







目录
概述
- 为什么要链路追踪
如果能跟踪每个请求,中间请求经过哪些微服务,请求耗时,网络延迟,业务逻辑耗时等。我们就能更好地分析系统瓶颈、解决系统问题。因此链路跟踪很重要。
我们自己思考解决方案:在调用前后加时间戳。捕获异常。
链路追踪目的:解决错综复杂的服务调用中链路的查看。排查慢服务。
市面上链路追踪产品,大部分基于google的Dapper论文。
-
探针的性能消耗。尽量不影响 服务本尊。
-
易用。开发可以很快接入,别浪费太多精力。
-
数据分析。要实时分析。维度足够。
sleuth简介
Sleuth是Spring cloud的分布式跟踪解决方案。
-
span(跨度),基本工作单元。一次链路调用,创建一个span,
span用一个64位id唯一标识。包括:id,描述,时间戳事件,spanId,span父id。
span被启动和停止时,记录了时间信息,初始化span叫:root span,它的span id和trace id相等。
-
trace(跟踪),一组共享“root span”的span组成的树状结构 称为 trace,trace也有一个64位ID,trace中所有span共享一个trace id。类似于一颗 span 树。
-
annotation(标签),annotation用来记录事件的存在,其中,核心annotation用来定义请求的开始和结束。
-
CS(Client Send客户端发起请求)。客户端发起请求描述了span开始。
-
SR(Server Received服务端接到请求)。服务端获得请求并准备处理它。SR-CS=网络延迟。
-
SS(Server Send服务器端处理完成,并将结果发送给客户端)。表示服务器完成请求处理,响应客户端时。SS-SR=服务器处理请求的时间。
-
CR(Client Received 客户端接受服务端信息)。span结束的标识。客户端接收到服务器的响应。CR-CS=客户端发出请求到服务器响应的总时间。
-
其实数据结构是一颗树,从root span 开始。
链路追踪
1. 依赖包。需要追踪的系统都需要以来该start
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>2. 配置完成后,启动服务
配置前

配置后

发一笔请求
配置前

配置后
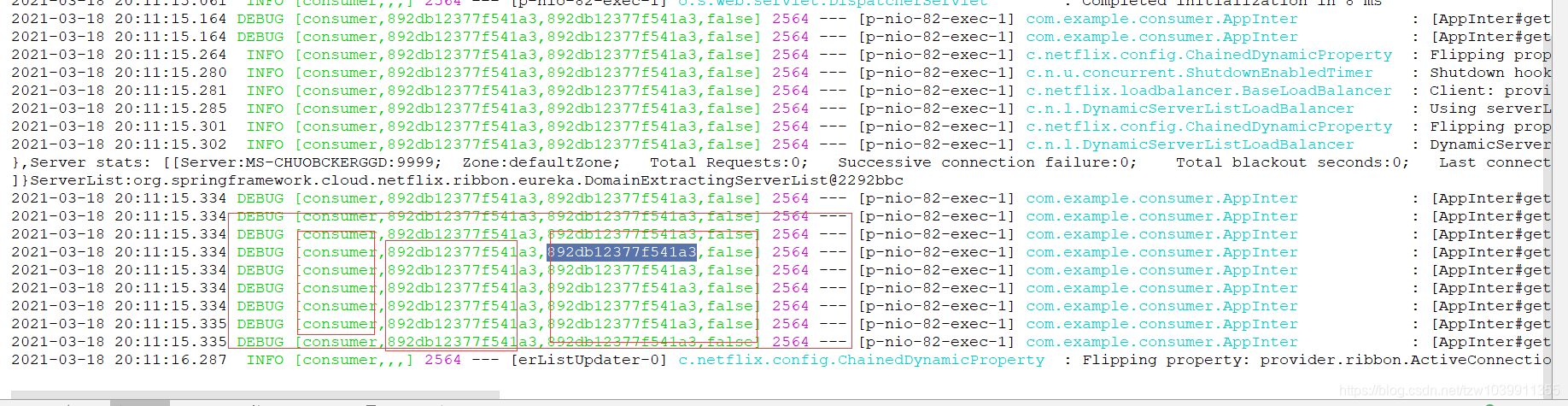
3. 通过比较,发现配置后,发生了变化。通过这些日志能够看出,是调用了Server:MS-CHUOBCKERGGD:9999服务,等等其他的信息。但是看的不明显,引入zpkin
Server stats: [[Server:MS-CHUOBCKERGGD:9999; Zone:defaultZone; Total Requests:0; Successive connection failure:0; Total blackout seconds:0; Last connection made:Thu Jan 01 08:00:00 CST 1970; First connection made: Thu Jan 01 08:00:00 CST 1970; Active Connections:0; total failure count in last (1000) msecs:0; average resp time:0.0; 90 percentile resp time:0.0; 95 percentile resp time:0.0; min resp time:0.0; max resp time:0.0; stddev resp time:0.0]
]}ServerList:org.springframework.cloud.netflix.ribbon.eureka.DomainExtractingServerList@2292bbc
[api-driver,1a409c98e7a3cdbf,1a409c98e7a3cdbf,true]
[服务名称,traceId(一条请求调用链中 唯一ID),spanID(基本的工作单元,获取数据等),是否让zipkin收集和展示此信息]看下游
[service-sms,1a409c98e7a3cdbf,b3d93470b5cf8434,true]traceId, 是一样的。
服务名必须得写。
4. zipkin原理
原理:
sleuth收集跟踪信息通过http请求发送给zipkin server,zipkin将跟踪信息存储,以及提供RESTful API接口,zipkin ui通过调用api进行数据展示。
默认内存存储,可以用mysql,ES等存储。
5. zipkin 依赖包
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
6. zipkin配置 ,zipkin地址。
#zipkin
spring.zipkin.base-url=http://localhost:9411/
#采样比例1
spring.sleuth.sampler.rate=17. 需要一个zipkin服务器,他是一个独立界面
下载zipkin,登录zipkin官网 zipkin.io,找quickstart,找java,然后下载,如果下载比较慢的话,就复制链接,用迅雷下载
下载完毕,启动。
java -jar zipkin.jar
或者docker:
docker run -d -p 9411:9411 openzipkin/zipkin
启动界面,浏览器输入http://localhost:9411/
发一笔请求,点搜索
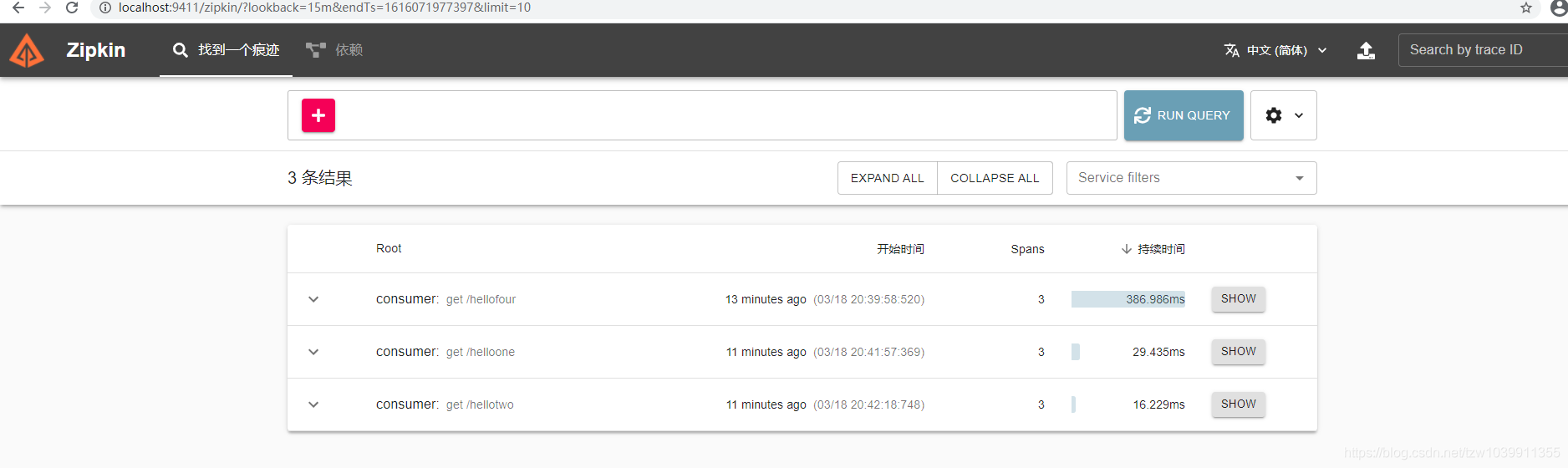
这样就可以使用了。
总结:
微服务加入链路追踪
1. sleuth 依赖
2. zipkin 依赖
3. 配置文件中配置将zipkin的地址,sleuth采集比例
4.需要zipkin的jar包
以上4步,就可以进行链路追踪了。 配置起来很简单吧

















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









