



1.线程基本定义
进程:进程是程序运行资源分配的最小单位 。进程是操作系统进行资源分配的最小单位,其中资源包括:CPU、内存空间、 磁盘 IO 等,同一进程中的多条线程共享该进程中的全部系统资源,而进程和进程 之间是相互独立的。
线程:线程是 CPU 调度的最小单位,必须依赖于进程而存在 线程是进程的一个实体,是 CPU 调度和分派的基本单位,它是比进程更小的、 能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中 必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其 他的线程共享进程所拥有的全部资源。
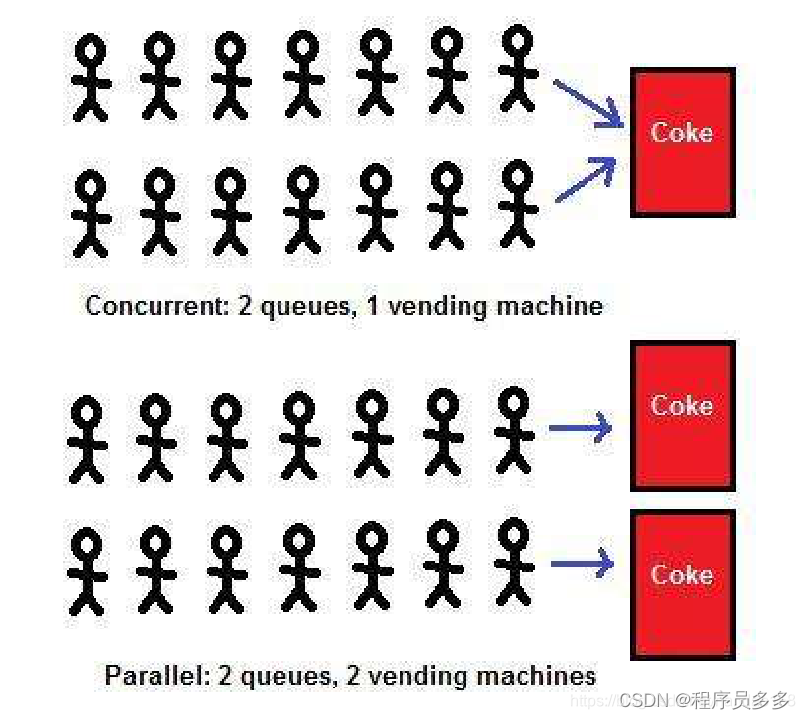
并发:指应用能够交替执行任务,比如单核CPU下执行多线程任务的时候,每个线程并不是同事执行,而是当某一线程所获得的CPU执行时间结束后或者线程结束后,CPU会切换到另一个线程继续执行线程任务,线程是交替执行的并不是同时执行的,只不过由于CPU执行速度极快,致使我们认为各个线程是同时执行的。
并行:并行就是真正意义上的多个线程任务同时执行,比如一个人他正在吃饭的同时也在看电视,这就是两个并行的线程任务。
2.java中的线程
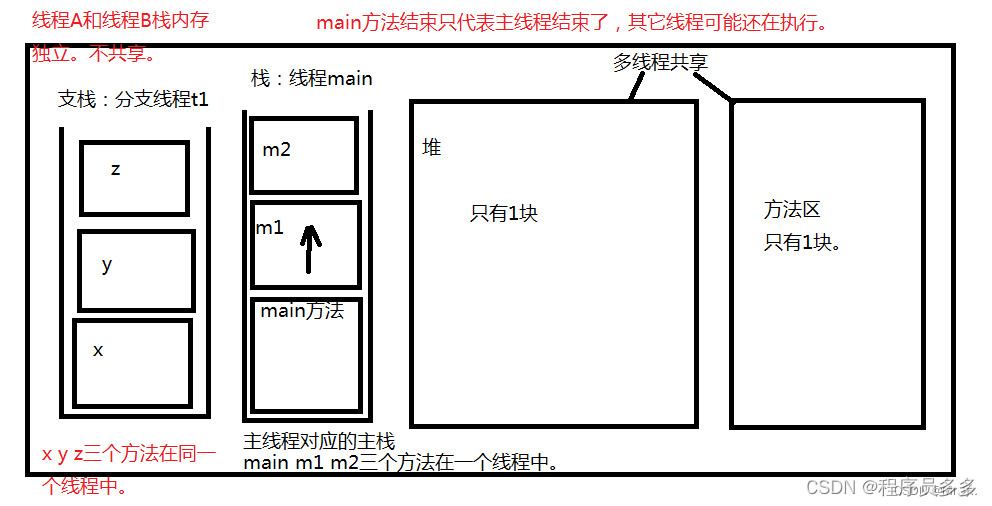
线程A和线程B,堆内存和方法区内存共享。
但是栈内存独立,一个线程一个栈。
假设启动10个线程,会有10个栈空间,每个栈和每个栈之间,互不干扰,各自执行各自的,这就是多线程并发。
3.线程的生命周期
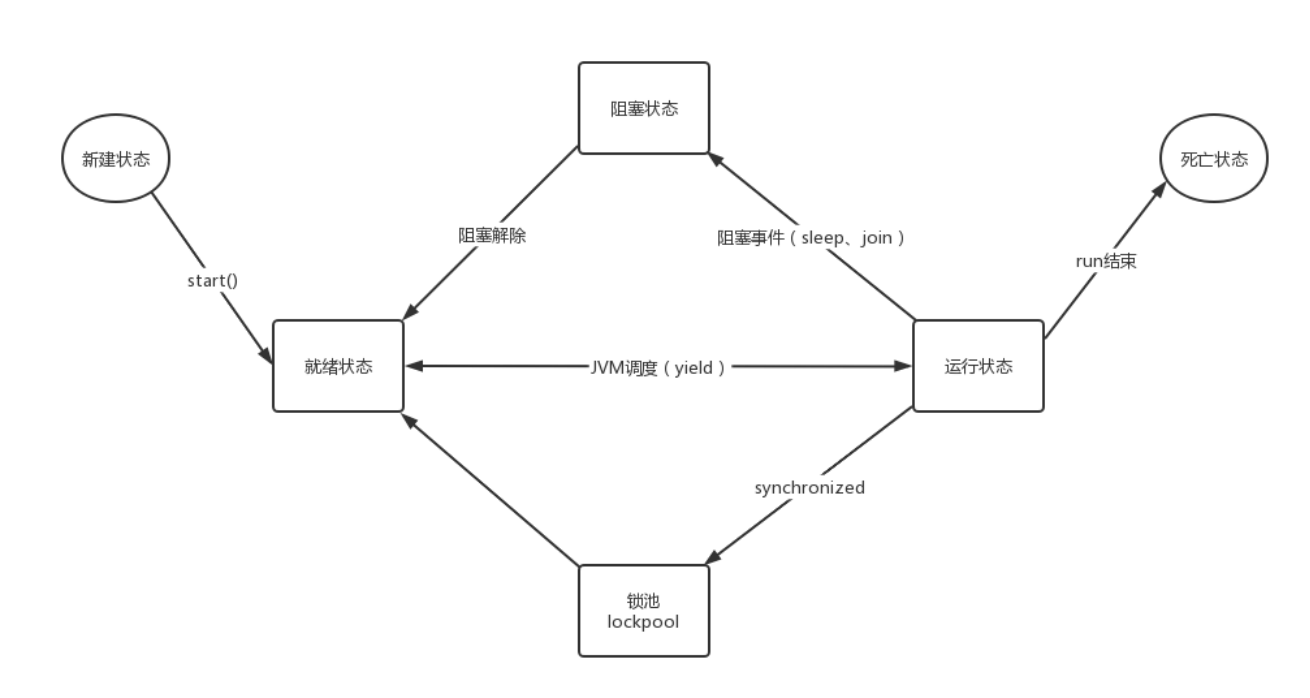
就绪状态:就绪状态的线程又叫做可运行状态,表示当前线程具有抢夺CPU时间片的权力(CPU时间片就是执行权)。当一个线程抢夺到CPU时间片之后,就开始执行run方法,run方法的开始执行标志着线程进入运行状态。
运行状态:run方法的开始执行标志着这个线程进入运行状态,当之前占有的CPU时间片用完之后,会重新回到就绪状态继续抢夺CPU时间片,当再次抢到CPU时间之后,会重新进入run方法接着上一次的代码继续往下执行。
阻塞状态:当一个线程遇到阻塞事件,例如接收用户键盘输入,或者sleep方法等,此时线程会进入阻塞状态,阻塞状态的线程会放弃之前占有的CPU时间片。之前的时间片没了需要再次回到就绪状态抢夺CPU时间片。
锁池:在这里找共享对象的对象锁线程进入锁池找共享对象的对象锁的时候,会释放之前占有CPU时间片,有可能找到了,有可能没找到,没找到则在锁池中等待,如果找到了会进入就绪状态继续抢夺CPU时间片。(这个进入锁池,可以理解为一种阻塞状态)
2.多线程实现方式
2.1继承Thread
public class ThreadDemo{
public static void main(String[] arg) {
MyThread thread1 = new Thread();
MyThread thread2 = new Thread("t2");
thread1.start();
thread2.start(); // 注意当执行thread对象的run方法是不会开启一个新的线程的,run()方法会在miain线程执行
thread1.setName("t1");
Thread.currentThread().setName("main");
for (int i = 0; i < 50; i++) {
system.out.println(Thread.currentThread().getName() + "-" + i);
}
}
}
class MyThread extend Thread {
public MyThread(){
}
public MyThread(String threadName){
super(threadName);
}
@Override
public void run() {
for (int i = 0; i < 50; i++) {
System.out.println(this.getName() + ":" + i);
}
}
}此处最重要的为start()方法。单纯调用run()方法不会启动线程,不会分配新的分支栈。
start()方法的作用是:启动一个分支线程,在JVM中开辟一个新的栈空间,这段代码任务完成之后,瞬间就结束了。线程就启动成功了。
启动成功的线程会自动调用run方法(由JVM线程调度机制来运作的),并且run方法在分支栈的栈底部(压栈)。
run方法在分支栈的栈底部,main方法在主栈的栈底部。run和main是平级的。
单纯使用run()方法是不能多线程并发的。
2.2实现Runnable接口
public class ThreadDemo{
public static void main(String[] arg) {
MyThread runnableThread = new MyThread();
Thread thread1 = new Thread(runnableThread,"t1");
Thread thread2 = new Thread(runnableThread,"t2");
thread1.start();
thread2.start();
//通过匿名内部类的方式创建线程
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 20; i++) {
System.out.println(Thread.currentThread().getName() + " - " + i);
}
}
},"t3").start();
}
}
class MyThread implements Runnable {
@Override
public void run() {
for (int i = 0; i < 50; i++) {
System.out.println(this.getName() + ":" + i);
}
}
}2.3实现Callable接口
public class Demo04 {
public static void main(String[] args) throws Exception {
// 第一步:创建一个“未来任务类”对象。
// 参数非常重要,需要给一个Callable接口实现类对象。
FutureTask task = new FutureTask(new Callable() {
@Override
public Object call() throws Exception { // call()方法就相当于run方法。只不过这个有返回值
// 线程执行一个任务,执行之后可能会有一个执行结果
// 模拟执行
System.out.println("call method begin");
Thread.sleep(1000 * 10);
System.out.println("call method end!");
int a = 100;
int b = 200;
return a + b; //自动装箱(300结果变成Integer)
}
});
// 创建线程对象
Thread t = new Thread(task);
// 启动线程
t.start();
// 这里是main方法,这是在主线程中。
// 在主线程中,怎么获取t线程的返回结果?
// get()方法的执行会导致“当前线程阻塞”
Object obj = task.get();
System.out.println("线程执行结果:" + obj);
// main方法这里的程序要想执行必须等待get()方法的结束
// 而get()方法可能需要很久。因为get()方法是为了拿另一个线程的执行结果
// 另一个线程执行是需要时间的。
System.out.println("hello world!");
}
}这种方式的优点:可以获取到线程的执行结果。
这种方式的缺点:效率比较低,在获取t线程执行结果的时候,当前线程受阻塞,效率较低。
2.4Runnable与Callable实现多线程的区别
1.实现接口不同,一个实现的是Runnable接口并重写Run()方法,一个实现的事Callable()接口重写的是Call()方法。
2.也是两者的最大区别,实现Callable接口需要重写Call()方法,Call()方法有返回值,所以使用Callable接口实现多线程可以获取到线程的执行结果,通过FultureTask的get()方法获得到返回的结果值。
3.call()方法可以向上抛出异常,但run()方法不可以,出现异常了必须在内部解决。
3.线程的方法
具体请看http://t.csdnimg.cn/l5mIm与http://t.csdnimg.cn/Fkkff
注意点:
3.1 join()
join()方法是在哪个线程调用了就会阻塞哪个线程
public static void main(String[] args) throws InterruptedException {
log.debug("开始");
Thread t1 = new Thread(() -> {
log.debug("开始");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("结束");
r = 10;
},"t1");
t1.start();
t1.join();
log.debug("结果为:{}", r);
log.debug("结束");
/**
* 不使用join()方法时候的结果为:
* 21:27:50.683 c.Test10 [main] - 开始
* 21:27:50.714 c.Test10 [t1] - 开始
* 21:27:50.714 c.Test10 [main] - 结果为:0
* 21:27:50.715 c.Test10 [main] - 结束
* 21:27:51.720 c.Test10 [t1] - 结束
* 使用join()方法后的结果
* 21:28:55.345 c.Test10 [main] - 开始
* 21:28:55.378 c.Test10 [t1] - 开始
* 21:28:56.380 c.Test10 [t1] - 结束
* 21:28:56.380 c.Test10 [main] - 结果为:10
* 21:28:56.382 c.Test10 [main] - 结束
*/
}需要强调的是执行join()此时main线程会进入阻塞状态,当t1线程执行完毕之后,main线程会继续执行,若假如有体t2线程也在main线程调用了t2.join()方法,则main线程需等待t2线程执行结束后再继续执行。
public final void join() throws InterruptedException {
//调用带有一个形参的join方法
join(0);
}
public final synchronized void join(long millis, int nanos)
throws InterruptedException {
//对参数millis合法性进行检查,如果小于0那么该参数为非法参数就会抛出异常
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
//对参数nanos 合法性进行检查,如果小于0那么该参数为非法参数就会抛出异常
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
//如果纳秒数大于等于500000或者毫秒数为0但是纳秒数不为0,那么把毫秒数参数millis加1
if (nanos >= 500000 || (nanos != 0 && millis == 0)) {
millis++;
}
//调用只有一个参数的join方法,此时millis最多比调用该方法时多1毫秒
join(millis);
}
public final synchronized void join(long millis)
throws InterruptedException {
//记录当前时间毫秒数
long base = System.currentTimeMillis();
//定义变量now,变量nowjoin代表该join方法已经执行的毫秒数
long now = 0;
//对参数合法性进行检查,如果小于0那么该参数为非法参数就会抛出异常
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
//如果参数等于0
if (millis == 0) {
//只要该线程处于活动状态那么进入while循环体
while (isAlive()) {
//如果该线程还存活,那么调用该线程join方法的线程,就会被置为阻塞状态(TIMED_WAITING)
wait(0);
}
} else {
//如果参数不等于0,其实到这一步就代表参数大于0
//只要该线程处于活动状态那么进入while循环体
while (isAlive()) {
//计算参数millis与now的差值
long delay = millis - now;
//如果差值delay小于等于零(主线程阻塞的时间大于等于millis 毫秒),
//那么就执行break,即跳出循环,
//这也就代表这join方法执行完毕
if (delay <= 0) {
break;
}
//主线程阻塞(TIMED_WAITING)dealy毫秒,
//但此时主线程可能在小于dealy毫秒的时候被唤醒
wait(delay);
//无论主线程是等待时间够了,还是在等待的中途被打断了
//now 变量都会被重新赋值,值为当前时间毫秒数减去刚进入该方法的时间数
//即now变量代表着join方法已经执行的毫秒数
//赋值完成后会继续进行下一轮的while循环
now = System.currentTimeMillis() - base;
}
}
}当主线程调用t1线程的join方法,那么此时主线程就会获得线程对象t1的锁,带主线程被wait后那么主线程会让出cpu及线程对象t1的锁。
如果线程t1还没有调用start方法启动,就调用t1的jion方法,是无效的,因为此时t1线程的isAlive()为false,即该线程还不是处于活动状态,此时就不会阻塞主线程。
3.2 yield()与sleep()
yield()方法与sleep()方法都是用Thread.的方式调用的,作用对象都是当前线程,sleep()方法会使线程进入阻塞状态,而yield()方法则是进入就绪状态,重新开始抢夺cpu执行时间片。
3.3 wait()与sleep()区别
Object.wait() 和 Thread.sleep() 是多线程编程中最常用的使线程等待的两个方法。
不同点:
- sleep()方法输入Thread类,而Object.wait()方法属于Object类
- sleep()方法使线程睡眠一定的时间,不能被唤醒,而wait()可以被唤醒,通过notify()/notifyAll()方法唤醒线程
- sleep()方法不释放任何资源,而wait()方法会释放所有资源
- wait()和notify()需要配合synchronized使用
4 线程池
补充:
在
ThreadPoolExecutor中,队列是指任务队列,它用于存放等待执行的任务。任务队列在ThreadPoolExecutor的构造方法中通过参数传递,这个参数的类型是BlockingQueue<Runnable>。Java线程池中的任务队列通常有以下几种类型:
直接交付队列(SynchronousQueue):
- 这种队列实际上不会保存提交的任务,而是直接将任务交给线程执行。如果没有可用线程,那么尝试创建新线程(如果当前线程数小于
maximumPoolSize)。无界任务队列(LinkedBlockingQueue):
- 如果使用无界队列(理论上有
Integer.MAX_VALUE的容量),那么所有提交的任务都会被加入队列等待执行,这意味着永远不会有超过corePoolSize个线程被创建(除非设置了allowCoreThreadTimeOut并且核心线程超时了),maximumPoolSize的值也就无效了。有界任务队列(ArrayBlockingQueue):
- 有界队列有一个固定的容量,当使用有界队列时,如果当前运行的线程数少于
corePoolSize,线程池会优先创建新线程而不是将任务加入队列;当运行的线程数等于corePoolSize时,新任务会被加入队列,直到队列满;一旦队列满了,会继续创建新线程处理任务,直到线程数达到maximumPoolSize。如果线程数已经达到maximumPoolSize,则采取饱和策略处理新提交的任务。优先任务队列(PriorityBlockingQueue):
- 这是一个特殊的无界队列,它可以根据任务之间的优先级顺序来执行任务。
线程池中各个参数的意义:
corePoolSize: 线程池的核心线程数,在没有任务需要执行时,核心线程会一直保持活动状态,即使没有任务可执行。如果线程池中的线程数量小于
corePoolSize,新的任务将会创建新线程来处理。maxNumPoolSize: 线程池允许创建的最大线程数,当线程池中的线程数量达到
corePoolSize且工作队列已满时,线程池可以创建更多的线程(直到达到maximumPoolSize)来处理任务。超过maximumPoolSize的任务将根据线程池的饱和策略进行处理。keepAliveTime :如果线程池中的线程数超过核心线程数,并且这些线程在指定的时间段内处于空闲状态,那么多余的空闲线程将被销毁,直到线程池中的线程数等于核心线程数。
TimeUnit :用于指定上述的时间参数的单位,例如秒、毫秒等。
workQueue :
workQueue是用于存储等待执行的任务的队列。当线程池中的线程数量达到corePoolSize时,新的任务会被添加到工作队列中等待执行。当工作队列已满时,如果线程池中的线程数量未达到maximumPoolSize,则会创建新的线程来处理任务;如果线程池中的线程数量已经达到maximumPoolSize,则根据饱和策略来处理任务。RejectedExecutionHandler :(饱和策略)当任务队列和线程池都已满时,用于处理新提交的任务的策略。常见的饱和策略有:抛出异常、丢弃任务、丢弃队列中最老的任务、由调用线程执行等。
在线程池中,常用的饱和策略(
RejectedExecutionHandler)有以下几种:
AbortPolicy:默认的饱和策略,当任务无法被提交时,会抛出RejectedExecutionException异常。
CallerRunsPolicy:如果线程池已满,新任务会由提交任务的线程来执行。这可能会导致调用线程的阻塞或延迟。
DiscardOldestPolicy:如果线程池已满,丢弃队列中最老的一个任务,然后执行当前任务。
DiscardPolicy:如果线程池已满,直接丢弃新提交的任务,不做任何处理。线程池中各个参数的关系:当进入线程池中的任务数少于corePoolSize时,线程池使用核心线程去处理任务。当核心线程都被占用了仍然有新的任务进来的时候,会将新来的任务放入到workQueue任务队列中去。当积压的任务达到了任务队列最大上限的时候,此时线程池创建的线程数量没有超过maxNumPoolSize时,线程池会创建非核心线程去执行任务,创建的最大非核心线程的数量为 (maxNumPoolSize - corePoolSize)。如果还是有任务进来,此时线程池无法创建新的线程,任务队列也已经存满了,会执行线程池的包和策略去抛出异常或是丢弃任务等等。
线程池执行:
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.Date;
public class ThreadPoolExecutorDemo {
private static final int CORE_POOL_SIZE = 5;
private static final int MAX_POOL_SIZE = 10;
private static final int QUEUE_CAPACITY = 100;
private static final Long KEEP_ALIVE_TIME = 1L;
public static void main(String[] args) {
//使用阿里巴巴推荐的创建线程池的方式
//通过ThreadPoolExecutor构造函数自定义参数创建
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAX_POOL_SIZE,
KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 10; i++) {
//创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
Runnable worker = new MyRunnable("" + i);
//执行Runnable
executor.execute(worker);// 这里是直接执行线程任务,如果想要获取执行线程的结果可以调用submit()方法,返回值是Future
}
//终止线程池
executor.shutdown();
while (!executor.isTerminated()) {
}
System.out.println("Finished all threads");
}
}
class MyRunnable implements Runnable {
private String command;
public MyRunnable(String s) {
this.command = s;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
processCommand();
System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
}
private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return this.command;
}
}
5.线程同步机制
lock:http://t.csdnimg.cn/KMWH5
生产者-消费者模型:经典并发同步模式:生产者-消费者设计模式 - 知乎

















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









