







目录
1)添加 node-exporter 至 Prometheus 捕获
3)合并上面1-2的配置项,添加进Prometheus configmap 配置文件中
一、Prometheus简介
原文链接: yPrometheus监控平台的部署与监控 - aganippe - 博客园
Prometheus是一个开源的系统监控和报警系统,在2012年由SoundCloud创建,并于2015年正式发布。2016年,Prometheus项目正式加入CNCF基金会,成为继kubernetes之后第二个在CNCF托管的项目,现在已经广泛用于容器和微服务领域。
Prometheus本身是基于go开发的一套开源的系统监控报警框架和时序数据库(TSDB)。
Prometheus的监控功能很完善和全面,性能支持上万规模的集群。
- Prometheus网站:Prometheus - Monitoring system & time series database
- Prometheus官网文档:Overview | Prometheus
- Prometheus代码仓库:Prometheus · GitHub
- Prometheus中文文档:https://www.prometheus.wang
- Prometheus exporters:Exporters and integrations | Prometheus
- Prometheus exporter golang客户端库:GitHub - prometheus/client_golang: Prometheus instrumentation library for Go applications
Prometheus的特点如下:
- 支持多维数据模型:由度量名和键值对组成的时间序列数据
- 内置时间序列数据库TSDB
- 支持PromQL(Prometheus Query Language)查询语言,可以完成非常复杂的查询和分析,对图表展示和告警非常有意义
- 支持HTTP的PULL方式采集时间序列数据
- 支持PushGateway采集瞬时任务的数据
- 支持服务发现和静态配置两种方式发现目标
- 多种可视化和仪表盘,支持第三方dashboard,比如Grafana
数据特点:
- 监控指标,采用独创的指标格式,我们称之为Prometheus格式,这个格式在监控场景中非常常见
- 数据标签,支持多维度标签,每个独立的标签组合都代表一个独立的时间序列
- 数据处理,Prometheus内部支持多种数据的聚合、切割、切片等功能
- 数据存储,Prometheus支持双精度浮点型数据存储
适用场景:
- Prometheus非常适合记录任何纯数字时间序列。它既适合以机器为中心的监控场景,又适合高度动态的面向服务的体系结构的监控场景
- 在微服务场景中,它对多维数据收集和查询的支持是一种特别的优势
- Prometheus的设计旨在提升可用性,使其省委中断期间要使用的系统,以快速诊断问题
- 每个Prometheus服务器都是独立的,而不依赖于网络存储或其他远程服务
二、Prometheus架构
Prometheus监控是一个监控体系,主要模块包括:Prometheus server、exporters、PushGateway、PromQL、Alertmanager以及图形化界面
主要组件:
- Prometheus server:时序数据存储、监控指标管理。Prometheus server包含Retrieval、TSDB、HTTP server三个组件。
- 可视化:Prometheus webUI、Grafana可视化套件
- 数据采集:exporters为当前客户端暴露出符合Prometheus规格的数据指标、PushGateway为push模式下的数据采集工具
- 监控目标:服务发现,包括文件方式、DNS方式、console方式、kubernetes方式
- 告警:Alertmanager,主要用来接受prometheus发送的告警信息,它支持丰富的告警通知渠道,并且很容易做到告警信息进行去重,降噪,分组 ,策略路由,是一款前卫的告警通知系统。
其中TSDB支持存储60天的数据,如果想要永久存储监控数据的话需要增加一个时序数据库后端,比较典型的是InfluxDB
Retrieval负责获取监控数据,也就是Prometheus targets,通常采用的是pull模式
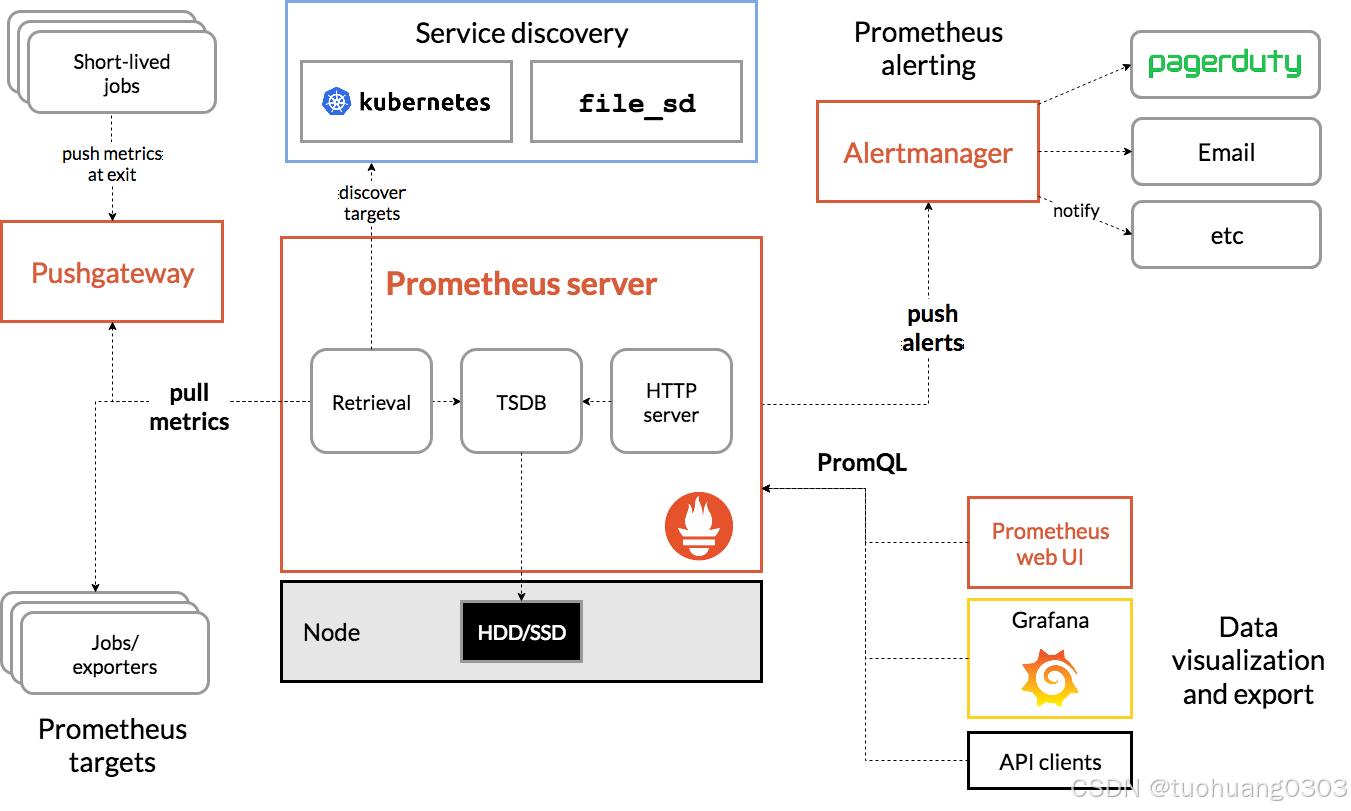
本质上来讲Prometheus只支持pull的方式来获取监控数据。
那么push又从何而来的呢?对于一些瞬时任务,比如一个存在时间极短的job,pull的方式显然是不太能够抓取到这些数据的。
Prometheus所采用的方式就是部署一个PushGateway,job在执行完成之后将数据push到这个网关代理,而Prometheus将从PushGateway中pull数据。
pull模式的特点:
- 被监控方提供一个server,并负责维护
- 监控方控制采集频率
第一点对用户来说要求更高了,但是好处很多,比如pull不到数据本身就说明节点存在故障;比如监控指标自然而然由用户自己维护,使得标准化很简单;
第二点更为重要,那就是在监控体系对metric采集的统一和稳定有了可靠的保证,对于数据量大的情况下很重要。
同样pull模式的缺点在于需要服务发现模块来动态发现被监控对象,同时被监控方和Prometheus可能存在数据维护不同步的情况,造成一定的信息丢失和不准确。
kubernetes/kube-state-metrics组件
能够获取kubernetes各种资源的最新状态,比如deployment或者daemonset等
Metrics Server
可以从api-server中获取cpu、内存使用率监控指标,它当前的核心作用是:为HPA kubectl等组件提供决策指标支持。
三、Prometheus数据模型
Prometheus中存储的数据为时间序列,即基于同一度量标准或者同一时间维度的数据流。
除了时间序列数据的正常存储外,Prometheus还会基于原始数据临时生成新的时间序列数据,用于后续查询的依据或结果。
每个时间序列都是由metric名称和标签(可选键值对)组成的唯一标识。
1、metric
- 该名字必须有意义,用于表示metric的一般性功能,例如:http_requests_total表示http请求的总数
- metric名字由ASCII字符、数字、下划线和冒号组成,且必须满足正则表达式a-zA-Z:*的查询请求
- 注意:冒号是为用户自定义的记录规则保留的

2、标签
- 标签是以键值对的形式存在的,不同的标签用于表示时间序列的不同维度标识
- 基本格式:
<metric name>{<label name>=<label value>, ...} | |
# 示例 | |
http_requests_total{method="POST", endpoint="/api/tracks"} | |
# 解析: | |
# http_requests_total{method="POST"}表示所有http请求中的POST请求 | |
# endpoint="/api/tracks"表示请求的url地址是/api/tracks |
- 标签中的key由ASCII字符、数字以及下划线组成,且必须要满足正则表达式a-zA-Z:*
- 标签值可以包含任何Unicode字符,标签值为空被认为等同于不存在的标签
查询语言允许基于这些维度进行过滤和聚合。更改任何标签值,包括添加或删除标签,都会创建一个新的时间序列。
四、Prometheus部署
1、常用的部署方式
包安装
RHEL系统:prometheus-rpm/release - Results in
Ubuntu和Debian可直接使用apt命令安装
二进制安装
docker安装
k8s operator安装
https://github.com/coreos/kube-prometheus
2、通过k8s资源对象部署prometheus系统
通过k8s的daemonset以及deployment等资源对象完成对prometheus系统相关组件的部署。能够更好的理解prometheus整套系统的运作逻辑。部署完成后,我们通过配置相关文件,监控一些基本的资源指标。
大致的部署逻辑图如下:
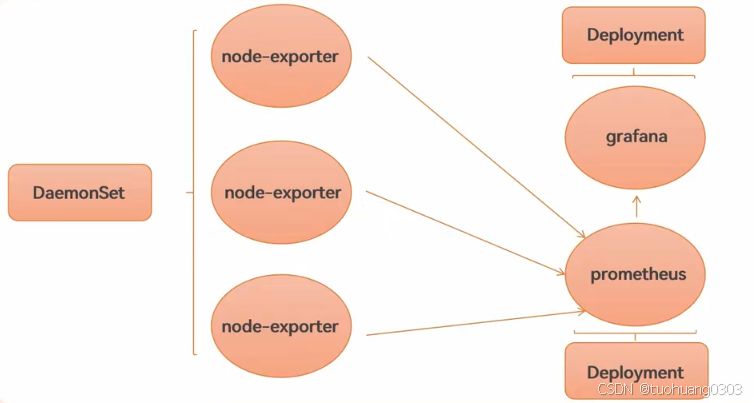
上面部署架构:
1、每个node节点部署exporter组件,目的是收集每个节点的metrics数据。它是通过DaemonSet进行部署,目的是确保每个node节点都有一个exporter的pod收集指标。
2、有一个deployment部署的prometheus server,确保当prometheus server有pod挂掉的时候,还能起来新的pod,高可用性。
3、有一个deployment部署的grafana监控web,确保当pod挂掉的时候,还能起来新的pod,高可用。
具体详细的部署步骤如下。
(1)部署 Prometheus
(2)监控 ingress-nginx
(3)创建 node-exporter,监控节点资源
1)添加 node-exporter 至 Prometheus 捕获
2)kubelet metrics 接口添加监控
3)合并 Prometheus configmap 配置文件
(4)监控容器资源指标
(5)监控 ApiServer 指标
(6)通过 Service 监控服务
(7)部署 kube-state-metrics,并监控
(8)部署 grafana 服务
(9)监控 metrics.server
(10)alertmanager 部署
(1)部署 Prometheus
#创建kube-ops命名空间
$ kubectl create ns kube-ops1. 创建configmap资源对象。目的是为prometheus提供配置文件。
# 创建 prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: |
global:
scrape_interval: 15s # 表示 prometheus 抓取指标数据的频率,默认是 15s
scrape_timeout: 15s # 表示 prometheus 抓取指标数据的超时时间,默认是 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']2. 创建 prometheus-pvc.yaml
# 创建 prometheus-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: prometheus
namespace: kube-ops
spec:
storageClassName: nfs-client #需要根据自己部署的storageclass名称
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi3. 创建prometheus-rbac.yaml
# 创建 prometheus-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-ops
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-ops4. 创建 prometheus-deploy.yaml
# 创建 prometheus-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus #创建app=prometheus标签的pod
spec:
serviceAccountName: prometheus
containers:
- image: prom/prometheus:v2.4.3 #镜像名称需要根据你自己pull的镜像而定
name: prometheus
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
- "--web.enable-admin-api" # 控制对admin HTTP API的访问,其中包括删除时间序列等功能
- "--web.enable-lifecycle" # 支持热更新,直接执行localhost:9090/-/reload立即生效
ports:
- containerPort: 9090
protocol: TCP
name: http
volumeMounts:
- mountPath: "/prometheus"
subPath: prometheus
name: data
- mountPath: "/etc/prometheus"
name: config-volume
resources:
requests:
cpu: 100m
memory: 512Mi
limits:
cpu: 100m
memory: 512Mi
securityContext:
runAsUser: 0
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus
- configMap:
name: prometheus-config #前面第一步创建的configmap的资源对象名称。
name: config-volume5.创建 prometheus-svc.yaml
# 创建 prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web
port: 9090
targetPort: http部署情况:
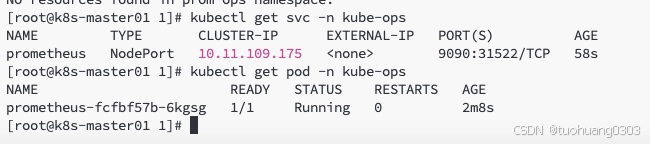
我们看到prometheus服务通过31522端口保留出来了,在浏览器中输入master01的ip以及端口:
点击Status-Targets:
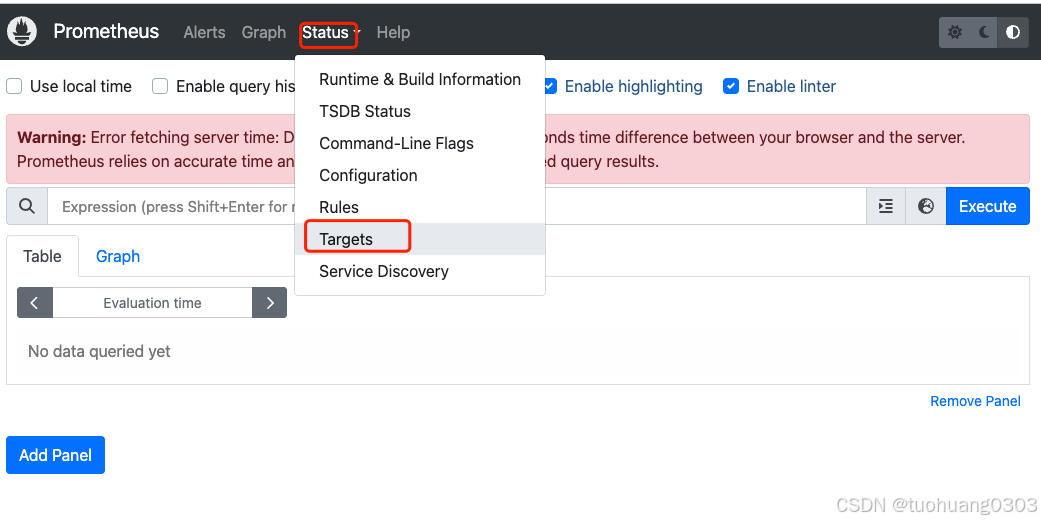
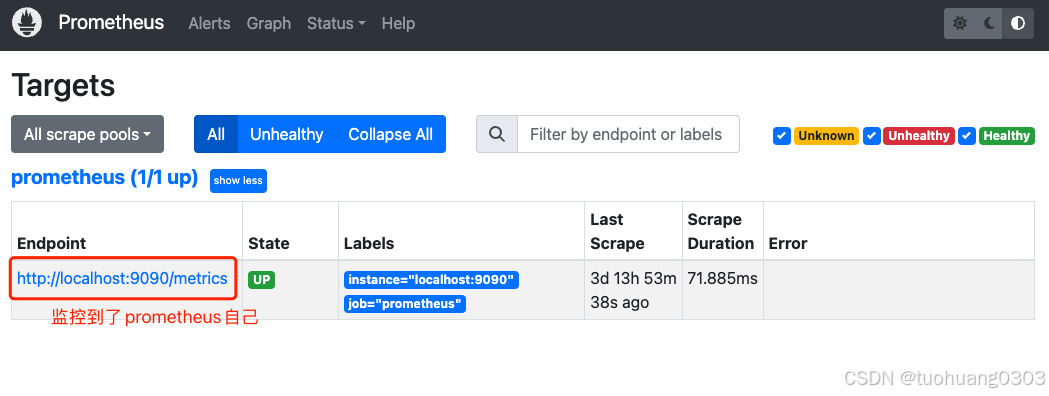
prometheus安装完成之后,我们接下来安装一个ingress-nginx
(2)监控 ingress-nginx
Prometheus 的数据指标是通过一个公开的 HTTP(S) 数据接口获取到的,我们不需要单独安装监控的 agent,只需要暴露一个 metrics 接口,Prometheus 就会定期去拉取数据;对于一些普通的 HTTP 服务,我们完全可以直接重用这个服务,添加一个 /metrics 接口暴露给 Prometheus
首先,我们看下之前部署的ingress-nginx的metrics服务接口的端口是否开启。
一个是可以在node节点上通过命令查看端口是否存在:netstat -antp | grep 10254
前提是你需要知道metirc服务是安装在哪些node上。我的是安装在了node01、node02节点上。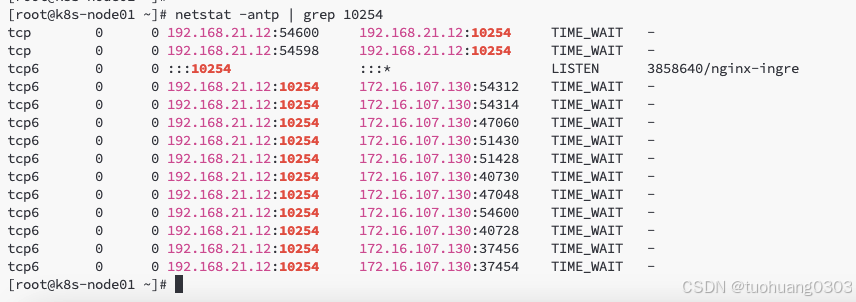
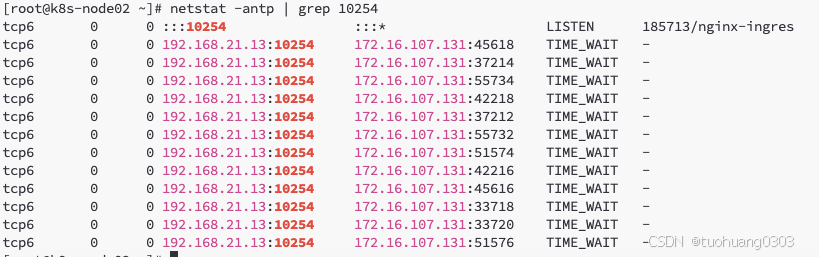 另外一个是可以通过查看service服务中的metircs是否已有了,如下。
另外一个是可以通过查看service服务中的metircs是否已有了,如下。

如果上面都没有找到10254端口开启, 那么需要去找到之前ingress章节里面helm部署的文件夹,我这里是ingress-nginx,找到vaules.yaml文件。

将里面的enabled改为true。
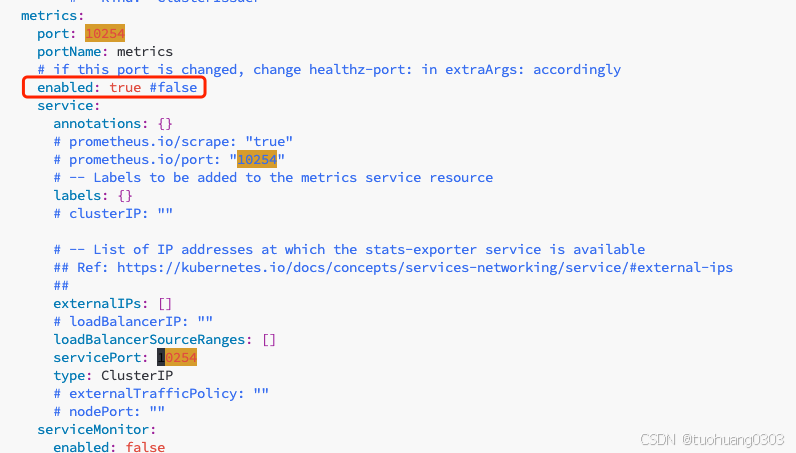
然后upgrade一下。
[root@k8s-master01 10]# helm upgrade ingress-nginx -n ingress ./ingress-nginx -f ./ingress-nginx/values.yaml
开启服务及端口之后,我们可以在浏览器中分别输入两个node的ip以及10254端口看下metrics内容:
node01地址和端口:
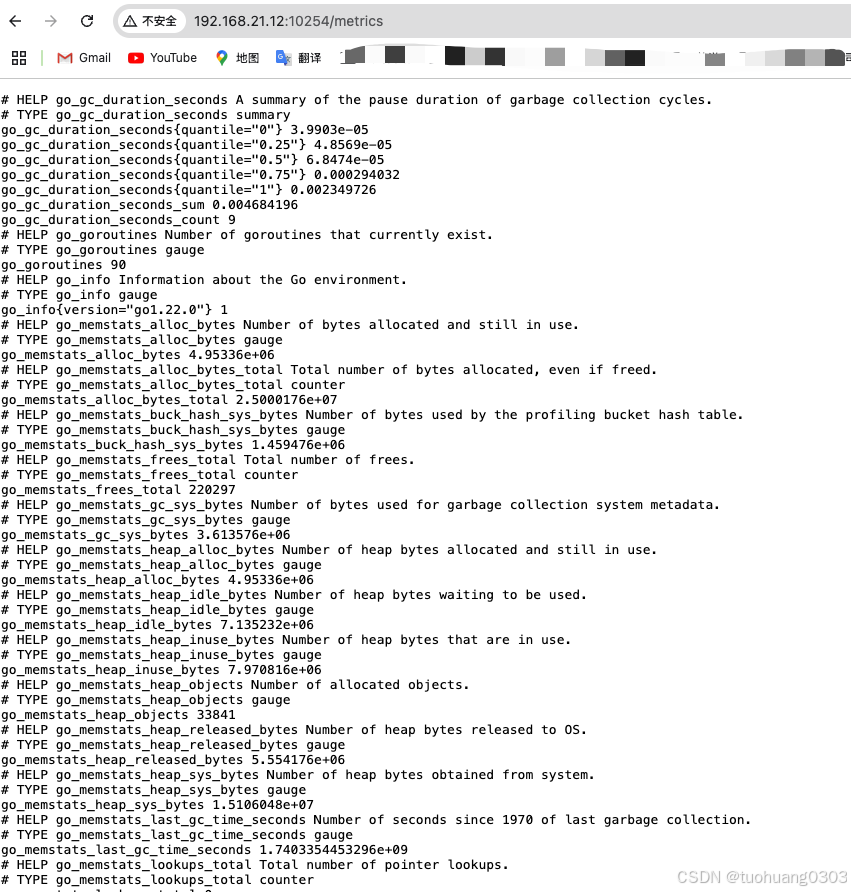
node02地址和端口:
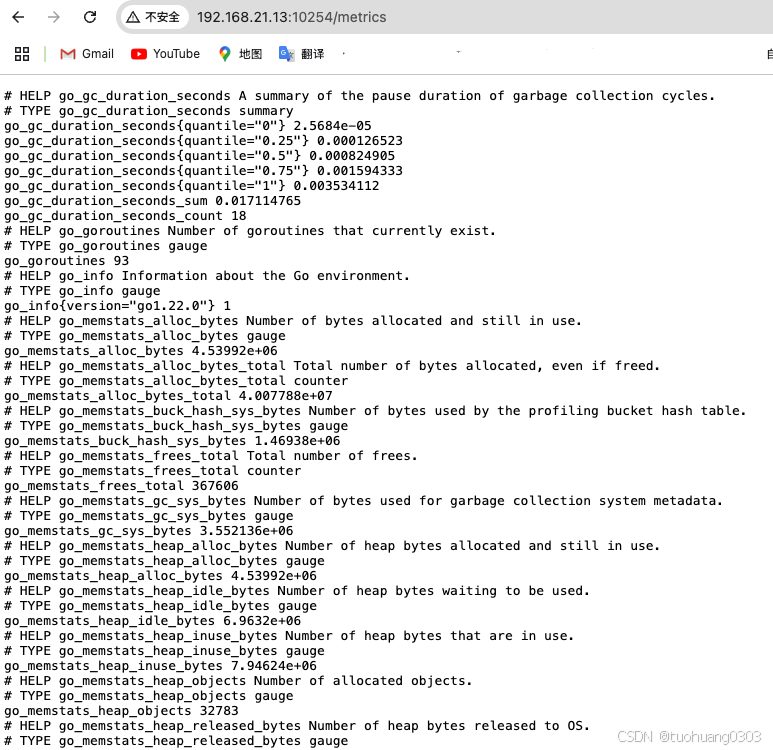
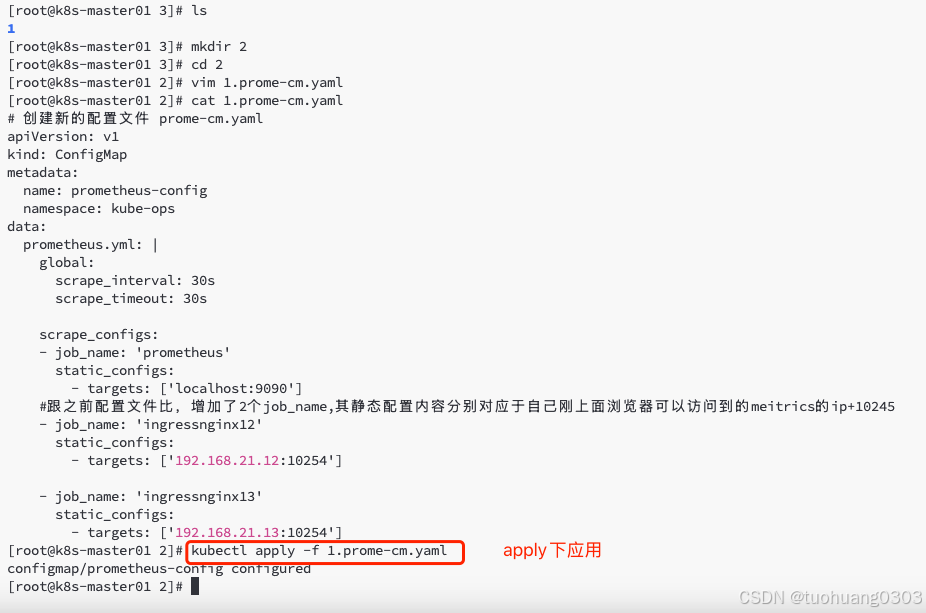
创建一个新的configmap文件,内容比之前第一步创建的多出了两个job_name内容。
# 创建新的配置文件 prome-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: |
global:
scrape_interval: 30s
scrape_timeout: 30s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
#跟之前配置文件比,增加了2个job_name,其静态配置内容分别对应于自己刚上面浏览器可以访问到的meitrics的ip+10245
- job_name: 'ingressnginx12'
static_configs:
- targets: ['192.168.21.12:10254']
- job_name: 'ingressnginx13'
static_configs:
- targets: ['192.168.21.13:10254']通过apply更新下configmap对象。
重载 prometheus,使得prometheus能够通过刚加入的两个metrics接口获取到数据。
[root@k8s-master01 2]# curl -X POST "http://10.11.109.175:9090/-/reload"
我们在prometheus页面里面查看是否获取到metrics数据
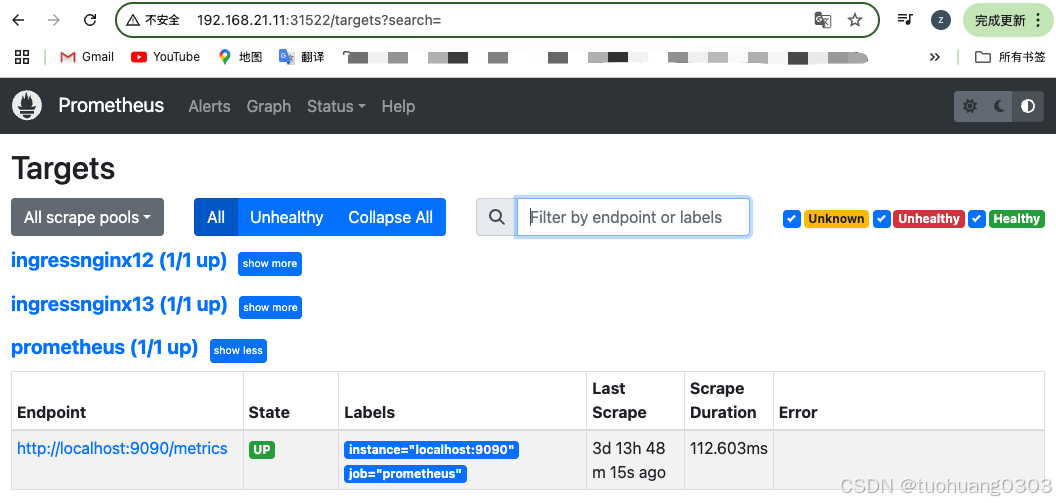
点击show more:
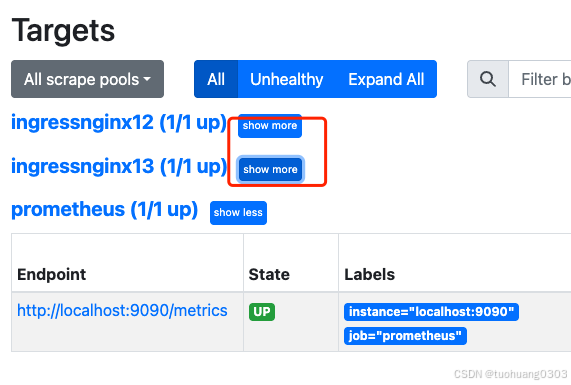
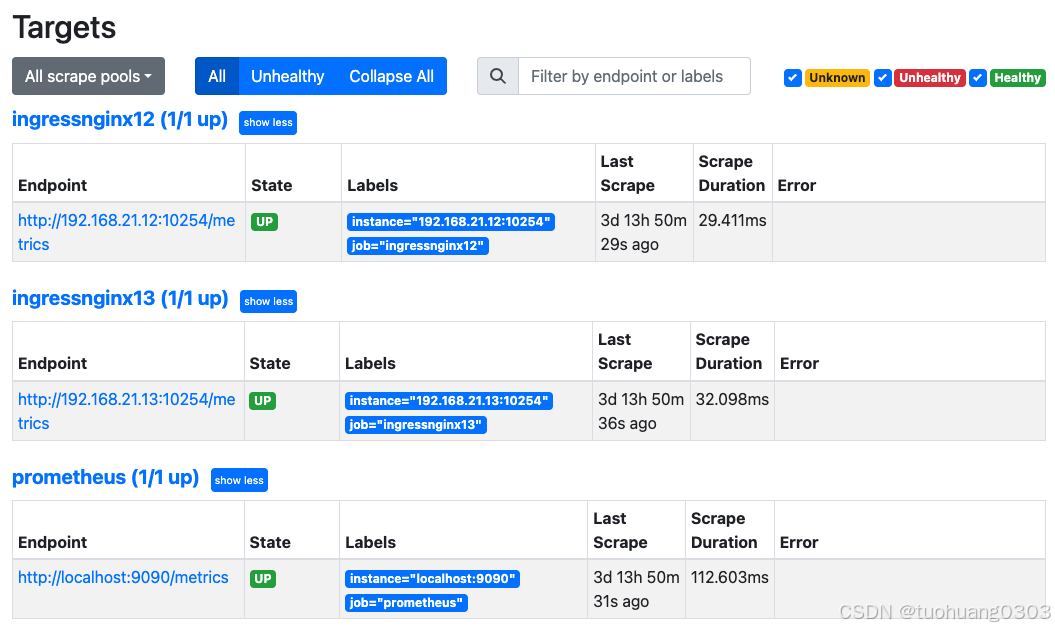
(3)创建node-exporter,监控节点资源
nodeexporter 就是抓取用于采集服务器节点的各种运行指标,目前 nodeexporter 支持几乎所有常见的监控点,比如 conntrack,cpu,diskstats,filesystem,loadavg,meminfo,netstat 等,详细的监控点列表可以参考其 Github repo
创建 prome-node-exporter.yaml,资源类别是daemonset,目的是在每个node主机节点上部署prom/node-exporter镜像容器,获取主机节点的运行指标。
# 创建 prome-node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-ops
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true #PID,IPC,Network打开表示,容器和主机共享相同的命名空间
hostIPC: true
hostNetwork: true
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0 #如果你是arm架构的服务器,需要注意使用arm架构的镜像。
ports:
- containerPort: 9100
resources:
requests:
cpu: 0.15
securityContext:
privileged: true #开启特权模式,因为需要抓去物理主机的相关信息
args:
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"' #排除这些挂载点,不监控相关数据
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations: #设置容忍
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /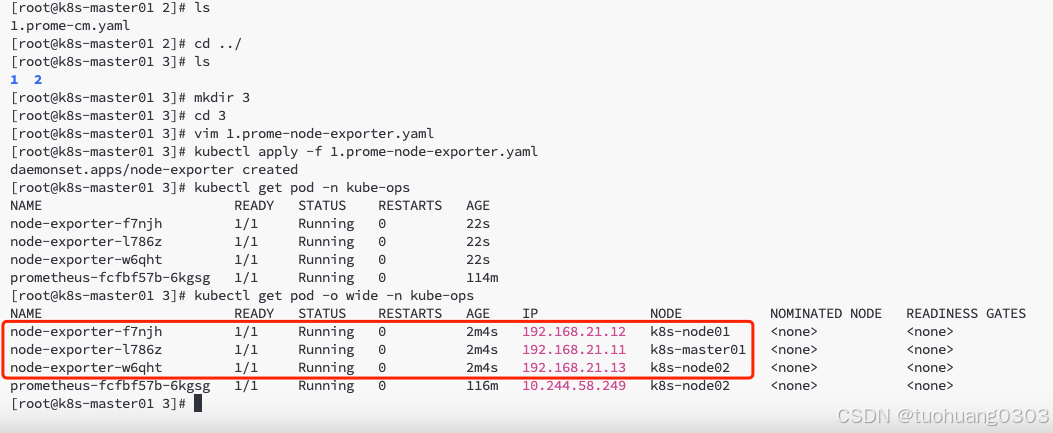
创建完成之后,还没有完成,还需要对1.prome_cm.yaml中configmap配置资源清单文件的修改才行。
1)添加 node-exporter 至 Prometheus 捕获
这一项的目的是监控node相关信息。
在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成,目前主要支持 5 种服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress。
通过指定 kubernetes_sd_configs 的模式为 node,Prometheus 就会自动从 Kubernetes 中发现所有的 node 节点并作为当前 job 监控的目标实例,发现的节点 /metrics 接口是默认的 kubelet 的 HTTP 接口。
prometheus 去发现 Node 模式的服务的时候,访问的端口默认是10250。不过目前我们通过 node-exporter 的pod抓取到的节点指标数据,配置中指定了hostNetwork=true(与物理主机节点共享网络),以及指定了容器端口为9100。
ports:
- containerPort: 9100
所以在每个pod部署所在的物理主机节点上就会绑定一个端口 9100。
下面的这个job做的目标就是将原来的默认的10250替换为9100端口,并且将物理节点node标签加到监控数据里面去。
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs: #自动发现配置
- role: node #发现类型为node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) #将node节点标签加到监控数据里面去,固定写法,以便确定数据的来源是哪个node节点。
对于 kubernetessdconfigs 下面可用的元标签如下:
- _meta_kubernetes_node_name:节点对象的名称
- _meta_kubernetes_node_label:节点对象中的每个标签。如上使用的示例。
- _meta_kubernetes_node_annotation:来自节点对象的每个注释
- _meta_kubernetes_node_address:每个节点地址类型的第一个地址(如果存在) *
关于 kubernetssdconfigs 更多信息可以查看官方文档:kubernetessdconfig
2)kubelet metrics 接口添加监控
这一项的目的是监控pod相关信息。(但是为什么在role中配置的是node呢?)
Kubernetes 1.11+ 版本以后,kubelet 就移除了 10255 端口, metrics 接口回到了 10250 端口也就是 node 自动发现监控的默认端口,但是需要使用 https 的协议。
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs: #自动发现配置
- role: node #发现类型为node
scheme: https #当前协议为https,因为是https,所以需要进行认证的相关配置
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #CA证书存放地址
insecure_skip_verify: true #证书验证跳过为true,即跳过证书验证,如果觉得不安全就改为false
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #指定SA的token,用于认证
relabel_configs: #标签的配置
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) #将node节点标签加到监控数据里面去,固定写法,以便确定数据的来源是哪个node节点。 同上。
3)合并上面1-2的配置项,添加进Prometheus configmap 配置文件中
# 创建新的配置文件 prome-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: |
global:
scrape_interval: 30s
scrape_timeout: 30s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
#跟之前配置文件比,增加了2个job_name,其静态配置内容分别对应于自己刚上面浏览器可以访问到的meitrics的ip+10245
- job_name: 'ingressnginx12'
static_configs:
- targets: ['192.168.21.12:10254']
- job_name: 'ingressnginx13'
static_configs:
- targets: ['192.168.21.13:10254']
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs: #自动发现配置
- role: node #发现类型为node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs: #自动发现配置
- role: node #发现类型为node
scheme: https #当前协议为https,因为是https,所以需要进行认证的相关配置
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #CA证书存放地址
insecure_skip_verify: true #证书验证跳过为true,即跳过证书验证,如果觉得不安全就改为false
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #指定SA的token,用于认证
relabel_configs: #标签的配置
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) #将node节点标签加到监控数据里面去,固定写法,以便确定数据的来源是哪个node节点。 同上.apply更新配置文件。
[root@k8s-master01 3]# kubectl apply -f 1.prome-cm.yaml
configmap/prometheus-config configured
稍微等待下,触发prometheus重载:
[root@k8s-master01 2]# curl -X POST "http://10.11.109.175:9090/-/reload"
我们在prometheus页面里面查看是否获取到metrics数据
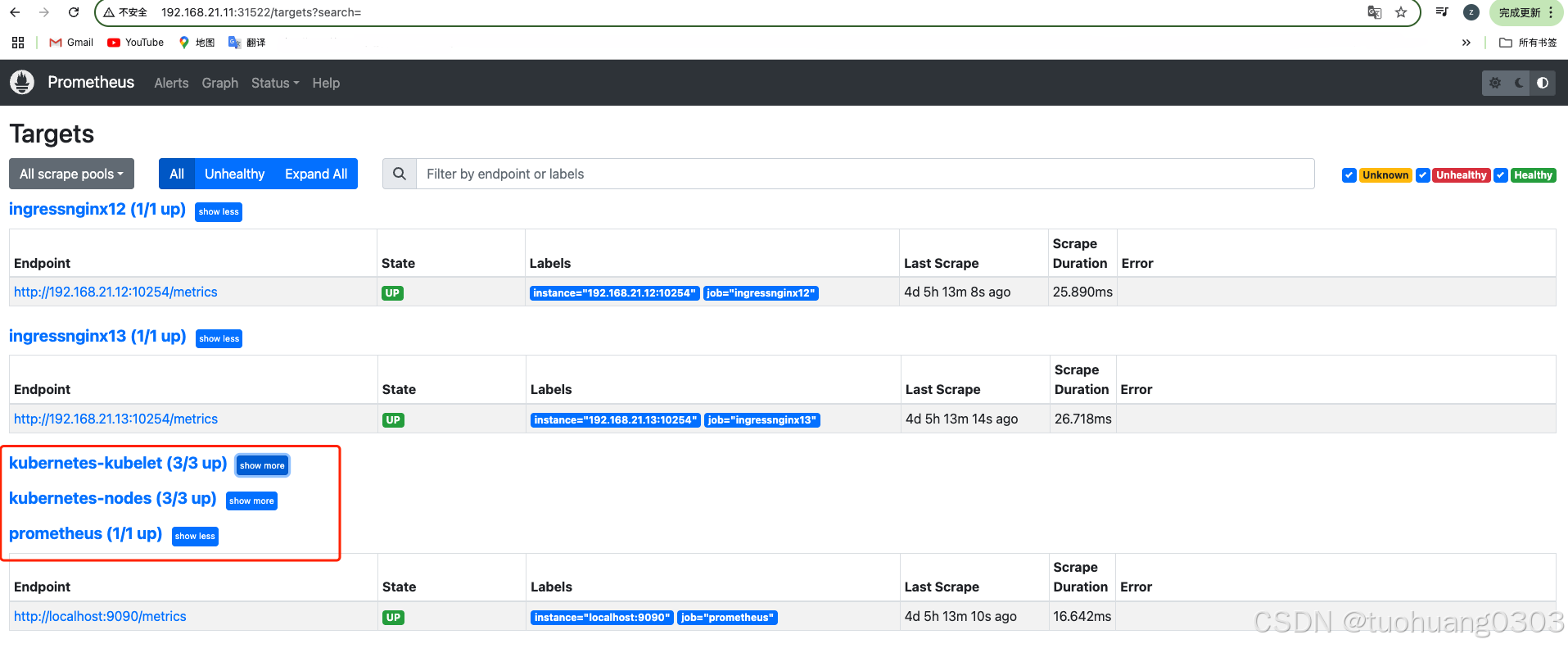
这是对kubelet的监控(间接可以知道节点有多少pod,以及重启了多少次等等pod的信息):
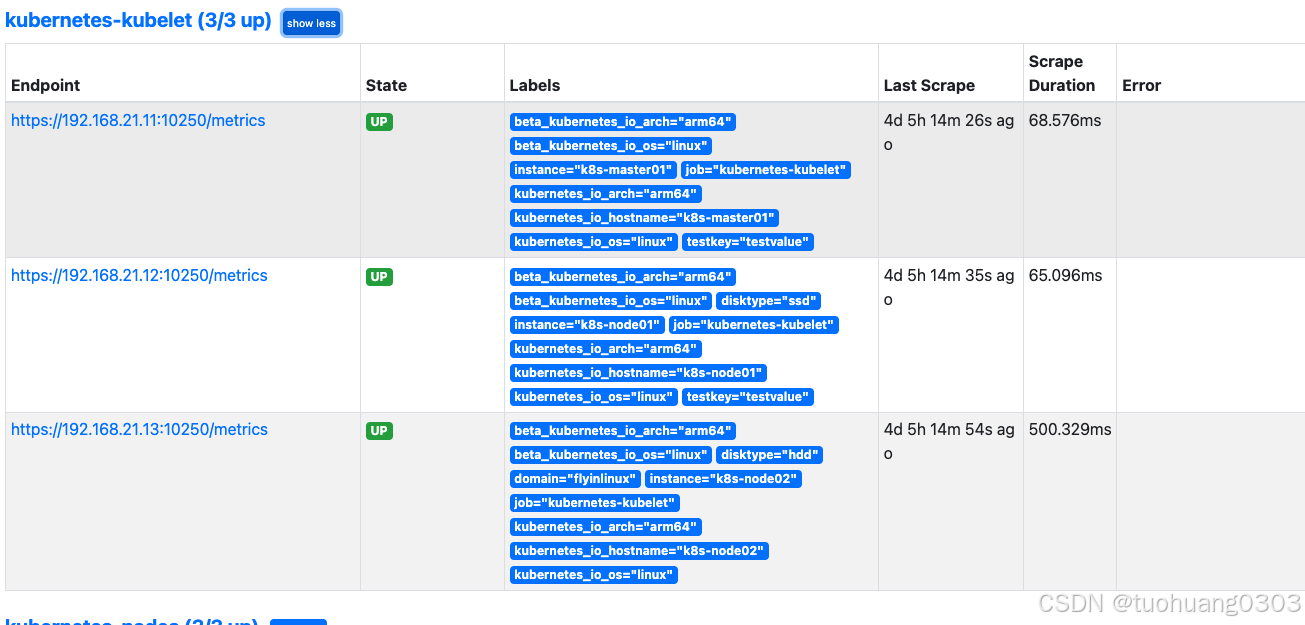
这是对node的监控:
(4)监控容器资源指标
说到容器监控我们自然会想到cAdvisor,我们前面也说过cAdvisor已经内置在了 kubelet 组件之中,所以我们不需要单独去安装,cAdvisor的数据路径为/api/v1/nodes/<node>/proxy/metrics,同样我们这里使用 node 的服务发现模式,因为每一个节点下面都有 kubelet。
我们在原来的prom-cm.yaml基础上增加cAdvisor的配置信息。
# 创建新的配置文件 prome-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: |
global:
scrape_interval: 30s
scrape_timeout: 30s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
#跟之前配置文件比,增加了2个job_name,其静态配置内容分别对应于自己刚上面浏览器可以访问到的meitrics的ip+10245
- job_name: 'ingressnginx12'
static_configs:
- targets: ['192.168.21.12:10254']
- job_name: 'ingressnginx13'
static_configs:
- targets: ['192.168.21.13:10254']
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs: #自动发现
- role: node #发现类型为node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs: #自动发现
- role: node #发现类型为node
scheme: https #当前协议为https,因为是https,所以需要进行认证的相关配置
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #CA证书存放地址
insecure_skip_verify: true #证书验证跳过为true,即跳过证书验证,如果觉得不安全就改为false
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #指定SA的token,用于认证
relabel_configs: #标签的配置
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) #将node节点标签加到监控数据里面去,固定写法,以便确定监控的数据的来源是哪个node节点。 同上。
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs: #自动发现
- role: node #发现类型为node
scheme: https #当前协议为https,因为是https,所以需要进行认证的相关配置
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #CA证书存放地址
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #指定SA的token,用于认证
relabel_configs: #标签的配置
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) #将node节点标签加到监控数据里面去,固定写法,以便确定监控的数据的来源是哪个node节点。 同上。
- target_label: __address__ #替换当前地址
replacement: kubernetes.default.svc:443 #替换的目标地址
- source_labels: [__meta_kubernetes_node_name] #对节点名进行以下操作
regex: (.+) #所有匹配
target_label: __metrics_path__ #其中的访问路径部分进行替换
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor #替换成目标路径,其中${1}表示当前节点名 [root@k8s-master01 4]# kubectl apply -f 1.prome-cm.yaml
configmap/prometheus-config configured
等待一会之后,执行热重启:
[root@k8s-master01 4]# curl -X POST "http://10.11.109.175:9090/-/reload"
如果在浏览器中没有找到如下的监控内容,可以等一会后再执行热重启命令。
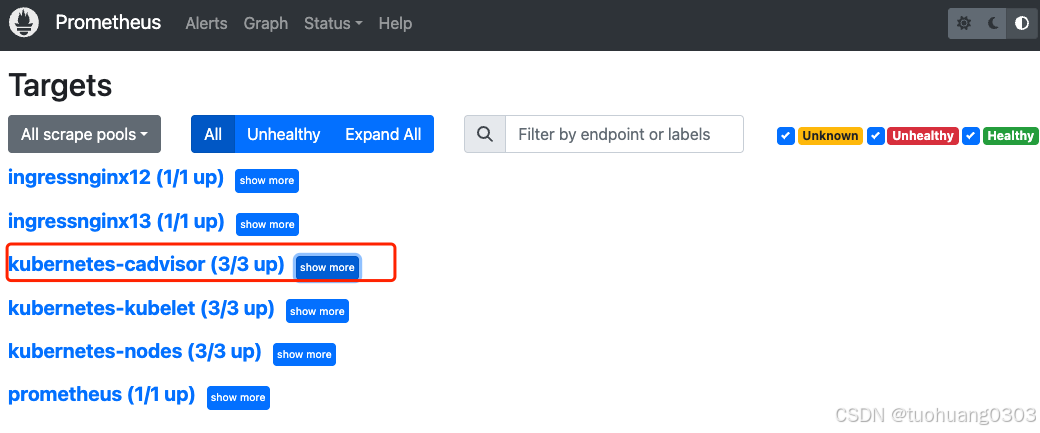
(5)监控ApiServer指标
ApiServer的请求频率,总请求量等等,我们也可以监控。我们通过监控ApiServer相关指标,判断是否其压力过大,也是可以评估我们kubernetes集群是否正常的重要的指标。需要将其监控起来。
同样在原来的cm资源文件后面增加相关内容。
# 创建新的配置文件 prome-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: |
global:
scrape_interval: 30s
scrape_timeout: 30s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
#跟之前配置文件比,增加了2个job_name,其静态配置内容分别对应于自己刚上面浏览器可以访问到的meitrics的ip+10245
- job_name: 'ingressnginx12'
static_configs:
- targets: ['192.168.21.12:10254']
- job_name: 'ingressnginx13'
static_configs:
- targets: ['192.168.21.13:10254']
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs: #自动发现
- role: node #发现类型为node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs: #自动发现
- role: node #发现类型为node
scheme: https #当前协议为https,因为是https,所以需要进行认证的相关配置
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #CA证书存放地址
insecure_skip_verify: true #证书验证跳过为true,即跳过证书验证,如果觉得不安全就改为false
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #指定SA的token,用于认证
relabel_configs: #标签的配置
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) #将node节点标签加到监控数据里面去,固定写法,以便确定监控的数据的来源是哪个node节点。 同上。
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs: #自动发现
- role: node #发现类型为node
scheme: https #当前协议为https,因为是https,所以需要进行认证的相关配置
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #CA证书存放地址
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #指定SA的token,用于认证
relabel_configs: #标签的配置
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) #将node节点标签加到监控数据里面去,固定写法,以便确定监控的数据的来源是哪个node节点。 同上。
- target_label: __address__ #替换当前地址
replacement: kubernetes.default.svc:443 #替换的目标地址
- source_labels: [__meta_kubernetes_node_name] #对节点名进行以下操作
regex: (.+) #所有匹配
target_label: __metrics_path__ #其中的访问路径部分进行替换
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor #替换成目标路径,其中${1}表示当前节点名
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs: #自动发现
- role: endpoints #端点的发现
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs: #标签的配置
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] #匹配当前的命名空间,当前服务名,当前端点名称
action: keep
regex: default;kubernetes;https操作同上。在浏览器可以看到如下结果: 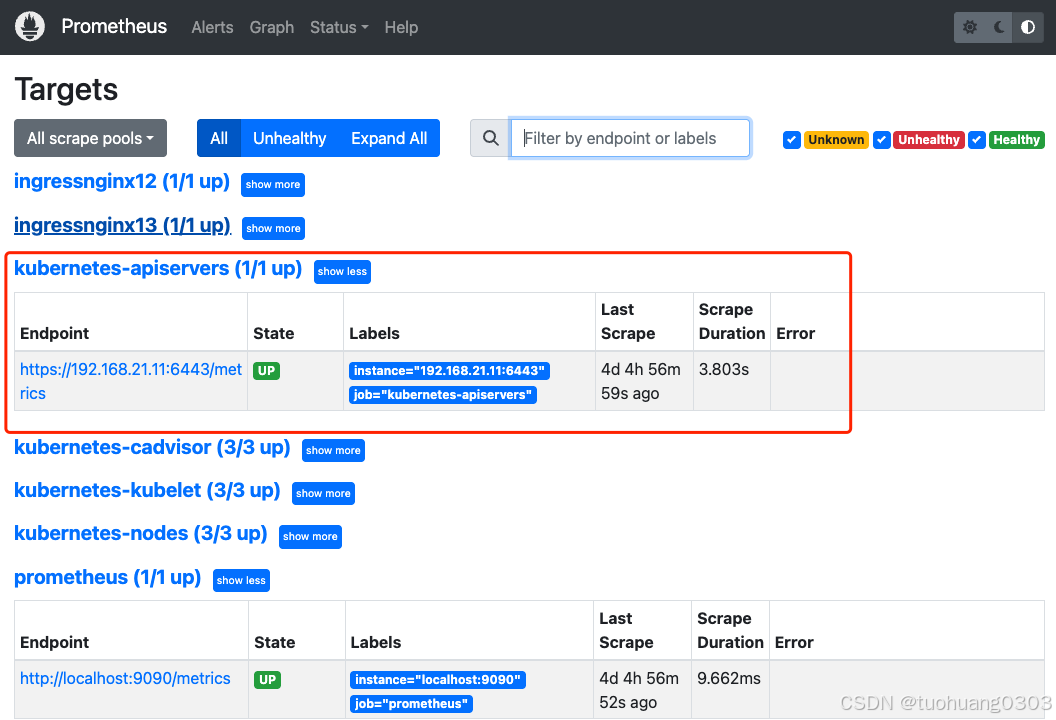
(6)通过 Service 监控服务
# 创建新的配置文件 prome-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: |
global:
scrape_interval: 30s
scrape_timeout: 30s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
#跟之前配置文件比,增加了2个job_name,其静态配置内容分别对应于自己刚上面浏览器可以访问到的meitrics的ip+10245
- job_name: 'ingressnginx12'
static_configs:
- targets: ['192.168.21.12:10254']
- job_name: 'ingressnginx13'
static_configs:
- targets: ['192.168.21.13:10254']
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs: #自动发现
- role: node #发现类型为node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs: #自动发现
- role: node #发现类型为node
scheme: https #当前协议为https,因为是https,所以需要进行认证的相关配置
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #CA证书存放地址
insecure_skip_verify: true #证书验证跳过为true,即跳过证书验证,如果觉得不安全就改为false
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #指定SA的token,用于认证
relabel_configs: #标签的配置
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) #将node节点标签加到监控数据里面去,固定写法,以便确定监控的数据的来源是哪个node节点。 同上。
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs: #自动发现
- role: node #发现类型为node
scheme: https #当前协议为https,因为是https,所以需要进行认证的相关配置
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #CA证书存放地址
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #指定SA的token,用于认证
relabel_configs: #标签的配置
- action: labelmap
regex: __meta_kubernetes_node_label_(.+) #将node节点标签加到监控数据里面去,固定写法,以便确定监控的数据的来源是哪个node节点。 同上。
- target_label: __address__ #替换当前地址
replacement: kubernetes.default.svc:443 #替换的目标地址
- source_labels: [__meta_kubernetes_node_name] #对节点名进行以下操作
regex: (.+) #所有匹配
target_label: __metrics_path__ #其中的访问路径部分进行替换
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor #替换成目标路径,其中${1}表示当前节点名
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs: #自动发现
- role: endpoints #端点的发现
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs: #标签的配置
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] #匹配当前的命名空间,当前服务名,当前端点名称
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true #在relabel_configs中过滤了 annotation 有prometheus.io/scrape=true的 Service
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name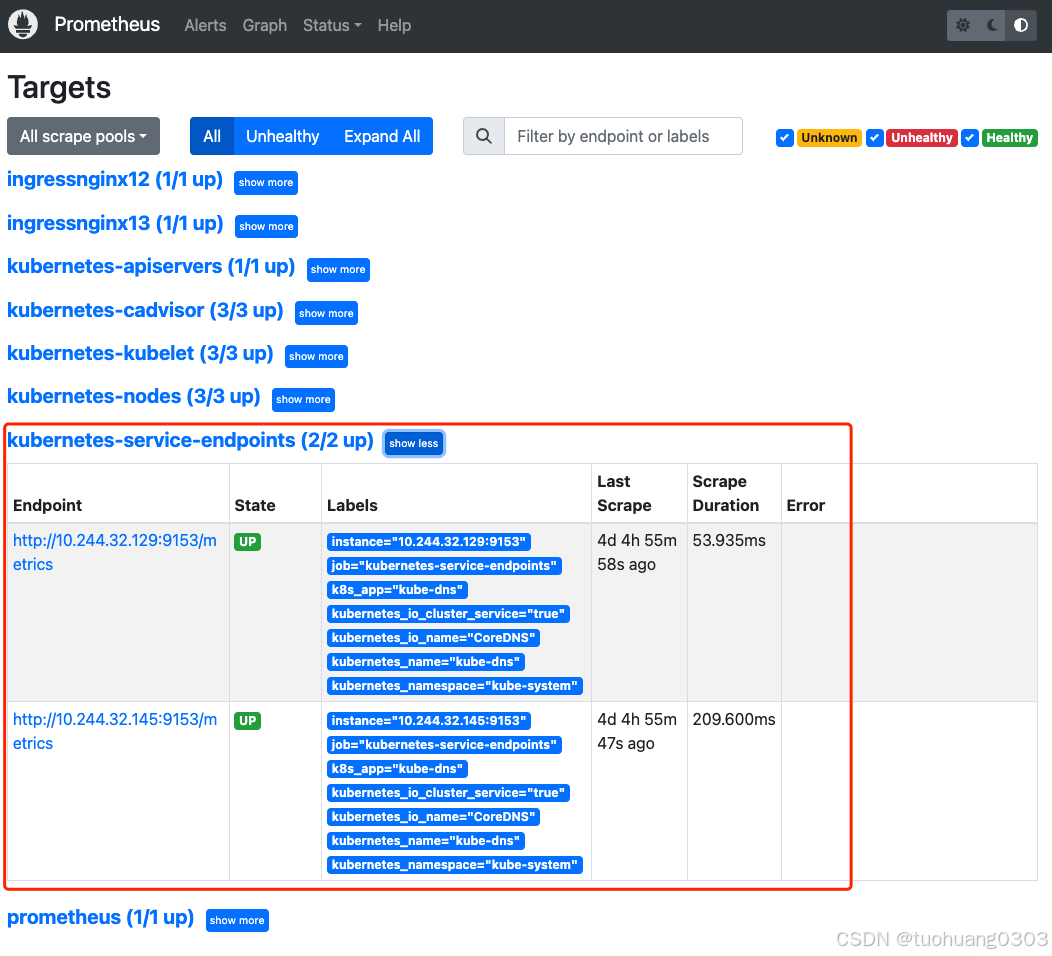
(7)部署 kube-state-metrics,并监控
# 部署 kube-state-metrics,地址 https://github.com/kubernetes/kube-state-metrics
$ kubectl apply -f examples/standard
# 创建 kube-state-metrics 服务的 svc 文件,被监控,svc.yaml
apiVersion: v1
kind: Service
metadata:
annotations: #自动会被上面configmap中的'kubernetes-service-endpoints'所监控到
prometheus.io/scrape: 'true'
prometheus.io/port: "8080" #默认为9100,修改默认端口
namespace: kube-system
labels:
app: kube-state-metrics
name: kube-state-metrics-exporter
spec:
ports:
- name: 8080-8080
port: 8080 #集群接口端口8080
protocol: TCP
targetPort: 8080 #后端真实服务器8080
selector:
app.kubernetes.io/name: kube-state-metrics #锁定带有这样标签的pod
type: ClusterIP(8)部署 grafana 服务
# 创建 grafana 部署文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: kube-ops
labels:
app: grafana
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:5.3.4
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: 100m
memory: 256Mi
requests:
cpu: 100m
memory: 256Mi
volumeMounts:
- mountPath: /var/lib/grafana
subPath: grafana
name: storage
securityContext:
fsGroup: 472
runAsUser: 472
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana
# 创建 grafana 存储 pv,grafana-volume.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana
namespace: kube-ops
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
# 创建 grafan svc 文件,grafana-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-ops
labels:
app: grafana
spec:
type: NodePort
ports:
- port: 3000
selector:
app: grafana
# 创建 job,调整 grafana 挂载目录权限,grafana-chown-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: grafana-chown
namespace: kube-ops
spec:
template:
spec:
restartPolicy: Never
containers:
- name: grafana-chown
command: ["chown", "-R", "472:472", "/var/lib/grafana"]
image: busybox
imagePullPolicy: IfNotPresent
volumeMounts:
- name: storage
subPath: grafana
mountPath: /var/lib/grafana
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana 

用户名admin,密码admin321,这个是我们在deployment资源清单中配置的。login登陆进去。
我们接下来通过grafana的仪表盘可视化监控数据(prometheus)。
仪表盘配置
因为grafana并不存储数据,他需要通过引入其他数据源,拉取数据源数据进行可视化展示。
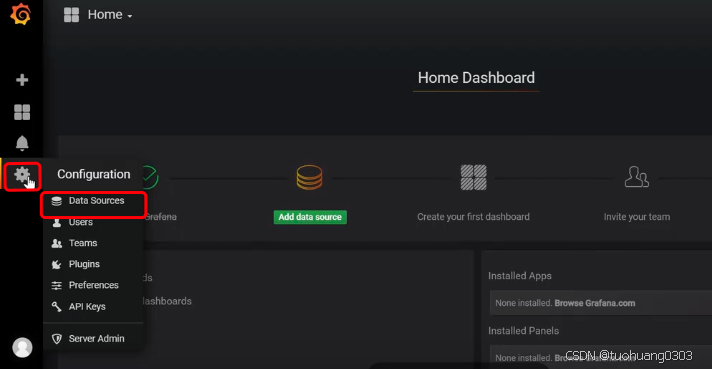
首先我们配置数据来源。点击“设置”- “data sources”。
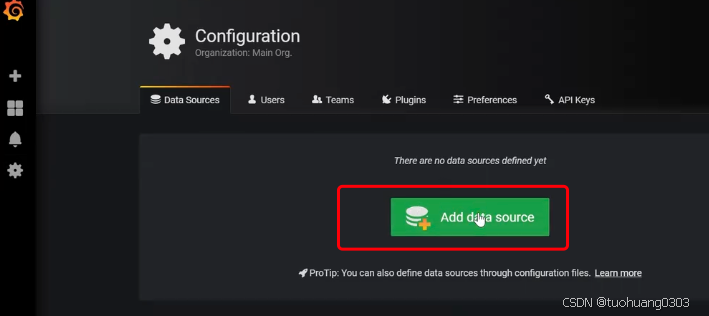
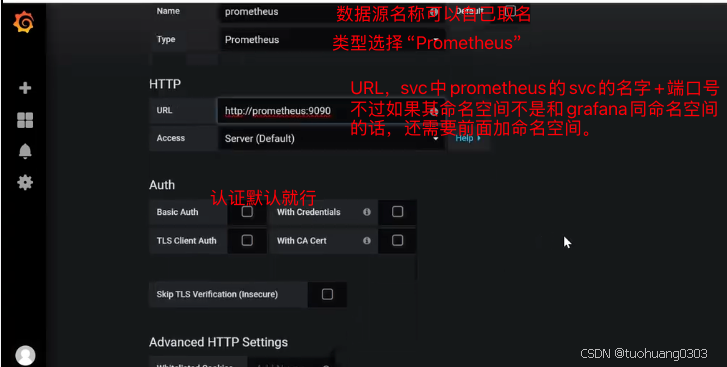
配置数据源:

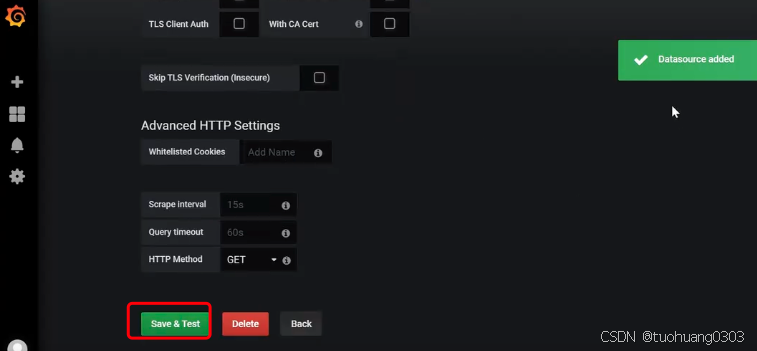
还没有仪表盘,我们需要添加仪表盘:
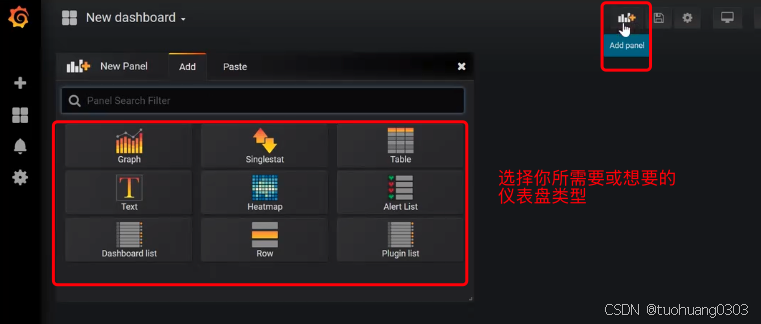
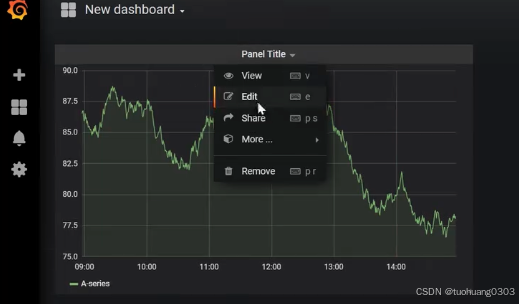
我们选择Graph,然后点击“Edit”编辑。
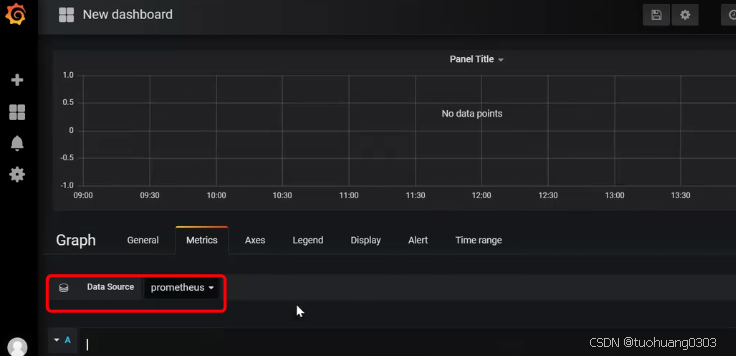
在Data Source里面选择“Prometheus”。
下面需要输入PQL语句,我们可以先从prometheus中选择以及输入PQL查询语句:
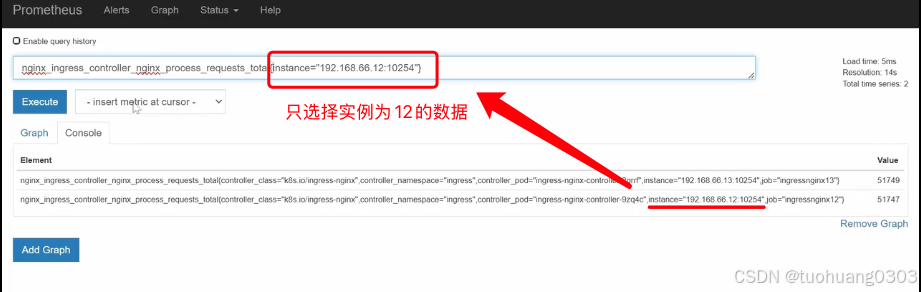
将其PQL语句复制,粘贴到grafana界面的输入框中。
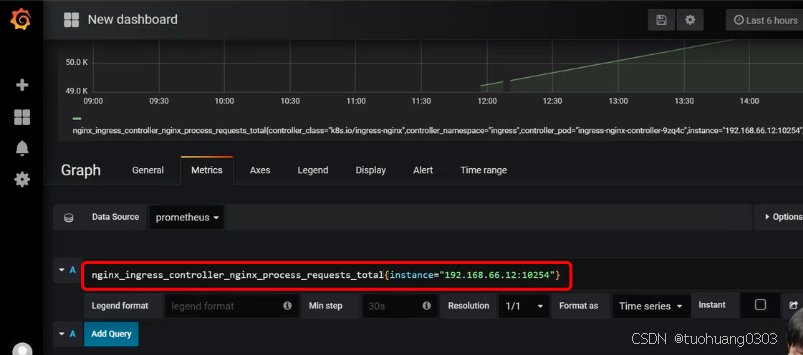
可以为这个graph图表起一个名字,点击general。在title中输入名称,然后点击save dashboard。
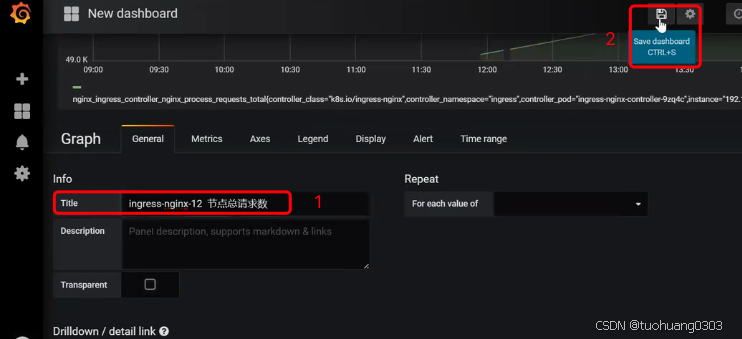
在弹出来的框中,可以不改任何信息,点击save。
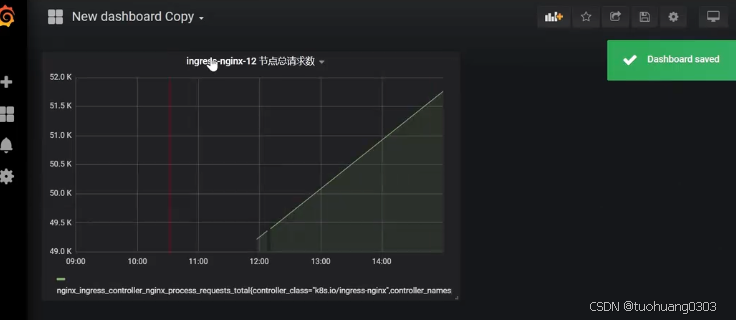
可以看到仪表盘dashboard创建成功了。
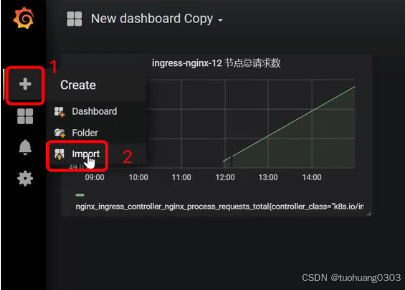
导入仪表盘配置
另外可以通过Import导入之前保存的仪表盘配置信息。
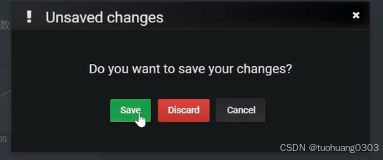
提示是否想保存你的修改。可以点击save保存。
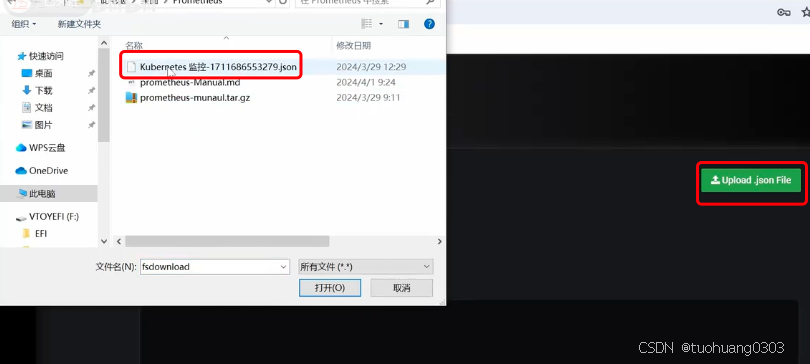
点击Upload .json File按钮,选择相关的Json文件。
选择prometheus的数据源。再点击下面的Import。
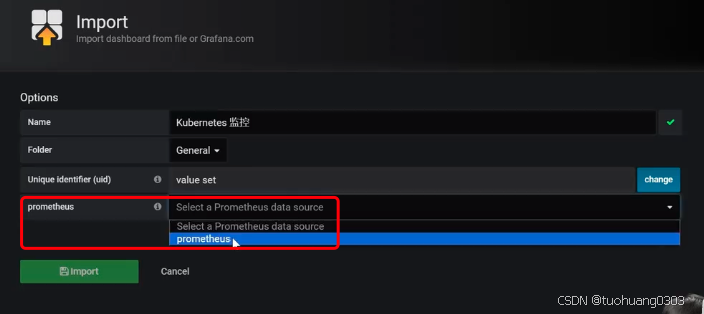
可以看到已经导入成功。
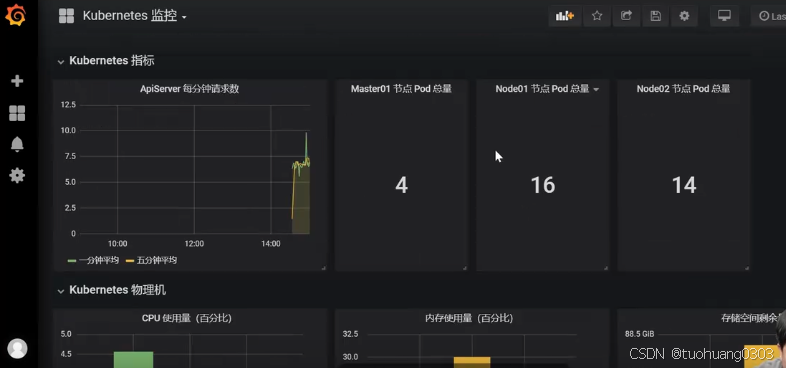
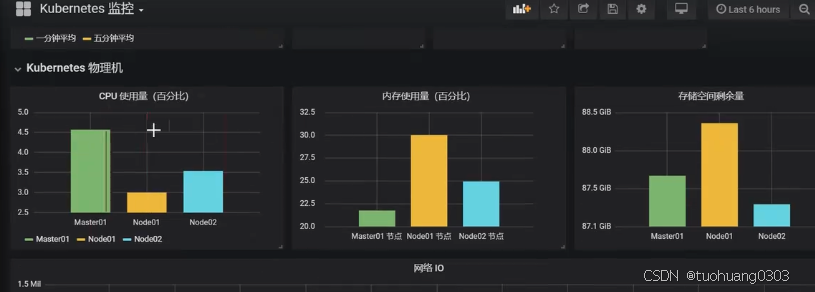
(9)部署metric.server监控
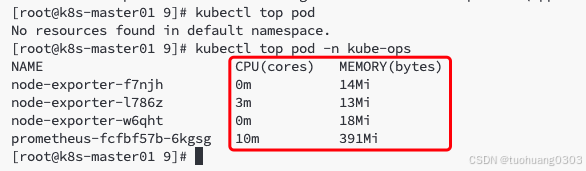
从 Kubernetes v1.8 开始,资源使用情况的监控可以通过 Metrics API 的形式获取,例如容器 CPU 和内存使用率。这些度量可以由用户直接访问(例如,通过使用 kubectl top 命令),或者由集群中的控制器(例如,Horizontal Pod Autoscaler)使用来进行决策,具体的组件为 Metrics Server,用来替换之前的 heapster,heapster 从 1.11 开始逐渐被废弃。
Metrics-Server 是集群核心监控数据的聚合器。通俗地说,它存储了集群中各节点的监控数据,并且提供了 API 以供分析和使用。Metrics-Server 作为一个 Deployment 对象默认部署在 Kubernetes 集群中。不过准确地说,它是 Deployment,Service,ClusterRole,ClusterRoleBinding,APIService,RoleBinding 等资源对象的综合体。
metric-server监控数据的原理图:
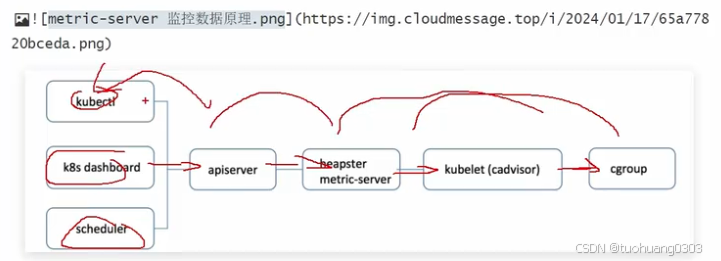
通过metric-server监控数据的原理图如上所示,当前端比如kubectl命令、k8s dashboard以及scheduler等获取监控数据的时候,他们会调用api-server接口,api-server接口去请求metric-server或者heapster,metric-server或者heapster去请求kubelet(cadvisor),然后其再去请求cgroup,获取到相关监控数据后,依次返回,最终返回到前端。
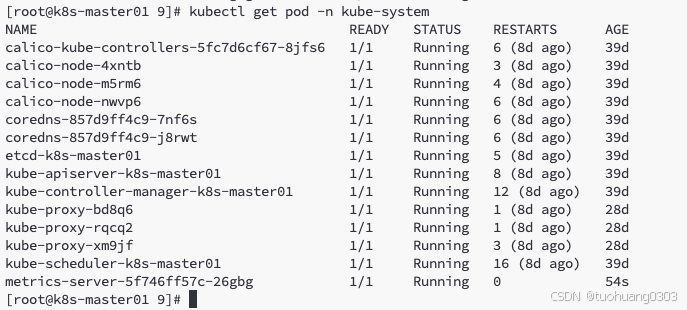
一开始没有部署相关资源对象,是无法获取监控数据的。如下:
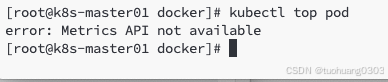
目前还没有激活,需要完成相关部署才行。从上图上可以看出,api-server接口本身集群安装就必须有的了,cgroup也是存在的,除此之外之前我们已完成了kubelet中的cadvisor的部署了,所以 现在剩下只需要将metric-server部署完成即可。
metric-server部署过程如下:
下载https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml 文件到本地。
[root@k8s-master01 9]# wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
####ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system #官方习惯,但凡是系统集群本身使用的话,都一般放在kube-system命名空间下。
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
####创建Service
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
####Deployment控制器,创建pod
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=10250
## InternalIP\Hostname\InternalDNS\ExternalDNS\ExternalIP, Hostname 默认的通过主机名通讯,InternalIP 需要显示设置后才能通过 IP 通讯
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls ## 如果不想设置 kubelet 的证书认证,可以通过此选项跳过认证
image: registry.k8s.io/metrics-server/metrics-server:v0.7.2 #如果因为网络拉取不下来,可以使用docker.imgdb.de/registry.k8s.io/metrics-server/metrics-server:v0.7.2镜像名
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 10250
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
seccompProfile:
type: RuntimeDefault
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
####添加apiservice接口,可以被我们的kubectl的top命令所读取
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true #跳过TLS认证。
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100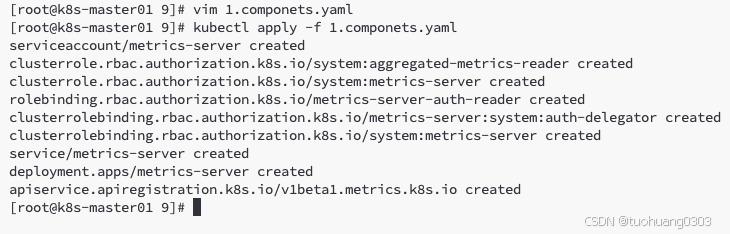
(10) AlertManager部署
告警器。我们部署alertmanager,检验是否真的能够发送对应的报警信息。
1)部署configmap文件,设置告警相关的配置信息。
# 创建 alertmanager 配置文件,alertmanager-conf.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: kube-ops
data:
config.yml: |-
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'wangyanglinux@163.com'
smtp_auth_username: 'wangyanglinux@163.com'
smtp_auth_password: 'xxxx' # 这个是授权密码。需要在163邮箱里面找到设置,获取授权密码。
smtp_hello: '163.com'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: email
group_wait: 10s
match:
team: node
receivers:
- name: 'default'
email_configs:
- to: 'wangyanglinux@88.com'
send_resolved: true
- name: 'email'
email_configs:
- to: 'wangyanglinux@88.com'
send_resolved: true其中邮箱密码不是你登陆邮箱的密码,而是授权密码。具体可以参考如下:
2)修改 prometheus 配置文件,prometheus-cm.yaml
主要增加的是以下内容。因为prometheus和alertmanager是同一家公司开发,他们可以一起进行配置。
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
这里为什么是localhost,是因我们将alertmanager部署到prometheus同一个pod里面上,所以可以使用localhost。
# 修改 prometheus 配置文件,prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: |
global:
scrape_interval: 30s
scrape_timeout: 30s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'ingressnginx12'
static_configs:
- targets: ['192.168.21.12:10254']
- job_name: 'ingressnginx13'
static_configs:
- targets: ['192.168.21.13:10254']
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]3)修改 prometheus service 文件, prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web #prometheus配置的端口
port: 9090
targetPort: http
- name: altermanager #新增altermanager配置内容
port: 9093
targetPort: 9093
















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









