







 本文详细解析了在建立NER模型时遇到的TypeError,深入分析了问题根源在于concatV2操作接受的不同类型张量,并给出了修改mask_zero参数的解决方案。
本文详细解析了在建立NER模型时遇到的TypeError,深入分析了问题根源在于concatV2操作接受的不同类型张量,并给出了修改mask_zero参数的解决方案。
1 问题描述
在建立NER识别模型时出现:
TypeError: Tensors in list passed to 'values' of 'ConcatV2' Op have types [bool, float32] that don't all match.
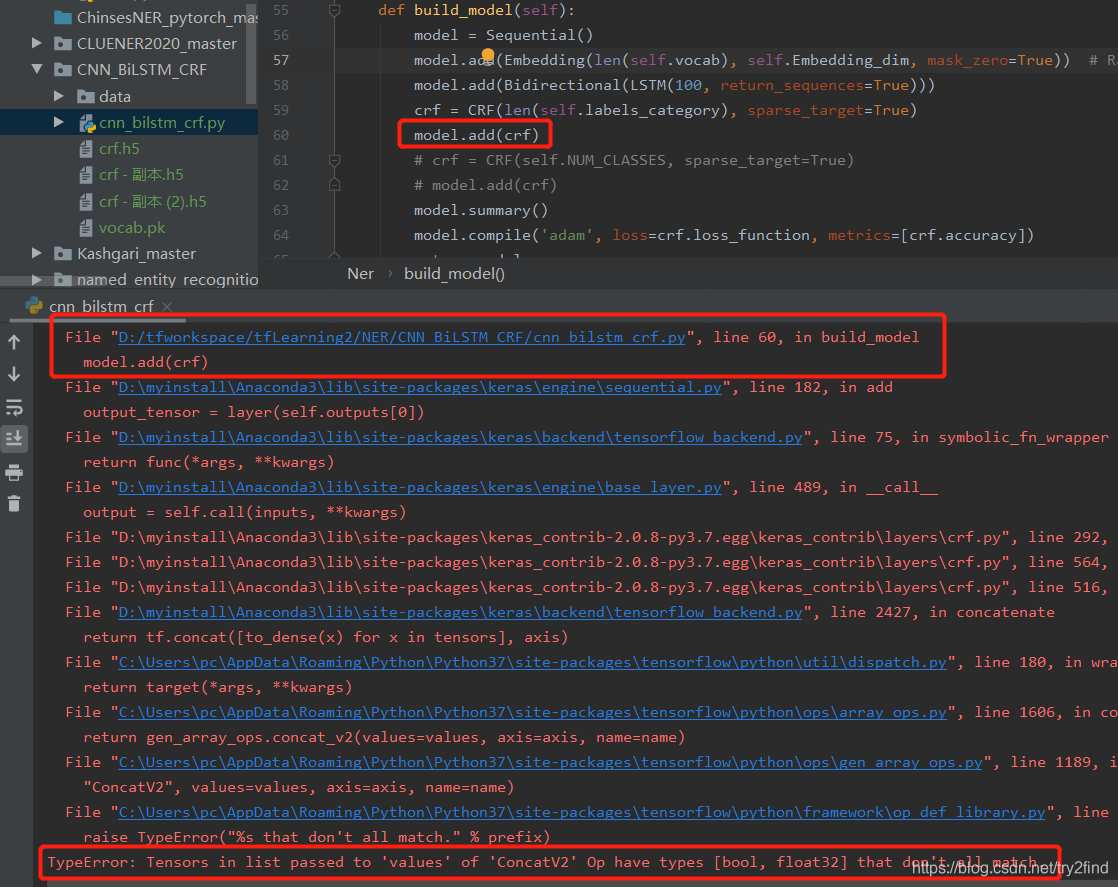
2 分析问题
我们仔细看报错语句,可以看到真正报错的语句为:return tf.concat([to_dense(x) for x in tensors], axis)
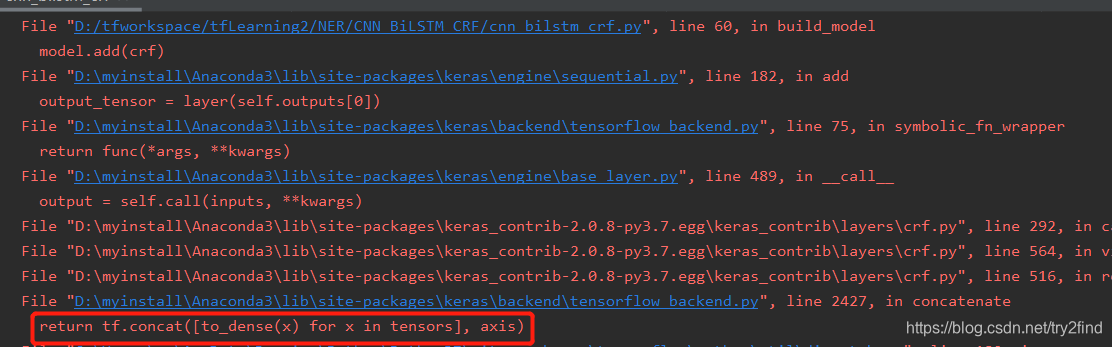
我们找到这行代码:
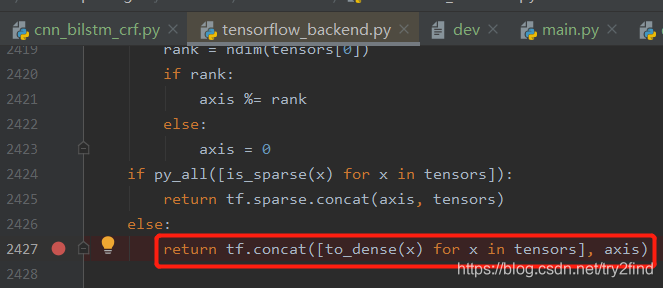
进行断点调试:
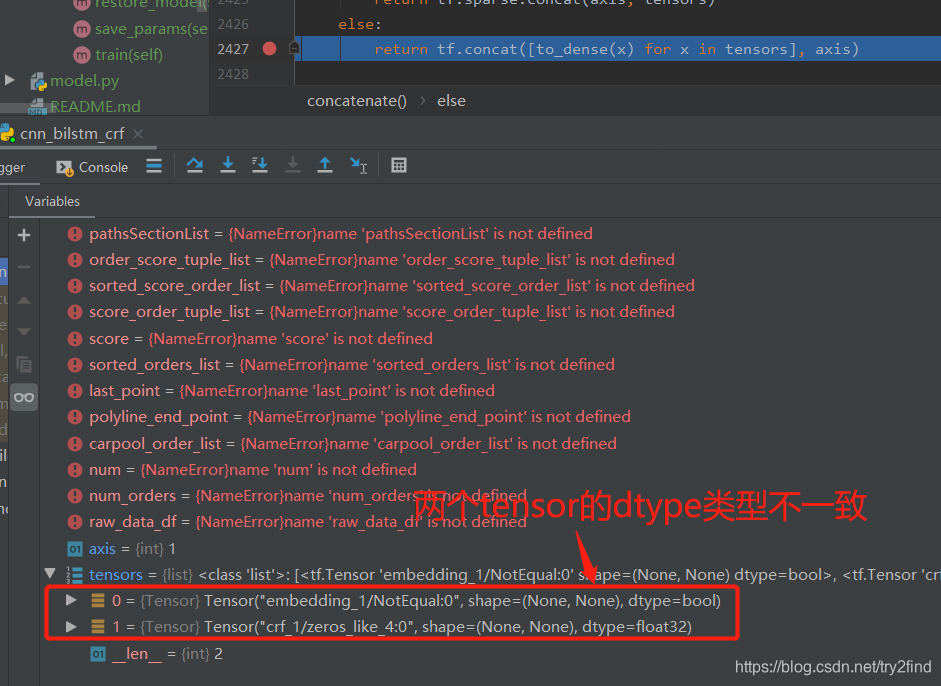
可以看到确实存在两个tensor的值类型不一致。
回过头再来看报错的语句:
TypeError: Tensors in list passed to 'values' of 'ConcatV2' Op have types [bool, float32] that don't all match.
这句话的意思是:传给concatV2操作的values值有两种类型,一直是bool类型,一种是float32类型。
从实际代码来看就是下面这一句:

但是上面两个tensor值是哪里传过来的呢?
经过调试,发现是从mask传过来的值:

bool类型的值是mask,float32类型的值是zeros_like的返回值。
3 解决问题
于是我们将建立模型时的参数:
model.add(Embedding(len(self.vocab), self.Embedding_dim, mask_zero=True))
改为:
model.add(Embedding(len(self.vocab), self.Embedding_dim, mask_zero=False))
于是,代码可以正常运行了:
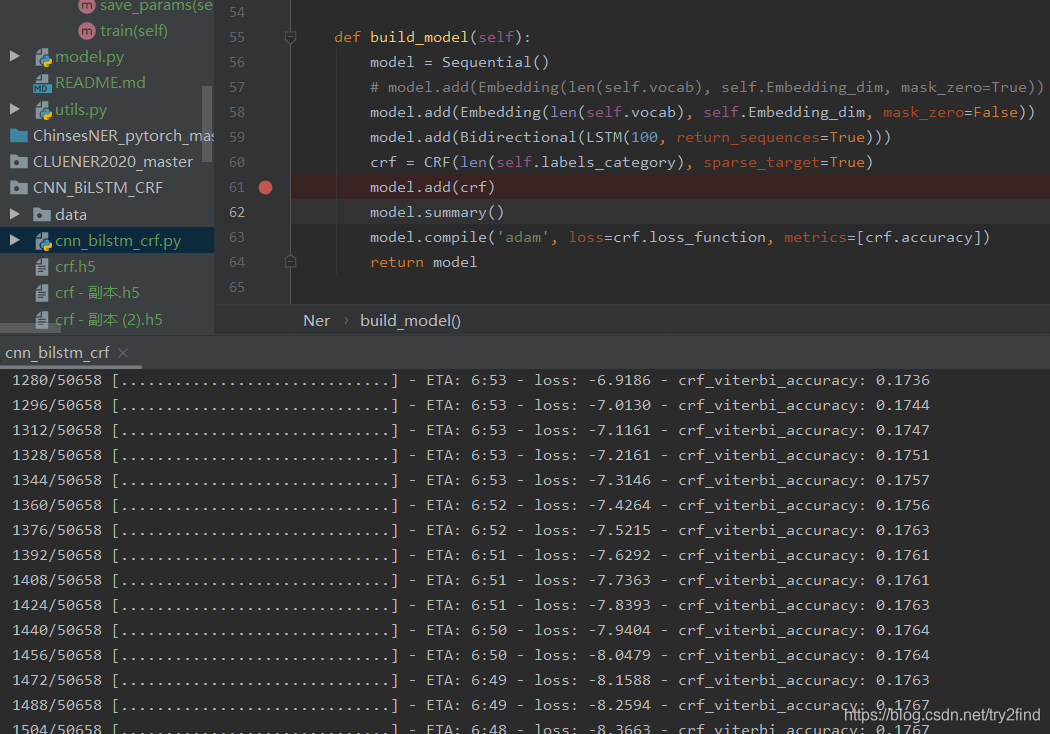
4 问题总结
(1) 需要认真看每一条报错信息对应代码;
(2) 打断点调试到报错的语句,查看相应的数据值;
(3) 怀疑是原始数据的问题导致,mask_zero不能设置为True,有待进一步分析。


















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









