







1. 正则表达式的概念
正则表达式是用于描述一组字符串特征的模式,用来匹配特定的字符串。通过字符串来进行模式描述,从而达到文本匹配目的。
2. 正则表达式的应用场景
(1)验证:表单提交时,进行用户名密码的验证等
(2)查找:从大量信息中快速提取指定内容。如在一批URL中查找指定的URL等
(3)替换:将指定格式的文本,进行正则表达式匹配查找后进行特定的替换。如vim文本替换等
3. 正则表达式的基本要素
(1)字符类
(2)数量限定符
(3)位置限定符
(4)特殊字符
4. 举例说明
如要在指定文件中进行按行查找,找到指定行是有效的手机号码的行。
首先对手机号码进行描述:
(1)手机号码中只包含数字不包含字母以及其他字符
(2)手机号码是由11位数字组成
(3)在当前行中只有手机号码,即行首是手机号码的特征,行尾也是手机号码的特征
将以上三个关于手机号码的特征用正则表达式的要素进行描述如下:
(1)手机号码的符号组成--------数字--------字符类
(2)手机号码的符号个数--------11--------数量限定符
(3)当前行只有手机号码,即以手机号码开头并以手机号码结尾的行--------位置限定符
注:以下关于正则表达式的匹配测试,所用工具为grep
grep工具的--color选项作用为将匹配的内容进行语法高亮
grep工具的-E选项作用为使用扩展正则匹配,若grep不加-E选项表示是基准正则匹配
grep工具是以贪心匹配的模式进行正则匹配的
5. 字符类
(1) . -----> 匹配任意一个字符
如:正则表达式 ‘abc.’ 匹配字符串“abcd”、“abc1”,但不匹配字符串“abcde”

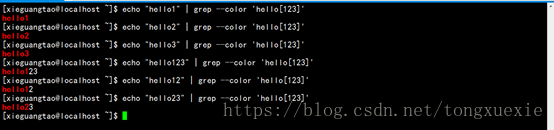
(2)[ 字符] -------> 匹配[]括号内的任意一个字符
如:正则表达式‘hello[123]’匹配字符串“hello1”、“hello2”、“hello3”,但不匹配字符串“hello12”
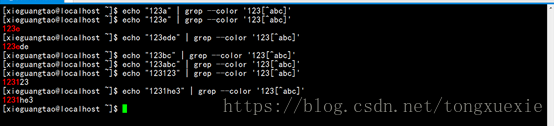
(3)- ---------> -位于[]括号内,表示字符范围
如:‘[0-9]’表示的字符范围是从0到9这10个数字
‘[a-z]’表示的字符范围是从小写字母a到小写字母z这26个小写字母
‘[A-Z]’表示的字符范围是从大写字母A到大写字母Z这26个大写字母
关于-和[]的组合的正则表达式的匹配举例如下所示:

(4)^ --------> ^位于[]括号开头,表示匹配除[]内的字符以外的任意一个字符
如:正则表达式‘[^abc]’匹配除了abc这三个字符以外的任意一个字符,不匹配“a”“ba”“cba”等
(5)[[:xxx:]] -------> grep工具预定义的一些命名字符类
[[:alpha:]] ----> 匹配一个字母,等价于[a-zA-Z]
[[:digit:]] ----> 匹配一个数字,等价于[0-9]

6. 数量限定符
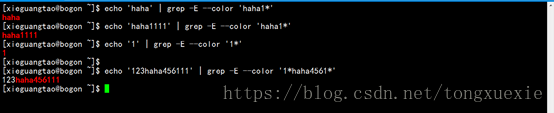
(1)? -------> 它前一单元应匹配0次或1次

(2)+ -------> 它前一单元应匹配1次或多次

(3)* -------> 它前一单元应匹配0次或多次
(4){N} ------> 它前一单元只匹配N次

这里需要注意的是,虽然{N}表示只匹配N次,但由于grep工具是贪心匹配模式,故它将所有符合N次的字符均匹配到,在之后的操作中也要留心操作后的结果出现的某些情况是不是由于grep工具的贪心匹配模式导致。
(5){N,} ------> 它前一单元至少匹配N次

(6){,M} ------> 它前一单元至多匹配M次

通过测试代码发现,无论怎样操作{,M}数量限定符都匹配不到任何结果。
造成这样的原因可能是grep工具不支持或此数量限定符被废弃等
(7){N,M} -----> 它前一单元至少匹配N次,至多匹配M次

7. 位置限定符
(1)^ ------> 匹配行首的位置
如:正则表达式‘^hello’匹配位于一行开头的“hello”

(2)$ -------> 匹配行末的位置
如:正则表达式‘world$’匹配位于一行末尾的“world”

(3)\< -------> 匹配单词开头的位置
如:正则表达式‘\<he’匹配单词开头的位置的“he”

(4)\> -------> 匹配单词结尾的位置
如:正则表达式‘me\>’匹配单词结尾的位置的“me”

(5)\b ------> 匹配单词开头或结尾的位置
如:正则表达式‘\bhe’匹配单词开头的位置的“he”
正则表达式‘he\b’匹配单词结尾的位置的“he”
正则表达式‘\bhe\b’匹配单词开头且结尾的位置的“he”

(6)\B -------> 匹配非单词开头和结尾的位置
如:正则表达式‘\Bhe’匹配非单词开头的位置的“he”
正则表达式‘he\B’匹配非单词结尾的位置的“he”
正则表达式‘\Bhe\B’匹配非单词开头和结尾的位置的“he”

这里需要额外讲的一点是:^$匹配空行
8. 特殊字符
(1)\ ------> 转义字符
将普通字符转义为特殊字符,如:<加\后的字符\<表示匹配单词开头的位置

将特殊字符转义为普通字符,如:特殊字符.加\后\.表示普通的字符.不再是特殊字符.

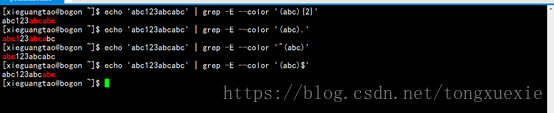
(2)() ------> 一个单元
将正则表达式的一部分用()括起来表示()内为一个单元,可以对这整个单元使用数量限定符
(3)| -------> 或关系
|连接两个正则表达式,表示或的关系

9. 正则表达式的练习
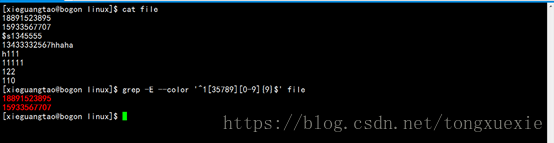
1.匹配文件一行中只有手机号码的行
分析如下:
手机号码是纯数字的组合,故字符类为[0-9]
手机号码是由11位数字组成,故数量限定为11
手机号码是以1开头的
手机号码的第二位数字一般为3、5、7、8、9
手机号码既是以数字开头也是以数字结尾的,用到位置限定符^和$
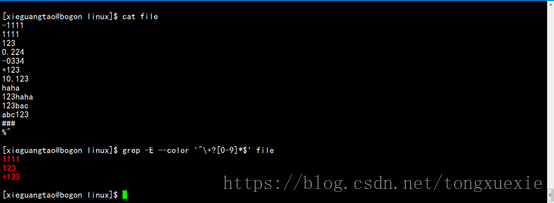
2. 匹配文件中一行只有非零的正整数的行
分析如下:
对于类似“+123”的字符串也视为非零的正整数,故需要利用位置限定符^和数量限定符?从而限定+只能出现在行首并且出现0次或者1次
对于非零的正整数中,除了+字符外,其他均为数字字符,即[0-9]的字符
关于数量限定符,由于只要求为非零正整数,故字符的数量不限定,使用数量限定符*
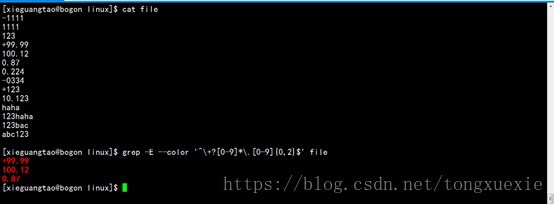
3.匹配文件一行中非零开头的最多带两位小数的数字的行
分析如下:
处理带有+号的非零数,可以匹配行首有字符+的数字,利用数量限定符?以及位置限定符^
处理小数的问题,先将特殊字符.通过转义字符转为普通字符.,再利用数量限定符从而限定普通字符.出现0次或1次
对于每一行的数字,需要限定行中均为数字,故行首和行尾均是数字,用到位置限定符^和$
对于最多带两位小数的数字,需要在表示小数点后面的正则表达式的数字最多含有2个字符,利用数量限定符{,M}
4.匹配文件每行中符合日期格式(2018-7-6)的
分析如下:
日期格式中均为数字字符和字符-
关于年,共由4个数字字符组成
关于月,共由2个数字字符组成
关于日,共由2个数字字符组成
年月日之间用字符-隔开
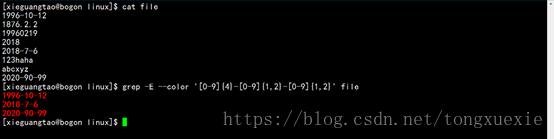
通过结果可以发现2020-90-99这样的日期格式也被过滤出来,但这是在现实生活中不会出现的日期格式,这是因为所写的正则表达式并没有更加精确地限定日期格式。想要说明的是,正则表达式只是快速过滤想要的信息,如果想要将信息过滤地更加详细,可以通过正则表达式粗略限定后,再利用其它方式进行详细地筛选。
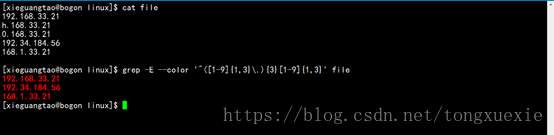
5. IP地址的粗略过滤
由于IP地址的格式为:192.168.33.108
IP地址中均有数字字符和普通字符.组成
在IP地址格式中用到了普通字符.,故需要利用转义字符将特殊字符.转为普通字符.
在被普通字符.分隔开的区间里,由至少1位数字字符至多3位数字字符组成

















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









