









 该博客介绍了如何使用Hadoop MapReduce实现对用户访问次数的统计和排序。首先创建了一个Maven项目,并在pom.xml中添加了Hadoop相关依赖。接着,创建了两个Mapper和Reducer类,分别用于统计用户访问次数和按次数排序。通过编译生成jar包,然后在Hadoop集群上运行,最终实现了按用户访问次数排序的功能。
该博客介绍了如何使用Hadoop MapReduce实现对用户访问次数的统计和排序。首先创建了一个Maven项目,并在pom.xml中添加了Hadoop相关依赖。接着,创建了两个Mapper和Reducer类,分别用于统计用户访问次数和按次数排序。通过编译生成jar包,然后在Hadoop集群上运行,最终实现了按用户访问次数排序的功能。
要求统计每个用户的访问次数并按用户访问次数排序。
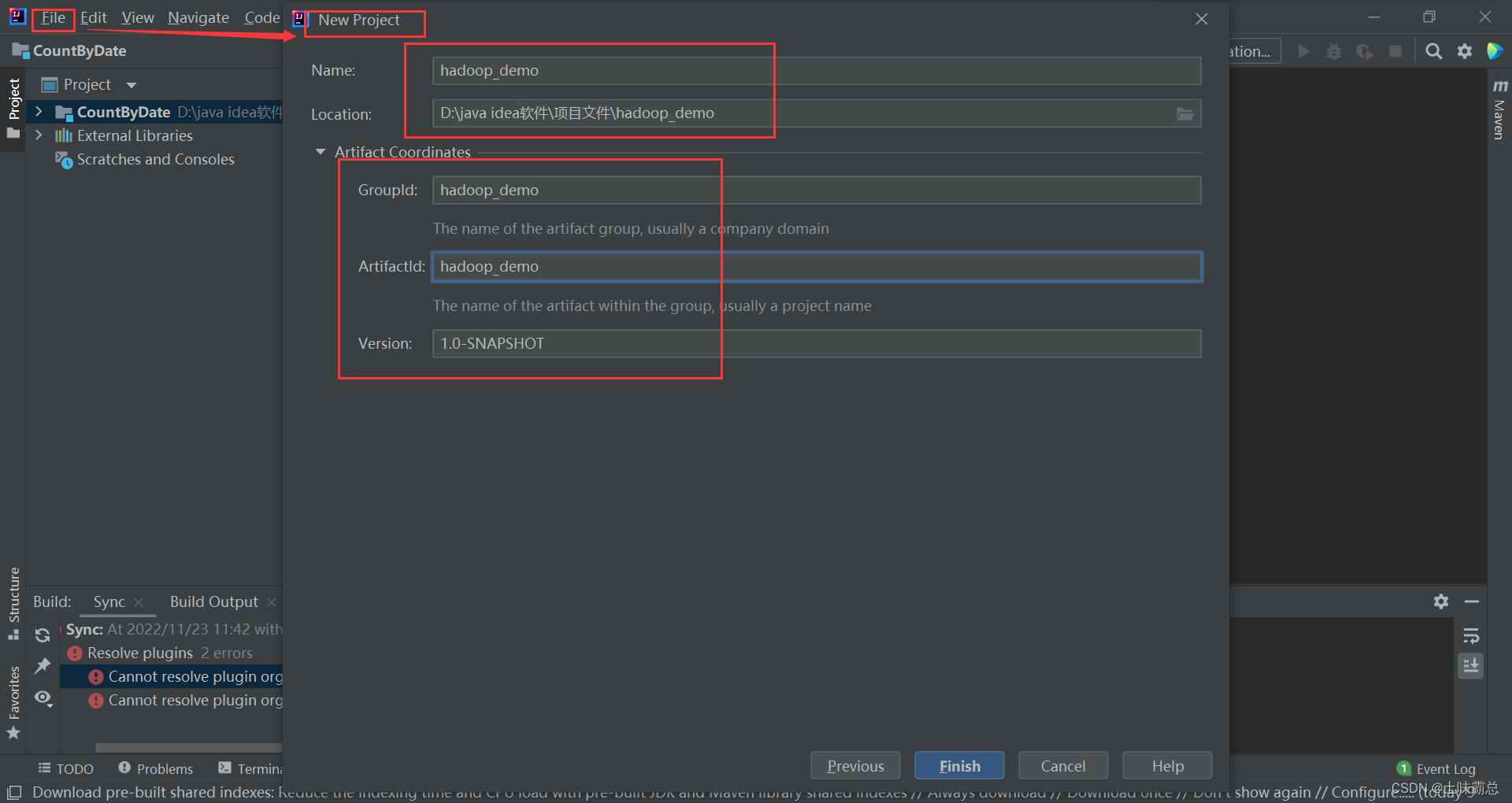
首先新建立maven项目hadoop_demo:
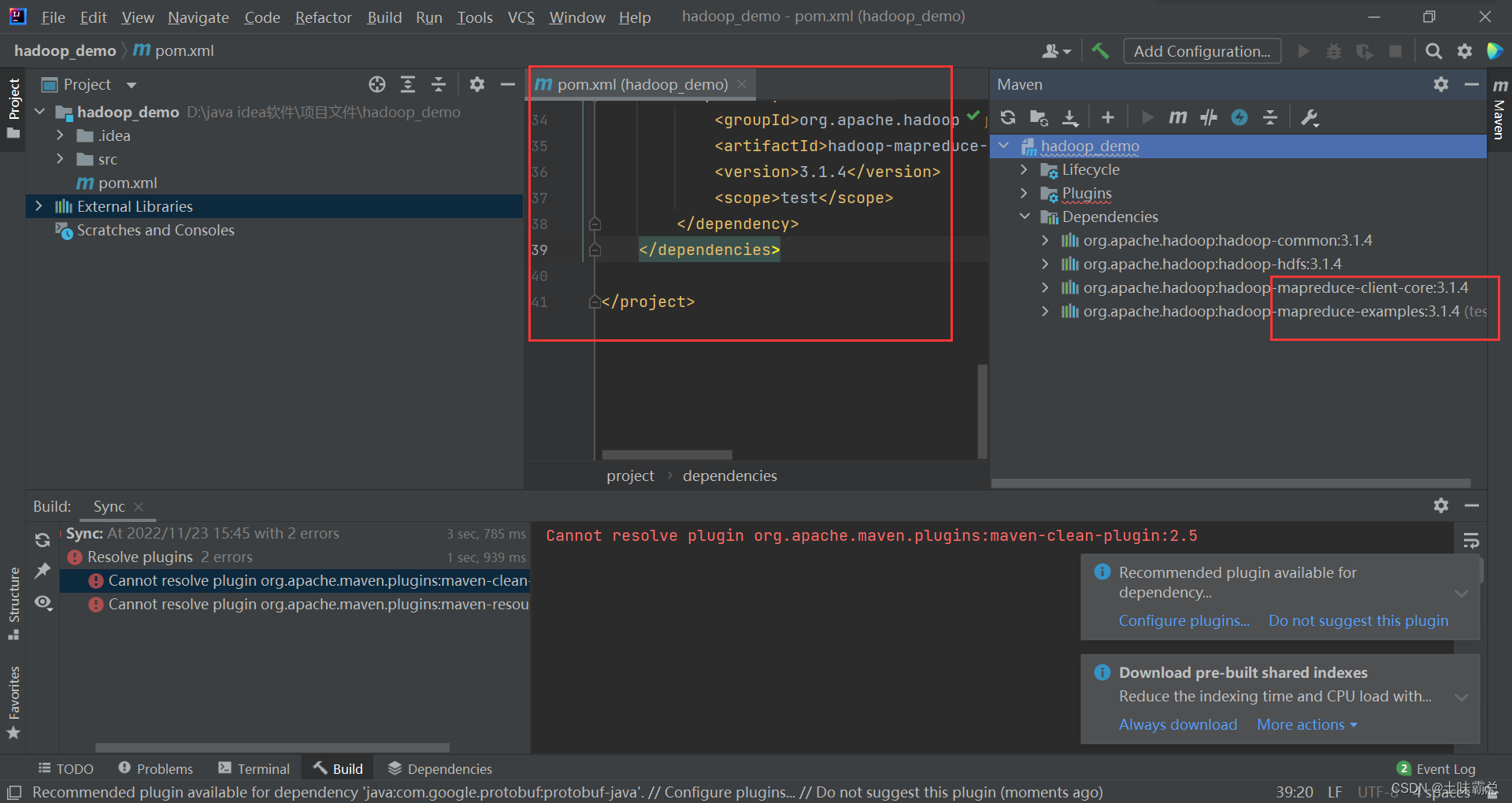
然后在pom.xml中添加依赖,和CountByDate中的依赖一样:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-examples -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-examples</artifactId>
<version>3.1.4</version>
<scope>test</scope>
</dependency>
</dependencies>
然后发现多了依赖:
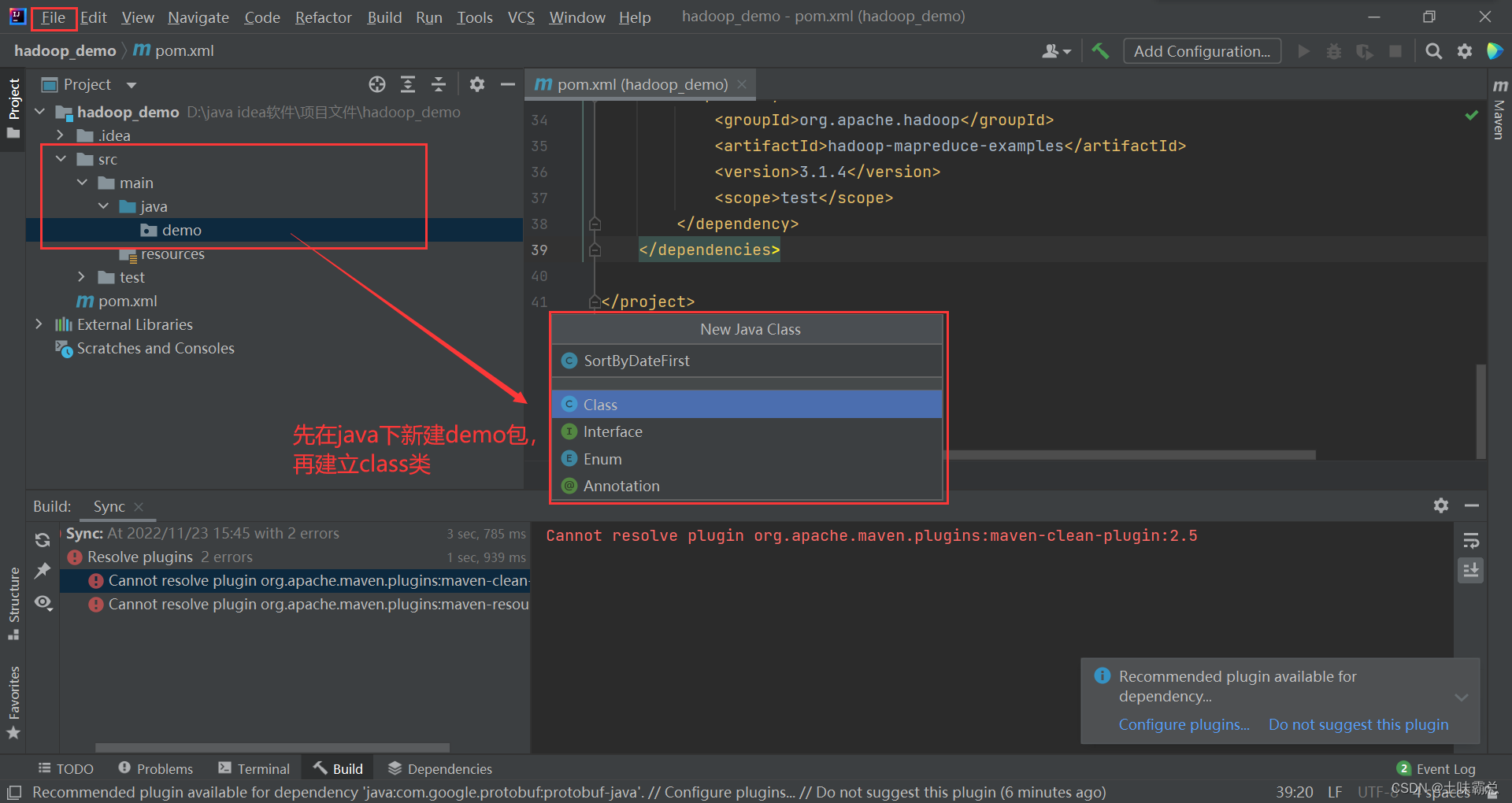
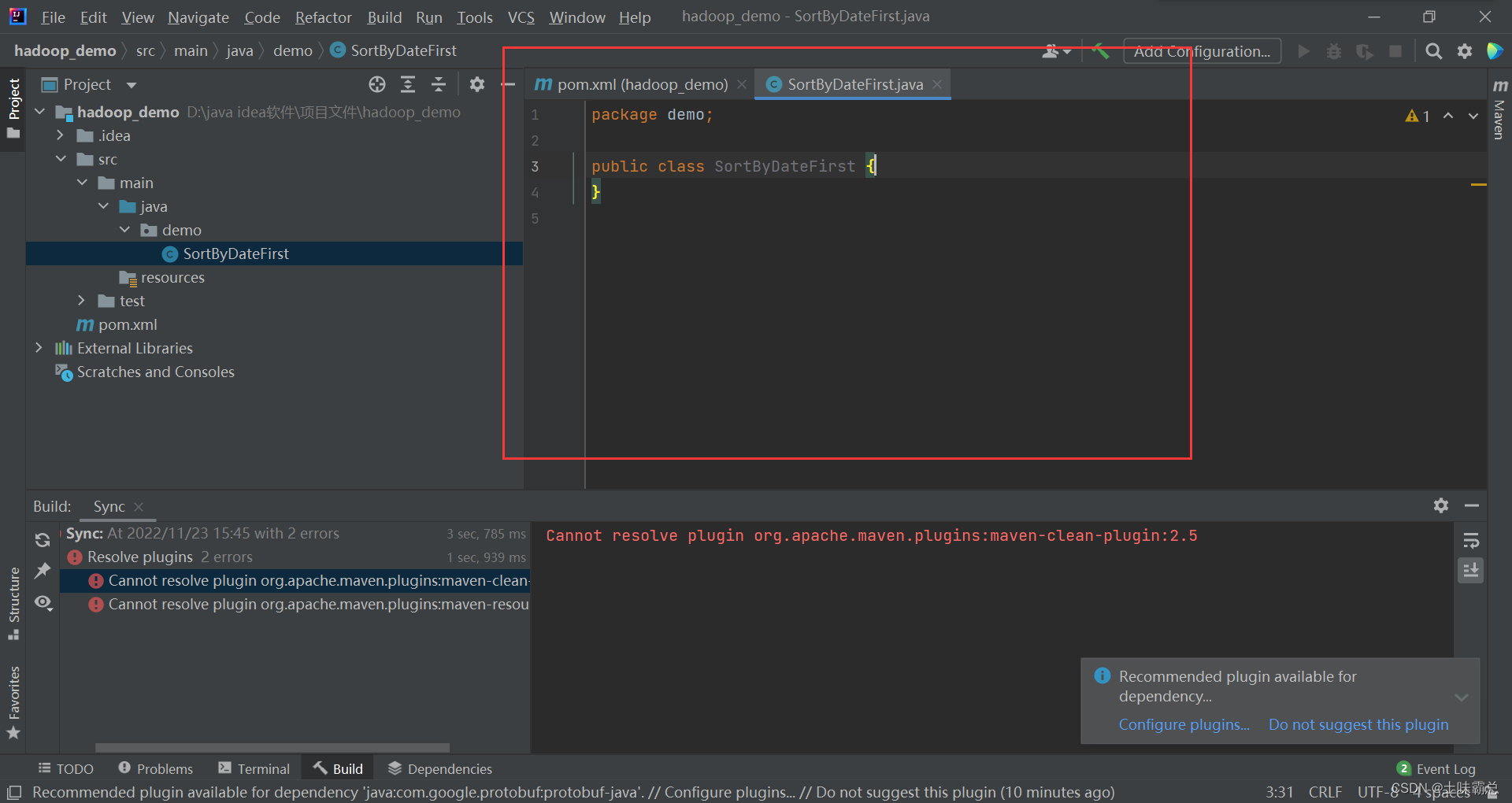
 由于一开始就有src/main/java,所以直接在java下面新建package包demo,然后再建立class类SortByDateFirst:
由于一开始就有src/main/java,所以直接在java下面新建package包demo,然后再建立class类SortByDateFirst:
然后将SortByDateFirst先copy,再点击paste: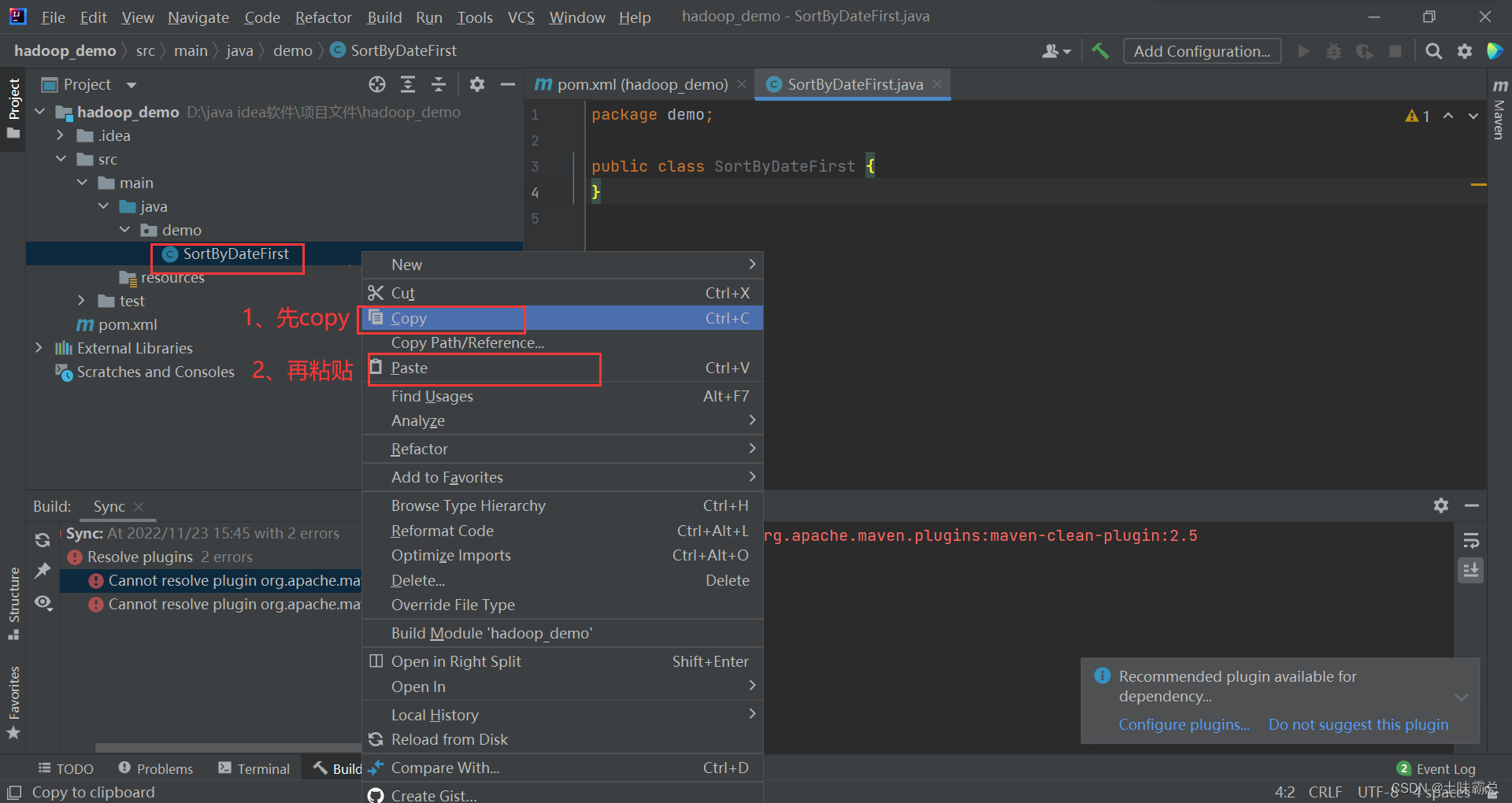
复制粘贴将名字改一下即可:
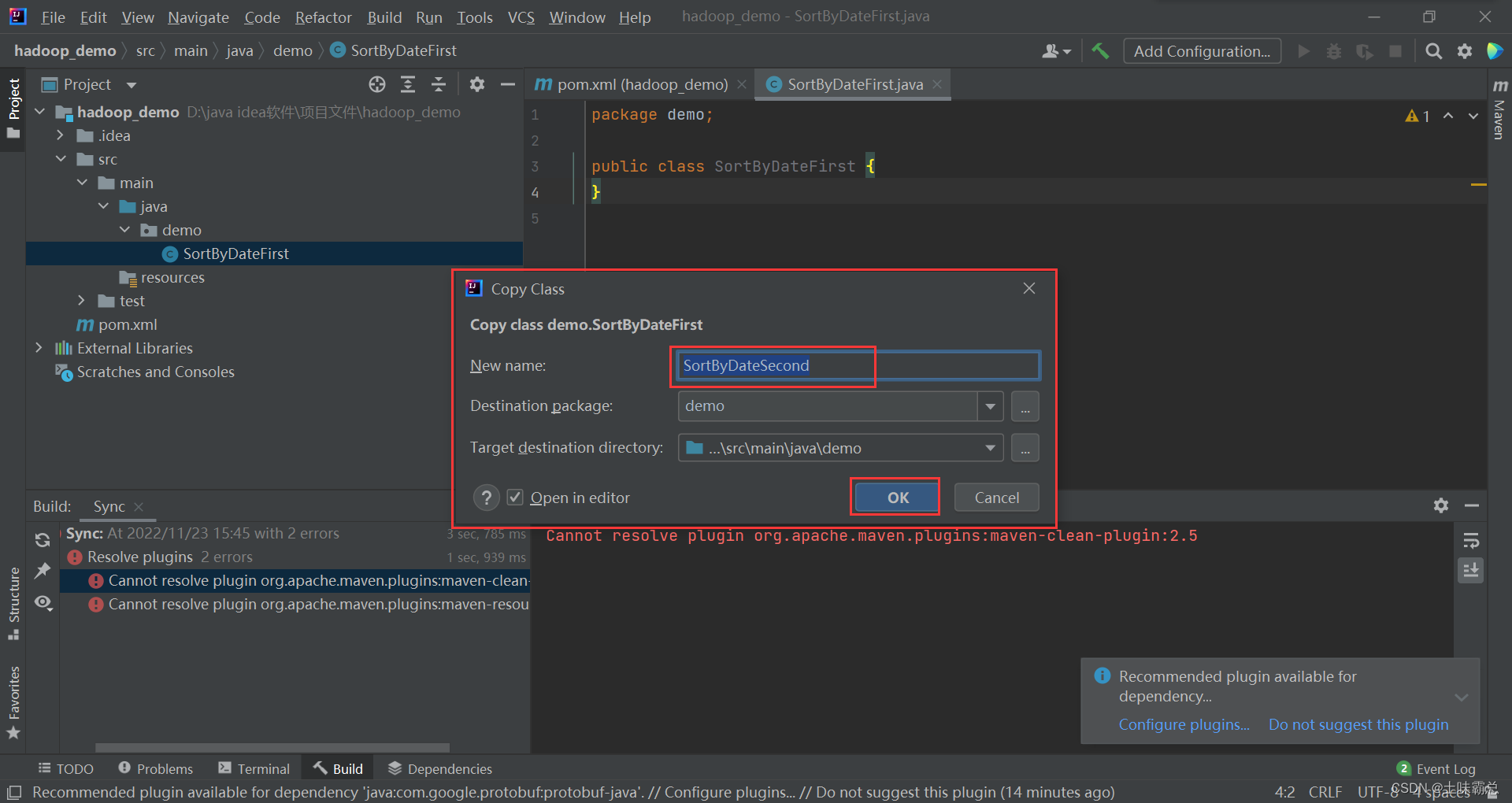
然后向SortByDateFirst中写入下面的代码:
package demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.StringTokenizer;
public class SortByDateFirst {
public static class SplitMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//value email | date
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
String data[] = value.toString().split("\\|", -1);
word.set(data[0]);
context.write(word, one);
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: SortByDateFirst <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(SortByDateFirst.class);
job.setMapperClass(SplitMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
向SortByDateSecond写入下面的代码:
package demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.StringTokenizer;
public class SortByDateSecond {
public static class SplitMapper
extends Mapper<Object, Text, IntWritable, Text> {
private IntWritable count = new IntWritable(1);
private Text word = new Text();
//value: email_address \t count
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
String data[] = value.toString().split("\t", -1);
word.set(data[0]);
count.set(Integer.parseInt(data[1]));
context.write(count, word);
}
}
public static class ReverseReducer
extends Reducer<IntWritable,Text,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(IntWritable key, Iterable<Text> values,
Context context
) throws IOException, InterruptedException {
for (Text val : values) {
context.write(val,key);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: SortByDateFirst <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(SortByDateFirst.class);
job.setMapperClass(SplitMapper.class);
//job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(ReverseReducer.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
两个类很像,但是有不同的代码。
然后编译自动生成jar包:
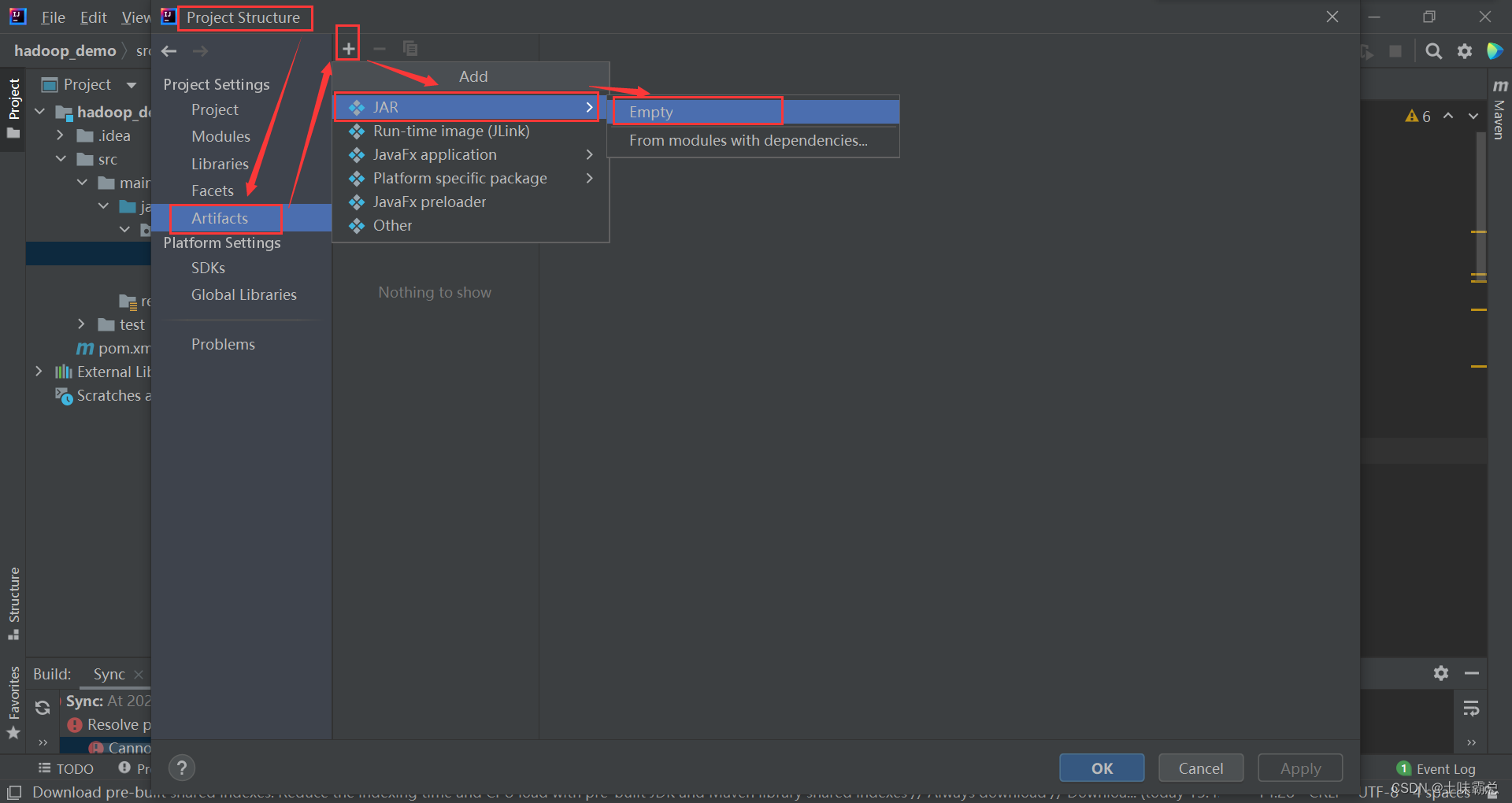
记得双击加入ouput: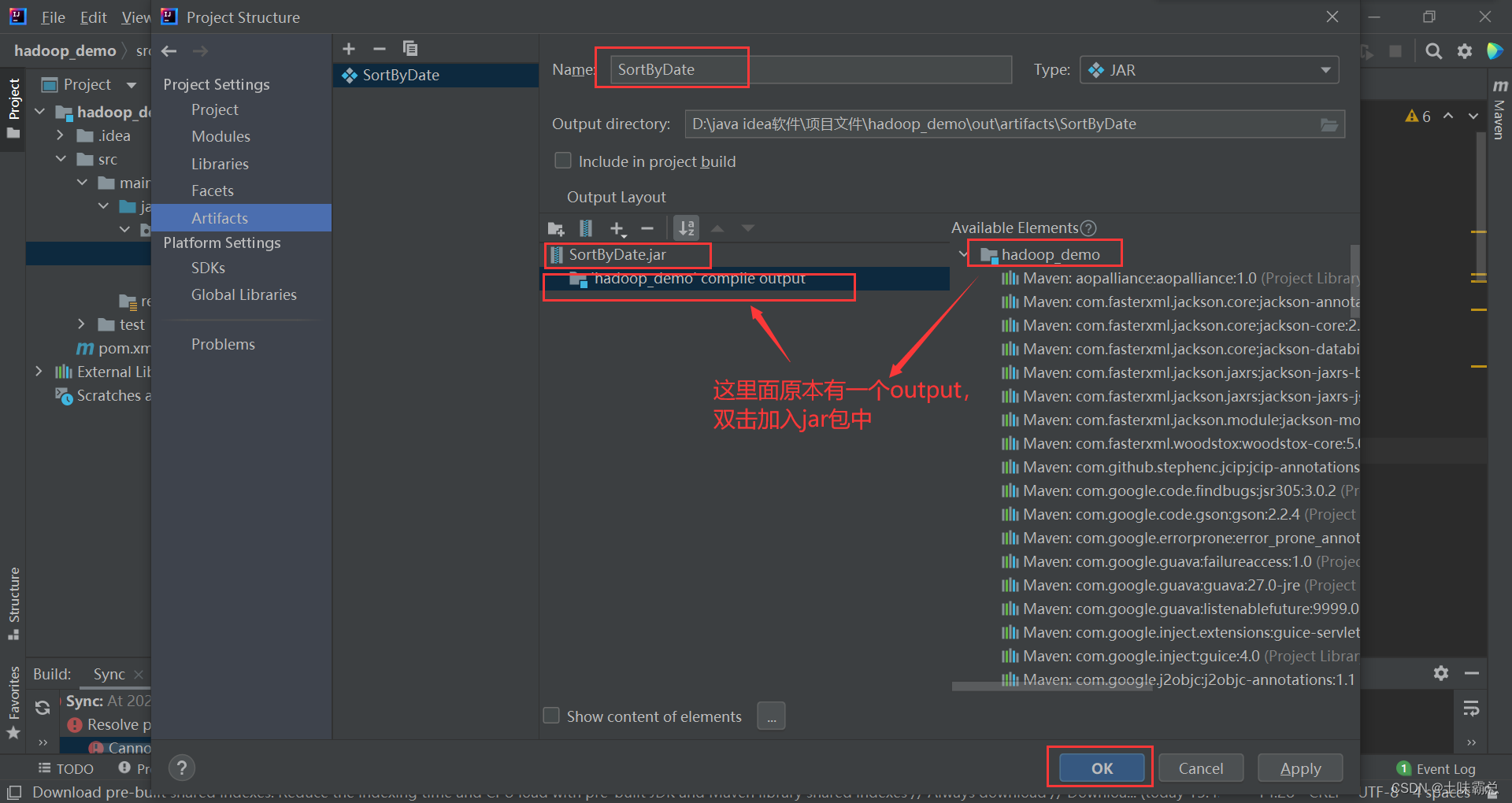 然后选择build:
然后选择build:
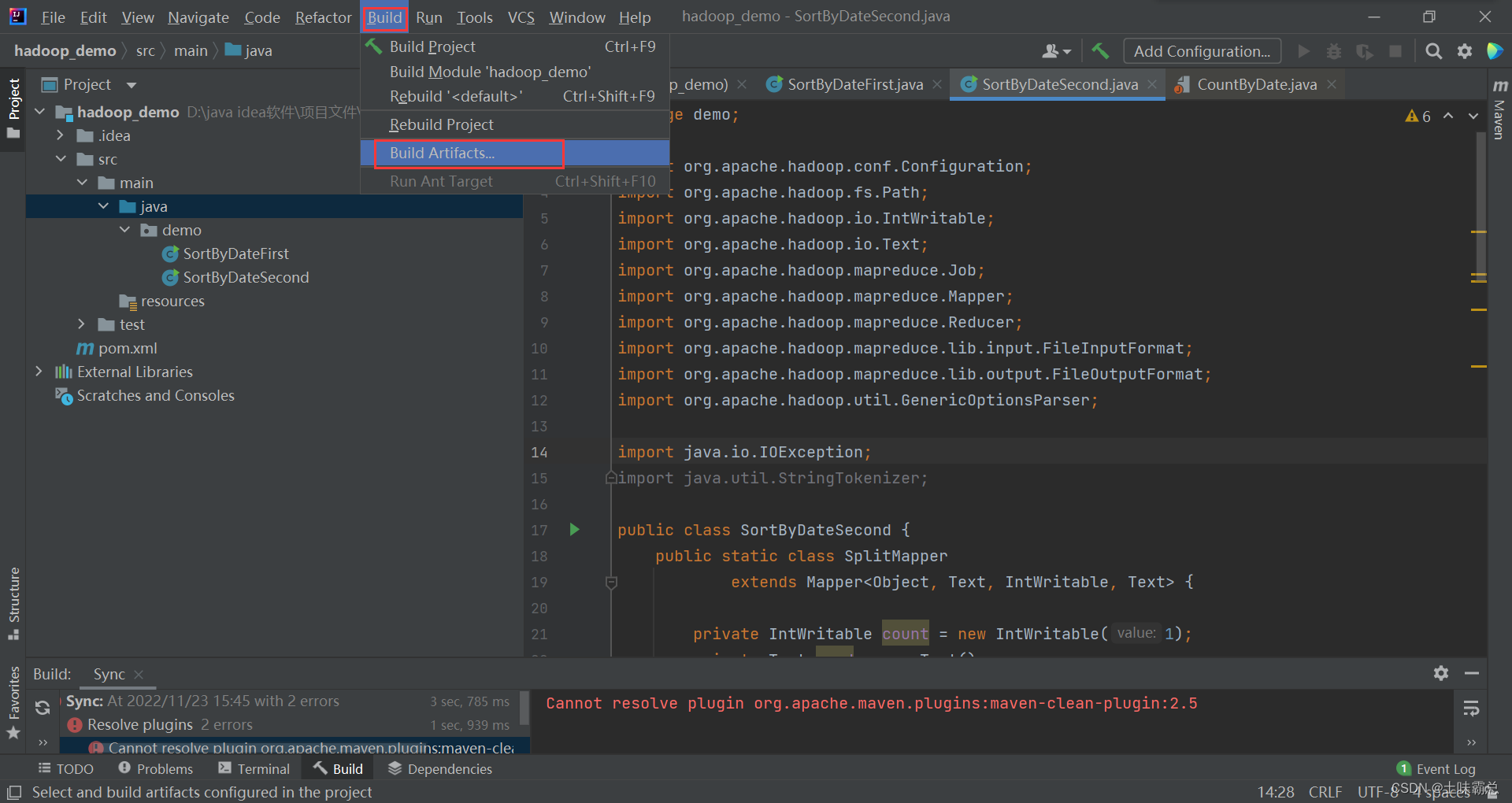
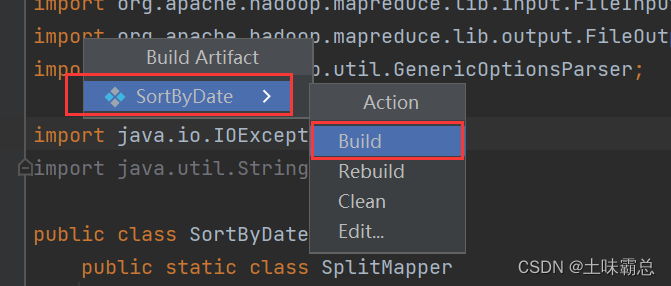
然后就可以发现自动生成了jar包:
然后就是使用xftp上传刚才产生的jar包:
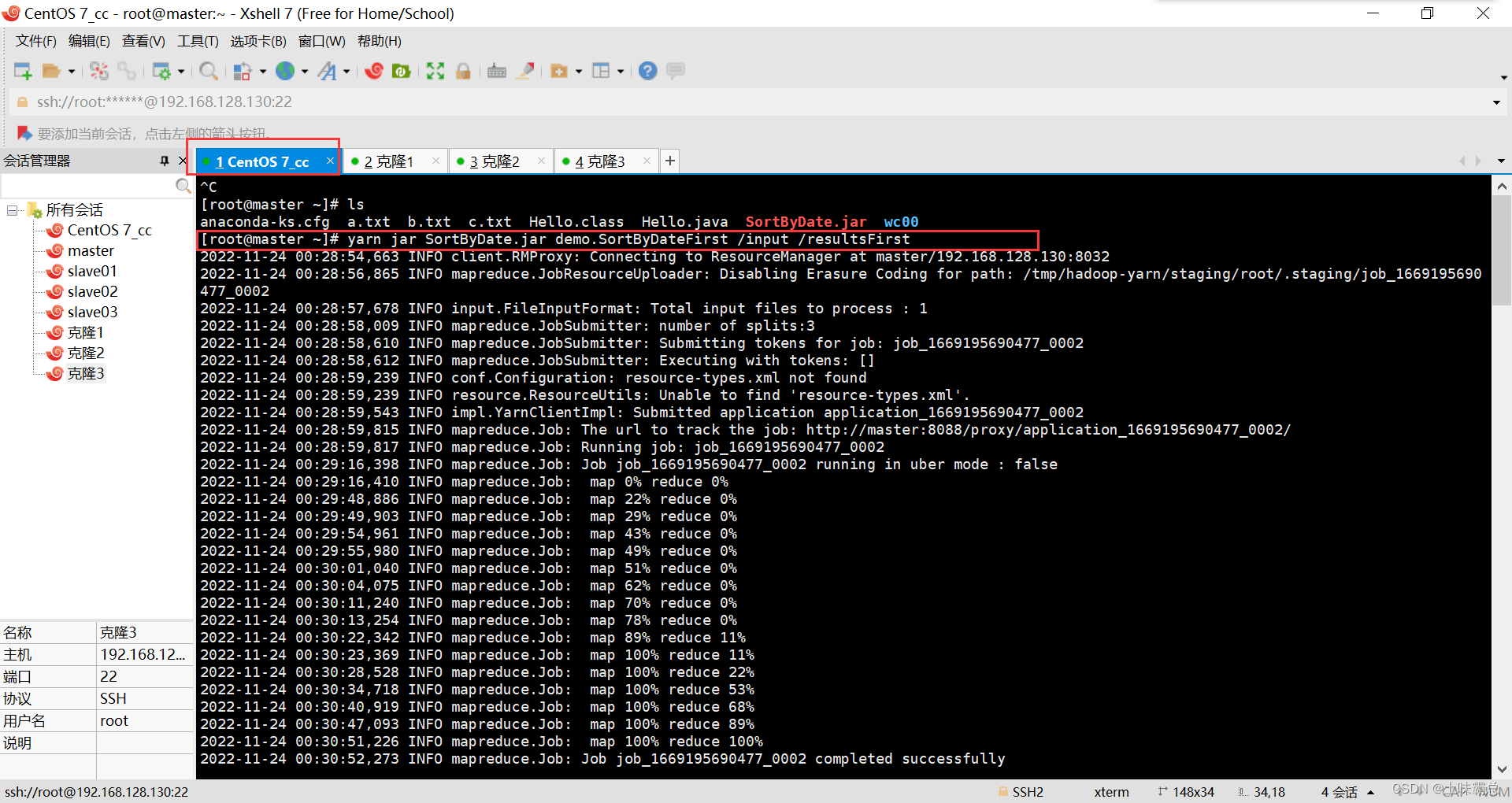
 接下来在xshell中查看我们的hadoop集群是否被启动,如果没有启动,那么先启动Hadoop集群,启动命令如下。我的Hadoop集群是开始就启动了的:
接下来在xshell中查看我们的hadoop集群是否被启动,如果没有启动,那么先启动Hadoop集群,启动命令如下。我的Hadoop集群是开始就启动了的:
cd /opt/hadoop-3.1.4/sbin
./start-dfs.sh
./start-yarn.sh
./mr-jobhistory-daemon.sh start historyserver
jps
我的操作都是在启动了Hadoop集群的前提下完成的:
最后就是运行程序达到统计每个用户的访问次数并按用户访问次数排序的要求,代码如下:
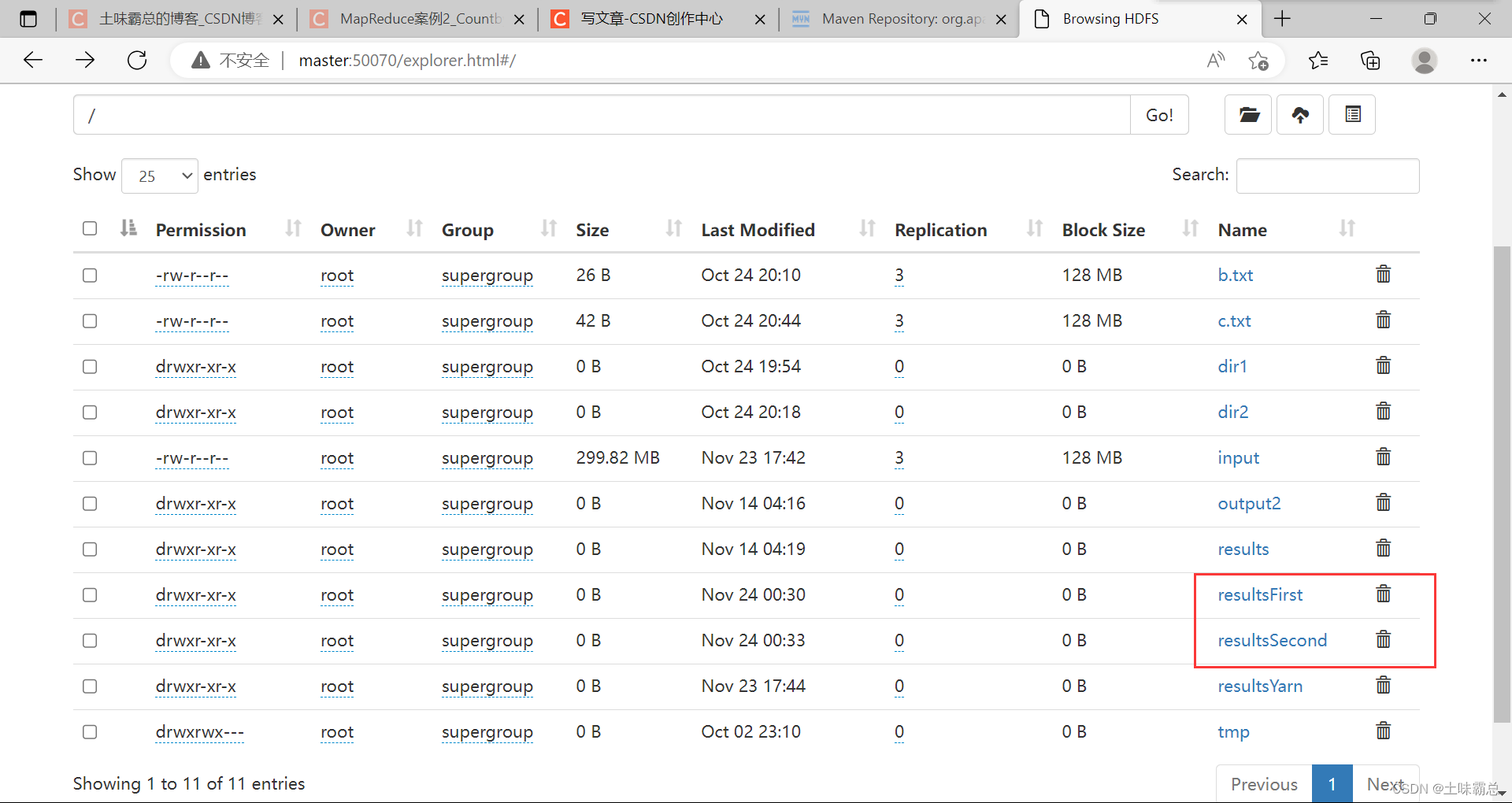
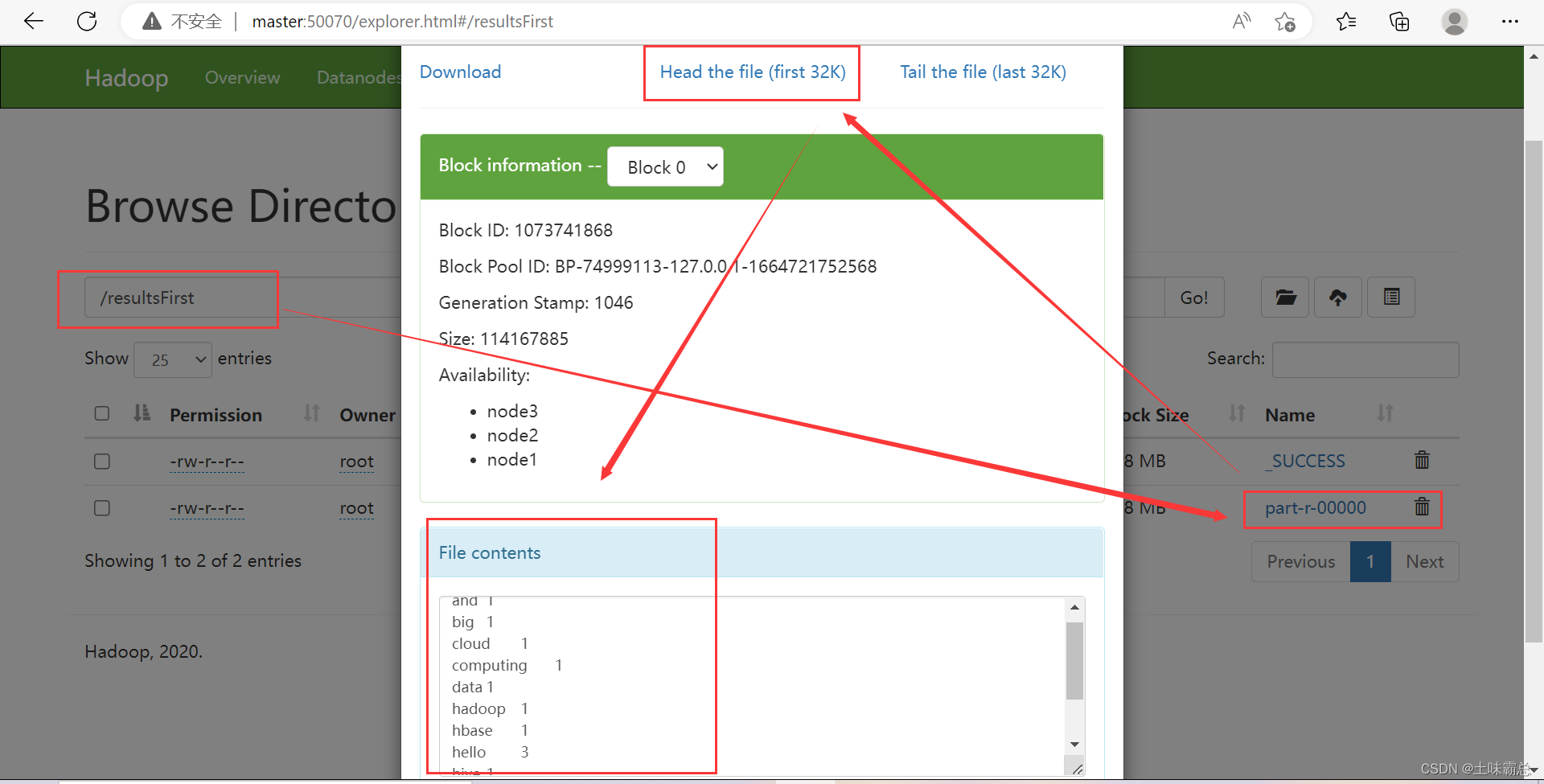
yarn jar SortByDate.jar demo.SortByDateFirst /input /resultsFirst
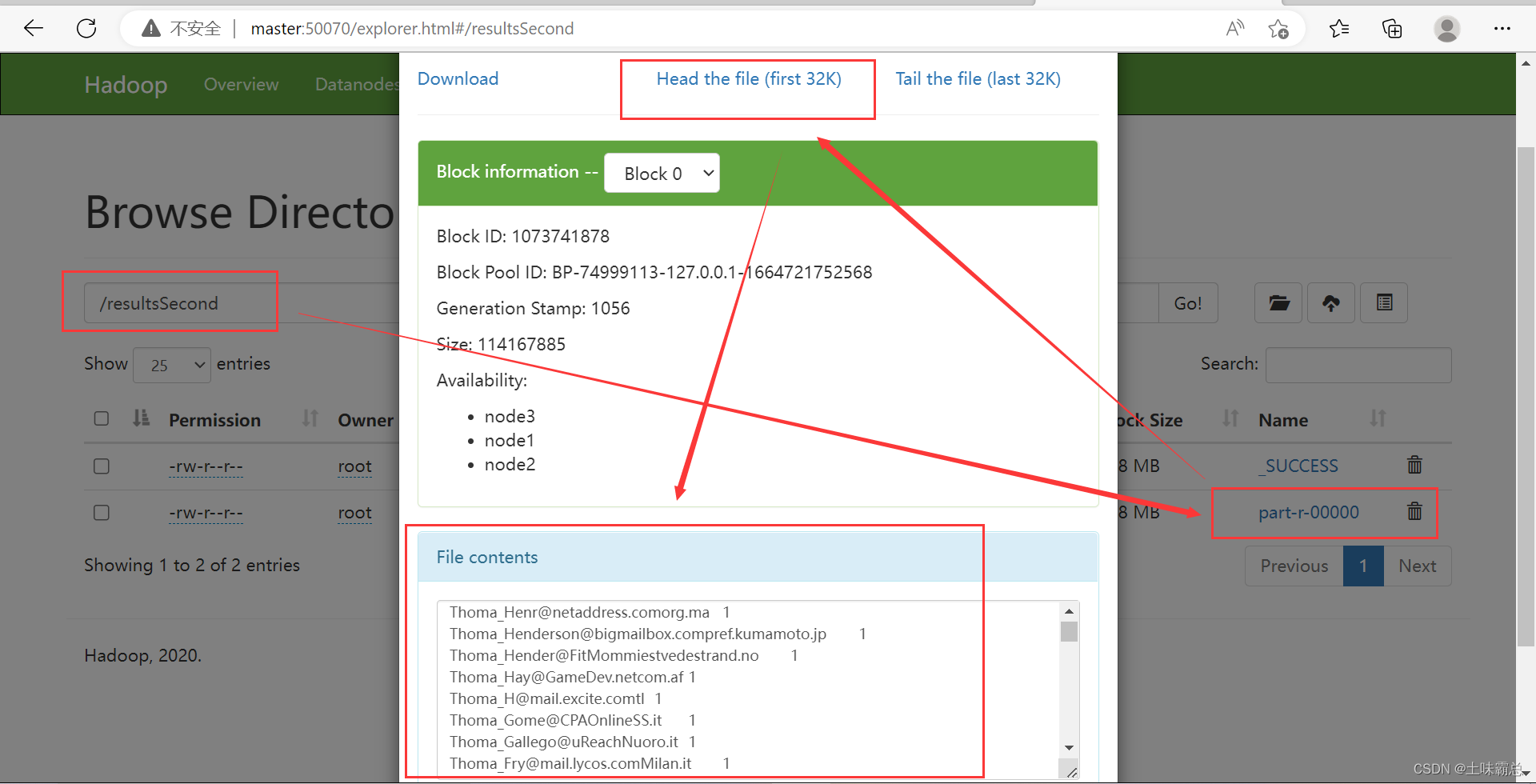
yarn jar SortByDate.jar demo.SortByDateSecond /resultsFirst /resultsSecond
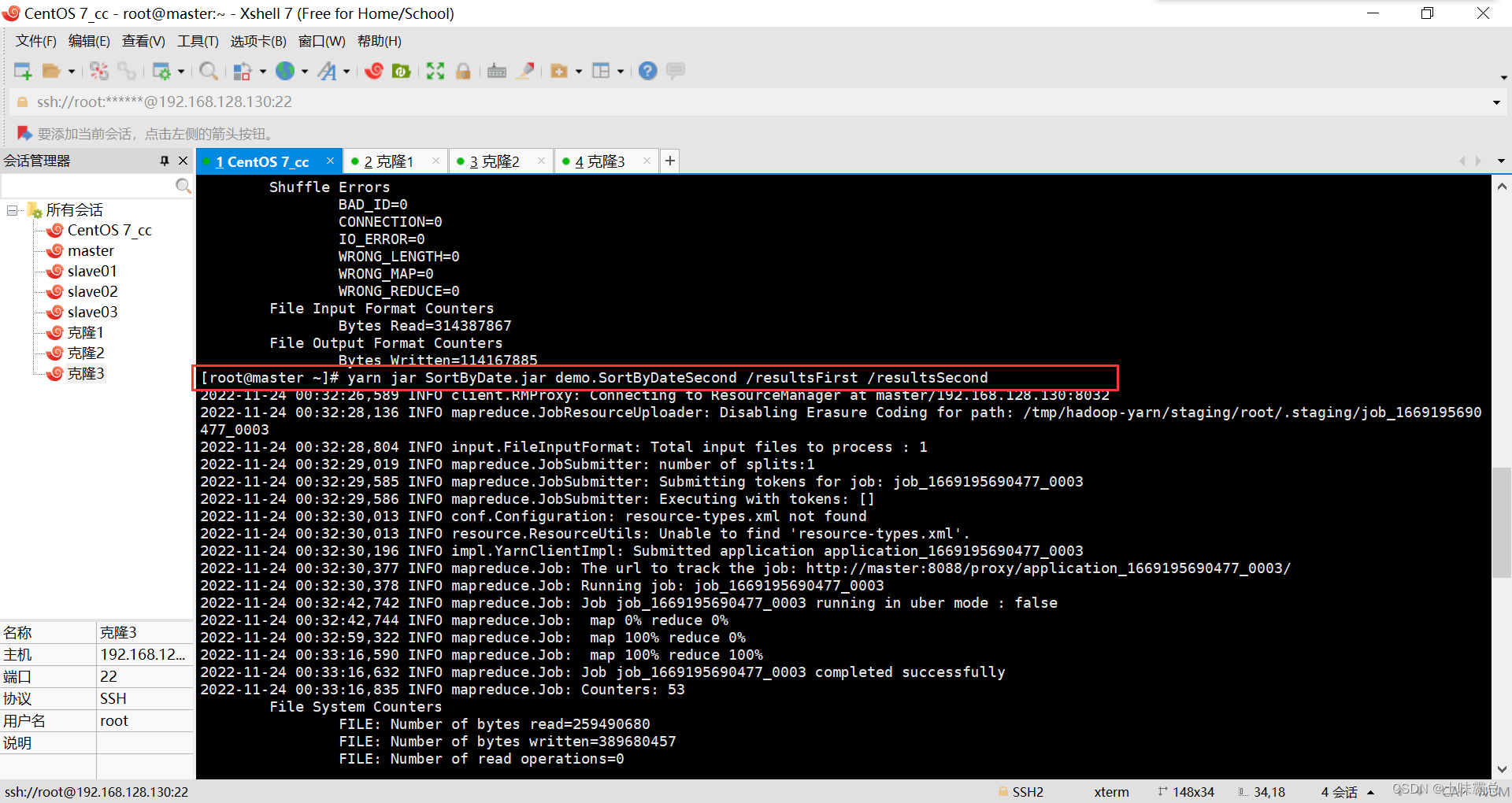 最后的运行结果如图:
最后的运行结果如图:

















 1274
1274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









