







 本文介绍如何利用PyQuery库进行HTML和XML的快速操作,包括安装方法、基本使用及属性操作等,适用于爬虫数据抓取和分析。
本文介绍如何利用PyQuery库进行HTML和XML的快速操作,包括安装方法、基本使用及属性操作等,适用于爬虫数据抓取和分析。
setuptools绝对是个好东西,它可以自动的安装模块,只需要你提供给它一个模块名字就可以了,并且自动帮你解决模块的依赖问题。一般情况下用setuptools给安装的模块会自动放到一个后缀是.egg的目录里,下面看看怎么用setuptools。
首先,需要安装setuptools这个东西,安装它很简单,先去下载一个脚本: http://peak.telecommunity.com/dist/ez_setup.py 下载完后直接执行它就会帮你把setuptools给装好了。
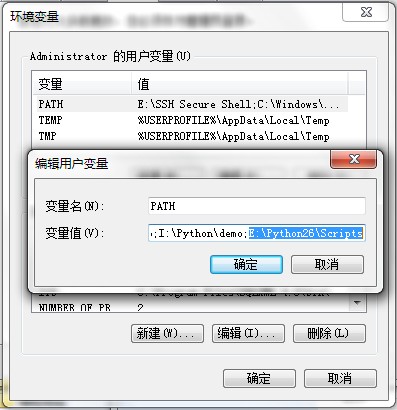
之后安装模块的使用方法就是使用一个叫easy_install的命令,在Windows里,这个命令在python安装目录下的scripts里面,所以需要把scripts加到环境变量的PATH里,如下图所示。这样用起来就更方便,linux下不需要注意这个问题。
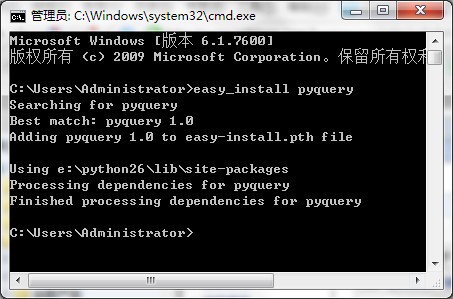
安装软件只需要执行
easy_install 模块名
就可以了,比如要安装pyquery,就把上面的模块名换成 pyquery 就可以了。
PyQuery是一个类似于jQuery的Python库,也可以说是jQuery在Python上的实现。pyQuery是使用lxml来实现快速的xml和html操作的。具体的PyQuery文档见:http://pyquery.org/
用这个来做蜘蛛爬数据的时候分析html并从中提取数据还是很爽的。
废话不多说,直接看一点简单的例子吧:
作者:黄聪
出处:http://www.cnblogs.com/huangcong/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
出处:http://www.cnblogs.com/huangcong/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









