







汇编语言堆栈
如下图所示,如果把 10 个盘子垒起来,其结果就称为堆栈。虽然有可能从这个堆栈的中间移出一个盘子,但是,更普遍的是从顶端移除。新的盘子可以叠加到堆栈顶部,但不能加在底部或中部。
堆栈数据结构(stack data structure)的原理与盘子堆栈相同:新值添加到栈顶,删除值也在栈顶移除。通常,对各种编程应用来说,堆栈都是有用的结构,并且它们也容易用面向对象的编程方法来实现。
如果大家已经学习过使用数据结构的编程课程,那么就应该已经用过堆栈抽象数据类型(stack abstract data type)。
堆栈也被称为 LIFO 结构(后进先出,Last-In First-Out),,其原因是,最后进入堆栈的值也是第一个出堆栈的值。
汇编语言运行时堆栈
运行时堆栈是内存数组,CPU 用 ESP(扩展堆栈指针,extended stack pointer)寄存器对其进行直接管理,该寄存器被称为堆栈指针寄存器(stack pointer register)。
32位模式下,ESP 寄存器存放的是堆栈中某个位置的 32 位偏移量。ESP 基本上不会直接被程序员控制,反之,它是用 CALL、RET、PUSH 和 POP 等指令间接进行修改。
ESP 总是指向添加,或压入(pushed)到栈顶的最后一个数值。为了便于说明,假设现有一个堆栈,内含一个数值。如下图所示,ESP 的内容是十六进制数 0000 1000,即刚压入堆栈数值(0000 0006)的偏移量。在图中,当堆栈指针数值减少时,栈顶也随之下移。
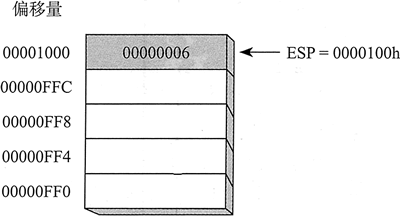
上图中,每个堆栈位置都是32位长,这 是32位模式下运行程序的情形。
运行时堆栈工作于系统层,处理子程序调用。堆栈 ADT 是编程结构,通常用高级编程语言编写,如 C++ 或 Java。它用于实现基于后进先出操作的算法。
入栈操作
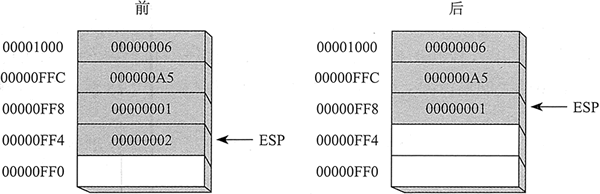
32 位入栈操作把栈顶指针减 4,再将数值复制到栈顶指针指向的堆栈位置。下图展示了把 0000 00A5 压入堆栈的结果,堆栈中已经有一个数值(0000 0006)。注意,ESP 寄存器总是指向最后压入堆栈的数据项。
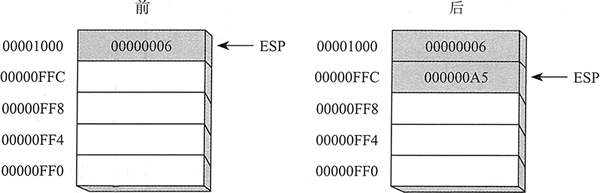
上图中显示的堆栈顺序与之前示例给出的盘堆栈顺序相反,这是因为运行时堆栈在内存中是向下生长的,即从高地址向低地址扩展。入栈之前, ESP=0000 1000h;入栈之后,ESP=0000 0FFCh。下图显示了同一个堆栈总共压入 4 个整数之后的情况。
出栈操作
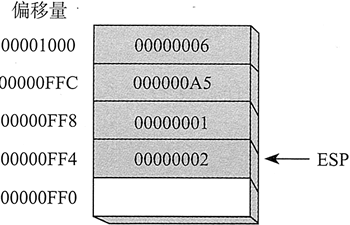
出栈操作从堆栈删除数据。数值弹岀堆栈后,栈顶指针增加(按堆栈元素大小),指向堆栈中下一个最高位置。下图展示了数值 0000 0002 弹出前后的堆栈情况。
ESP 之下的堆栈域在逻辑上是空白的,当前程序下一次执行任何数值入栈操作指令都可以覆盖这个区域。
堆栈应用
运行时堆栈在程序中有一些重要用途:
- 当寄存器用于多个目的时,堆栈可以作为寄存器的一个方便的临时保存区。在寄存器被修改后,还可以恢复其初始值。
- 执行 CALL 指令时,CPU 在堆栈中保存当前过程的返回地址。
- 调用过程时,输入数值也被称为参数,通过将其压入堆栈实现参数传递。
- 堆栈也为过程局部变量提供了临时存储区域。
汇编语言PUSH和POP指令(压栈和出栈)
汇编里把一段内存空间定义为一个栈,栈总是先进后出,栈的最大空间为 64K。由于 "栈" 是由高到低使用的,所以新压入的数据的位置更低,ESP 中的指针将一直指向这个新位置,所以 ESP 中的地址数据是动态的。
PUSH 指令
PUSH 指令首先减少 ESP 的值,再将源操作数复制到堆栈。操作数是 16 位的,则 ESP 减 2,操作数是 32 位的,则 ESP 减 4。PUSH 指令有 3 种格式:
PUSH reg/mem16
PUSH reg/mem32
PUSH inm32
POP指令
POP 指令首先把 ESP 指向的堆栈元素内容复制到一个 16 位或 32 位目的操作数中,再增加 ESP 的值。如果操作数是 16 位的,ESP 加 2,如果操作数是 32 位的,ESP 加 4:
POP reg/mem16
POP reg/mem32
PUSHFD 和 POPFD 指令
PUSHFD 指令把 32 位 EFLAGS 寄存器内容压入堆栈,而 POPFD 指令则把栈顶单元内容弹出到 EFLAGS 寄存器:
pushfd
popfd
不能用 MOV 指令把标识寄存器内容复制给一个变量,因此,PUSHFD 可能就是保存标志位的最佳途径。有些时候保存标志寄存器的副本是非常有用的,这样之后就可以恢复标志寄存器原来的值。通常会用 PUSHFD 和 POPFD 封闭一段代码:
pushfd ;保存标志寄存器
;
;任意语句序列
;
popfd ;恢复标志寄存器
当用这种方式使用入栈和出栈指令时,必须确保程序的执行路径不会跳过 POPFD 指令。当程序随着时间不断修改时,很难记住所有入栈和出栈指令的位置。因此,精确的文档就显得至关重要!
一种不容易出错的保存和恢复标识寄存器的方法是:将它们压入堆栈后,立即弹出给一个变量:
.data saveFlags DWORD ? .code pushfd ;标识寄存器内容入栈 pop saveFLags ;复制给一个变量
下述语句从同一个变量中恢复标识寄存器内容:
push saveFlags ;被保存的标识入栈 popfd ;复制给标识寄存器
PUSHAD,PUSHA,POPAD 和 POPA
PUSHAD 指令按照 EAX、ECX、EDX、EBX、ESP(执行 PUSHAD 之前的值)、EBP、ESI 和 EDI 的顺序,将所有 32 位通用寄存器压入堆栈。
POPAD 指令按照相反顺序将同样的寄存器弹出堆栈。与之相似,PUSHA 指令按序(AX、CX、DX、BX、SP、BP、SI 和 DI)将 16 位通用寄存器压入堆栈。
POPA 指令按照相反顺序将同样的寄存器弹出堆栈。在 16 位模式下,只能使用 PUSHA 和 POPA 指令。
如果编写的过程会修改 32 位寄存器的值,则在过程开始时使用 PUSHAD 指令,在结束时使用 POPAD 指令,以此保存和恢复寄存器的内容。示例如下列代码段所示:
MySub PROC
pushad ;保存通用寄存器的内容
.
.
mov eax,...
mov edx,...
mov ecx,...
.
.
popad ;恢复通用寄存器的内容
ret
MySub ENDP
必须要指岀,上述示例有一个重要的例外:过程用一个或多个寄存器来返回结果时,不应使用 PUSHA 和 PUSHAD。假设下述 ReadValue 过程用 EAX 返回一个整数;调用 POPAD 将会覆盖 EAX 中的返回值:
ReadValue PROC
pushad ;保存通用寄存器的内容
.
.
mov eax rreturn_value
.
.
popad ;覆盖 EAX !
ret
ReadValue ENDP
示例:字符串反转
现在查看名为 RevStr 的程序:在一个字符串上循环,将每个字符压入堆栈,再把这些字符从堆栈中弹出(相反顺序),并保存回同一个字符串变量。由于堆栈是 LIFO(后进先出)结构,字符串中的字母顺序就发生了翻转:
;字符串翻转(Revstr.asm)
.386
.model flat,stdcall
.stack 4096
ExitProcess PROTO,dwExitCode:DWORD
.data
aName BYTE "Abraham Lincoln",0
nameSize = ($-aName)-1
.code
main PROC
;将名字压入堆栈
mov ecx,nameSize
mov esi,0
L1: movzx eax,aName[esi] ;获取字符
push eax ;压入堆栈
inc esi
loop L1
;将名字逆序弹出堆栈
;并存入aName数组
mov ecx,nameSize
mov esi,0
L2: pop eax ;获取字符
mov aName[esi],al ;存入字符串
inc esi
loop L2
INVOKE ExitProcess,0
main ENDP
END main
汇编语言PROC和ENDP伪指令
在汇编语言中,通常用术语过程(procedure)来指代子程序。在其他语言中,子程序也被称为方法或函数。
就面向对象编程而言,单个类中的函数或方法大致相当于封装在一个汇编语言模块中的过程和数据集合。汇编语言出现的时间远早于面向对象编程,因此它不具备面向对象编程中的形式化结构。汇编程序员必须在程序中实现自己的形式化结构。
定义过程
过程可以非正式地定义为:由返回语句结束的已命名的语句块。过程用 PROC 和 ENDP 伪指令来定义,并且必须为其分配一个名字(有效标识符)。到目前为止,所有编写的程序都包含了一个名为 main 的过程,例如:
main PROC
.
.
main ENDP
当在程序启动过程之外创建一个过程时,就用 RET 指令来结束它。RET 强制 CPU 返回到该过程被调用的位置:
sample PROC
.
.
ret
sample ENDP
过程中的标号
默认情况下,标号只在其被定义的过程中可见。这个规则常常影响到跳转和循环指令。在下面的例子中,名为 Destination 的标号必须与 JMP 指令位于同一个过程中:
jmp Destination
解决这个限制的方法是定义全局标号,即在名字后面加双冒号 (::)。
Destination::
就程序设计而言,跳转或循环到当前过程之外不是个好主意。过程用自动方式返回并调整运行时堆栈。如果直接跳出一个过程,则运行时堆栈很容易被损坏。
示例:三个整数求和
现在创建一个名为 SumOf 的过程计算三个 32 位整数之和。假设在过程调用之前,整数已经分配给 EAX、EBX 和 ECX。过程用 EAX 返回和数:
SumOf PROC
add eax,ebx
add eax,ecx
ret
SumOf ENDP
过程说明
要培养的一个好习惯是为程序添加清晰可读的说明。下面是对放在每个过程开头的信息的一些建议:
- 对过程实现的所有任务的描述。
- 输入参数及其用法的列表,并将其命名为 Receives ( 接收 )。如果输入参数对其数值有特殊要求,也要在这里列岀来。
- 对过程返回的所有数值的描述,并将其命名为 Returns ( 返回 )。
- 所有特殊要求的列表,这些要求被称为先决条件 (preconditions),必须在过程被调用之前满足。列表命名为 Requires。例如,对一个画图形线条的过程来说,一个有用的先决条件是该视频显示适配器必须已经处于图形模式。
上述选择的描述性标号,如 ReceivesReturns 和 Requires,不是绝对的;其他有用的名字也常常被使用。
有了这些思想,现在对 SumOf 过程添加合适的说明:
;-------------------------------------------------------
; sumof
; 计算 3 个 32 位整数之和并返回和数。
; 接收:EAX、EBX和ECX为3个整数,可能是有符号数,也可能是无符号数。
; 返回:EAX=和数
;------------------------------------------------------
SumOf PROC
add eax,ebx
add eax,ecx
ret
SumOf ENDP
用高级语言,如 C 和 C++,编写的函数,通常用 AL 返回 8 位的值,用 AX 返回 16 位的值,用 EAX 返回 32 位的值。
汇编语言CALL和RET指令
CALL 指令调用一个过程,指挥处理器从新的内存地址开始执行。过程使用 RET(从过程返回)指令将处理器转回到该过程被调用的程序点上。
从物理上来说,CALL 指令将其返回地址压入堆栈,再把被调用过程的地址复制到指令指针寄存器。当过程准备返回时,它的 RET 指令从堆栈把返回地址弹回到指令指针寄存器。32 位模式下,CPU 执行的指令由 EIP(指令指针寄存器)在内存中指岀。16 位模式下,由 IP 指出指令。
调用和返回示例
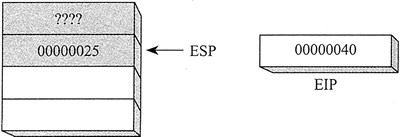
假设在 main 过程中,CALL 指令位于偏移量为 0000 0020 处。通常,这条指令需要 5 个字节的机器码,因此,下一条语句(本例中为一条 MOV 指令)就位于偏移量为 0000 0025 处:
main PROC
00000020 call MySub
00000025 mov eax,ebx
然后,假设 MySub 过程中第一条可执行指令位于偏移量 0000 0040 处:
MySub PROC
00000040 mov eaxz edx
.
.
ret
MySub ENDP
当 CALL 指令执行时如下图所示,调用之后的地址(0000 0025)被压入堆栈,MySub 的地址加载到 EIP。
执行 MySub 中的全部指令直到 RET 指令。当执行 RET 指令时,ESP 指向的堆栈数值被弹岀到 EIP(如下图所示,步骤 1)。在步骤 2 中,ESP 的数值增加,从而指向堆栈中的前一个值(步骤 2)。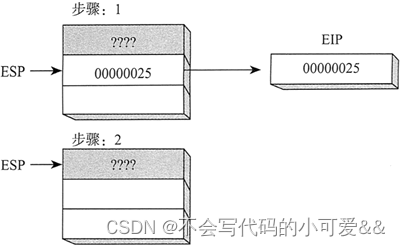
汇编语言过程调用嵌套
被调用过程在返回之前又调用了另一个过程时,就发生了过程调用嵌套。假设 main 调用了过程 Sub1。当 Sub1 执行时,它调用了过程 Sub2。当 Sub2 执行时,它调用了过程 Sub3。步骤如下图所示。
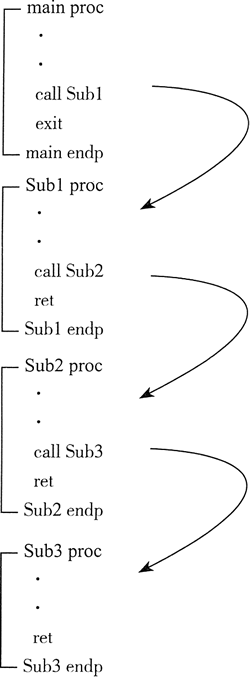
当执行 Sub3 末尾的 RET 指令时,将 stack[ESP](堆栈段首地址 +ESP 给岀的偏移量)中的数值弹出到指令指针寄存器中,这使得执行转回到调用 Sub3 后面的指令。下图显示的是执行从 Sub3 返回操作之前的堆栈:
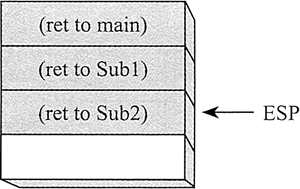
返回之后,ESP 指向栈顶下一个元素。当 Sub2 末尾的 RET 指令将要执行时,堆栈如下所示:
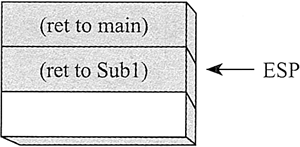
最后,执行 Sub1 的返回,stack[ESP] 的内容弹出到指令指针寄存器,继续在 main 中执行:
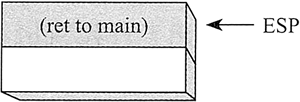
显然,堆栈证明了它很适合于保存信息,包括过程调用嵌套。一般说来,堆栈结构用于程序需要按照特定顺序返回的情况。
向过程传递寄存器参数
如果编写的过程要执行一些标准操作,如整数数组求和,那么,在过程中包含对特定变量名的引用就不是一个好主意。如果这样做了,该过程就只能作用于一个数组。更好的方法是向过程传递数组的偏移量以及指定数组元素个数的整数。这些内容被称为参数(或输入参数)。在汇编语言中,经常用通用寄存器来传递参数。
在《PROC和ENDP伪指令》一节中创建了一个简单的过程 SumOf,计算 EAX、EBX 和 ECX 中的整数之和。在 main 调用 SumOf 之前,将数值分配给 EAX、EBX 和 ECX:
.data theSum DWORD ? .code main PROC mov eax, 10000h ;参数 mov ebx, 20000h ;参数 mov ecx, 30000h ;参数 call Sumof ;EAX=(EAX+EEX+ECX) mov theSum,eax ;保存和数
在 CALL 语句之后,选择了将 EAX 中的和数复制给一个变量。
汇编语言示例:整数数组求和
程序员在 C++ 或 Java 中编写过的非常常见的循环类型是计算整数数组之和。这在汇编语言中很容易实现,它可以被编码为按照尽可能快的方式来运行。比如,在循环内可以使用寄存器而非变量。
现在创建一个过程 ArraySum,从一个调用程序接收两个参数:一个指向 32 位整数数组的指针,以及一个数组元素个数的计数器。该过程计算和数,并用 EAX 返回数组之和:
;------------------------------------
;ArraySum
;计算32位整数数组元素之和
;接收:ESI = 数组偏移量
; ECX = 数组元素的个数
;返回:EAX = 数组元素之和
;-------------------------------------
ArraySum PROC
push esi ;保存ESI和ECX
push ecx
mov eax,0 ;设置和数为0
L1: add eax,[esi] ;将每个整数与和数相加
add esi,TYPE DWORD ;指向下一个整数
loop L1 ;按照数组大小重复
pop ecx ;恢复ECX和ESI
pop esi
ret ;和数在EAX中
ArraySum ENDP
这个过程没有特别指定数组名称和大小,它可以用于任何需要计算32位整数数组之和的程序。只要有可能,编程者也应该编写具有灵活性和适应性的程序。
测试 ArraySum 过程
下面的程序通过传递一个 32 位整数数组的偏移量和长度来测试 ArraySum 过程。调用 ArraySum 之后,程序将过程的返回值保存在变量 theSum 中。
;测试ArraySum过程
.386
.model flat,stdcall
.stack 4096
ExitProcess PROTO,dwExitCode:DWORD
.data
array DWORD 10000h,20000h,30000h,40000h,50000h
theSum DWORD ?
.code
main PROC
mov esi,OFFSET array ;ESI指向数组
mov ecx,LENGTHOF array ;ECX = 数组计算器
call ArraySum ;计算和数
mov theSum,eax ;用EAX返回和数
INVOKE ExitProcess,0
main ENDP
;------------------------------------
;ArraySum
;计算32位整数数组元素之和
;接收:ESI = 数组偏移量
; ECX = 数组元素的个数
;返回:EAX = 数组元素之和
;-------------------------------------
ArraySum PROC
push esi ;保存ESI和ECX
push ecx
mov eax,0 ;设置和数为0
L1: add eax,[esi] ;将每个整数与和数相加
add esi,TYPE DWORD ;指向下一个整数
loop L1 ;按照数组大小重复
pop ecx ;恢复ECX和ESI
pop esi
ret ;和数在EAX中
ArraySum ENDP
END main
汇编语言USES运算符
USES 运算符
USES 运算符与 PROC 伪指令一起使用,让程序员列出在该过程中修改的所有寄存器名。USES 告诉汇编器做两件事情:第一,在过程开始时生成 PUSH 指令,将寄存器保存到堆栈;第二,在过程结束时生成 POP 指令,从堆栈恢复寄存器的值。
USES 运算符紧跟在 PROC 之后,其后是位于同一行上的寄存器列表,表项之间用空格符或制表符(不是逗号)分隔。
在 ArraySum 过程使用 PUSH 和 POP 指令来保存和恢复 ESI 和 ECX。 USES 运算符能够更加容易地实现同样的功能:
ArraySum PROC USES esi ecx mov eax, 0 ;置和数为0 L1: add eax,[esi] ;将每个整数与和数相加 add esi, TYPE DWORD ;指向下个整数 loop L1 ;按照数组大小重复 ret ;和数在 EAX 中 ArraySum ENDP
汇编器生成的相应代码展示了使用 USES 的效果:
ArraySum PROC push esi push ecx mov eax, 0 ;置和数为0 L1: add eax, [esi] ;将每个整数与和数相加 add esi, TYPE DWORD ;指向下一个整数 loop L1 ;按照数组大小重复 pop ecx pop esi ret ArraySum ENDP
调试提示:使用 Microsoft Visual Studio 调试器可以查看由 MASM 高级运算符和伪指令生成的隐藏机器指令。在调试窗口中右键点击,选择 Go To Disassembly。该窗口显示程序源代码,以及由汇编器生成的隐藏机器指令。
当过程利用寄存器(通常用 EAX)返回数值时,保存使用寄存器的惯例就岀现了一个重要的例外。在这种情况下,返回寄存器不能被压入和弹出堆栈。例如下述 SumOf 过程把 EAX 压入、弹出堆栈,就会丢失过程的返回值:
SumOf PROC ;三个整数之和 push eax ;保存EAX add eax, ebx add eax, ecx ;计算EAX、EBX和ECX之和 pop eax ;和数丢失! ret SumOf ENDP
汇编语言链接库简介
背景知识
链接库是一种文件,包含了已经汇编为机器代码的过程(子程序)。链接库开始时是一个或多个源文件,这些文件再被汇编为目标文件。目标文件插入到一个特殊格式文件,该文件由链接器工具识别。
假设一个程序调用过程 WriteString 在控制台窗口显示一个字符串。该程序源代码必须包含 PROTO 伪指令来标识 WriteString 过程:
WriteString proto
之后,CALL 指令执行 WriteString:
call WriteString
当程序进行汇编时,汇编器将不指定 CALL 指令的目标地址,它知道这个地址将由链接器指定。链接器在链接库中寻找 WriteString,并把库中适当的机器指令复制到程序的可执行文件中。同时,它把 WriteString 的地址插入到 CALL 指令。
如果被调用过程不在链接库中,链接器就发出错误信息,且不会生成可执行文件。
链接命令选项
链接器工具把一个程序的目标文件与一个或多个目标文件以及链接库组合在一起。比如,下述命令就将 hello.obj 与 irvine32.lib 和 kernel32.lib 库链接起来:
link hello.obj irvine32.lib kernel32.lib
32位程序链接
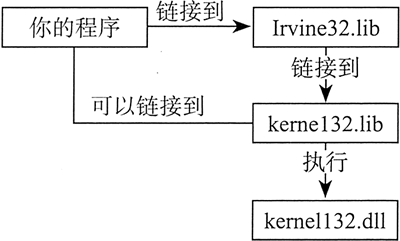
kernel32.lib 文件是 Microsoft Windows 平台软件开发工具(Software Development Kit)的一部分,它包含了 kernel32.dll 文件中系统函数的链接信息。kernel32.dll 文件是 MS-Windows 的一个基本组成部分,被称为动态链接库(dynamic link library)。它含有的可执行函数实现基于字符的输入输出。
下图展示了为什么 kernel32.lib 是通向 kernel32.dll 的桥梁。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











