




 本文深入探讨了数据库并发管理的关键概念,包括事务(transaction)、并发控制以及多版本并发控制(MVCC)。事务是数据库操作的基本单元,确保数据的准确性和安全性。并发管理通过加锁策略防止数据冲突,如共享锁和互斥锁,但加锁可能导致死锁和效率问题。多版本控制则允许只读事务无需加锁,提高读取效率,通过日志机制实现不同版本的数据读取,从而避免写-读和读-写冲突。这一策略在高并发环境中尤为重要。
本文深入探讨了数据库并发管理的关键概念,包括事务(transaction)、并发控制以及多版本并发控制(MVCC)。事务是数据库操作的基本单元,确保数据的准确性和安全性。并发管理通过加锁策略防止数据冲突,如共享锁和互斥锁,但加锁可能导致死锁和效率问题。多版本控制则允许只读事务无需加锁,提高读取效率,通过日志机制实现不同版本的数据读取,从而避免写-读和读-写冲突。这一策略在高并发环境中尤为重要。
一个好的数据库,其特点必然是吞吐量高,也就是它能在高并发请求压力下保证数据的准确性和安全性,由此并发管理是不可或缺的一环。事实上并发管理是一个相当复杂的计算机科学领域的课题,它几乎可以自成一格领域,是能够与操作系统,编译原理比肩,完全可以成为计算机科学中的支柱性存在,因此它自身也有着丰富且复杂的理论基础,在这里我们就接触一下它的皮毛。
在前面章节中,我们提到一个叫”交易“或者是”事务“的概念,事实上它本质是一组提交给数据库系统的命令,这些命令依次执行以便完成一个具体的目标。我们需要在对”交易“进行逻辑上的描述,这样我们才有思考的材料。第一种描述方法是详细描述其读写过程,例如记录它一次读取了哪个数据,写入哪个数据,例子如下:
tx1: setInt(blk, 80, 1, false)
setString(blk, 40, "one", false)
tx2: getInt(blk, 80);
getString(blk, 40);
setInt(blk, 80, newival, true);
setString(blk, 40, newsval, true);
第二种描述方法是对对第一种方法的简化,它仅仅描述对特定区块的读写操作,例如:
tx1: W(blk1); W(blk2);
tx2: R(blk1); R(blk2); W(blk3); W(blk4);
第二种方法仅仅记录在特定区块上的操作,同时忽略具体的操作内容。所谓”交易“实际上就是两种方式所描述的操作的集合。在思考并发管理时,我们需要想象程序给数据库系统提交了一系列的命令,如果程序提交的命令能依次运行, 例如下面:
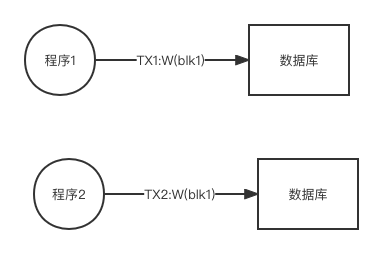
这种情况不难处理,数据库系统依次执行给定命令即可,但是下面的情况就麻烦了:

上面的情况是,两个交易同时将同一个区块的写命令提交给数据库,那么后者该执行哪个命令先,不同的执行次序就会导致不同的数据结果。所谓并发管理就是一种如何处理情况2的方法,它要求对同时抵达的处理命令进行调度或安排,使得执行命令在执行后得到某种特定的结果。
当我们面临情况2时会产生一种模糊,那就是如何定义”正确“,我们到底是先值程序1的请求还是现执行程序2的请求,不同的选择会导致不同的结果,那么哪种结果可以是认为“正确”呢,我们这里需要建立一种客观条件来判断结果的正确性。由此我们回到情况1,也就是假想所有交易的步骤都是单独无干扰的进行,也就是假设当一个交易启动时,它向数据库发送命令期间没有其他交易在进行,也就是我们设想当一个交易启动后,它会独占整个数据库。也就是数据库每次只执行一个交易的命令,当它把当前交易的命令全部执行完毕后才去执行另一个交易的命令,于是当程序1和程序2 同时向数据库发送交易命令时,假设数据库把程序2的命令请求全部缓存起来,一直到程序1的交易完成后再依次执行程序2的交易命令,我们把这种调度叫做序列调度。
在序列调度的前提下我们可以定义”正确性“,假设我们有两个交易:
T1: W(b1),W(b2)
T2:W(b1),W(b2)
假设T1在执行W(b1)时,它写入的数据是X, T2在执行W(b1)时写入Y,那么哪个交易先调度所得结果就会不同,如果先调度T1,那么两个交易执行完毕,区块b1包含的数据就是Y,如果先调度T2,那么b1包含的结果就是X,那么哪一种
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









