




先来尝试一下爬取京东的网站,网页信息如下:
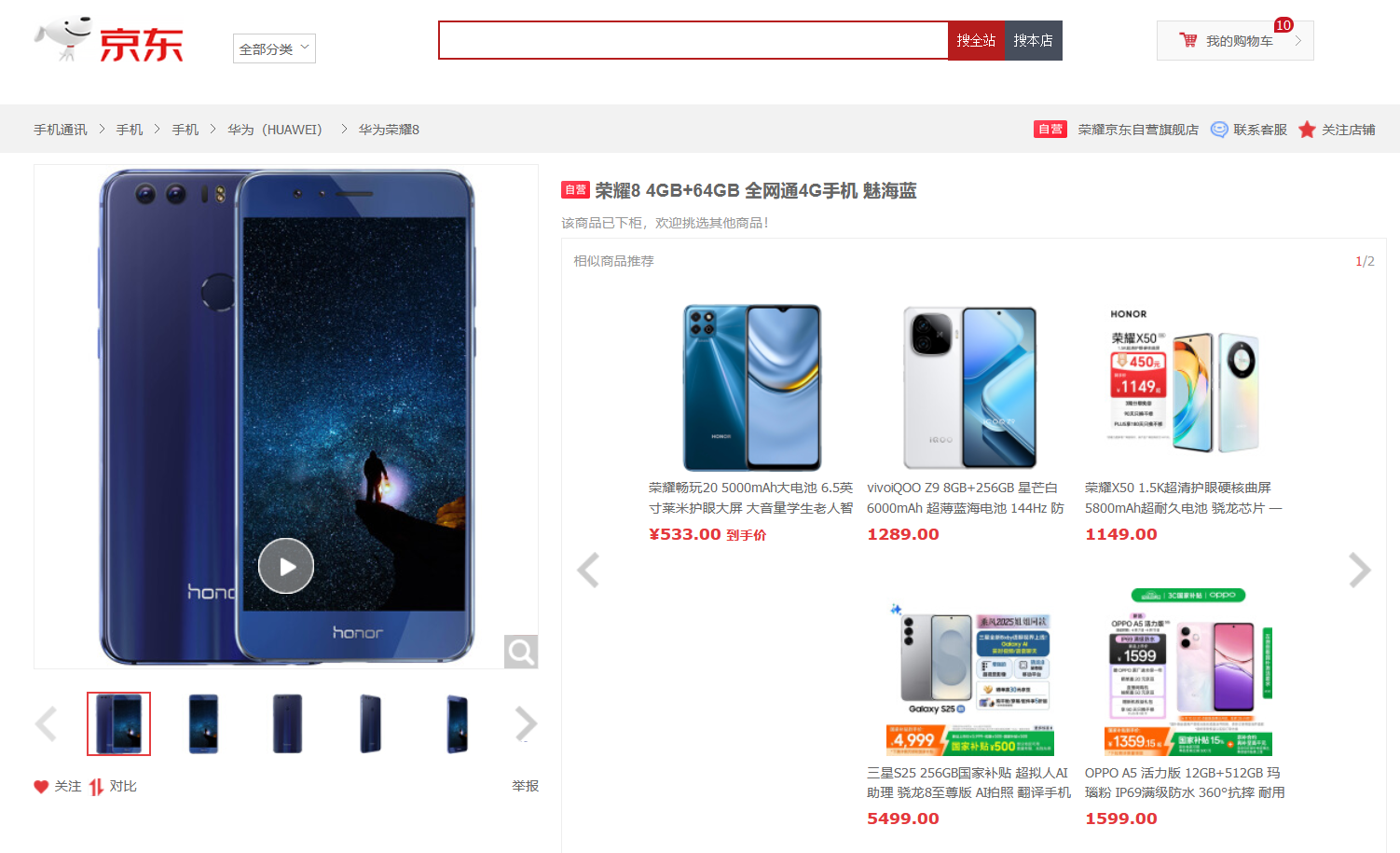
爬取代码1
import requests
url='https://item.jd.com/2967929.html'
try:
r=requests.get(url)
r.raise_for_status() #如果状态不是200,引发HTTPError异常
r.encoding=r.apparent_encoding
print(r.text[:1000])
except:
print ("爬取失败")可以看到只爬取到了head标题信息,没有爬取到网页的实质内容
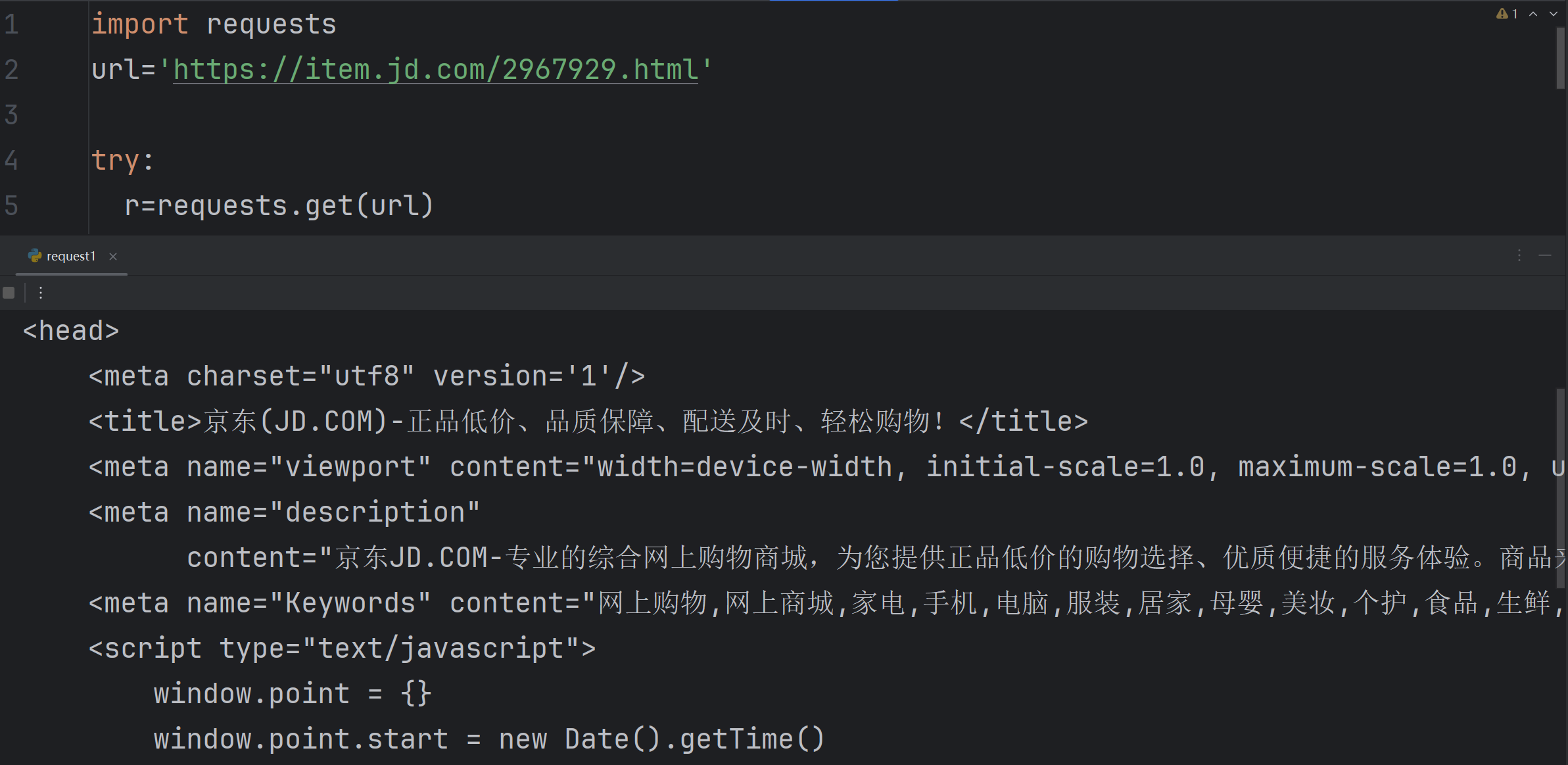
当我们换一个网站的时候,会发现出现了部分网页信息
http://www.rj-jwb.com.cn/spiderbook/chapter5/
原始网页如下:
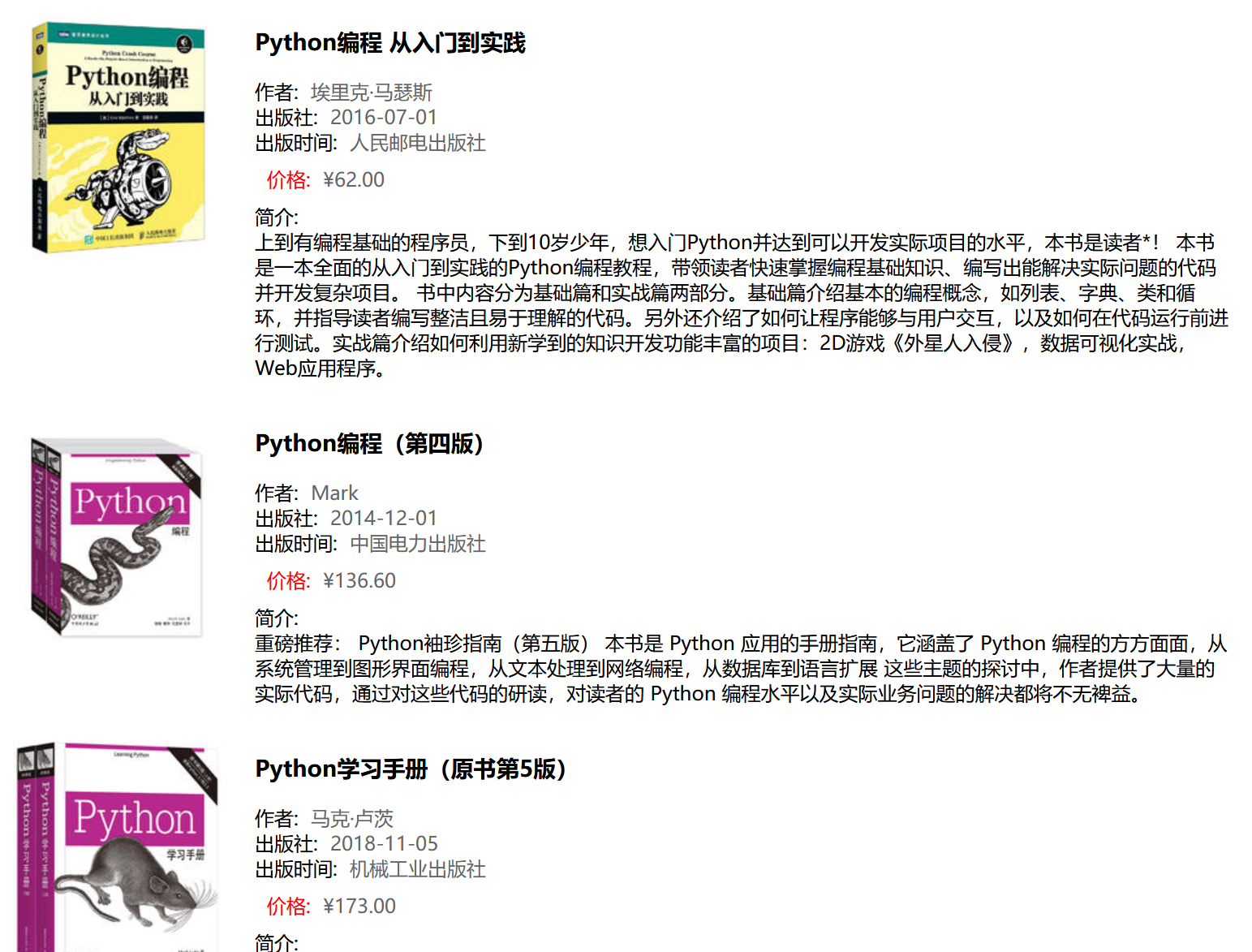
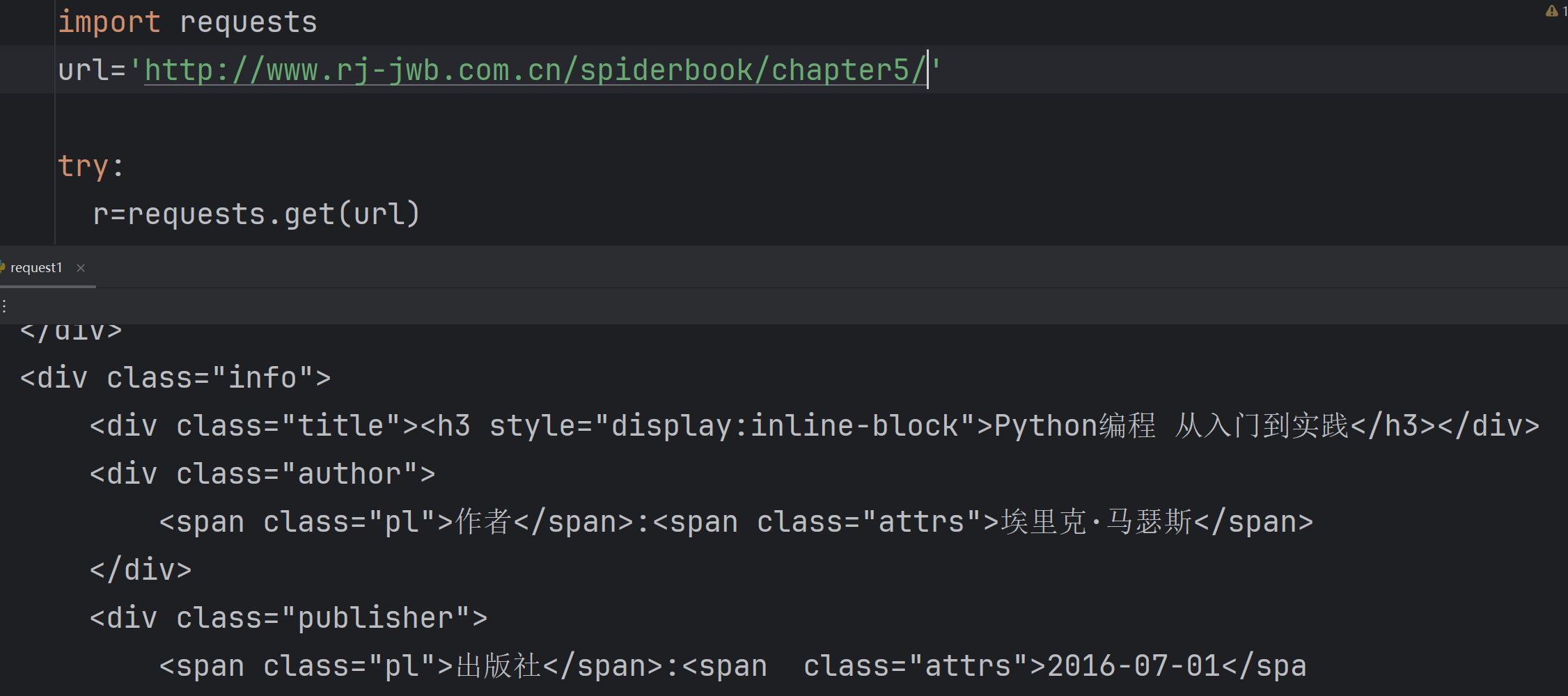
继续尝试爬取亚马逊https://www.amazon.cn/gp/product/B01M8L5Z3Y
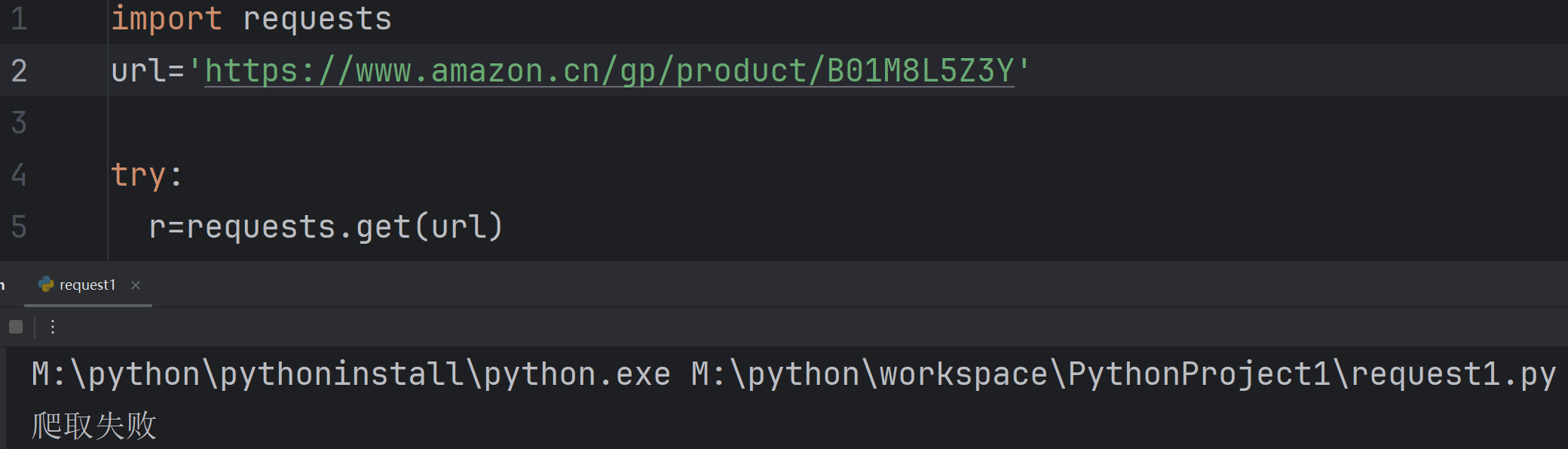
结果爬取失败,这个需要用到其他知识。后续再学。
查询一下headers发现爬虫如实的向网页汇报了是python提出的申请
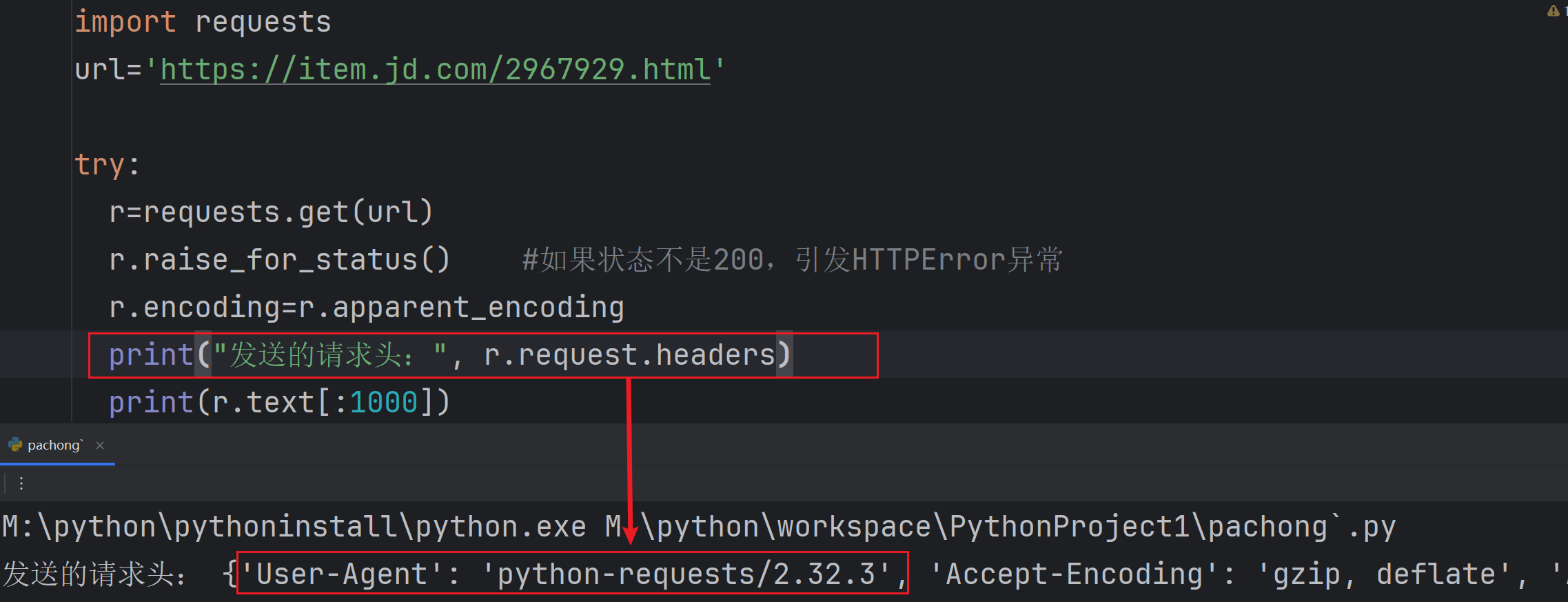
import requests
url='https://item.jd.com/2967929.html'
try:
r=requests.get(url)
r.raise_for_status() #如果状态不是200,引发HTTPError异常
r.encoding=r.apparent_encoding
print("发送的请求头:", r.request.headers)
print(r.text[:1000])
except:
print ("爬取失败")☆☆爬取代码2(请求头模拟浏览器)
如果我们能模拟浏览器,应该可以绕过网站限制。这里Mozilla/5.0是代表chrome、firefox等浏览器的通用写法。这是用构建键值对 kv={'user-agent':'Mozilla/5.0'}的方法
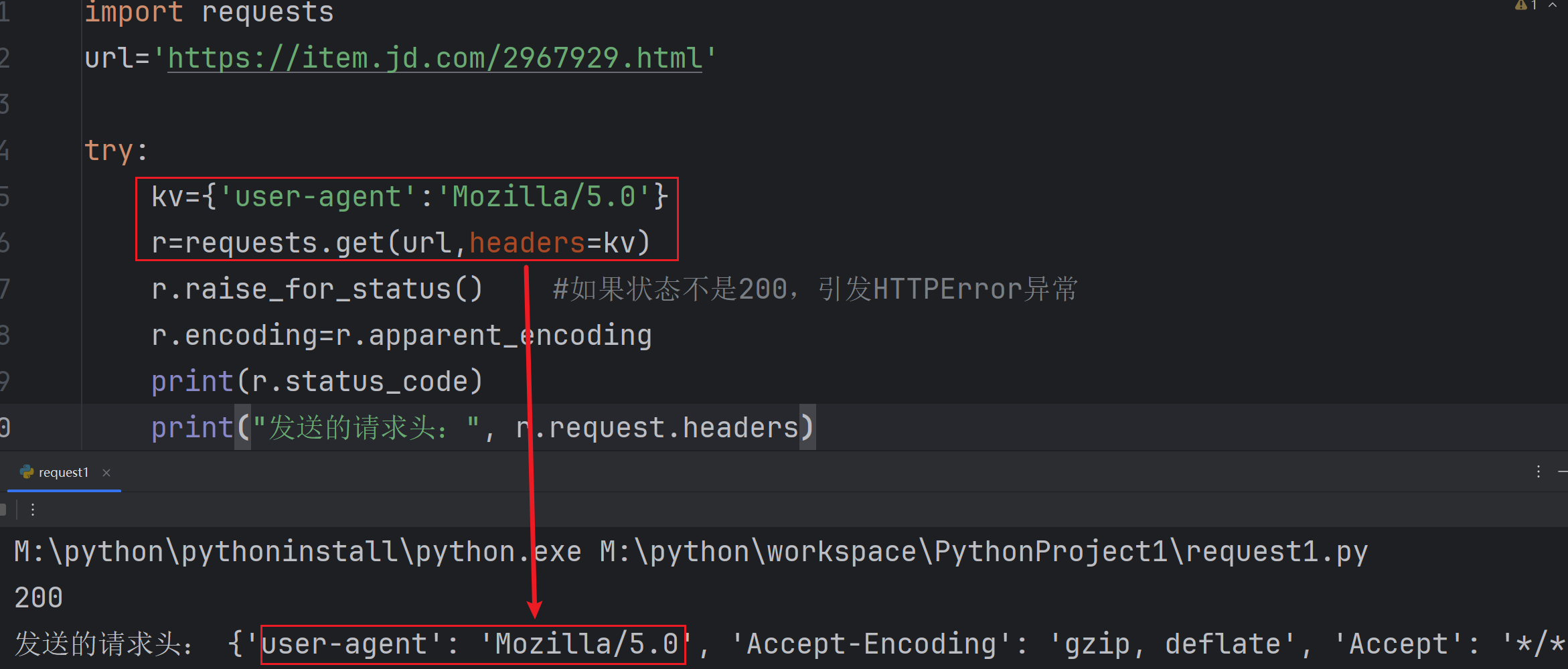
import requests
url='https://item.jd.com/2967929.html'
try:
kv={'user-agent':'Mozilla/5.0'}
r=requests.get(url,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.status_code)
print("发送的请求头:", r.request.headers)
print(r.text[1000:2000])
except:
print ("爬取失败")
这次我们尝试了爬取网站的内容,但是有时会遇到请求失败。本次主要学到了用构建键值对请求头模拟浏览器的方法可以更改提交给网页的信息。
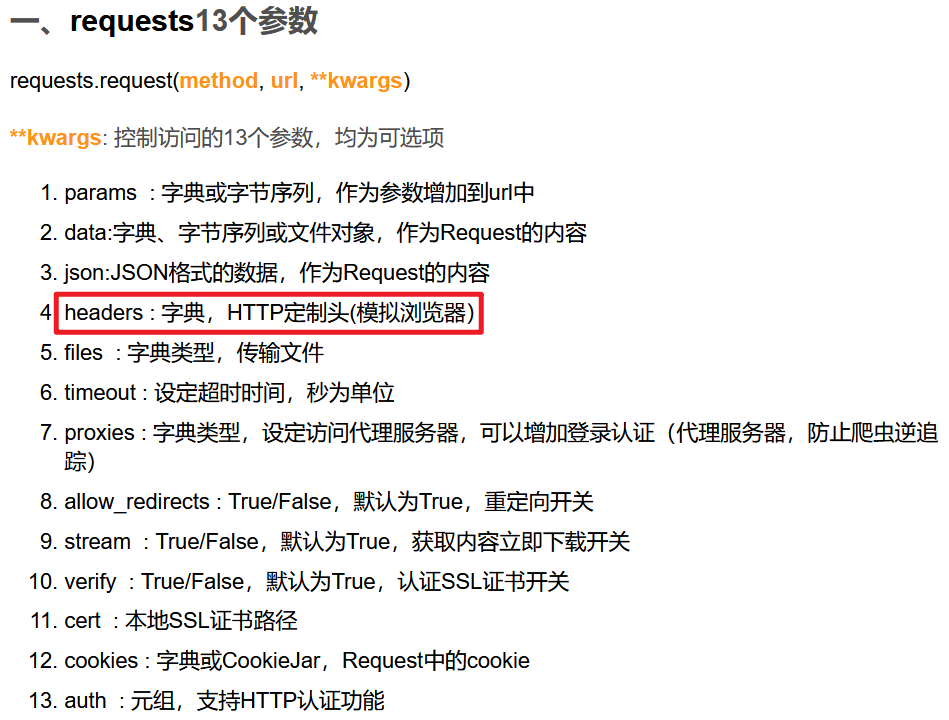
这就是上次学到requests的参数headers的作用~

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









