




 本文详细解析PostgreSQL中的各种锁类型,包括表锁和行锁,解释如何使用LOCK TABLE命令来控制数据的一致性和并发访问,以及不同锁模式之间的冲突和应用策略。
本文详细解析PostgreSQL中的各种锁类型,包括表锁和行锁,解释如何使用LOCK TABLE命令来控制数据的一致性和并发访问,以及不同锁模式之间的冲突和应用策略。
表锁
LOCK [ TABLE ] [ ONLY ] name [ * ] [, ...] [ IN lockmode MODE ] [ NOWAIT ]
lockmode包括以下几种:
ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE| SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE
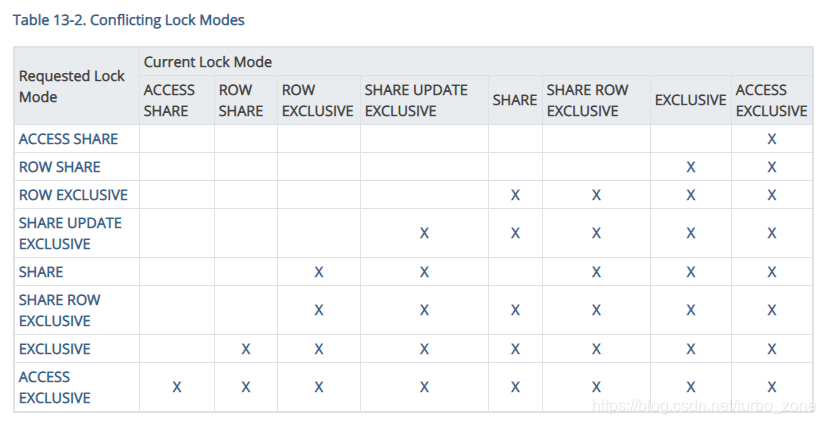
LOCK TABLE命令用于获取一个表锁,获取过程将阻塞一直到等待的锁被其他事务释放。如果使用NOWAIT关键字则如果获取不到锁,将不会等待而是直接返回,放弃执行当前指令并抛出一个错误(error)。一旦获取到锁,将一直持有锁直到事务结束。(没有主动释放锁的命令,锁总是会在事务结束的时候被释放)。
当使用自动获取锁的模式的时候,PostgreSQL总是尽可能地使用限制最小的模式。LOCK TABLE命令使我们可以自己定义锁的限制大小。比如一个应用程序使用事务在读提交(Read Committed isolation level)模式下需要保证数据库的数据在事务期间保持稳定,于是可以使用SHARE锁模式在读取前对表进行加锁。这可以防止并发的数据改变并且可以保证后续的事务对这个表的读取不会读到没有提交的数据,因为SHARE锁和由写入事务持有的ROW EXCLUSIVE锁是冲突的,所以对于想要使用SHARE锁对表进行加锁的事务,将会等到它之前所有持有该表的ROW EXCLUSIVE锁的事务commit或者是roll back。因此,一旦获取了表的SHARE锁,将不会有没有提交的数据,同样也不会有其他事务能够对表数据进行改变,直到当前事务释放SHARE锁。
为了在REPEATABLE READ(重复读)模式和SERIALIZABLE(序列化)模式下实现同样的效果,必须在任何查询和修改语句之前加上LOCK TABLE。在执行第一句SELECT语句或者修改数据语句前,重复读和序列化模式中一个事务的的数据视图将会被存储为快照。在这种情况下,事务申明的表锁同样可以避免并发的修改,但是并不能保证该事务能够读取到最新提交的数据。
如果一个事务想要修改表中的数据,应该使用SHARE ROW EXCLUSIVE(共享行排他)锁而不是SHARE锁。共享行排他锁将能够保证在同一时间只有当前事务能够运行。不加这个锁的话可能会造成死锁:两个事务同时想要获取SHARE锁,并且接下来又想要同时获取ROW EXCLUSIVE锁去进行数据更新(注意:同一个事务获取的两种不同的锁不会造成冲突,所以对于同一个事务,它可以在获取SHARE锁之后再次获取ROW EXCLUSIVE,当然是在没有其他事务获取SHARE锁的情况下)。为了避免死锁,应该保证所有的事务获取同一对象的锁的顺序是一致的,同时如果在同一个对象上想要获取多个锁,则总是应该先获取限制最大的锁。
ACCESS SHARE(访问共享锁)
只与ACCESS EXCLUSIVE锁冲突。
SELECT命令会在当前查询的表上获取一个ACCESS SHARE锁。总的来说,任何只读操作都会获取该锁。
ROW SHARE(行共享锁)
和EXCLUSIVE锁和ACCESS EXCLUSIVE锁冲突。
SELECT FOR UPDATE或者SELECT FOR SHARE命令会在目标表上获取该锁,并且所有被引用但是没有FOR UPDATE的表上会加上ACCESS SHARED锁。
ROW EXCLUSIVE(行排他锁)
和SHARE,SHARE ROW EXCLUSIVE和ACCESS EXCLUSIVE锁冲突。
UPDATE,DELETE和INSERT会在目标表上获取该锁,总的来说,任何对数据库数据进行修改的命令会获取到该锁。
SHARE UPDATE EXCLUSIVE(共享更新排他锁)
和SHARE UPDATE EXCLUSIVE,SHARE ROW EXCLUSIVE,EXCLUSIVE和ACCESS EXCLUSIVE冲突,该锁可以保护表防止并发的(schema)改变和VACUUM(释放空间)命令。
VACUUM,ANALYZE,CREATE INDEX CONCURRENTLY和ALTER TABLE VALIDATE以及其他ALTER TABLE类的命令会获取该锁。
SHARE(共享锁)
和ROW EXCLUSIVE,SHARE UPDATE EXCLUSIVE,SHARE ROW EXCLUSIVE,EXCLUSIVE和ACCESS EXCLUSIVE锁冲突。该锁保护一个表防止并发的数据改变。
由CREATE INDEX命令获得。
SHARE ROW EXCLUSIVE(行共享排他锁)
和ROW EXCLUSIVE,SHARE UPDATE EXCLUSIVE,SHARE,SHARE ROW EXCLUSIVE,EXCLUSIVE以及ACCESS EXCLUSIVE锁冲突,该锁用于保护一个表防止并发的数据改变,同时是自排他的,所以在同一时间只有同一个session可以持有该锁。
该锁不会被PGSQL的任何命令自动获取。
EXCLUSIVE(排它锁)
和ROW SHARE,ROW EXCLUSIVE,SHARE UPDATE EXCLUSIVE,SHARE,SHARE ROW EXCLUSIVE,EXCLUSIVE和ACCESS EXCLUSIVE锁冲突。该锁只允许并发的ACCESS SHARE锁,只有只读操作能在一个事务持有排他锁的时候进行并发操作。
ACCESS EXCLUSIVE(访问排他锁)
和所有的锁都冲突,该锁保证只有持有锁的事务能够访问当前表。
被DROP TABLE,TRUNCATE,REINDEX,CLUSTER,VACUUM FULL和REFRESH MATERIALIZED VIEW命令自动获取。有很多种形式的ALTER TABLE命令可以获取该锁,它同样也是LOCK TABLE命令默认的锁级别。
只有ACCESS EXCLUSIVE锁可以防止一个SELECT语句。
注意
一段获取锁,只有当事务结束的时候才会释放,但是如果一个锁是在一个savepoint(保存点)之后被获取,则当这个保存点回滚的时候这个锁会被马上释放。
行锁
除了表锁,PgSQL还提供了行锁。一个事务可以获取相互冲突的两种行锁,包括在子事务中,但是两个事务不能同时在同一行获取相互冲突的两种锁。
FOR UPDATE
FOR UPDATE锁使得SELECT语句可以获取行锁用于更新数据。这使得该行可以防止被其他的事务获取锁或者进行更改删除操作,也就是说其他事务的操作会被阻塞直到当前事务结束;同样的,SELECT FOR UPDATE命令会等待直到前一个事务结束。在REPEATABLE模式或者SERIALIZABLE模式下,如果一个将要被上锁的行在事务开始之前被删除了,则会返回一个error。
FOR UPDATE锁同样可以被DELETE命令获取,以及UPDATE命令当使用在确定的行用来修改数据的时候也会获取到该锁。目前当使用确定的唯一索引时使用UPDATE命令可以获取到该锁(部分索引和联合索引暂时不支持),但是未来可能会改变这种设计。
FOR NO KEY UPDATE
和FOR UPDATE命令类似,但是对于获取锁的要求更加宽松一些,在同一行中不会阻塞SELECT FOR KEY SHARE命令。同样在UPDATE命令的时候如果没有获取到FOR UPDATE锁的情况下会获取到该锁。
FOR SHARE
和FOR NO KEY UPDATE命令类似,不同点在于这个锁是一个共享锁而不是之前的锁一样是排他锁,所以这个锁会阻塞UPDATE,DELETE,SELECT FOR UPDATE或者SELECT FOR NO KEY UPDATE,但是不会阻塞SELECT FOR SHARE或者SELECT FOR KEY SHARE。
FOR KEY SHARE
和FOR SHARE表现类似,但是对加锁的要求更加宽松,SELECT FOR UPDATE会被阻塞但是SELECT FOR NO KEY UPDATE不会被阻塞。KEY SHARE模式下的锁会阻塞其他事务的DELETE或者是改变KEY值的UPDATE语句,但是对于其他的UPDATE或者是SELECT FOR NO KEY UPDATE,SELECT FOR SHARE以及SELECT FOR KEY SHARE则不会阻塞。


















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









