成50个定时器事件,以限制对系统资源的消耗。如果系统在相同的 clock tick 内设置了大量的定时器,那么实际上最多有50个定时器事件会准时触发;其余的将在下一个 clock tick 处理(受到最多50个定时器事件的相同限制)。
有关使用定时器的更多信息,请参阅 QNX Neutrino 入门中的 Clocks, Timers, and Getting a Kick Every So Often 章节的内容。
1.7. 中断处理
无论我们多么希望如此,计算机都不是无限快的。在实时系统中,避免不必要地花费CPU周期是至关重要的。从外部事件发生开始,到对该事件负责作出反应的实际代码进行执行,这之间的时间也很重要。这个时间被称为延迟【latency】。
我们最关心的两种形式的延迟是中断延迟【interrupt latency】和调度延迟【scheduling latency】。
根据处理器的速度和其他因素,延迟时间可能会有很大的不同。更多信息,请访问我们的网站(www.qnx.com)。
1.7.1. Interrupt latency
中断延迟【Interrupt latency】是从硬件中断断言到设备驱动程序的中断处理程序的第一条指令被执行的时间。
操作系统几乎一直使中断完全启用,因此中断延迟通常是微不足道的。但是某些关键部分的代码确实要求暂时禁用中断。这种禁用时间的最大值通常定义了最坏情况下的中断延迟,在QNX Neutrino中,这是非常小的。
下面的图表说明了硬件中断由已建立的中断处理程序【interrupt handler】进行处理的情况。中断处理程序要么简单返回,要么返回并导致事件被交付。
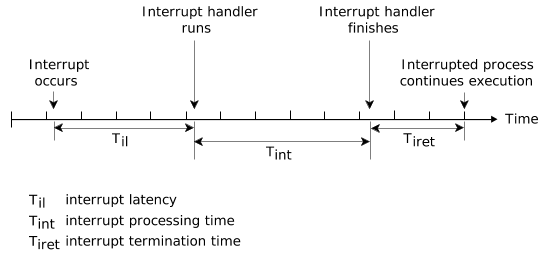
上图中的中断延迟(Til)表示最小延迟,也就是启用中断的情况下中断发生时的最小延迟。最坏情况下的中断延迟将是这个时间加上操作系统或正在运行的系统进程禁用CPU中断的最长时间。
1.7.2. Scheduling latency
在某些情况下,低级别的硬件中断处理程序必须安排一个高级线程进行运行。在这种情况下,中断处理程序将返回并指示要交付一个事件。这引入了第二种形式的延迟,也就是调度延迟【Scheduling latency】。
调度延迟是用户的中断处理程序的最后一条指令和执行驱动程序线程第一条指令之间的时间。这通常意味着保存当前执行线程的上下文和恢复所需驱动线程的上下文所需的时间。虽然这个时间大于中断延迟,但在QNX Neutrino系统中也保持较小。
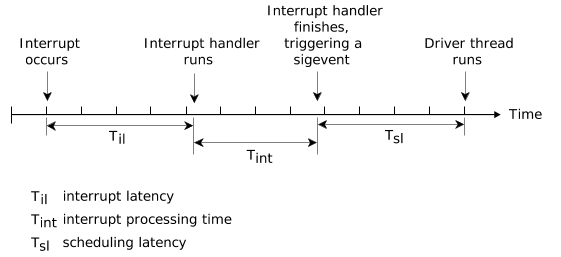
需要注意的是,大多数中断在没有交付事件的情况下终止。在很多情况下,中断处理程序可以处理所有与硬件相关的问题。只有在发生重大事件时,才会交付事件以唤醒高级驱动线程。例如,串行设备驱动程序的中断处理程序会在每次接收到传输中断时向硬件提供一个字节的数据,并且只有在输出缓冲区几乎为空时才会触发串行设备驱动程序(devc-ser*)中的高级别线程。
1.7.3. 中断嵌套【Nested interrupts】
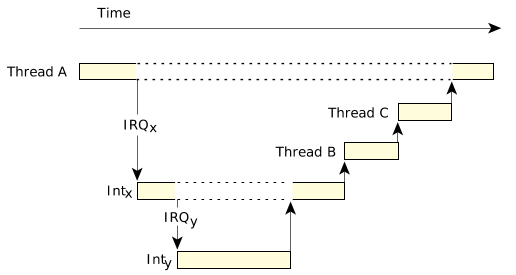
QNX Neutrino RTOS完全支持中断嵌套。
前面的场景描述了只发生一个中断的情况,是最简单也是最常见的情况。考虑到非屏蔽中断最坏情况的时间要求,必须把当前正在处理的所有中断的时间都考虑进来,因为更高优先级的非屏蔽中断将抢占现有中断。
在下面的图中,线程A正在运行。中断IRQx导致中断处理程序Intx运行,它被IRQy和它的处理程序Inty抢占。Inty返回导致线程B运行的事件;Intx返回一个导致线程C运行的事件。只有在两个中断处理程序返回的事件触发的线程运行之后,线程A才能恢复运行。
1.7.4. 中断调用
中断处理API包括以下内核调用:
| 函数 | 描述 |
| 将某个本地函数(中断服务程序或ISR)附加到中断向量上。 | |
| 在中断上生成一个事件,该事件会使某个线程就绪。此方法不需要用户中断handler运行。 这是首选函数调用。 | |
| 使用InterruptAttach()或InterruptAttachEvent()返回的ID,解除对指定中断的附加。 | |
| 等待某个中断。 | |
| 使能硬件中断。 | |
| 禁用硬件中断。 | |
| 屏蔽某个硬件中断。 | |
| 解除对某个硬件中断的屏蔽。 | |
| 保护中断处理程序和线程之间的代码临界段。通过使用自旋锁使代码成为SMP-safe的。该函数是InterruptDisable()的超集,应该用该函数代替对InterruptDisable()的使用。 | |
| 移除代码临界段上的SMP-safe锁。 |
要使用这个API,适当的特权用户级线程可以调用InterruptAttach()或InterruptAttachEvent()函数,传递硬件中断号,并传递要在中断发生时调用的函数在线程地址空间中的地址。QNX Neutrino 允许对每个中断向量号附加多个 ISR 程序,在中断处理程序的执行期间,为未屏蔽的中断提供服务。
- 启动代码负责确保在系统初始化期间屏蔽所有中断源。当对中断向量的第一次调用
InterruptAttach()或InterruptAttachEvent()完成时,内核将解除对该中断的屏蔽。类似地,当最后一次对中断向量执行InterruptDetach()时,内核会重新屏蔽该级别的中断。 - 你禁用中断的时间应该尽可能短(即,访问或处理硬件所需的最短时间)。如果不这样做,可能会导致中断延迟增加,无法满足实时性要求。
- 某些内核调用和库例程会重新启用中断。屏蔽中断不起作用。
- 有关
InterruptLock()和InterruptUnlock()的更多信息,请参见本指南的多核处理章节中的“Critical sections”的内容。 - (QNX Neutrino 7.1或更高版本)内核在进入和离开 ISR 时会保存和恢复 FPU 上下文,因此在其中使用浮点操作是安全的。
下面的代码示例展示了如何将 ISR 附加到 PC 上的硬件定时器中断(也被 OS 用作系统时钟)。由于内核的计时器 ISR 已经执行了清除中断源的处理,因此该 ISR 只是在线程的数据空间中增加一个计数器变量并返回内核:
#include <stdio.h>
#include <sys/neutrino.h>
#include <sys/syspage.h>
#include <sys/procmgr.h>
struct sigevent event;
volatile unsigned counter;
const struct sigevent *handler( void *area, int id ) {
// Wake up the thread every 100th interrupt
if ( ++counter == 100 ) {
counter = 0;
return( &event );
}
else
return( NULL );
}
int main() {
int i;
int id;
// Initialize event structure
event.sigev_notify = SIGEV_INTR;
// Enable the INTERRUPT ability
procmgr_ability(0,
PROCMGR_ADN_ROOT|PROCMGR_AOP_ALLOW|PROCMGR_AID_INTERRUPT,
PROCMGR_AID_EOL);
// Attach ISR vector
id=InterruptAttach( SYSPAGE_ENTRY(qtime)->intr, &handler,
NULL, 0, 0 );
for( i = 0; i < 10; ++i ) {
// Wait for ISR to wake us up
InterruptWait( 0, NULL );
printf( "100 events\n" );
}
// Disconnect the ISR handler
InterruptDetach(id);
return 0;
}使用这种方法,具有适当特权的用户级线程,可以在运行时动态地将中断处理程序附加到硬件中断向量上(以及进行动态分离)。这些用户级线程可以使用常规的源代码调试工具进行调试;ISR本身可以通过线程级别的调用,以及源代码级别的逐级调用,或使用InterruptAttachEvent()调用,来进行调试。
当硬件中断发生时,处理器将进入微内核中的中断重定向器。这段代码会把当前正在运行的线程上下文的寄存器推入到适当的 thread table entry 中,并设置处理器上下文【线程上下文入栈】,为 ISR 所在线程的运行做准备。这种方法允许 ISR 使用用户级线程中的缓冲区和代码来处理中断,如果需要线程执行更高级别的工作,则可以为 ISR所属线程的排队一个事件。然后,这个线程就可以处理被 ISR 从ISR程序中放入到线程缓冲区中的数据。
因为 ISR 运行在它所属线程的内存映射中,所以 ISR 可以直接操作被映射到线程地址空间的设备,或者直接执行I/O指令。因此,操作硬件的设备驱动程序不需要链接到内核中。
微内核中的中断重定向器代码将会调用附加到该硬件中断的每个ISR。如果 ISR 的返回值表明进程会被传递某种类型的事件,内核会把该事件放入到队列中。当调用该中断向量上的最后一个ISR 时,内核中断处理程序将完成对中断控制硬件的操作,然后“从中断返回”。
这个“中断返回”不一定会返回到原先被中断线程的上下文中。如果队列中的事件导致高优先级线程变为READY状态,那么微内核将会从中断返回到现在READY的线程的上下文中。
这种方法提供了一个边界良好的分隔,从中断的发生到用户级 ISR 的第一条指令的执行(作为中断延迟来衡量),以及从 ISR 的最后一条指令再到 ISR 中导致线程就绪的第一条指令(作为线程或进程调度延迟来衡量)。
最坏情况下的中断延迟是有界限的,因为操作系统只会对少数几个临界区的几个操作码进行禁用中断的操作。禁用中断的时间间隔运行时具有确定性,因为它们不依赖于数据。
微内核的中断重定向器在调用用户的ISR之前只执行几个指令。因此,硬件中断的进程抢占或内核调用的进程抢占都是一样快的,并且基本上使用相同的代码路径。
ISR在执行时具有完全的硬件访问权限(因为它是特权线程的一部分),但不能发出其他内核调用。ISR的目的是在尽可能少的微秒级别时间内响应硬件中断,做最少的工作来满足中断需求(例如,从UART读取字节),并且,如果有必要的话,可以拉起一个线程,在一些用户指定的优先级上做进一步的工作。
对于给定的硬件优先级,最坏情况下的中断延迟,可以直接从内核所施加的中断延迟以及每个中断的最大 ISR 运行时间中计算得出(算在范围内的每个中断的硬件优先级,高于所讨论ISR的硬件优先级,也就是发生中断嵌套的情况)。由于硬件中断优先级可以重新分配,系统中最重要的中断可以被设置为最高优先级。
还要注意,通过使用InterruptAttachEvent()调用,不会运行任何用户的ISR程序。相反,在每个中断上生成一个用户指定的事件;该事件通常会导致一个等待线程被安排运行并完成工作。当事件生成时,中断被自动屏蔽,然后由处理该设备的线程在适当的时间显式地解除屏蔽【需要在事件处理程序中解除中断屏蔽】。
InterruptMask()和InterruptUnmask()都是计数函数【counting】。例如,如果InterruptMask()被调用十次,那么InterruptUnmask()也必须被调用十次。
因此,由硬件中断生成的工作的优先级,可以在操作系统调度的优先级上执行,而不是在硬件定义的优先级上执行【意思是实际工作可以转移到线程优先级顺序上执行,而不是只能在中断的硬件优先级上进行执行】。由于中断源在服务之前不会重新中断,因此关于硬实时调度方面,对临界代码区域的运行时的影响,可以得到有效控制。
除了硬件中断之外,微内核中的各种“事件”也可以被用户进程和线程“钩住”。当其中一个事件发生时,内核可以向上调用用户线程中指定的函数,对该事件执行一些特定的处理。例如,无论何时调用系统中的空闲线程,用户线程都可以对该线程进行内核向上调用,以便可以轻松实现特定于硬件的低功耗模式。
| Microkernel call | Description |
| 当内核没有活动线程要调度时,它运行空闲线程,该线程可以调用用户处理程序。这个处理程序可以执行特定于硬件的电源管理操作。 | |
| 这个函数附加了一个伪中断处理程序,该处理程序可以从仪表化内核接收跟踪事件。 |
有关中断的更多信息,请参阅QNX Neutrino入门中的“Interrupts”章节,以及QNX Neutrino程序员指南中的“Writing an Interrupt Handler”章节。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











