






 本文介绍了在字符串匹配问题中,暴力匹配法和KMP算法的应用。暴力匹配法通过两个指针比较字符串,遇到不匹配时回溯。KMP算法通过部分匹配值表避免无效比较,提高效率。文章提供了部分匹配表的生成方法,并详细解释了KMP算法的查找过程。
本文介绍了在字符串匹配问题中,暴力匹配法和KMP算法的应用。暴力匹配法通过两个指针比较字符串,遇到不匹配时回溯。KMP算法通过部分匹配值表避免无效比较,提高效率。文章提供了部分匹配表的生成方法,并详细解释了KMP算法的查找过程。
有两个字符串,原字符串和子字符串,在原字符串里寻找子字符串出现的位置,如果有,返回对应下标,如果没有,返回-1。解决这个问题可以用到两个方法,暴力匹配和KMP算法。
这个视频更好懂一点–>link
暴力匹配法
思路是:用两个下标,i指向原字符串,j指向子字符串。比较str1[i]和str2[j]相不相等,如果相等,就进入比较状态,比较后续的字符相不相等,把两个下标后移一位,比较两字符串的下一个字符相不相等,如果一直相等,当j移动到尾时,说明整个字符串都相等,这时就可以退出,输出位置。如果遇到了str1[i]和str2[j]不相等的情况,应该回退到进入比较状态之前,把i移动到最开始字符相等的下一位 i=i-j+1,j重新置为0,重复以上过程。如果直到i指向原字符串末尾也没有输出,那就代表没找到子串,返回-1。
//暴力匹配法
public static int violenceMatch(String s1,String s2){
char[] str1=s1.toCharArray();
char[] str2=s2.toCharArray();
int i=0;
int j=0;
while (i<str1.length && j<str2.length){
if(str1[i]==str2[j]){
i++;
j++;
}else {
//没匹配到就把i移动到刚开始和j匹配的后一位
i = i - j + 1;
j = 0;
}
}
if(j==str2.length){
return i-j;
}
return -1;
}
KMP算法

在进行暴力匹配法时,每次遇到不匹配的情况,就会回溯到开始比对相不相等的下一位,也就是i每次只前进1位,按照上图,从a->a开始比较,abcdab都是匹配的,d不匹配,这时就回到a后一位也就是b,比较b->a。但是在比较d的那次,我已经知道前面的顺序是abcd。。。,也就是a后面跟得是bcd,再用子字符串的a去对应b肯定是不可能比配的,我应该把子字符串的去跟原字符串的bcd后的那个a比较才有可能找到相同,因为我在上一次的比较中已经知道原字符串a后的是bcd,而子串也是abcd,这时候去比较b->a是没有意义的。
为了减少这种无意义的比较,发明了kmp算法。kmp算法的目的就是在比较时让下标i跳过这些无意义的比较,从而提高效率。
kmp算法
首先获得子串的部分匹配值表
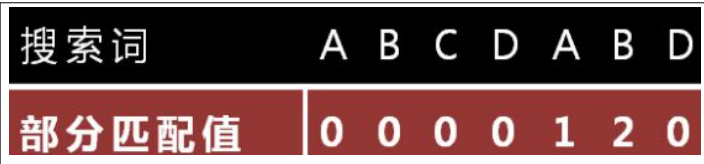
部分匹配值表示对应子串的最大公共前后缀长度,比如a->0,就表示a这个串没有相等的前后缀,因为a只有一个字符,它没有前后缀,b->0,就表示ab这个串没有相等的前后缀,因为ab的前缀是a后缀是b,不相等,就是0,b->2,就表示abcdab这个串,最大的相等前后缀长度为2,因为它的前缀是a|ab|abc|abcd|abcda,后缀是bcdab|cdab|dab|ab|b,ab是相等且最长的,长度为2,所以就是2
注意这里的值是前缀与后缀相等中最长的那个缀的长度,而不是这个串的回文长度,这两个是不一样的
如何求的部分匹配表(说实话,不太懂,可以看b站视频KMP讲解)
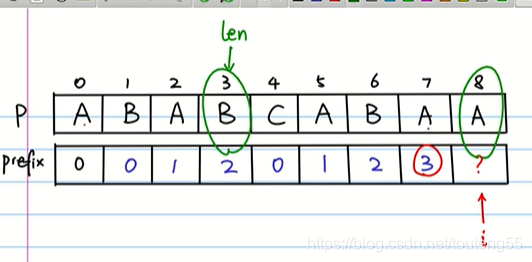
prefix为部分匹配表
首先,因为子串的第一个字符没有前后缀,所以prefix第一位肯定为0。有一个规律,当我们填8这一位的prefix值时,7的prefix是3,也就是说子串前三个肯定是相等的,那么如果8的prefix要为4,p[8]只要等于子串的第四个字符就好,也就是prefix[7]作为下标的p里的值,就是p[8]是否等于p[len],len既是p的下标也是最长的公共前后缀匹配值,如果相等,len就加一,然后把len存进匹配表。假如不相等,不用从头比较(这样就跟暴力算法一样了),因为在之前的比较中已经获得了信息,跟动态规划有点像,这个结果的获得跟之前的结果有联系,而不是独立的。这时让len=prefix[len-1](为啥要这样我也没懂,但这是算法的核心),直到len<0或者相等。假如len=0了,还是不相等,就说明找不到一样的前后缀了,之间把len存进prefix,假如len=0并相等了,就进入之前的情况,len+1并存入prefix。
//求prefix数组
public static int[] getNext(String str){
char[] arr=str.toCharArray();
int[] prefix=new int[arr.length];
int len=0;
prefix[0]=0;
for (int i = 1; i <arr.length ; i++) {
while (len>0&& arr[i]!=arr[len]){
len=prefix[len-1];
}
if(arr[i]==arr[len]){
len++;
prefix[i]=len;
}
}
return prefix;
}
之后,正式进行子串的查找
遍历原字符串,i指向原串,最好用for循环,while循环会麻烦一点。j指向子串,如果str1.charAt(i) == str2.charAt(j),说明匹配到了,j++继续看下一个匹不匹配(不用i++是因为是for循环,i每次自动++了,只++j就好),如果一直匹配,当j=子串的长的时候(为什么不是等于length-1是因为匹配到的时候已经把j++了让j指向下一位了)就说明全部匹配,就说明找到了,直接返回下标i-j+1(因为此时i还没有++,而j已经++,i就比j小一,就要加回来),当不匹配时,j = next[j-1],直到j<=0或相等,逻辑其实和上面求匹配表时一样,原理我也不是很懂,可以看kmp解释。这部分涉及到算法设计的数学原理,不是很好理解
如果最终也没有输出,说明没找到,返回-1
//写出我们的 kmp 搜索算法
/**
*
* @param str1 源字符串
* @param str2 子串
* @param next 部分匹配表, 是子串对应的部分匹配表
* @return 如果是-1 就是没有匹配到,否则返回第一个匹配的位置
*/
public static int kmpSearch(String str1, String str2, int[] next) {
//遍历
for(int i = 0, j = 0; i < str1.length(); i++) {
//需要处理 str1.charAt(i) != str2.charAt(j), 去调整 j 的大小
//KMP 算法核心点, 可以验证...
while( j > 0 && str1.charAt(i) !=str2.charAt(j)) {
j = next[j-1];
}
if(str1.charAt(i) == str2.charAt(j)) {
j++;
}
if(j == str2.length()) {//找到了 // j = 3 i
return i - j + 1;
}
}
return -1
总之,不匹配时,j = next[j-1];就完事
更详细的可以看link


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









