



1. 前提
-
Hadoop环境:已搭建Hadoop伪分布式集群,HDFS服务正常运行(需提前验证
start-dfs.sh和start-yarn.sh)。 -
Python现状:Ubuntu 20.04默认预装Python3.8,需保留系统原有版本,避免影响依赖Python3.8的其他组件(如系统工具或Hadoop生态工具)。
2. 安装Python3.6的步骤
-
检查现有Python版本
-
通过
ls -l /usr/bin/python*查看软链接,确认python3指向python3.8。
从输出的文件列表可以看出,python3实际是一个软链接文件,指向python3.8执行程 序。我们可以分别运行python3和python3.8命令,以确认它们是否为同一个:
Python命令不可用
-
现在面临两个选择,一是将系统默认安装的Python3.8 卸载替换成Python3.6,但是有风险。二就是在系统中同时保留多个Python版本,然后根据实际需要切换使用。这里准备采取第二种做法,即保留预装的Python3.8,另外安装一个Python3.6 运 行环境到系统中。
-
在安装Python3.6之前,先执行一下apt软件源的更新工作:

-
-
添加第三方软件源(Deadsnakes PPA)
-
由于Ubuntu软件源不含Python3.6的预编译版本,所以就要使用一个非常优秀的第 三方软件源Deadsnakes PPA。
执行以下命令添加PPA源:
回车:

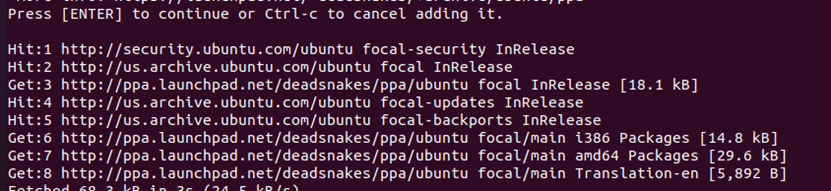
-
注意:若未安装
add-apt-repository,需先安装software-properties-common。
-
-
安装Python3.6
-
命令:
sudo apt install python3.6,安装完毕查看一下Python3.6的启动程序。


-
安装后生成两个关键文件:
-
/usr/bin/python3.6:标准解释器。 -
/usr/bin/python3.6m:优化内存分配版本。
-
-
-
配置PySpark环境变量
-
在
/etc/profile中设置PYSPARK_PYTHON指向Python3.6:

-
生效配置:
source /etc/profile。
-
3. 验证PySpark交互环境
-
启动PySpark Shell
-
运行
pyspark,观察启动日志确认Python版本为3.6。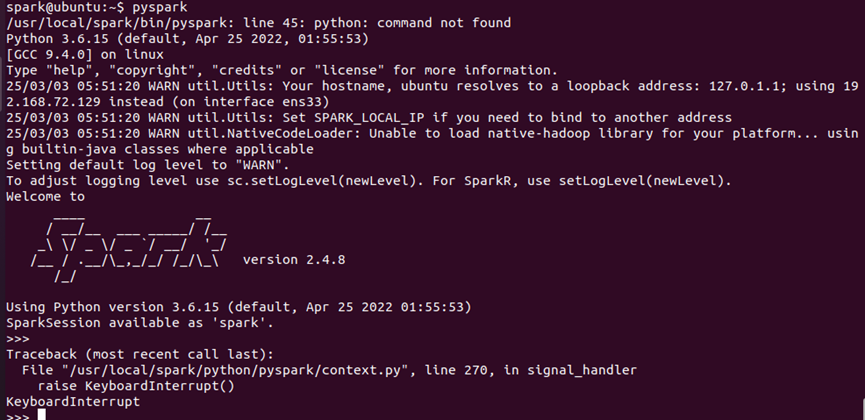
-
关键点:若版本不符,检查环境变量或重新加载配置。
-
-
测试文件读写
-
本地文件:
sc.textFile("file:///path/to/local/file")。

-
HDFS文件:
sc.textFile("hdfs://localhost:9000/path/to/hdfs/file")(需确保HDFS服务已启动)。
-
-
退出Shell
-
使用
Ctrl+D或quit()。
-
4. 配置pip工具与国内镜像
-
安装pip
-
在Linux终端执行下面的命令安装pip工具,然后查看一下pip的版本信息,以及对应管理的Python版本:


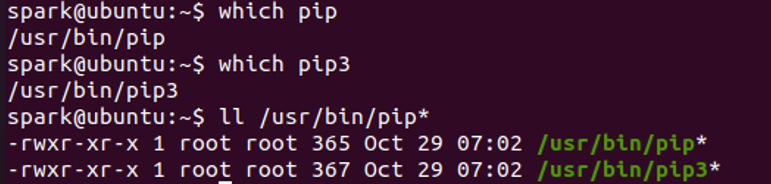

-
在Linux终端继续执行下面的命令:

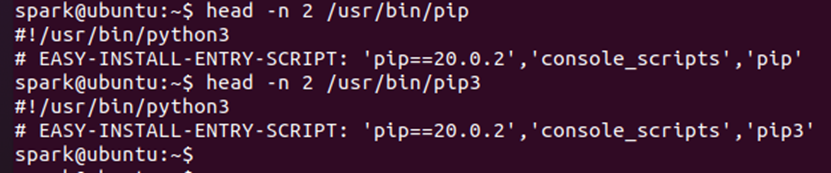



-
现在可以验证pip和pip3的设置是否达到了预期目标
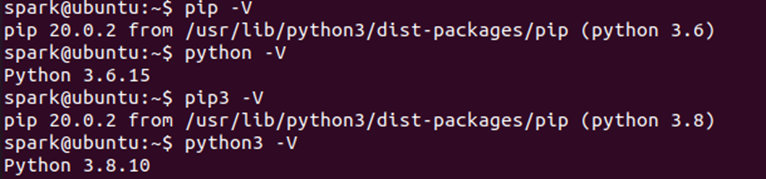
-
-
配置国内镜像源(如清华/阿里云)
-
当pip包管理工具安装配置好之后,考虑到实际使用时需要访问网络下载软件,下 面将pip源改成国内镜像(如阿里云、清华镜像站点等),以加快下载速度。

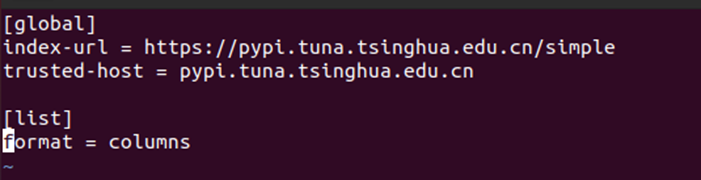
-
pip镜像源配置文件修改完毕,通过下面的命令进行验证是否有效:
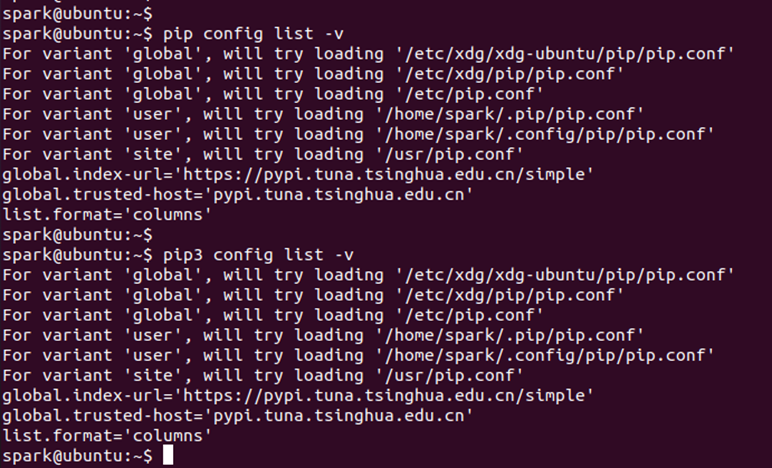
-
5. Spark目录结构与关联性
-
Spark安装目录:
在Spark的系统目录中包含有一系列的文件和子目录内容,每个目录都有其特定的目的和用途。-
bin/:包含pyspark、spark-shell等可执行脚本。 -
conf/:配置文件(如spark-env.sh可覆盖PYSPARK_PYTHON)。 -
jars/:依赖的Java库(Hadoop兼容性需匹配版本)。
-
-
与Hadoop关联:
-
Spark默认读取HDFS需依赖
core-site.xml和hdfs-site.xml的配置(位于Hadoop配置路径)。
-
关键注意事项
-
版本冲突:避免卸载系统Python3.8,否则可能导致apt依赖错误。
-
环境隔离:推荐使用
virtualenv或conda管理Python多版本(可选)。 -
HDFS权限:PySpark操作HDFS时需确保用户有读写权限(如
hdfs dfs -chmod)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









