






 本文详细介绍了MySQL的查询和更新流程,从建立连接、查询缓存、SQL解析到存储引擎读写数据,以及InnoDB的更新流程,包括内存数据更新、redo log记录、事务提交等,深入探讨了数据库内部工作机制。
本文详细介绍了MySQL的查询和更新流程,从建立连接、查询缓存、SQL解析到存储引擎读写数据,以及InnoDB的更新流程,包括内存数据更新、redo log记录、事务提交等,深入探讨了数据库内部工作机制。
mysql的查询更新流程
1.mysql基本的架构层次
mysql的架构可以分为三层:连接层、服务层、存储引擎层
- 连接层
- 负责与客户端之间进行连接
- 进行鉴权和权限控制
- 服务层
- 查询缓存的读写
- 对sql进行词法分析、语法分析、预处理
- 对sql进行优化
- 调用存储引擎执行sql
- 存储引擎层
- 存储数据到内存或者磁盘
- 提供读写数据的接口
2.mysql的查询流程
mysql执行一条查询语句,有那么几个步骤:
| 查询步骤 | 对应mysql架构层次 |
|---|---|
| 1. 建立连接 | 连接层 |
| 2. 查询是否有缓存 | 服务层 |
| 3. sql解析 | 服务层 |
| 4. sql预处理 | 服务层 |
| 5. sql优化 | 服务层 |
| 6. 执行引擎处理执行计划 | 服务层 |
| 7. 存储引擎读写数据 | 存储引擎层 |
2.1 步骤一:建立连接
和一个中间件连接,我们会考虑一下几点:
- 连接协议
- 数据的格式
- 连接的最大允许数量
- 如果是长连接,还需要考虑连接超时时间
- 数据包最大允许的容量
2.1.1连接的协议
平常我们说的协议,常见的比如有http、webservice、tcp,mysql的话,包含以下几种协议:
1. TCP/IP协议
这个是最常用的协议,会使用的场景eg:
- 我们用jdbc去连接mysql数据库
- mysql命令通过-h参数指定了目标地址
2. unix socket协议
这个是一种进程间通信的协议,会使用的场景eg:
- 当mysql和客户端在同一台linux服务器上时,用mysql命令连接
3. 其它协议(命名管道、共享内存)
其它的这2种协议,都只跟windows相关,但是生产环境的时候,无论是我们的程序,还是mysql服务端,都很少部署在windows上,所以我也就不去了解了
ps: 可能有人会疑惑,为什么没有socket协议?因为socket其实并不是一个协议,而是一套接口,可以方便我们使用tcp/ip协议
2.1.2数据的格式
数据格式,常见的比如有json、xml
mysql的话,既不是json,也不是xml,而是一个普通的tcp包,大概是这样的一个格式:

2.1.3连接的最大允许数量
2.1.3.1查看当前连接数
-- 查看连接相关的信息
show global status like "Thread%"
-- 结果:
Threads_cached 2
Threads_connected 2
Threads_created 4
Threads_running 1
-
Threads_cached:
缓存中的线程连接数。
eg: navicat刚打开软件,且有1个tab已经打开的时候,如果把那个tab关闭,connected就会-1,cached会+1,如果再打开1个会话,发现cached会-1,connected会+1,created不变 -
Threads_connected:
当前打开着的连接数。
eg: cached的数量不是0的情况下,新打开1个navicat会话,就会增加+1 -
Threads_created :
历史一共创建的线程数 -
Threads_running:
非睡眠状态的连接数,通常指并发连接数。
eg: navicat打开1个会话,然后执行 select sleep(30),发现running的数量就会+1
2.1.3.2修改最大连接数
-- 查看最大连接数:
show variables like "max_connections";
-- 结果:151
mysql默认的最大连接数量是151,如果要修改最大连接数:
法1:执行sql命令修改
-- ps: 这种方式重启后就会失效
set global max_connections = 200
法2:修改配置
mysql的配置文件中,追加一行配置max_connections=300,这种方式可以永久修改。windows环境,对应my.ini文件,然后重启mysql服务即可生效;linux中的docker环境,对应 /etc/mysql/mysql.conf.d/mysqld.cnf 文件,修改好了重启docker容器
2.1.4连接超时时间
查看当前连接的保持时间:
show processlist;
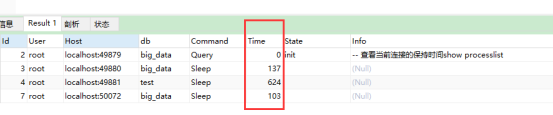
定位当前慢查询的sql语句:
-- 这里有个t_user表,有240w数据,交叉连接查询,就可以测试慢查询
select * from(
SELECT * FROM t_user
where age > 2
)t1, t_user t2
where t1.age = t2.age
-- 通过Info字段,就能知道,Time很长的那个连接,当前在执行的sql是啥
show processlist;

查看超时时间参数
超时时间有2种:
- 交互式连接,eg: 使用jdbc去连接
- 非交互式连接,eg: 使用navicat这样的数据库工具去连接
交互式连接,和非交互式连接的区别,在于不同的客户端,连接mysql时,调用mysql_real_connect()函数时怎样的一个传参方式
-- 查看交互式连接的超时时间
show global variables like "interactive_timeout";
-- 结果:28800,单位是秒,默认8小时
-- 查看非交互式连接的超时时间
show global variables like "wait_timeout";
-- 结果:28800
2.1.5数据包最大允许的容量
show variables like "max_allowed_packet";
-- 结果:4194304,单位是字节,默认4M
因为这个数据包的容量,有大小限制,所以,我们平时利用mybatis去动态拼接sql的时候,就要留意了,如果说sql的大小,超过了这个大小,就会报错的
解决办法有2种:
- 方法一:批量插入,或者批量更新的的时候,分批处理
- 方法二:把 max_allowed_packet 调大
-- 临时设置,如果想要永久设置还是要修改mysql的配置文件 set global max_allowed_packet = 5 * 1024 * 1024
2.2步骤二:查询缓存
-- 查询缓存类别
-- OFF关闭
-- ON开启
-- DEMAND按需缓存:缓存带有sql_cache关键字的查询结果
show variables like "query_cache_type";
-- 结果:OFF,因为mysql的缓存,默认是关闭的
为什么mysql默认关闭了缓存呢?甚至mysql8.0中都已经没有缓存模块了,因为mysql自带的缓存不是很好用,比如:
(1)只要表里面多1条记录就会失效
(2)sql必须一模一样才能查到,如果修改过参数,或者多1个空格,都不会命中缓存
ps: 现在基本都用mybatis或者redis这些手段来做缓存了
2.3步骤三:sql解析
sql的解析分两大类:
- 词法解析:把sql拆分成一个个的单词
- 语法解析:看sql有没有语法错误,然后通过sql拆分开的各个单词生成解析树,解析树示例如下
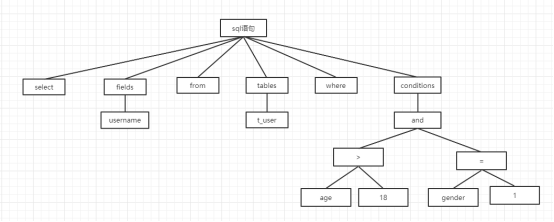
2.4步骤四:sql预处理
sql的预处理,是由预处理器对sql生成的解析树,做进行进一步的检查,判断sql语句中用到的表、字段名是否都存在
2.5步骤五:sql优化
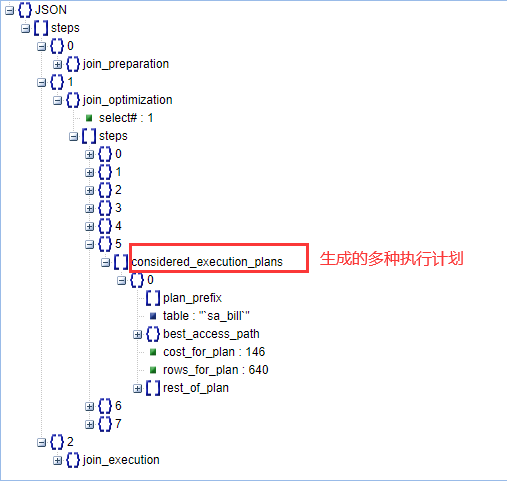
sql优化时,会做的事情:
- 分析sql,列举各种执行计划
- 确定最优的执行计划
查看生成了几种执行计划,和优化过程中的一些信息:
-- 当前会话开启分析结果入库
show variables like "optimizer_trace%";
set optimizer_trace="enabled=on";
-- 执行要分析的sql
select sa_bill.bill_code, sa_back_factory.executor from sa_bill
left join sa_back_factory
on sa_bill.bill_code = sa_back_factory.bill_code
where state = 3;
-- 查看分析结果
select * from information_schema.optimizer_trace;
分析结果的内容格式:
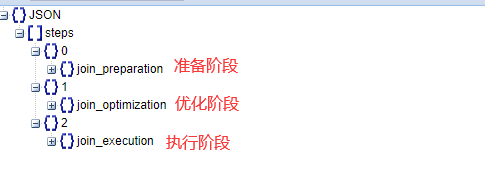
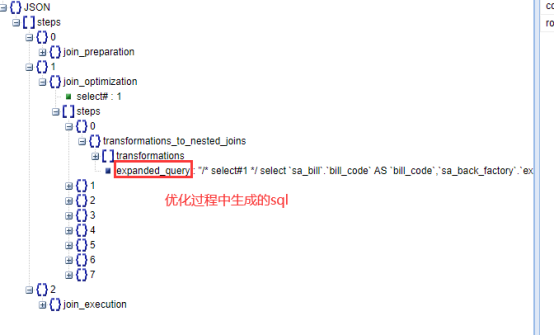
优化过程中生成的sql示例
SELECT
`sa_bill`.`bill_code` AS `bill_code`,
`sa_back_factory`.`executor` AS `executor`
FROM
`sa_bill`
LEFT JOIN `sa_back_factory` ON ( ( CONVERT ( `sa_bill`.`bill_code`
USING utf8mb4 ) = `sa_back_factory`.`bill_code` ) )
WHERE
( `sa_bill`.`state` = 3 )
-- 这条sql,就可以告诉我们,sa_back_factory表,和sa_bill表,关联的字段,字符串编码不一致,降低了关联的效率
2.6步骤六:执行引擎处理执行计划
执行引擎会做的事情包括:
- 验证某条sql,是否拥有某个表的权限
- 把sql解析成更加颗粒度更加小的操作,调用存储引擎去处理数据
示例:select * from t_user where age=10;
- 执行引擎会先去看,用户是否拥有t_user 的权限,没有的话就报错;
- 调用存储引擎查询第1条的数据,age如果不是10,就再调用存储引擎遍历下一条数据。在这个遍历的过程中,还会累加计算扫描的行数
2.7步骤七:存储引擎读写数据
我们知道,存储引擎有很多种,但他们其实都有一套统一的接口,执行引擎只需要调用通用的接口,就可以操作数据
3.mysql中innoDb的更新流程
mysql的内存和磁盘结构
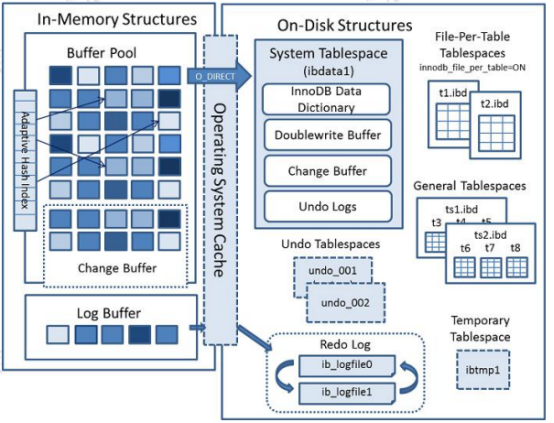
更新流程分为这几个步骤:
- 更新内存中的数据
- 记录redolog
- 提交事务
- 记录binlog
- 更新redolog
- 后台线程刷盘
3.1步骤一:更新内存中的数据
这个步骤,只更新值到内存
3.1.1 bufferPool介绍
查询时的作用:
虽然innodb存储引擎底层数据是存储在idb文件中,但并不会在每次查询的时候,都去访问磁盘中innodb的页,因为那样效率很低,而是会把页的数据放到一块叫bufferPool的内存中中,这样下次再查询就减少了一次文件的io
ps: 如果bufferPool满了,就按照LRU算法,清理数据
更新时的作用:
如果bufferPool中无对应的页,就先把页加载到bufferPool中,然后再执行更新操作,最后通过后台线程,进行刷脏操作,把数据的修改应用到磁盘
-- 查看bufferPool的大小
show variables like "innodb_buffer_pool_size";
-- 结果:innodb_buffer_pool_size 134217728
-- 默认134217728/1024/1024 = 128M
3.1.2 changeBuffer
5.1.2.1面临的问题:
当更新的页,有唯一索引时,是需要把磁盘中的数据加载到bufferPool的,以便进行唯一性检查,既然查询时可以优化成不每次都读取磁盘,那更新的时候,也应该可以优化,我们可以利用bufferPool中一块叫做changeBuffer的区域来优化
3.1.2.2作用:
当更新的页,没有唯一索引时,更新数据,就不再从磁盘加载数据进行唯一性检查,changeBuffer中的数据更新完后,达到特定的时机时,就执行merge操作,把数据记录到磁盘的页
3.1.2.3 merge的时机:
- 此页的数据再次被访问
- 后台线程执行刷脏的定时任务
- 数据库正常关闭
- redolog被写满
3.1.2.4 changeBuffer的大小:
show variables like "innodb_change_buffer_max_size"
-- 结果:innodb_change_buffer_max_size 25
-- 25表示,占25%的buffePool的大小
当我们的表,大部分都是非唯一索引,而且更新后不会立即读取时,建议把这个值调大
3.2步骤二:记录redolog
这个步骤,会记录redolog,状态标记为 prepare
3.2.1rodolog介绍
面临问题
如果刷脏进行到一半,数据库重启或者宕机,就会导致写操作不完整,可能破坏数据文件
作用
- 写之前记录redolog日志,下次重启就就先用日志文件恢复我们的数据,用这种方式来实现crash safe 崩溃安全
- 刷盘是随机IO,记录了redolog,我们就不用那么频繁的刷盘了,可以减少随机IO的次数
rodolog的大小
mysql默认在变量datadir对应目录下,有2个日志文件:ib_logfile0、ib_logfile1,都是48M
顺序IO
写redolog用的是顺序IO,因为它比普通的IO效率更高,磁盘的最小访问单位是block(块),在找数据块的过程中,磁臂、磁头,需要不停的做旋转、移动之类的工作
- 普通的IO写数据:
找到第一个块,写完后,继续找下一个块的位置,然后再写,因为块可能分布在不同的页中、不同的扇区中,所以多次找块的时间可能很长 - 顺序IO读写数据:
找到对应的页->扇区->块,读写完后,就用下一个块继续写,这样的话,多次找块的时间就很短
3.2.2 logBuffer
3.2.2.1面临问题
redolog的作用之一,是减少刷盘随机IO的次数,其实数据写入redolog也是一次IO,有没有什么办法能够减少写入redolog的IO次数呢?答案是有的,内存中有一块叫做logBuffer的区域,可以解决这个问题
3.2.2.1作用
暂存要写入redolog日志文件的数据,当满足我们写入时机时,里面的数据才被写入redolog文件,这样就可以减少redolog的IO次数
3.2.2.3特点
- 此日志是物理日志,记录的是这个数据页做了什么修改。不像binlog一样,binlog是逻辑日志,记录的是语句的原始逻辑
- 循环写入,文件内容会被不停的覆盖。每次写满了,就会把数据刷到磁盘中去
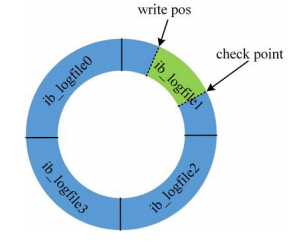
如下图,当write_pos写的位置,和check_point重叠了,就说明必须要刷数据到文件中了
3.2.2.4大小
show variables like "innodb_log_buffer_size"
-- 结果:innodb_log_buffer_size 8388608
-- ps:经过个人的测试,mysql5.6是8M,mysql5.7是16M
3.2.2.5写入时机
ps: 在了解写入时机之前,有个需要知道的是,做磁盘IO操作时,会存在1个操作系统的缓存问题,我们平常写程序,写入完文件之后,会执行flush操作,但redolog的flush,是可配置的
--查看写入时机:`
show variables like "innodb_flush_log_at_trx_commit"
-- 结果:1
变量值的规则如下:
| 值 | 策略 | 详细描述 |
|---|---|---|
| 0 | 延时写,延时刷 | 每秒执行,写入redolog文件+ flush |
| 1(默认) | 实时写,实时刷 | 每次提交事务执行,写入rodolog文件+ flush |
| 2 | 实时写,延时刷 | 每次提交事务写入redolog文件,每秒执行1次flush |
3.3步骤三:提交事务
这个步骤,会执行commit操作
3.4步骤四:记录binlog
作用
- 主从复制:从服务器拿到主服务器的binlog,执行一遍相同的操作,就能同步数据
- 数据恢复:可以把binlog转成sql语句,通过把历史操作执行一遍,来达到数据恢复的目的
特点
- 逻辑日志,会记录DDL、DML语句
- 内容是以追加的方式写入,大小不断增大
3.4步骤五:更新redolog
这个步骤,会把最开始记录的redolog,状态从 prepare,更新成commit状态
3.5步骤六:后台线程刷盘
这个步骤,执行的时机不一定,会把内存中的数据,真正刷到磁盘中去
3.5.1磁盘结构
磁盘结构,包含5个表空间和redolog的内容
3.5.1.1系统表空间
系统表空间是mysql自带的1个共享表空间,包含 undolog、changeBuffer写缓冲、doubleWriteBuffer双写缓冲、数据字典
存储路径:
datadir属性对应路径下的ibdata1文件
大小:
会不断增加,不是固定的
3.5.1.1.1 undolog
这是undolog 表空间的信息,默认存储在系统表空间的文件中
3.5.1.1.2 changeBuffer
写缓冲的信息
3.5.1.1.3双写缓冲
面临问题:
innoDb的页,是16K,操作系统的页是4K,所以说,每次写入磁盘的时候,需要写4次,在这个过程中如果中断了,就可能导致这个页坏掉,无法再进行IO操作,数据库重启后,即使想用redolog恢复数据,也写不进去,从而造成数据的丢失(这种情况叫"写失效")
作用:
写的时候生成页副本,在使用redolog恢复数据时,在页副本上写redolog的内容,然后用这个页的副本来恢复数据,这样就能防止"写失效"
特点:
也是顺序IO
3.5.1.1.4数据字典
存储表和索引的元数据(元数据就是定义信息)
3.5.1.2独占表空间
-- 查看是否开启
show variables like "innodb_file_per_table%";
-- 结果:ON(默认就是打开的)
作用:
开启之后,每张表都会独占1个表空间,这样的话,每新建1张表,就会生成新的ibd文件
-- 测试一下关闭这个属性的情况:
set global innodb_file_per_table = "OFF";
CREATE TABLE `t_close_file_per_table` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
)
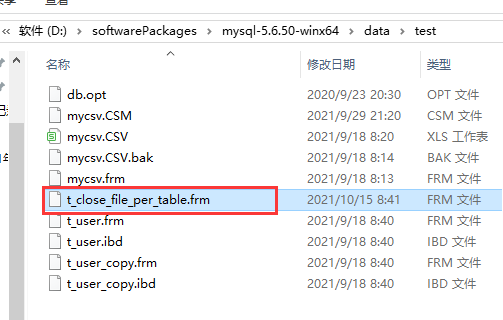
可以发现,关闭了这个属性后,新建的表,就只有1个frm文件了
3.5.1.3通用表空间
作用:
可以让特定的一些表,共享1个ibd文件
-- 创建表空间
-- tip: 测试成功的环境,mysql5.7
create tablespace test_table_space_01 add datafile
"/var/lib/mysql/test_table_space_01.ibd" file_block_size=16K engine=innodb;
-- 创建表,制定命名空间。
create table test_table_space(id int, cname varchar(20)) tablespace
test_table_space_01;
-- 效果:生成了 test_table_space.frm,但是没有新生成ibd文件
3.5.1.4临时表空间
作用:存储临时表的数据
3.5.1.5 undolog 表空间
作用:
记录事务执行之前的数据状态
特点:
undolog是逻辑日志,eg 1条数据name是zhangsan,需要执行update t_user set name = “aaaa” where id = 1 ,name,undolog就会记录 name=zhangsan
存储位置:
默认存储在datadir属性对应路径下的ibdata1文件
3.5.1.6 redo log
redolog写满了,或者满足redolog的写入时机时,会保存在磁盘中的该区域
3.5.2后台线程介绍
- master线程:负责协调各个线程
- page cleaner 线程:负责刷脏
- purge 线程:负责回收undolog的空间
- io 线程:负责读写请求的io回调操作


















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









