






mysql 数据质量检测 sql 代码集合
文提供了一系列用于 MySQL 数据库质量检测的 SQL 查询语句,
主要包括:
数据字典生成 - 全面展示数据库表结构信息,包括表基本信息、字段属性、索引、外键等,并统计每张表的字段数量
综合质量报告 - 统计表备注缺失、字段备注缺失以及备注完整表的情况
表备注检查 - 专门查找缺少表备注的表,并显示相关表信息
字段备注统计 - 分析每张表中缺少字段备注的情况,计算缺失比例
这些 SQL 语句可以帮助 DBA 和开发人员快速评估数据库元数据质量,特别适用于需要进行数据治理或文档整理的场景。所有查询均基于 INFORMATION_SCHEMA 系统视图实现,可针对特定数据库执行质量评估。
文章目录
1.数据字典生成SQL
SELECT
c.TABLE_SCHEMA AS 数据库名称,
c.TABLE_NAME AS 表名,
t.TABLE_COMMENT AS 表注释,
t.ENGINE AS 表引擎,
DATE_FORMAT(t.CREATE_TIME, '%Y-%m-%d %H:%i:%s') AS 表创建时间,
DATE_FORMAT(t.UPDATE_TIME, '%Y-%m-%d %H:%i:%s') AS 表修改时间,
c.ORDINAL_POSITION AS 字段序号,
c.COLUMN_NAME AS 列名,
c.COLUMN_TYPE AS 数据类型,
c.DATA_TYPE AS 字段类型,
c.CHARACTER_MAXIMUM_LENGTH AS 长度,
c.IS_NULLABLE AS 是否为空,
c.COLUMN_DEFAULT AS 默认值,
c.COLUMN_COMMENT AS 备注,
CASE
WHEN c.COLUMN_KEY = 'PRI' THEN '主键'
WHEN c.COLUMN_KEY = 'UNI' THEN '唯一索引'
WHEN c.COLUMN_KEY = 'MUL' THEN '普通索引'
ELSE '无'
END AS 索引类型,
IFNULL(idx.索引信息, '无') AS 索引名称,
IF(c.EXTRA LIKE '%auto_increment%', '是', '否') AS 是否自增,
fk.REFERENCED_TABLE_NAME AS 外键关联表,
fk.REFERENCED_COLUMN_NAME AS 外键关联字段,
-- 使用窗口函数统计每张表的字段数量
COUNT(*) OVER (PARTITION BY c.TABLE_NAME) AS 该表字段总数
FROM
INFORMATION_SCHEMA.COLUMNS c
INNER JOIN
INFORMATION_SCHEMA.TABLES t
ON c.TABLE_SCHEMA = t.TABLE_SCHEMA
AND c.TABLE_NAME = t.TABLE_NAME
LEFT JOIN (
-- 预聚合索引信息
SELECT
TABLE_SCHEMA,
TABLE_NAME,
COLUMN_NAME,
GROUP_CONCAT(
DISTINCT CONCAT(
INDEX_NAME,
'(',
IF(NON_UNIQUE = 0, '唯一', '普通'),
',位置:', SEQ_IN_INDEX,
')'
)
ORDER BY INDEX_NAME, SEQ_IN_INDEX
SEPARATOR ' | '
) AS 索引信息
FROM
INFORMATION_SCHEMA.STATISTICS
WHERE
TABLE_SCHEMA = '你的数据库名称'
GROUP BY
TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME
) idx ON c.TABLE_SCHEMA = idx.TABLE_SCHEMA
AND c.TABLE_NAME = idx.TABLE_NAME
AND c.COLUMN_NAME = idx.COLUMN_NAME
LEFT JOIN (
-- 预聚合外键信息(避免重复)
SELECT DISTINCT
CONSTRAINT_SCHEMA,
TABLE_NAME,
COLUMN_NAME,
REFERENCED_TABLE_NAME,
REFERENCED_COLUMN_NAME
FROM
INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE
CONSTRAINT_SCHEMA = '你的数据库名称'
AND REFERENCED_TABLE_NAME IS NOT NULL
) fk ON c.TABLE_SCHEMA = fk.CONSTRAINT_SCHEMA
AND c.TABLE_NAME = fk.TABLE_NAME
AND c.COLUMN_NAME = fk.COLUMN_NAME
WHERE
c.TABLE_SCHEMA = '你的数据库名称'
ORDER BY
c.TABLE_NAME, c.ORDINAL_POSITION;
2.综合质量报告
SELECT
'表备注缺失' AS 问题类型,
COUNT(DISTINCT TABLE_NAME) AS 问题数量
FROM
INFORMATION_SCHEMA.TABLES
WHERE
TABLE_SCHEMA = '你的数据库名称'
AND TABLE_TYPE = 'BASE TABLE'
AND (TABLE_COMMENT IS NULL OR TABLE_COMMENT = '' OR TABLE_COMMENT = ' ')
UNION ALL
SELECT
'字段备注缺失' AS 问题类型,
COUNT(*) AS 问题数量
FROM
INFORMATION_SCHEMA.COLUMNS
WHERE
TABLE_SCHEMA = '你的数据库名称'
AND (COLUMN_COMMENT IS NULL OR COLUMN_COMMENT = '' OR COLUMN_COMMENT = ' ')
UNION ALL
SELECT
'备注完整的表' AS 问题类型,
COUNT(DISTINCT t.TABLE_NAME) AS 问题数量
FROM
INFORMATION_SCHEMA.TABLES t
WHERE
t.TABLE_SCHEMA = '你的数据库名称'
AND t.TABLE_TYPE = 'BASE TABLE'
AND t.TABLE_COMMENT IS NOT NULL
AND t.TABLE_COMMENT != ''
AND NOT EXISTS (
SELECT 1
FROM INFORMATION_SCHEMA.COLUMNS c
WHERE c.TABLE_SCHEMA = t.TABLE_SCHEMA
AND c.TABLE_NAME = t.TABLE_NAME
AND (c.COLUMN_COMMENT IS NULL OR c.COLUMN_COMMENT = '' OR c.COLUMN_COMMENT = ' ')
);
3.检查缺少表备注的表
SELECT
t.TABLE_SCHEMA AS 数据库名称,
t.TABLE_NAME AS 表名,
t.ENGINE AS 表引擎,
t.TABLE_ROWS AS 表行数,
DATE_FORMAT(t.CREATE_TIME, '%Y-%m-%d %H:%i:%s') AS 表创建时间,
IFNULL(t.TABLE_COMMENT, '【缺失】') AS 表备注状态,
IFNULL(col_count.字段总数, 0) AS 字段总数
FROM
INFORMATION_SCHEMA.TABLES t
LEFT JOIN (
SELECT
TABLE_SCHEMA,
TABLE_NAME,
COUNT(*) AS 字段总数
FROM
INFORMATION_SCHEMA.COLUMNS
WHERE
TABLE_SCHEMA = '你的数据库名称'
GROUP BY
TABLE_SCHEMA,
TABLE_NAME
) AS col_count
ON t.TABLE_SCHEMA = col_count.TABLE_SCHEMA
AND t.TABLE_NAME = col_count.TABLE_NAME
WHERE
t.TABLE_SCHEMA = '你的数据库名称'
AND t.TABLE_TYPE = 'BASE TABLE'
AND (t.TABLE_COMMENT IS NULL OR t.TABLE_COMMENT = '' OR TRIM(t.TABLE_COMMENT) = '')
ORDER BY
t.TABLE_NAME;
4.统计每个表中缺少字段备注的情况 SQL
SELECT
c.TABLE_NAME AS 表名,
t.TABLE_COMMENT AS 表备注,
t.TABLE_ROWS AS 表行数,
ROUND((t.DATA_LENGTH + t.INDEX_LENGTH) / 1024 / 1024, 2) AS 表大小MB,
DATE_FORMAT(t.UPDATE_TIME, '%Y-%m-%d %H:%i:%s') AS 最后数据更新时间,
DATE_FORMAT(t.CREATE_TIME, '%Y-%m-%d %H:%i:%s') AS 表创建时间,
COUNT(*) AS 字段总数,
SUM(CASE
WHEN c.COLUMN_COMMENT IS NULL OR c.COLUMN_COMMENT = '' OR c.COLUMN_COMMENT = ' '
THEN 1
ELSE 0
END) AS 缺少备注字段数,
CONCAT(
ROUND(
SUM(CASE
WHEN c.COLUMN_COMMENT IS NULL OR c.COLUMN_COMMENT = '' OR c.COLUMN_COMMENT = ' '
THEN 1
ELSE 0
END) * 100.0 / COUNT(*),
2
),
'%'
) AS 缺失比例,
-- 额外加上:优先级判断
CASE
WHEN t.TABLE_ROWS > 100000 AND SUM(CASE
WHEN c.COLUMN_COMMENT IS NULL OR c.COLUMN_COMMENT = '' OR c.COLUMN_COMMENT = ' '
THEN 1 ELSE 0 END) > 5
THEN '🔴 高优先级'
WHEN t.TABLE_ROWS > 10000
THEN '🟡 中优先级'
ELSE '🟢 低优先级'
END AS 优先级
FROM
INFORMATION_SCHEMA.COLUMNS c
LEFT JOIN
INFORMATION_SCHEMA.TABLES t
ON c.TABLE_SCHEMA = t.TABLE_SCHEMA
AND c.TABLE_NAME = t.TABLE_NAME
WHERE
c.TABLE_SCHEMA = '你的数据库名称'
GROUP BY
c.TABLE_NAME,
t.TABLE_COMMENT,
t.TABLE_ROWS,
t.DATA_LENGTH,
t.INDEX_LENGTH,
t.UPDATE_TIME,
t.CREATE_TIME
HAVING
缺少备注字段数 > 0
ORDER BY
t.TABLE_ROWS DESC, -- 先按表行数降序(大表优先)
缺少备注字段数 DESC,
c.TABLE_NAME;
5.详细列出所有缺少备注的字段 sql
SELECT
c.TABLE_NAME AS 表名,
IFNULL(t.TABLE_COMMENT, '【表备注缺失】') AS 表备注,
c.ORDINAL_POSITION AS 字段序号,
c.COLUMN_NAME AS 字段名,
c.COLUMN_TYPE AS 数据类型,
c.IS_NULLABLE AS 是否为空,
c.COLUMN_DEFAULT AS 默认值,
CASE
WHEN c.COLUMN_KEY = 'PRI' THEN '主键'
WHEN c.COLUMN_KEY = 'UNI' THEN '唯一索引'
WHEN c.COLUMN_KEY = 'MUL' THEN '普通索引'
ELSE ''
END AS 键类型,
'【待补充】' AS 备注状态
FROM
INFORMATION_SCHEMA.COLUMNS c
LEFT JOIN
INFORMATION_SCHEMA.TABLES t
ON c.TABLE_SCHEMA = t.TABLE_SCHEMA
AND c.TABLE_NAME = t.TABLE_NAME
WHERE
c.TABLE_SCHEMA = '你的数据库名称'
AND (c.COLUMN_COMMENT IS NULL OR c.COLUMN_COMMENT = '' OR c.COLUMN_COMMENT = ' ')
ORDER BY
c.TABLE_NAME, c.ORDINAL_POSITION;
6.数据库整体统计(数据大小 + 索引大小)
-- 行转列版本3:最简洁优雅
WITH db_stats AS (
SELECT
TABLE_SCHEMA,
COUNT(DISTINCT TABLE_NAME) AS table_count,
SUM(DATA_LENGTH) AS data_size,
SUM(INDEX_LENGTH) AS index_size,
SUM(DATA_FREE) AS free_size,
AVG(DATA_LENGTH + INDEX_LENGTH) AS avg_size,
SUM(TABLE_ROWS) AS total_rows
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = '你的数据库名称' AND TABLE_TYPE = 'BASE TABLE'
GROUP BY TABLE_SCHEMA
)
SELECT '数据库名称' AS 统计项, TABLE_SCHEMA AS 统计值 FROM db_stats
UNION ALL SELECT '表数量', CAST(table_count AS CHAR) FROM db_stats
UNION ALL SELECT '数据大小(MB)', CONCAT(ROUND(data_size / 1024 / 1024, 2)) FROM db_stats
UNION ALL SELECT '数据大小(GB)', CONCAT(ROUND(data_size / 1024 / 1024 / 1024, 2)) FROM db_stats
UNION ALL SELECT '索引大小(MB)', CONCAT(ROUND(index_size / 1024 / 1024, 2)) FROM db_stats
UNION ALL SELECT '索引大小(GB)', CONCAT(ROUND(index_size / 1024 / 1024 / 1024, 2)) FROM db_stats
UNION ALL SELECT '总大小(MB)', CONCAT(ROUND((data_size + index_size) / 1024 / 1024, 2)) FROM db_stats
UNION ALL SELECT '总大小(GB)', CONCAT(ROUND((data_size + index_size) / 1024 / 1024 / 1024, 2)) FROM db_stats
UNION ALL SELECT '碎片大小(MB)', CONCAT(ROUND(free_size / 1024 / 1024, 2)) FROM db_stats
UNION ALL SELECT '索引占比', CONCAT(ROUND(index_size * 100.0 / (data_size + index_size), 2), '%') FROM db_stats
UNION ALL SELECT '平均表大小(MB)', CONCAT(ROUND(avg_size / 1024 / 1024, 2)) FROM db_stats
UNION ALL SELECT '总行数', CAST(total_rows AS CHAR) FROM db_stats;
7. 查询每个表的大小、索引大小、磁盘占用详情
SELECT
TABLE_SCHEMA AS 数据库名称,
TABLE_NAME AS 表名,
ENGINE AS 存储引擎,
TABLE_ROWS AS 行数,
-- 数据大小
ROUND(DATA_LENGTH / 1024 / 1024, 2) AS 数据大小MB,
-- 索引大小
ROUND(INDEX_LENGTH / 1024 / 1024, 2) AS 索引大小MB,
-- 总占用空间
ROUND((DATA_LENGTH + INDEX_LENGTH) / 1024 / 1024, 2) AS 总占用MB,
-- 碎片大小
ROUND(DATA_FREE / 1024 / 1024, 2) AS 碎片大小MB,
-- 索引占比
CASE
WHEN (DATA_LENGTH + INDEX_LENGTH) > 0 THEN
CONCAT(
ROUND(INDEX_LENGTH * 100.0 / (DATA_LENGTH + INDEX_LENGTH), 2),
'%'
)
ELSE '0%'
END AS 索引占比,
-- 平均行大小
CASE
WHEN TABLE_ROWS > 0 THEN
ROUND((DATA_LENGTH + INDEX_LENGTH) / TABLE_ROWS, 2)
ELSE 0
END AS 平均行大小Byte,
-- 碎片率
CASE
WHEN (DATA_LENGTH + INDEX_LENGTH) > 0 THEN
CONCAT(
ROUND(DATA_FREE * 100.0 / (DATA_LENGTH + INDEX_LENGTH + DATA_FREE), 2),
'%'
)
ELSE '0%'
END AS 碎片率,
-- 创建和更新时间
DATE_FORMAT(CREATE_TIME, '%Y-%m-%d %H:%i:%s') AS 创建时间,
DATE_FORMAT(UPDATE_TIME, '%Y-%m-%d %H:%i:%s') AS 最后修改时间,
TABLE_COMMENT AS 表注释
FROM
INFORMATION_SCHEMA.TABLES
WHERE
TABLE_SCHEMA = '你的数据库名称'
AND TABLE_TYPE = 'BASE TABLE'
ORDER BY
(DATA_LENGTH + INDEX_LENGTH) DESC -- 按总占用空间降序排列
8.找出最大的TOP 10表
SELECT
TABLE_NAME AS 表名,
ROUND((DATA_LENGTH + INDEX_LENGTH) / 1024 / 1024, 2) AS 总占用MB,
ROUND(DATA_LENGTH / 1024 / 1024, 2) AS 数据大小MB,
ROUND(INDEX_LENGTH / 1024 / 1024, 2) AS 索引大小MB,
TABLE_ROWS AS 行数,
CONCAT(
ROUND(INDEX_LENGTH * 100.0 / (DATA_LENGTH + INDEX_LENGTH), 2),
'%'
) AS 索引占比,
TABLE_COMMENT AS 表注释
FROM
INFORMATION_SCHEMA.TABLES
WHERE
TABLE_SCHEMA = '你的数据库名称'
AND TABLE_TYPE = 'BASE TABLE'
ORDER BY
(DATA_LENGTH + INDEX_LENGTH) DESC
LIMIT 10;
9. 索引优化检测
SELECT
TABLE_NAME AS 表名,
TABLE_ROWS AS 行数,
ROUND((DATA_LENGTH + INDEX_LENGTH) / 1024 / 1024, 2) AS 总占用MB,
ROUND(DATA_LENGTH / 1024 / 1024, 2) AS 数据大小MB,
ROUND(INDEX_LENGTH / 1024 / 1024, 2) AS 索引大小MB,
CONCAT(
ROUND(INDEX_LENGTH * 100.0 / (DATA_LENGTH + INDEX_LENGTH), 2),
'%'
) AS 索引占比,
ROUND(DATA_FREE / 1024 / 1024, 2) AS 碎片大小MB,
CONCAT(
ROUND(DATA_FREE * 100.0 / (DATA_LENGTH + INDEX_LENGTH + DATA_FREE), 2),
'%'
) AS 碎片率,
-- 更合理的判断逻辑
CASE
-- 碎片率超过20%,明确需要优化
WHEN DATA_FREE / (DATA_LENGTH + INDEX_LENGTH + DATA_FREE) > 0.2 THEN '⚠️ 碎片过多-需要OPTIMIZE'
-- 索引大且数据量大的情况才需要检查
WHEN INDEX_LENGTH / (DATA_LENGTH + INDEX_LENGTH) > 0.5
AND (DATA_LENGTH + INDEX_LENGTH) > 100 * 1024 * 1024 -- 总大小超过100MB
THEN '🔍 索引占比高-建议检查冗余索引'
-- 碎片率10-20%,可以考虑优化
WHEN DATA_FREE / (DATA_LENGTH + INDEX_LENGTH + DATA_FREE) > 0.1 THEN '💡 有碎片-可考虑优化'
ELSE '✅ 正常'
END AS 优化建议,
-- 提供不同的优化建议
CASE
WHEN DATA_FREE / (DATA_LENGTH + INDEX_LENGTH + DATA_FREE) > 0.1
THEN CONCAT('OPTIMIZE TABLE `', TABLE_NAME, '`;')
WHEN INDEX_LENGTH / (DATA_LENGTH + INDEX_LENGTH) > 0.5
AND (DATA_LENGTH + INDEX_LENGTH) > 100 * 1024 * 1024
THEN CONCAT('-- 检查表 ', TABLE_NAME, ' 的索引使用情况:\nSHOW INDEX FROM `', TABLE_NAME, '`;\nSELECT * FROM sys.schema_unused_indexes WHERE object_schema=''你的数据库名称'' AND object_name=''', TABLE_NAME, ''';')
ELSE '-- 无需优化'
END AS 优化SQL
FROM
INFORMATION_SCHEMA.TABLES
WHERE
TABLE_SCHEMA = '你的数据库名称'
AND TABLE_TYPE = 'BASE TABLE'
AND (
-- 只关注真正有问题的表
DATA_FREE / (DATA_LENGTH + INDEX_LENGTH + DATA_FREE) > 0.1 -- 碎片率超过10%
OR (
INDEX_LENGTH / (DATA_LENGTH + INDEX_LENGTH) > 0.5 -- 索引占比超过50%
AND (DATA_LENGTH + INDEX_LENGTH) > 100 * 1024 * 1024 -- 且总大小超过100MB
)
)
ORDER BY
DATA_FREE DESC;
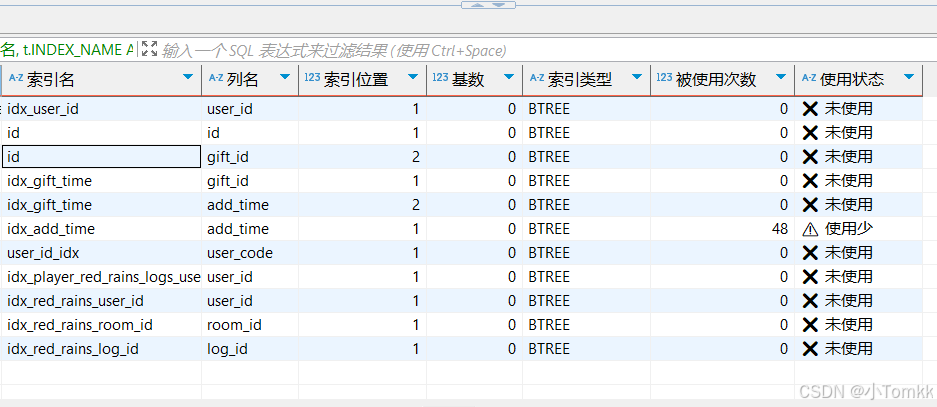
10.查看索引使用统计(需要开启performance_schema)
SELECT
t.TABLE_NAME AS 表名,
t.INDEX_NAME AS 索引名,
t.COLUMN_NAME AS 列名,
t.SEQ_IN_INDEX AS 索引位置,
t.CARDINALITY AS 基数,
t.INDEX_TYPE AS 索引类型,
s.rows_selected AS 被使用次数,
CASE
WHEN s.rows_selected IS NULL OR s.rows_selected = 0 THEN '❌ 未使用'
WHEN s.rows_selected < 100 THEN '⚠️ 使用少'
ELSE '✅ 正常使用'
END AS 使用状态
FROM
INFORMATION_SCHEMA.STATISTICS t
LEFT JOIN
sys.schema_index_statistics s
ON t.TABLE_SCHEMA = s.table_schema
AND t.TABLE_NAME = s.table_name
AND t.INDEX_NAME = s.index_name
WHERE
t.TABLE_SCHEMA = '你的数据库名称'
AND t.INDEX_NAME != 'PRIMARY'
ORDER BY
t.TABLE_NAME,
IFNULL(s.rows_selected, 0) ASC;
| 情况 | 是否需要优化 | 原因 |
|---|---|---|
| 碎片率 > 20% | ✅ 需要 | 明确影响性能 |
| 碎片率 10-20% | 💡 建议 | 可以优化 |
| 索引占比 > 50% 且表很小 (<10MB) | ❌ 不需要 | 正常现象 |
| 索引占比 > 50% 且表很大 (>100MB) | 🔍 需检查 | 可能有冗余索引 |
| 索引从不使用 | ✅ 需要 | 删除无用索引 |
11.后端开发人员加 备注指南
1️⃣ 创建表时添加备注
-- 示例:创建表时同时添加表备注和列备注
CREATE TABLE `user_info` (
`id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '用户ID,主键',
`username` VARCHAR(50) NOT NULL COMMENT '用户名,唯一标识',
`email` VARCHAR(100) DEFAULT NULL COMMENT '用户邮箱地址',
`phone` VARCHAR(20) DEFAULT NULL COMMENT '手机号码',
`status` TINYINT DEFAULT 1 COMMENT '用户状态:0-禁用,1-启用,2-冻结',
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_username` (`username`),
KEY `idx_email` (`email`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户信息表,存储系统用户的基本信息';
2️⃣ 修改现有表,添加表备注
– 方法1:只修改表备注
ALTER TABLE `user_info` COMMENT = '用户信息表,存储系统用户的基本信息';
– 方法2:同时修改表的其他属性和备注
ALTER TABLE `user_info`
ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
COMMENT = '用户信息表,存储系统用户的基本信息';
3️⃣ 给现有列添加备注
– 方法1:MODIFY COLUMN(需要重新定义列的完整信息)
ALTER TABLE `user_info`
MODIFY COLUMN `username` VARCHAR(50) NOT NULL COMMENT '用户名,唯一标识';
– 方法2:CHANGE COLUMN(可以同时修改列名和备注)
ALTER TABLE `user_info`
CHANGE COLUMN `username` `username` VARCHAR(50) NOT NULL COMMENT '用户名,唯一标识';
– 注意:必须保留列的原有属性(类型、长度、是否为空、默认值等)
4️⃣ 批量添加备注(推荐方式)
– 一次性修改多个列的备注
ALTER TABLE `user_info`
MODIFY COLUMN `id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '用户ID,主键',
MODIFY COLUMN `username` VARCHAR(50) NOT NULL COMMENT '用户名,唯一标识',
MODIFY COLUMN `email` VARCHAR(100) DEFAULT NULL COMMENT '用户邮箱地址',
MODIFY COLUMN `phone` VARCHAR(20) DEFAULT NULL COMMENT '手机号码',
MODIFY COLUMN `status` TINYINT DEFAULT 1 COMMENT '用户状态:0-禁用,1-启用,2-冻结';
备注规范建议
✅ 好的备注示例:
-- 表备注
COMMENT = '用户信息表,存储系统注册用户的基本资料和账户信息'
-- 列备注
`status` TINYINT COMMENT '用户状态:0-禁用,1-正常,2-冻结,3-注销'
`price` DECIMAL(10,2) COMMENT '商品价格,单位:元,保留2位小数'
`user_id` BIGINT COMMENT '用户ID,关联user_info.id'
`create_time` DATETIME COMMENT '记录创建时间,自动生成'



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











