






 本文深入探讨了可变编解码器在现代人工智能中的应用,特别是其在人脸交换技术上的独特能力。文章详细解释了如何将图片特征映射到概率空间,并通过随机采样实现特性组合,如生成具有特定眼皮类型的人脸。此外,还介绍了高维正太分布函数在特征编码中的作用,以及如何训练编码器和解码器以实现精确的图像还原。
本文深入探讨了可变编解码器在现代人工智能中的应用,特别是其在人脸交换技术上的独特能力。文章详细解释了如何将图片特征映射到概率空间,并通过随机采样实现特性组合,如生成具有特定眼皮类型的人脸。此外,还介绍了高维正太分布函数在特征编码中的作用,以及如何训练编码器和解码器以实现精确的图像还原。
现代人工智能技术能神乎其神的将一个人的脸严丝合缝的移植到另一个人的照片或视频里,类似于ZAO这类风靡一时的应用就能让用户将指定头像切换到一段视频中的对应角色里,而且表情变化看不出任何违和感,我们本节提到的可变编解码器就能实现类似功能。
前面章节我们创建的编码器是将一张图片映射为二维空间中一个点,然后让解码器读取该点后将图片还原,它的问题在于如果我们将该点值稍微做一些更改,那么解码器将无法还原回原来图片。可变编解码器特点是将图片映射到指定概率空间,这样一来我们在该空间内无论取哪一点,解码器都能把图片还原回来,因此相较于原来编解码器,可变编解码器对输入图片的编码特色如下图所示:
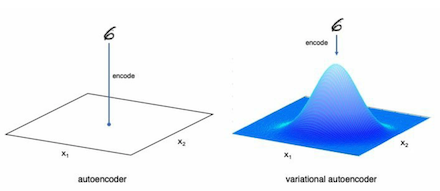
通常情况下,我们会将图片映射到正太分别函数对应的概率空间,上图右边的钟型图像就是二维正太分布函数图像,它就像一口倒挂的钟,我们在这口钟在二维平面上的投影图像里任取一点输入到解码器都可以把图片还原回来。这种做法的好处在于我们能方便将各种要素进行组合,例如我们可以把双眼皮和单脸皮两种特性分别映射到空间[0,0.5]和[0.5, 1.0],这样我们就可以通过使用一个随机数来决定生成人脸的眼皮,如果生成的随机数小于0.5,那网络在生成人脸时使用单眼皮,要不然就使用双眼皮。
在神经网络开发中,我们时常要涉及到对高维数据的运算,例如我们要对人脸进行编码时我们需要将它转换为含有d个数值的向量,其中每个数值用于表示人脸的某个特征,同时我们让每个数值按照单值正太概率函数图形方式进行映射。单值正太分布函数图像如下:
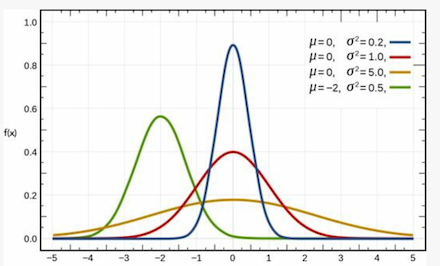
它由两个关键参数决定,一个是均值u,一个是方差𝞼,其中区间[u-𝞼,u+𝞼]占据整个区间的60%以上,而[u-2𝞼,u+2𝞼]占据整个区间90%以上,这样网络就可以把常见特征映射到区间[u-𝞼,u+𝞼],少见的特征映射到该区间之外,例如发色,黑色白色最常见,那么我们就使用区间[u-𝞼,u+𝞼]中的数组来表示,金色和绿色非常少见,那么我们就使用[u-𝞼,u+𝞼]之外的数值来表示,这样网络在生成人脸时,60%以上的概率会让人脸拥有黑色会白色头发,而不到30%的概率让人脸拥有金色或绿色的头发,由此可见将某个特征映射到连续区间有利于我们通过采样以随机的方式来决定特性的具体表现。
我们看看高维正太分布函数的具体形式:
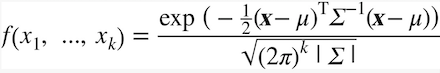
由于我们面对的是二维情况,因此上面公式中k=2,同时有:
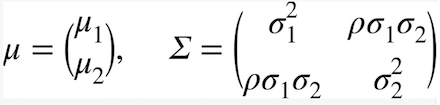
上面两个变量对正太分布起到决定性作用,其中u1,𝞼1,u2,𝞼2分布对应第一个和第二个变量的均值和方差,于是我们要训练编码器在接收图片后输出两个向量分布是u=[u1,u2]和𝞼 = [𝞼1,𝞼2],这两个向量一旦确定,那么相应的正太分布概率函数就确定,接下来我们就要进行随机采样,具体做法是通过u=0,𝞼=1的正太分布函数生成一个随机值ε,然后计算z=u+ε*𝞼,该向量再输入给解码器,让它生成输入编码器的图片,这样训练出来的解码器就能将满足u=[u1,u2]和𝞼 = [𝞼1,𝞼2]二维正太分布区间内任一点转换为给定图片。
在实践中我们通常让编码器生成𝞼’ = lg(𝞼 )=[log(𝞼1),log(𝞼2)],因此在采样时计算要稍微做一些改变,那就是z = u + ε*exp(𝞼’ /2),接下来我们看看可变编解码器的代码实现:
class VariationalEncoder():
....
def _build(self):
....
self.mu = Dense(self.z_dim, name = "mu")(x) #生成均值向量
self.log_var = Dense(self.z_dim, name="log_var")(x) #生成方差向量
self.encoder_mu_log_var = Model(encoder_input, (self.mu, self.log_var))
def sampling(args):#利用u=0,var=1的正太分布函数生成一个随机数以便进行采样
mu, log_var = args
epsilon = K.random_normal(shape = K.shape(mu), mean = 0., stddev = 1.)
encoder_output = self.mu + epsilon * K.exp(log_var / 2)
return encoder_output
encoder_output = Lambda(sampling, name = "encoder")([self.mu, self.log_var])
self.encoder = Model(encoder_input, encoder_output)
self.model.summary()
def compile(self, learning_rate, r_loss_factor):
self.learning_rate = learning_rate
optimizer = Adam(lr = learning_rate)
def vae_r_loss(y_true, y_pred): #输出图像与输入图像像素点差值的平方和越小表示网络解码后恢复的图像越好
return K.mean(K.square(y_true - y_pred), axis = [1,2,3]) * r_loss_factor
def vae_kl_loss(y_true, y_pred):
kl_loss = -0.5 * K.sum(1 + self.log_var - K.square(self.mu) - K.exp(self.log_var), axis = 1)
return kl_loss
self.model.compile(optimizer = optimizer, loss = r_loss)
....
....
上面显示代码是本节代码与上一节不同之处,需要注意的是kl_loss,它使用信息论中的卡尔贝克-洛贝格公式来判断编码器生成的两个向量所决定的概率函数是否与标准正太分布函数足够接近,此处我们暂时忽略掉它的数学原理,接着我们启动网络的训练过程:
LEARNING_RATE = 0.0005
R_LOSS_FACTOR = 1000
vae.compile(LEARNING_RATE, R_LOSS_FACTOR)
BATCH_SIZE = 32
EPOCHS = 200
PRINT_EVERY_N_BATCHES = 100
INITIALIZE_EPOCH = 0
vae.train(x_train, batch_size = BATCH_SIZE, epochs = EPOCHS,
print_every_n_batches = PRINT_EVERY_N_BATCHES,
run_folder = 'C:\\Users\\cheny\\Desktop\\vae_encoder',
initial_epoch = INITIALIZE_EPOCH)
在普通计算机上,训练过程会持续一个较长时间,在给定文件夹下会产生网络创建的数字图片,我在自己机器上训练将一轮就快一小时,在没有GPU支持下要完成200轮将需要一周时间,因此我在训练几小时后停止,然后测试网络的效果,我们依然像上节那样将测试图片让编码器识别后,将识别出来的二维向量绘制出来如下图:
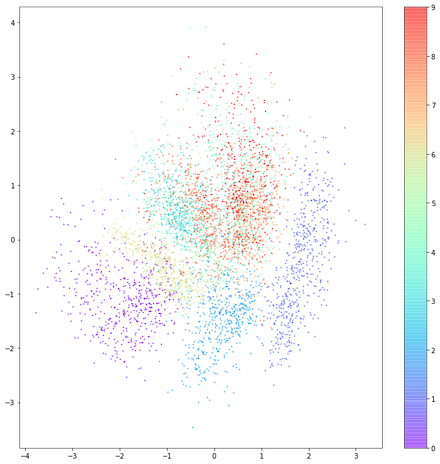
我们看到相同颜色的点对应相同数字图片,而同色点恰好汇集在同一区域,这意味着编码器确实可以将表示同一个数字的不同图片映射到同一给定区域,下一节我们将看看如何使用该网络实现如假包换的换脸效果。
更多技术信息,包括操作系统,编译器,面试算法,机器学习,人工智能,请关照我的公众号:


















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









